MYCAT介绍,安装及操作
一.MYCAT
1.mycat是什么
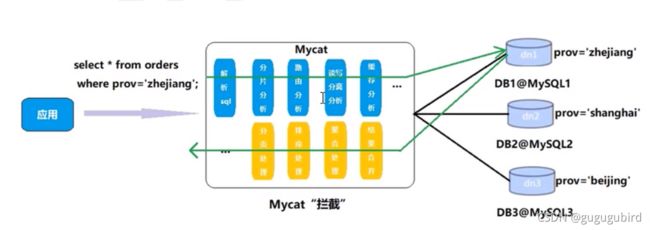
mycat是数据库中间件.
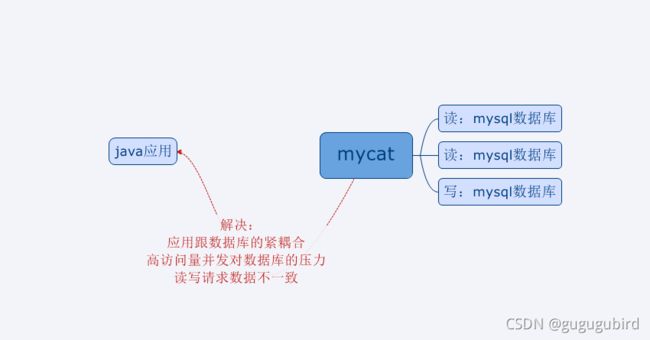
1.数据库中间件:
中间件:是一类连接软件组件和应用的计算机软件,以便于软件各部件之间的沟通。
列子:tomcat,web中间件
数据库中间件:连接java应用和数据库
2.数据库中间件对比
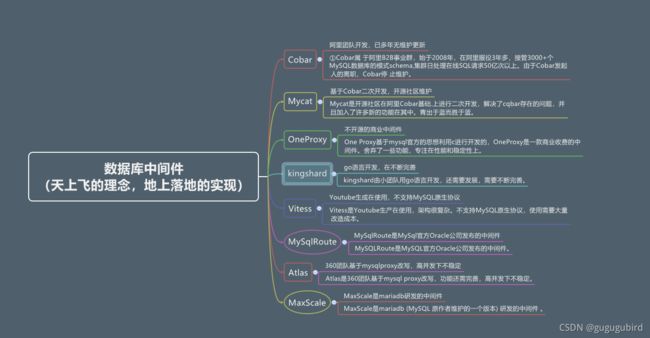
2.mycat官网
http://www.mycat.io/
3.mycat干什么的
1.读写分离

2.数据分片
垂直拆分(分库),水平拆分(分表),垂直+水平拆分(分库分表)
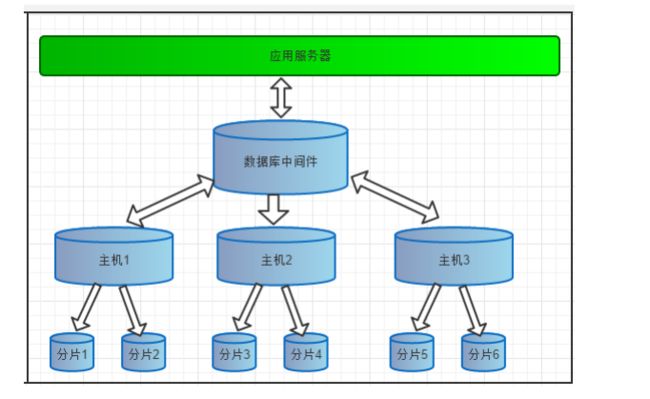
3.多数据源整合
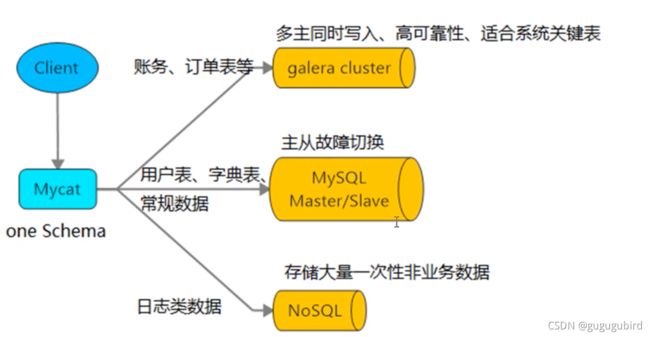
4.mycat原理
Mycat的原理中最重要的一一个动词是“拦截”,它拦截了用户发送过来的sql语句,首先对sql 语句做了-些特定的分析:如分片分析、 路由分析、读写分离分析、缓存分析等,然后将此sql发往后端的真实数据库,并将返回的结果做适当的处理最终再返回给用户。
5.mycat安装
安装包连接
链接:https://pan.baidu.com/s/1G8xvGvYrgF2q0Q9cLMO61A
提取码:idea
1.将安装包放到opt目录下
2.在linux虚拟机上进行解压
cd /opt进入到该目录,执行命令
tar -zxvf Mycat-server-1.6.7.4-release-20200105164103-linux.tar.gz 进行解压得到

3.将该文件夹复制到 /usr/local/目录下
cp -r mycat /usr/local/进入该文件夹查看内容
4.配置文件
schema.xml # 定义逻辑库,表,分片节点等内容
rule.xml # 定义分片规则
server.xml # 定义用户以及系统相关变量,如端口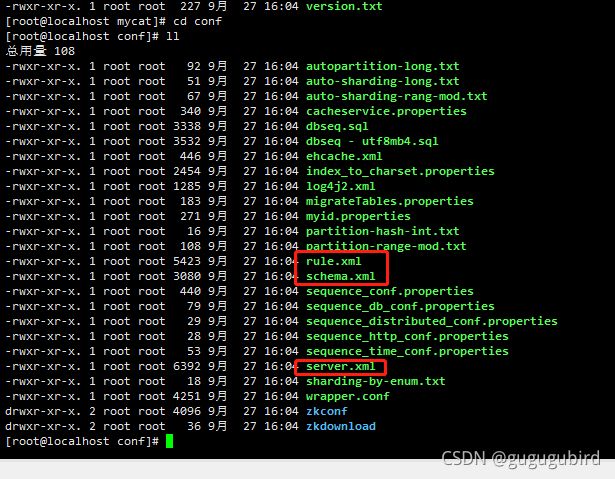
5.修改server.xml文件
vi server.xml

