EXPLAIN的用法
一、语法
EXPLAIN + SQL语句
二、各字段解释
![]()
1、table
● 单表:显示这一行的数据是关于哪张表的。
 ● 多表关联:t1为驱动表,t2为被驱动表。
● 多表关联:t1为驱动表,t2为被驱动表。
注意: 内连接时,MySQL性能优化器会自动判断哪个表是驱动表,哪个表示被驱动表,和书写的顺序无关。

2、id
表示查询中执行select子句或操作表的顺序。
● id相同:执行顺序由上至下

● id不同:如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行

注意: 查询优化器可能对涉及子查询的语句进行优化, 转为连接查询

● id为NULL:最后执行

小结:
● id如果相同,可以认为是一组,从上往下顺序执行
● 在所有组中,id值越大,优先级越高,越先执行
● 关注点:id号每个号码,表示一趟独立的查询, 一个sql的查询趟数越少越好
3、select_type
查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询。
● SIMPLE:简单查询。查询中不包含子查询或者UNION。

● PRIMARY:主查询。查询中若包含子查询,则最外层查询被标记为PRIMARY。
● SUBQUERY:子查询。在SELECT或WHERE列表中包含了子查询。

● DEPENDENT SUBQUREY:如果包含了子查询,并且查询语句不能被优化器转换为连接查询,并且子查询是 相关子查询(子查询基于外部数据列) ,则子查询就是DEPENDENT SUBQUREY。

● UNCACHEABLE SUBQUREY:表示这个subquery的查询要受到外部系统变量的影响。

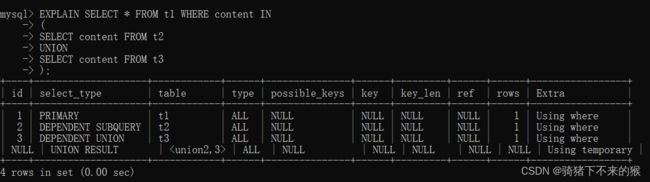
● UNION:对于包含UNION或者UNION ALL的查询语句,除了最左边的查询是PRIMARY,其余的查询都是UNION。
● UNION RESULT:UNION会对查询结果进行查询去重,MYSQL会使用临时表来完成UNION查询的去重工作,针对这个临时表的查询就是"UNION RESULT"。

● DEPENDENT UNION:子查询中的UNION或者UNION ALL,除了最左边的查询是DEPENDENT SUBQUREY,其余的查询都是DEPENDENT UNION。
● DERIVED:在包含 派生表(子查询在from子句中) 的查询中,MySQL会递归执行这些子查询,把结果放在临时表里。

这里的
MySQL在处理带有派生表的语句时,优先尝试把派生表和外层查询进行合并,如果不行,再把派
生表 物化掉(执行子查询,并把结果放入临时表) ,然后执行查询。
下面的例子就是就是将派生表和外层查询进行合并的例子:

● MATERIALIZED:优化器对于包含子查询的语句, 如果选择将子查询物化后再与外层查询连接查询 ,该子查询的类型就是MATERIALIZED。如下的例子中,查询优化器先将子查询转换成物化表,然后将t1和物化表进行连接查询。

4、type
结果值从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery
> index_subquery > range > index > ALL
比较重要的包含:system >const >eq_ref >ref >range > index > ALL
SQL 性能优化的目标:至少要达到 range 级别,要求是 ref 级别,最好是 consts 级别。(阿里巴巴开发手册要求)
● ALL:全表扫描。Full Table Scan,将遍历全表以找到匹配的行

● index:当使用 覆盖索引 ,但需要扫描全部的索引记录时。
覆盖索引: 如果能通过读取索引就可以得到想要的数据,那就不需要读取用户记录,或者不用再做回表操作了。一个索引包含了满足查询结果的数据就叫做覆盖索引。
-- 只需要读取聚簇索引部分的非叶子节点,就可以得到id的值,不需要查询叶子节点。

-- 只需要读取二级索引,就可以在二级索引中获取到想要的数据,不需要再根据叶子节点中的id做回表操作。
● range:只检索给定范围的行,使用一个索引来选择行。key 列显示使用了哪个索引,一般就是在你的where语句中出现了between、<、>、in等的查询。这种范围扫描索引扫描比全表扫描要好,因为它只需要开始于索引的某一点,而结束于另一点,不用扫描全部索引。
 ● ref:通过普通二级索引列与常量进行等值匹配时。
● ref:通过普通二级索引列与常量进行等值匹配时。

