pytorch中常用的hooks函数
pytorch中的钩子函数有很多,可以直接去官网搜索,在这里挑了其他博客中介绍到的几个钩子函数来进行学习和介绍
1、torch.Tensor.register_hook()
2、torch.nn.Module.register_forward_hook()
3、torch.nn.Module.register_full_backward_hook(hook)
4、torch.nn.Module.register_forward_pre_hook().
以下资料可以配合官方文档查看学习
1、torch.Tensor.register_hook(hook(grad))
这里的hook(grad)是指自己定义的 一个方法函数,形参就是输入的某一个张量的梯度,对于方法函数grad_hook而言,她的形参输入就是x.grad
比如以下代码:
import torch
def grad_hook(grad):
print(grad)
return grad
x = torch.tensor([1.], requires_grad=True)
y = torch.pow(x, 2)
y1 = torch.exp(y)
y2 = torch.sqrt(y1)
z = torch.mean(y2)
print(z)
h2 = y2.register_hook(grad_hook)
h1 = y1.register_hook(grad_hook)
h = y.register_hook(grad_hook)
z.backward()
h.remove()
h1.remove()
h2.remove()
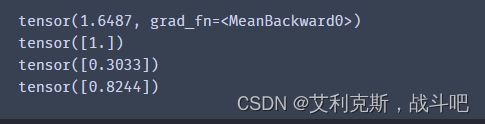
在计算的过程中,依次先把y2.grad、y1.grad以及y.grad送进grad_hook中进行计算在计算的过程中也需要前传的结果,比如计算y1的梯度,应该是这样计算

(1)用来导出指定张量的梯度,或修改这个梯度值,因此只适合在backward()中使用该函数,这个钩子必须要在backward之前,remove必须在backward之后
(2)可以用remove()方法取消hook。注意remove()必须在backward()之后,因为只有在执行backward()语句时,pytorch才开始计算梯度,而在x.register_hook(grad_hook)时它仅仅是"注册"了一个grad的钩子,此时并没有计算,而执行remove就取消了这个钩子,然后再backward()时钩子就不起作用了。
(3)如果在类中定义钩子函数,输入参数必须先加上self,这个还没有尝试,之后再说吧
2、nn.Module.register_forward_hook(hook(module,input,output)
(1)用来导出指定子模块(可以是层、模块等nn.Module类型)的输入输出张量,但只可修改输出,常用来导出或修改卷积特征图。
(2)因为模块可以是多输入的,所以输入是tuple型的,需要先提取其中的Tensor再操作;输出是Tensor型的可直接用。
(3)导出后不要放到显存上,除非你有A100。
(4)只能修改输出out的值,不能修改输入inp的值(不能返回,本地修改也无效),修改时最好用return形式返回,如:
可以稍微验证一下,理论上上一层的输出是下一层的输入,可以用一个小网络判断一下输入和输出是否相等!
import torchvision.models as models
from PIL import Image
import torchvision.transforms as transforms
net = models.alexnet(pretrained = True)
print(net)
import torch.nn as nn
import torch.nn.functional as F
import torch
std = [0.229, 0.224, 0.225]
mean = [0.485, 0.456, 0.406]
img = Image.open('./data/cat.jpg').convert('RGB')
print(img.size)
trans = transforms.Compose([
transforms.CenterCrop(max(img.size)),
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize(mean,std)
])
input = trans(img).unsqueeze(0)
input = torch.cat((input,input),0)
# 在你想要的层注册hook,方法就是调用register_forward_hook
feature_in_list = []
feature_out_list = []
def get_feature_hook(x,feature_in,feature_out):
print(f'feature_in:{feature_in[0].size()}')#这里feature_in是一个元组(tensor(……),)
print(f'feature_out:{feature_out.size()}')#这里feature_out是一个tensor
# print(f'{x} Done one!')
feature_in_list.append(feature_in[0])
feature_out_list.append(feature_out)
name_children = ['features.11','features.12','features']
Handle = []
for name_child,child in net.named_modules():
# print(name_child)
if name_child in name_children:
print(f'Find it:{name_child}')
handle = child.register_forward_hook(get_feature_hook)
Handle.append(handle)
out = net(input)
out = F.softmax(out,1)
# softmax = nn.Softmax(1)
# out = softmax(out)
for hand in Handle:
hand.remove()
value, predicted = torch.max(out.data, 1)
print(value, predicted)
print(len(feature_in_list))
x = torch.equal(feature_in_list[1].data,feature_out_list[0].data)
print(x)
print(feature_in_list[1][0].size())
print(feature_out_list[0][0].size())
y = torch.equal(feature_out_list[1].data,feature_out_list[2].data)
print(y)

通过最后一个代码段的验证结果,我们可以看见,上一层的输出是下一层的输入,而且对于一个大层来说,大层的输出等于最后一个子层的输出
3、register_full_backward_hook(hook)
本来应该讲的是register_backward_hook,但是已经被弃用了,新方法是register_full_backward_hook(hook(module, grad_input, grad_output)),参考register_forward_hook用法
def get_grad_hook(module,grad_in,grad_out):
print(f'grad_in:{grad_in[0].size()}')#这里grad_in是一个元组(tensor(……),)
print(f'grad_out:{grad_out[0].size()}')#这里fgrad_out也一个元组(tensor(……),)
# print(f'{x} Done one!')
grad_in_list.append(grad_in[0])
grad_out_list.append(grad_out[0])
name_children = ['features.11',,'features']
for name_child,child in net.named_modules():
if name_child in name_children:
print(f'Find it:{name_child}')
handle_grad = child.register_backward_hook(get_grad_hook)
Hadle_grad.append(handle_grad)
for hand in Handle:
hand.remove()
out = net(input)
out = F.softmax(out,1)
# softmax = nn.Softmax(1)
# out = softmax(out)
value, predicted = torch.max(out.data, 1)
loss = torch.mean(value)
print(out)
out[0,0].backward()
for handle_grad in Handle_grad:
handle_grad.remove()
# print(value, predicted,loss)
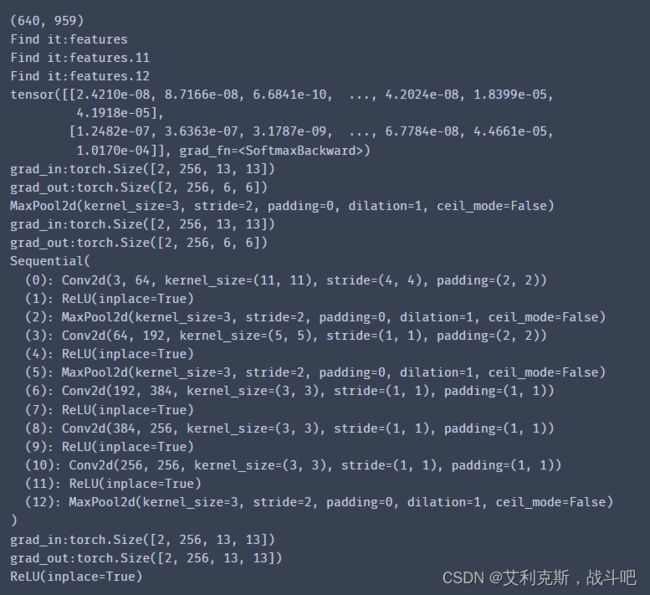
可以看到,这里最先输出的是feature.12,然后才是feature(父层(我也不知道叫啥名字)),然后才是feature.11,与前传结果不一样,前传结果按照顺序来,肯定是先输出featur.11,然后输出feature.12,最后输出父层feature,也就是说,总是先计算子层grad,然后计算父层,然后计算其他子层grad.