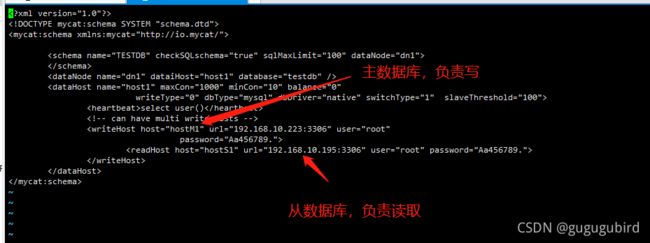
6.修改schema.xml文件
select user()
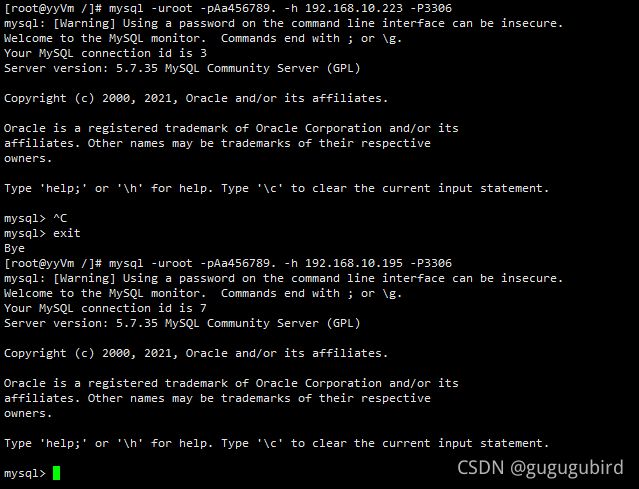
6.验证数据库访问情况
mysql -uroot -pAa456789. -h 192.168.10.195 -P3306
mysql -uroot -pAa456789. -h 192.168.10.223 -P3306
6.启动mycat
方式一:
控制台启动 :去mycat/bin 目录下执行 ./mycat console
方式二:
后台启动:去mycat/bin 目录下执行 ./mycat start
为了能第一时间看到启动日志,方便定位问题,我们选择方式一,控制台启动。
启动成功
./mycat console 启动
./mycat start 启动
./mycat stop 停止
./mycat restart 重启
./mycat pause 暂停
./mycat status 查看启动状态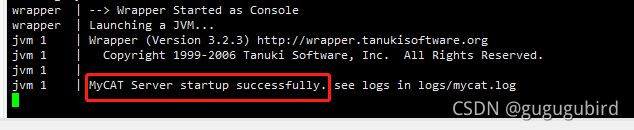
7.登录mycat
1、登录后台管理窗口,此登录方式用于管理维护 Mycat (运维管理方式)
mysql -umycat -p123456 -P 9066 -h 192.168.10.223
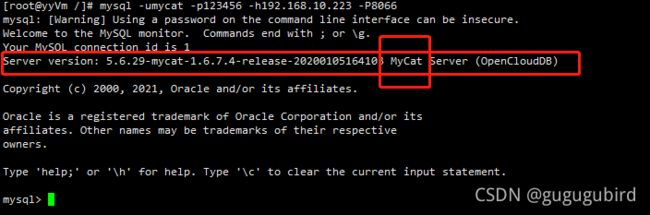
2.登录数据窗口(java应用方式)
此登录方式用于通过 Mycat 查询数据,我们选择这种方式访问 Mycat
mysql -umycat -p123456 -P 8066 -h 192.168.10.223

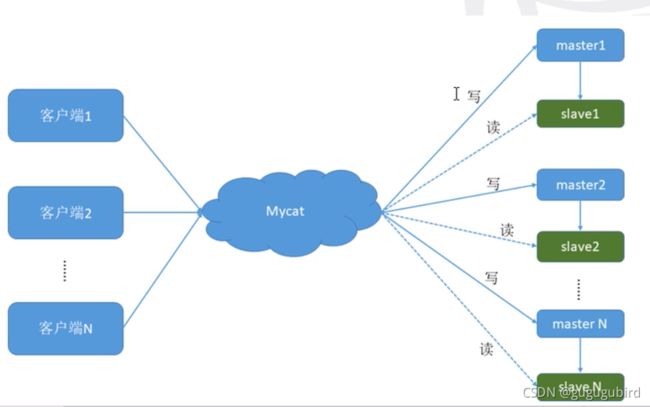
二.mycat实现读写分离
我们通过 Mycat 和 MySQL 的主从复制配合搭建数据库的读写 分离,实现 MySQL 的高可用性。 我们将搭建:一主一从、双主双从两种读写分离模式。
1.搭建一主一从
一个主机用于处理所有写请求,一台从机负责所有读请求,架构图如下
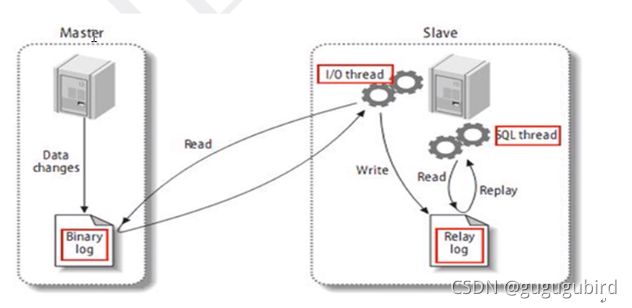
1.搭建 MySQL 数据库主从复制
mysql主从复制原理
2.主机配置(yyVm)
修改配置文件:vim /etc/my.cnf
#主服务器唯一ID
server-id=1
##启用二进制日志
log-bin=mysql-bin
## 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
##设置需要复制的数据库
binlog-do-db=testdb
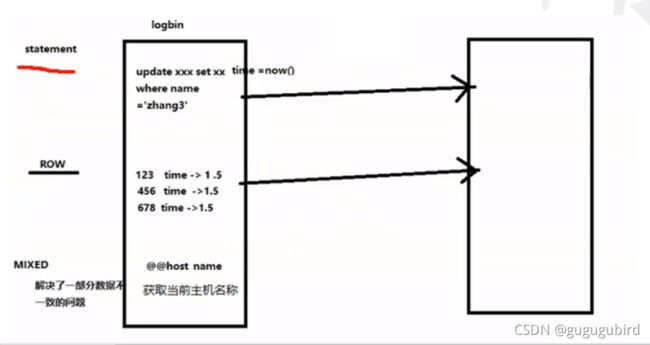
##设置logbin格式
binlog_format=STATEMENT
binlog日志的三种格式
3.从机配置
修改配置文件:vim /etc/my.cnf
#从服务器唯一ID
server-id=2
#启用中继日志
relay-log=mysql-relay4.重启主从数据库
systemctl restart mysqld
5.确认主从机的防火墙关闭
systemctl status firewalld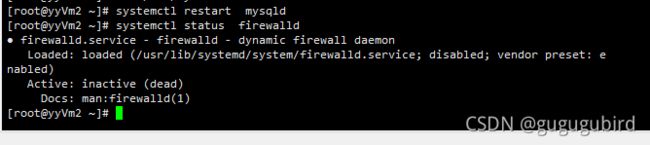

6.在主机上创建账户,并授权给从机(slave)
#在主机MySQL里执行授权命令
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY 'Aa456789.';查看master状态 :show master status;