● eq_ref:连接查询时通过主键或不允许NULL值的唯一二级索引列进行等值匹配时。

● const:根据 主键 或者 唯一二级索引 列与 常数 进行匹配时。

● system:MyISAM引擎中,当表中只有一条记录时。 (这是所有type的值中性能最高的场景)。

5、possible_keys
possible_keys 表示执行查询时可能用到的索引,一个或多个。 查询涉及到的字段上若存在索
引,则该索引将被列出,但不一定被查询实际使用。
6、keys
keys 表示实际使用的索引。如果为NULL,则没有使用索引。

7、key_len
表示索引使用的字节数,根据这个值可以判断索引的使用情况, 检查是否充分利用了索引,针对联合索引值越大越好。
如何计算:
1. 先看索引上字段的类型+长度。比如:int=4 ; varchar(20) =20 ; char(20) =20
2. 如果是varchar或者char这种字符串字段,视字符集要乘不同的值,比如utf8要乘 3,如果是
utf8mb4要乘4,GBK要乘2
3. varchar这种动态字符串要加2个字节
4. 允许为空的字段要加1个字节
8、ref
显示与key中的索引进行比较的列或常量。
9、rows
MySQL认为它执行查询时必须检查的行数。值越小越好。
10、filtered
最后查询出来的数据占所有服务器端检查行数(rows)的 百分比 。值越大越好。
11、Extra
包含不适合在其他列中显示但十分重要的额外信息。通过这些额外信息来 理解MySQL到底将如何执行当前的查询语句 。MySQL提供的额外信息有好几十个,这里只挑介绍比较重要的介绍。
● Impossible WHERE:where子句的值总是false

● Using where:使用了where,但在where上有字段没有创建索引

● Using temporary:使了用临时表保存中间结果

● Using filesort:
在对查询结果中的记录进行排序时,是可以使用索引的,如下所示:

如果排序操作无法使用到索引,只能在内存中(记录较少时)或者磁盘中(记录较多时)进行排序
(filesort),如下所示:

● Using index:使用了覆盖索引,表示直接访问索引就足够获取到所需要的数据,不需要通过索引
回表

● Using index condition:叫作 Index Condition Pushdown Optimization (索引下推优化)
♦如果没有索引下推(ICP) ,那么MySQL在存储引擎层找到满足 content1 > 'z' 条件的第一条二级索引记录。 主键值进行回表 ,返回完整的记录给server层,server层再判断其他的搜索条件是否成立。如果成立则保留该记录,否则跳过该记录,然后向存储引擎层要下一条记录。
♦如果使用了索引下推(ICP ),那么MySQL在存储引擎层找到满足 content1 > 'z' 条件的第一条二级索引记录。 不着急执行回表 ,而是在这条记录上先判断一下所有关于 idx_content1索引中包含的条件是否成立,也就是 content1 > 'z' AND content1 LIKE '%a' 是否成立。如果这些条件不成立,则直接跳过该二级索引记录,去找下一条二级索引记录;如果这些条件成立,则执行回表操作,返回完整的记录给server层。

如果这里的查询条件 只有content1 > 'z' ,那么找到满足条件的索引后也会进行一次索引下推
的操作,判断content1 > 'z'是否成立(这是源码中为了编程方便做的冗余判断)

● Using join buffer:在连接查询时,当被驱动表不能有效的利用索引时,MySQL会为其分配一块
名为连接缓冲区(join buffer)的内存来加快查询速度

测试数据
CREATE TABLE t1(id INT(10) AUTO_INCREMENT, content VARCHAR(100) NULL, PRIMARY
KEY (id));
CREATE TABLE t2(id INT(10) AUTO_INCREMENT, content VARCHAR(100) NULL, PRIMARY
KEY (id));
CREATE TABLE t3(id INT(10) AUTO_INCREMENT, content VARCHAR(100) NULL, PRIMARY
KEY (id));
CREATE TABLE t4(id INT(10) AUTO_INCREMENT, content1 VARCHAR(100) NULL, content2
VARCHAR(100) NULL, PRIMARY KEY (id));
CREATE INDEX idx_content1 ON t4(content1); -- 普通索引
# 以下新增sql多执行几次,以便演示
INSERT INTO t1(content) VALUES(CONCAT('t1_',FLOOR(1+RAND()*1000)));
INSERT INTO t2(content) VALUES(CONCAT('t2_',FLOOR(1+RAND()*1000)));
INSERT INTO t3(content) VALUES(CONCAT('t3_',FLOOR(1+RAND()*1000)));
INSERT INTO t4(content1, content2) VALUES(CONCAT('t4_',FLOOR(1+RAND()*1000)),
CONCAT('t4_',FLOOR(1+RAND()*1000)));