记录下File和Position的值,执行完此步骤后不要再操作主服务器MySQL,防止主服务器状态值变化
7.在从机上配置需要复制的主机
#复制主机的命令
CHANGE MASTER TO MASTER_HOST='主机的IP地址',
MASTER_USER='slave',
MASTER_PASSWORD='123123',
MASTER_LOG_FILE='mysql-bin.具体数字',MASTER_LOG_POS=具体值;
启动从机服务:start slave;
如果之前搭建过主从,执行该命令
stop slave; #停止从服务功能
重新配置主从
stop slave;
reset master;查看主从关系
#启动从服务器复制功能
start slave;
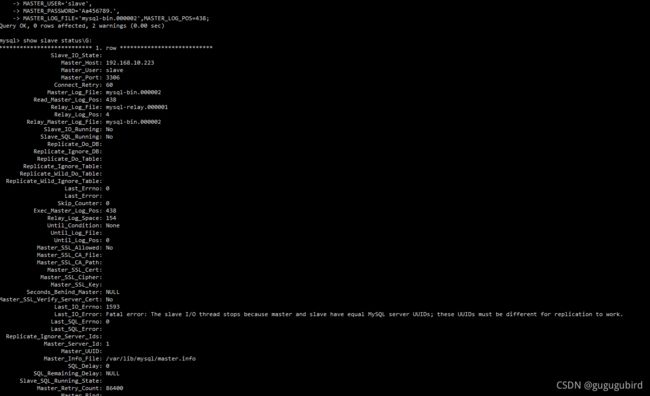
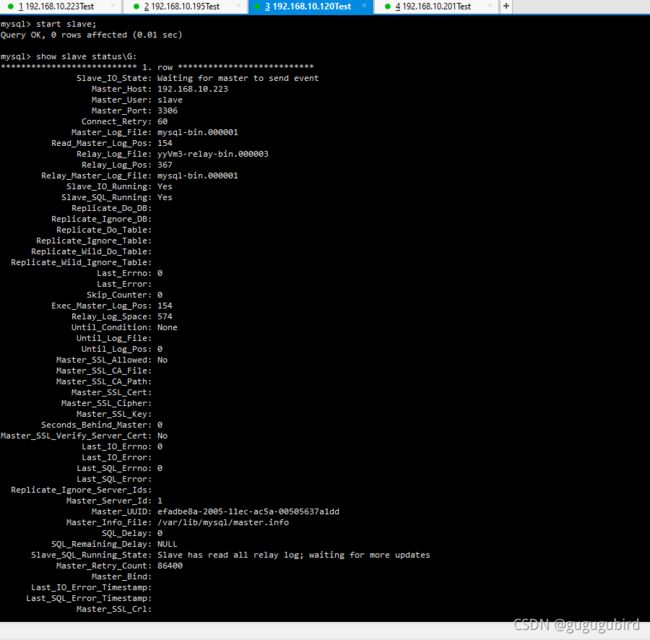
#查看从服务器状态
show slave status\G;2个都是no,并且看到错误信息
Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work。
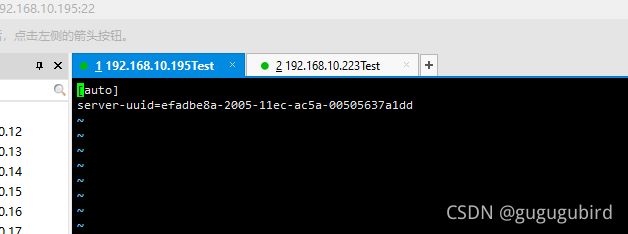
原因从机用的是直接Linux一台服务器的克隆,然后进行主从复制,报了如下的错
退出mysql,输入命令 vi /var/lib/mysql/auto.cnf 查看2台机器的uuid相同

关闭现在从库的Mysql,删除掉auto.cnf文件,开启从库Mysql
[root@yyVm2 ~]# systemctl stop mysqld #关闭mysql
[root@yyVm2 ~]# rm -rf /var/lib/mysql/auto.cnf #删除从库auto.cnf文件
[root@yyVm2 ~]# systemctl start mysqld #启动从库mysqld服务
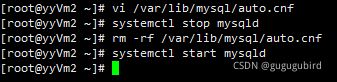
重启主从数据库。

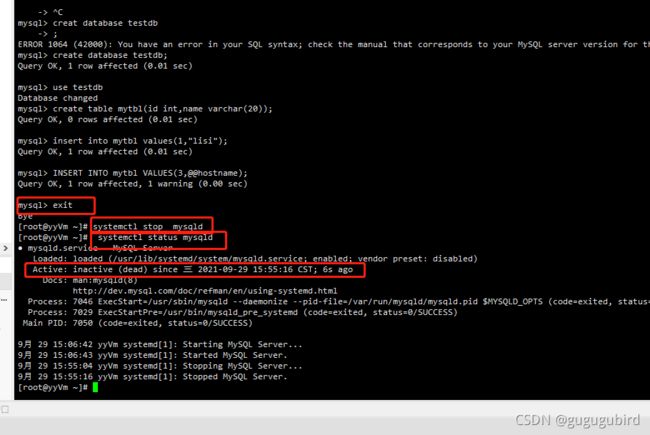
8.测试主从效果

第一次创建数据库报错:ERROR 1007 (HY000): Can't create database 'testdb'; database exists
是因为一开始我们已经创建了testdb数据库,把数据库删除之后在执行创建数据库。

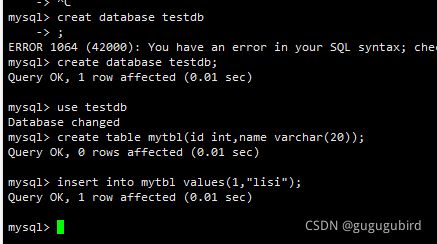
主机创建表
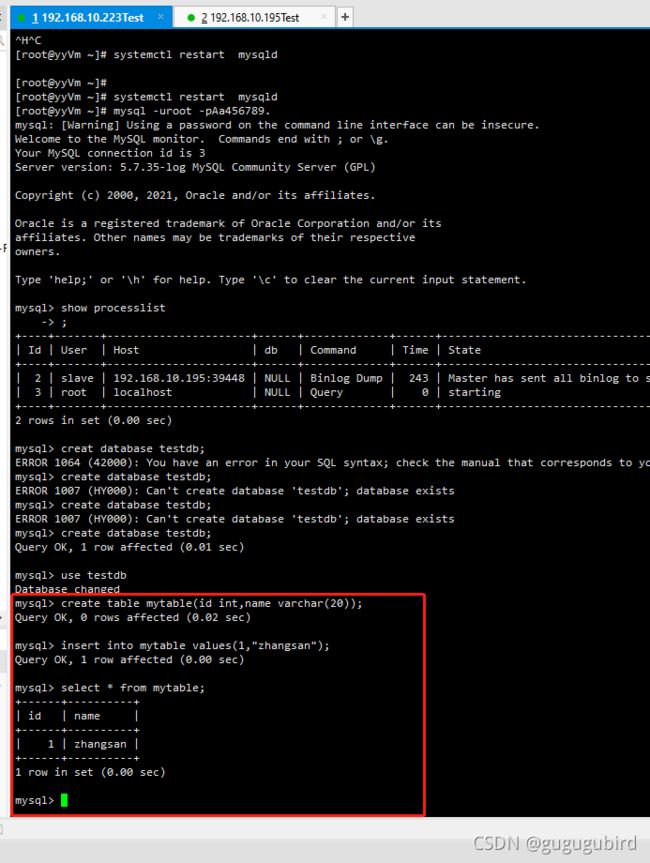
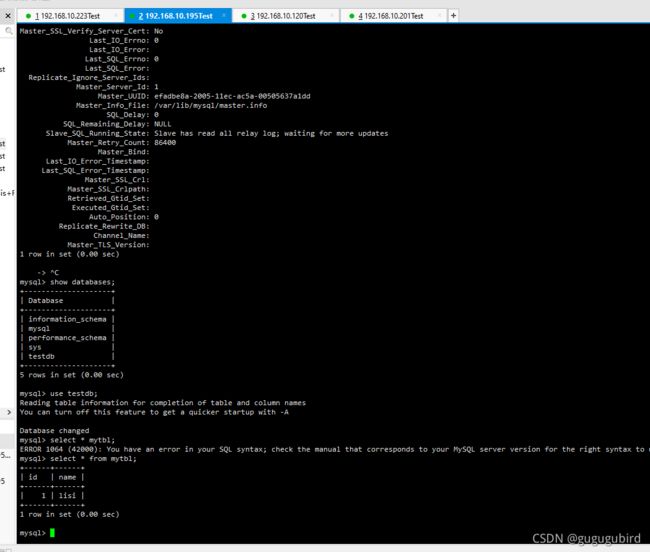
从库查看
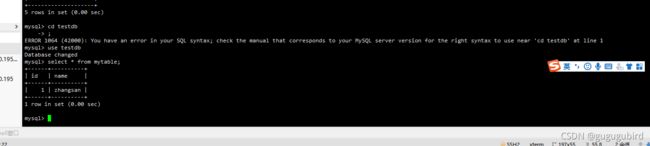
2.主从读写分离
1.查看主机上的schema.xml文件查看是否跟上边配置的一样
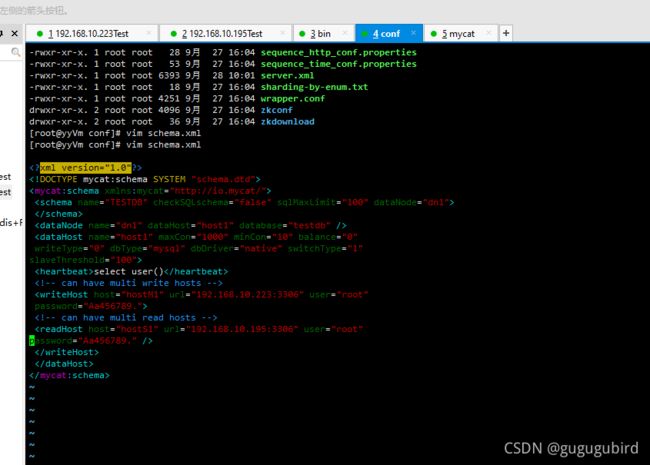
2.启动mycat,查看表

3.验证读写分离
在主机插入
insert into mytable values(1,@@hostname);
在mycat里边查询
select * from mytable;
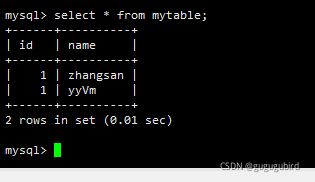
读请求在主机上。
4.修改的balance属性,通过此属性配置读写分离的类型
负载均衡类型,目前的取值有4 种:
(1)balance="0", 不开启读写分离机制,所有读操作都发送到当前
可用的 writeHost 上。
(2)balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。
(3)balance="2",
所有读操作都随机的在 writeHost、readhost 上分发。
(4)balance="3",
所有读请求随机的分发到 readhost 执行,writerHost 不负担读压力
将mycat停止,修改 schema.xml 文件中的 blance属性改为2
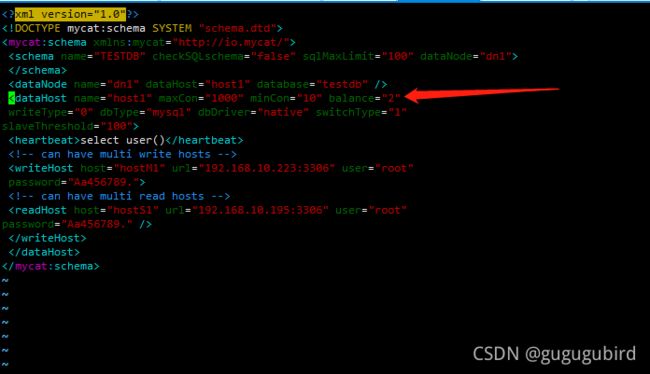
重启mycat,进入数据库查看效果,2台机器随机分配

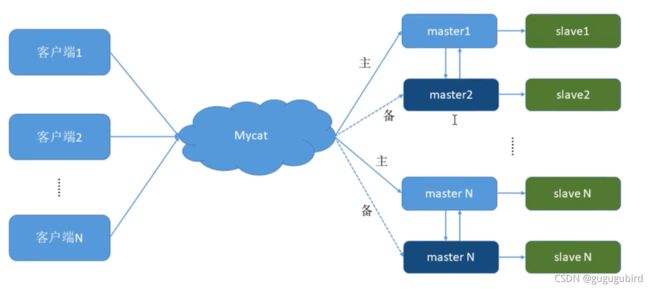
3.双主双从
一个主机 m1 用于处理所有写请求,它的从机 s1 和另一台 主机 m2 还有它的从机 s2 负责所有读请 求。当 m1 主机宕机后,m2 主机负责写请求,m1、m2 互为 备机。架构图如下
| 编号 | 角色 | IP地址 | 机器名字 |
| 1 | Master1 | 192.168.10.223 | yyVm |
| 2 | Slave1 | 192.168.10.195 | yyVm2 |
| 3 | Master2 | 192.168.10.120 | yyVm3 |
| 4 | Slave2 | 192.168.10.201 | yyVm4 |
注意:先把前边的创建testdb数据库给删除
1.搭建mysql数据库的主从复制(双主双从)
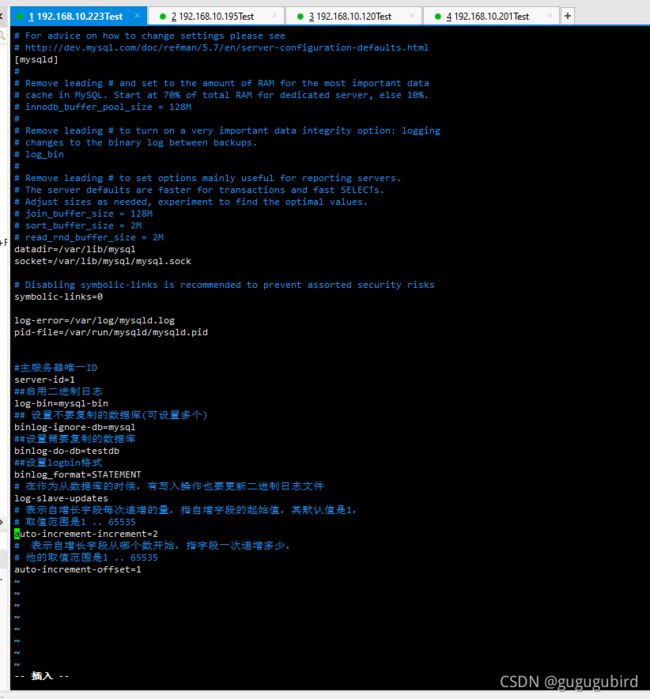
双主机配置
Master1修改配置文件 vim /etc/my.cnf
#主服务器唯一ID
server-id=1
##启用二进制日志
log-bin=mysql-bin
## 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
##设置需要复制的数据库
binlog-do-db=testdb
##设置logbin格式
binlog_format=STATEMENT
# 在作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updates
# 表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1,
# 取值范围是1 .. 65535
auto-increment-increment=2
# 表示自增长字段从哪个数开始,指字段一次递增多少,
# 他的取值范围是1 .. 65535
auto-increment-offset=1
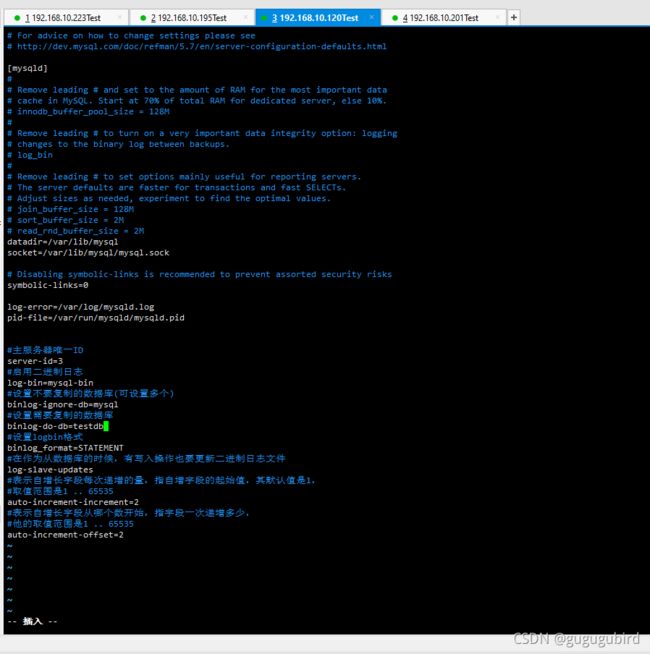
Master2修改配置文件 vim /etc/my.cnf
#主服务器唯一ID
server-id=3
#启用二进制日志
log-bin=mysql-bin
#设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
#设置需要复制的数据库
binlog-do-db=testdb
#设置logbin格式
binlog_format=STATEMENT
#在作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updates
#表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1,
#取值范围是1 .. 65535
auto-increment-increment=2
#表示自增长字段从哪个数开始,指字段一次递增多少,
#他的取值范围是1 .. 65535
auto-increment-offset=2
Slave1修改配置文件 vim /etc/my.cnf
上边已经修改过

Slave2修改配置文件 vim /etc/my.cnf
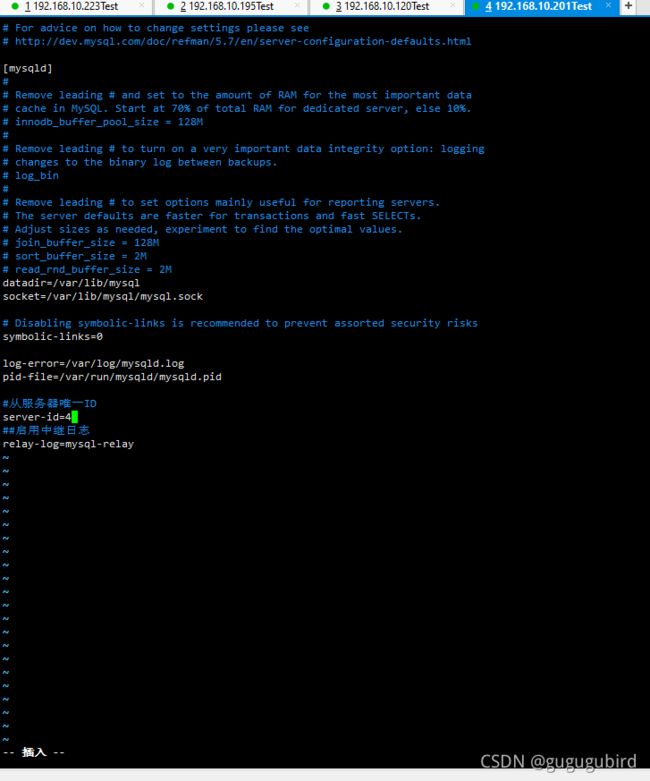
重启4台服务器的mysql systemctl restart mysqld
查看防火墙状态 systemctl status firewalld
如果没有关闭 1. systemctl stop firewalld.service 2.systemctl disable firewalld.service
查看mysql状态 systemctl status mysqld
停止前边创建的主从关系
stop slave;
reset master;
查看Master1的状态
show master status;

查看Master2的状态
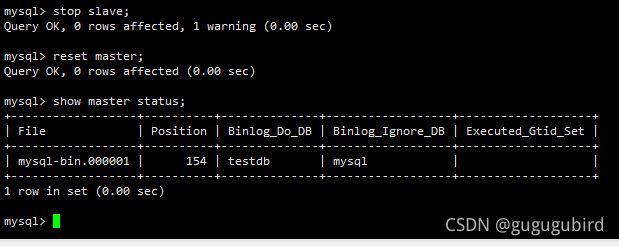
在从机上配置需要复制的主机 Slava1 复制 Master1,Slava2 复制 Master2
#复制主机的命令
CHANGE MASTER TO MASTER_HOST='主机的IP地址',
MASTER_USER='主机名',
MASTER_PASSWORD='主机密码',
MASTER_LOG_FILE='mysql-bin.具体数字',MASTER_LOG_POS=具体值;
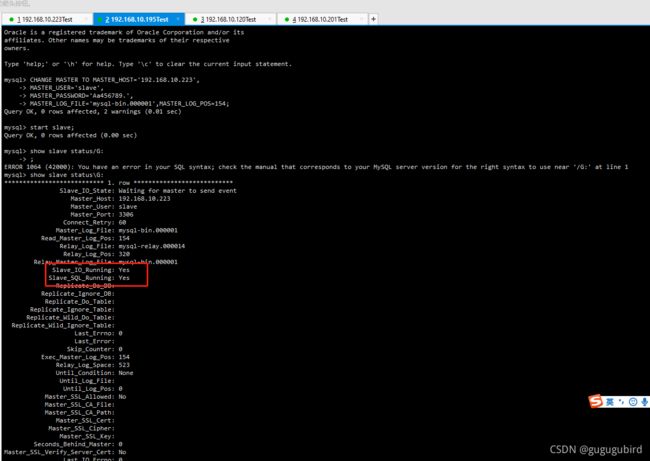
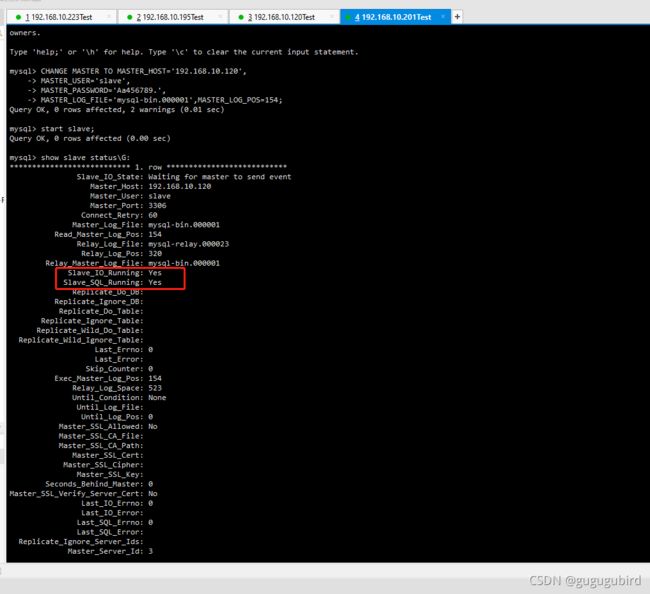
2个主机相互复制
Master1当Master2的从机

Master2当Master1的从机
查看效果
在M1上创建数据库跟表
在其他从机中查看
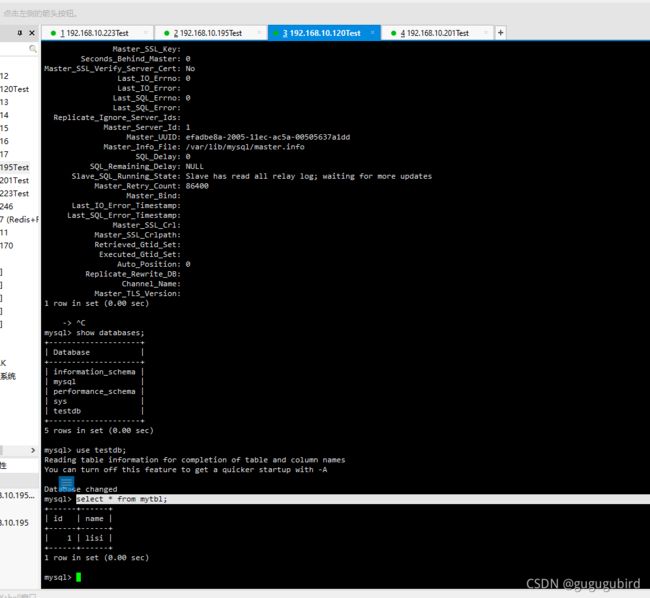
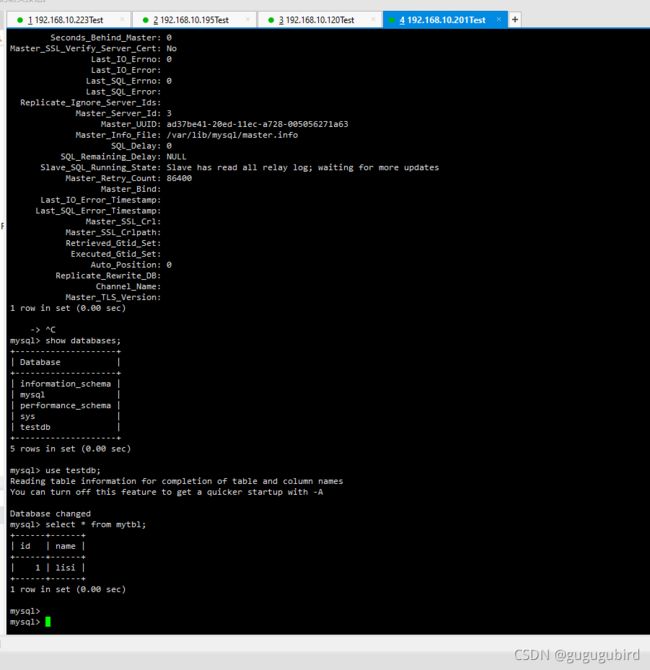
2.mycat实现双主双从,读写分离
修改mycat的vim schema.xml 配置文件
select user()
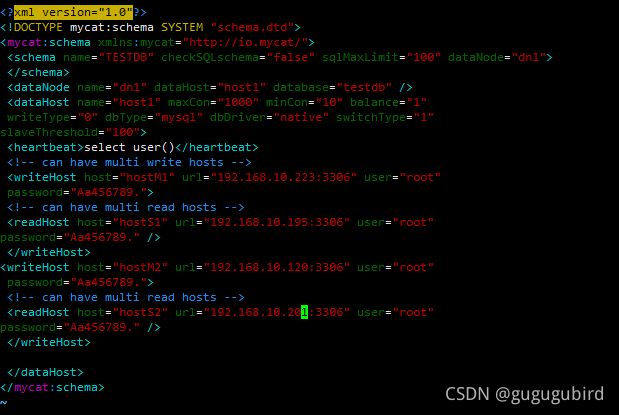
balance="1": 全部的readHost与stand by writeHost参与select语句的负载均衡。
writeType="0": 所有写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二个
writeType="1",所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐
writeHost,重新启动后以切换后的为准,切换记录在配置文件中:dnindex.properties 。
switchType="1": 1 默认值,自动切换。-1 表示不自动切换。2 基于 MySQL 主从同步的状态决定是否切换。
启动mycat ./mycat console
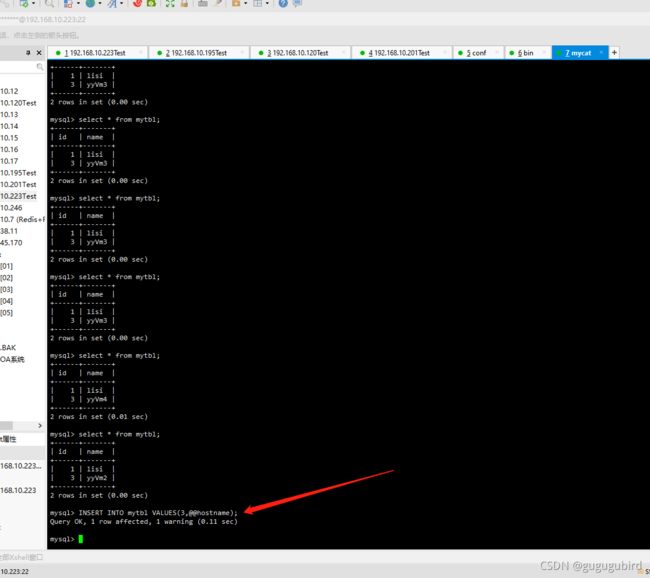
验证读写分离,在写主机Master1数据库表mytbl中插入带系统变量数据,
造成主从数据不一致
INSERT INTO mytbl VALUES(3,@@hostname);
查看3台从机的值
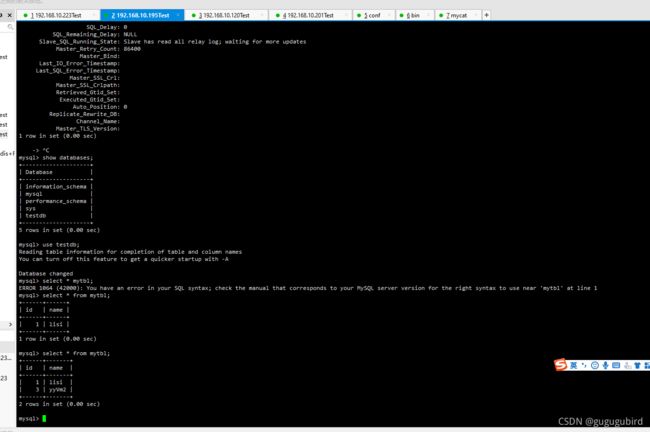
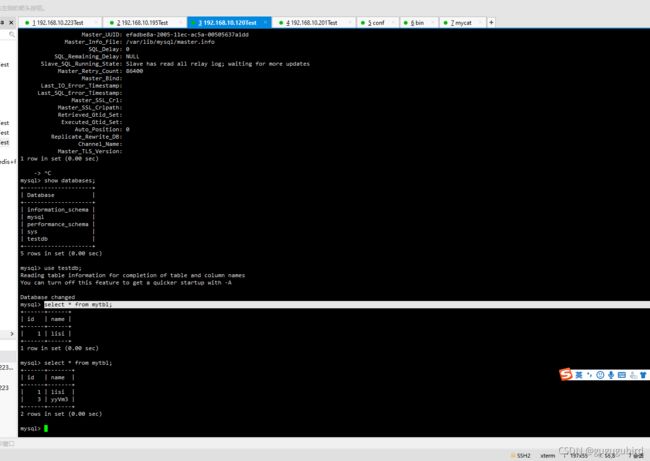
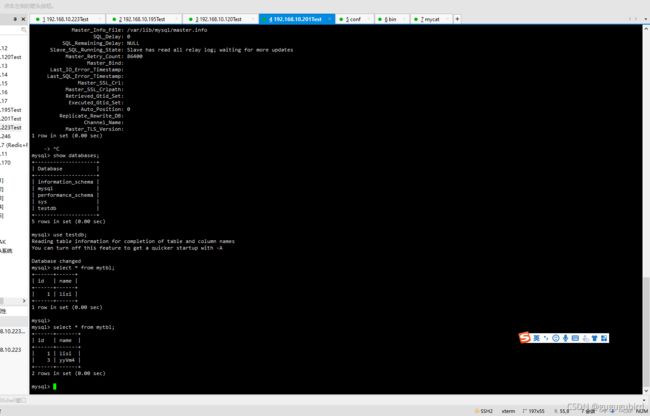
在Mycat里查询mytbl表
重新打开233虚拟机窗口,用mysql命令进入mycat
mysql -umycat -p123456 -h 192.168.10.223 -P8066;

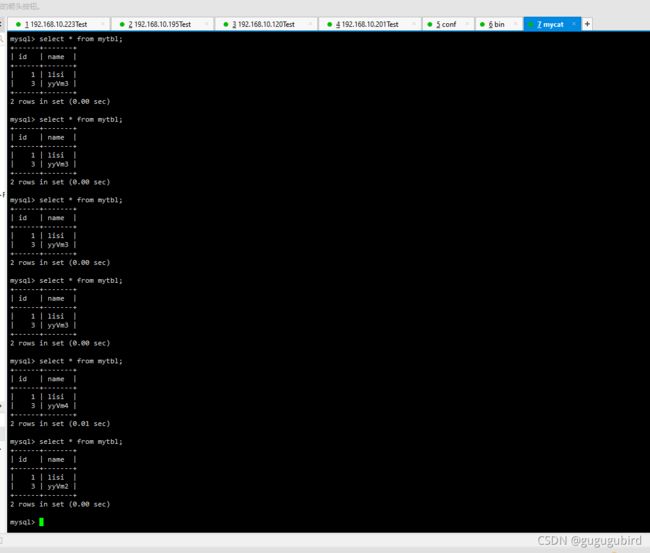
抗风险能力,停止数据库Master1
在Mycat里插入数据
INSERT INTO mytbl VALUES(3,@@hostname);
依然成功,Master2自动切换为写主机
启动数据库Master1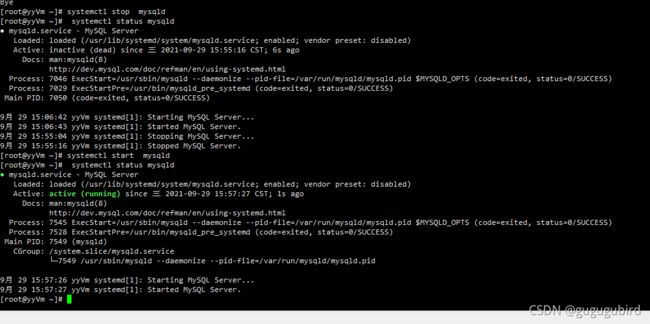
在Mycat里查询mytbl表,可以看到查询语句在Master1(yyVm)、
Slava1(yyVm2)、Slava2(yyVm4)查询从三个从机间切换
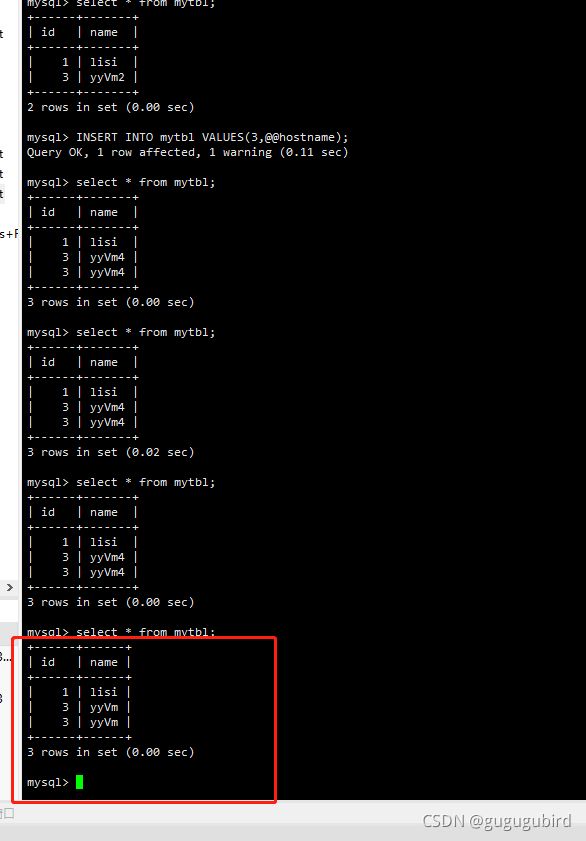
Master1、Master2 互做备机,负责写的主机宕机,备机
切换负责写操作,保证数据库读写分离高可用性。
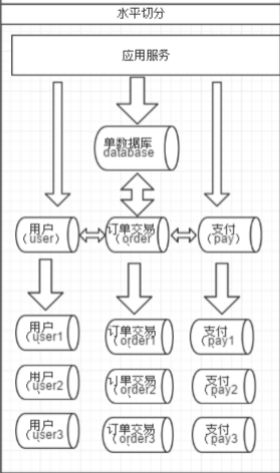
4.垂直拆分——分库
一个数据库由很多表的构成,每个表对应着不同的业务,
垂直切分是指按照业务将表进行分类,
分布到不同 的数据库上面,这样也就将数据或者说压力分担
到不同的库上面,如下图: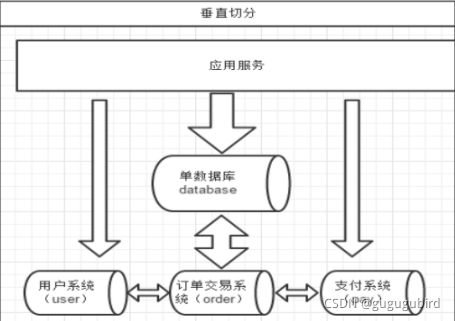
系统被切分成了,用户,订单交易,支付几个模块
一个问题:在两台主机上的两个数据库中的表,能否关联查询?
答案:不可以关联查询。
分库的原则:有紧密关联关系的表应该在一个库里,相互没有
关联关系的表可以分到不同的库里。
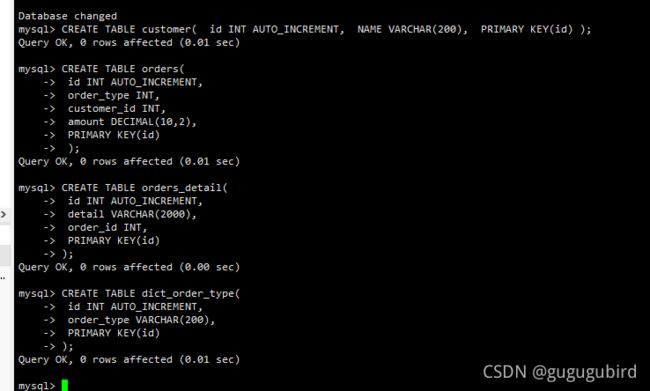
#客户表 rows:20万
CREATE TABLE customer(
id INT AUTO_INCREMENT,
NAME VARCHAR(200),
PRIMARY KEY(id)
);
#订单表 rows:600万
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
#订单详细表 rows:600万
CREATE TABLE orders_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
);
#订单状态字典表 rows:20
CREATE TABLE dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(200),
PRIMARY KEY(id)
);
以上四个表如何分库?客户表分在一个数据库,另外三张都 需要关联查询,分在另外一个数据库。
1.修改mycat的schema.xml文件
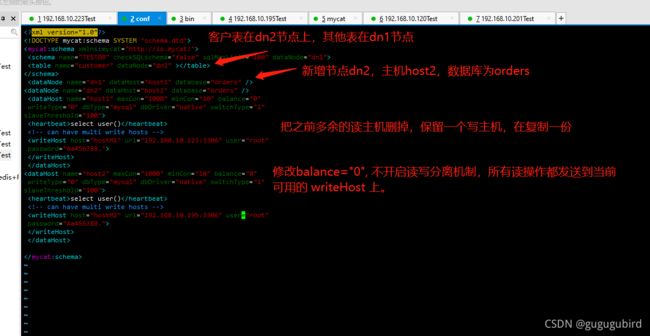
select user()
select user()
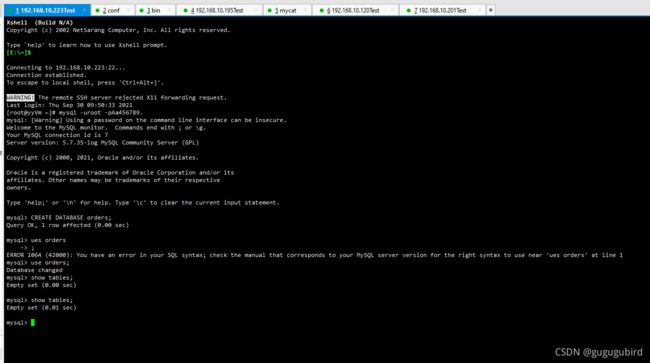
2.在223跟195上先创建数据库
CREATE DATABASE orders;
3.启动mycat
./mycat console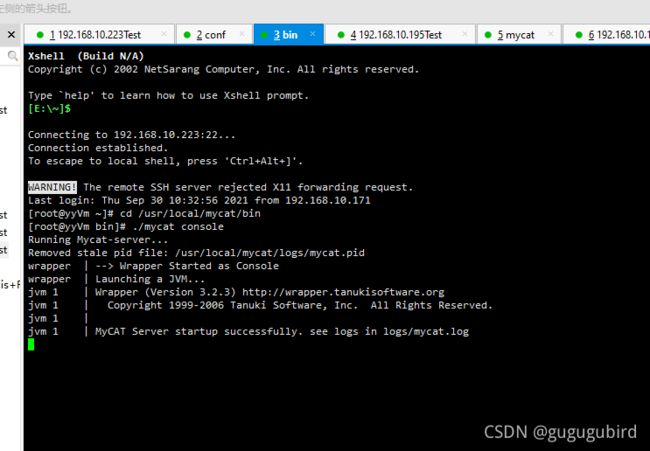
4. 访问 Mycat 进行分库
mysql -umycat -p123456 -h 192.168.140.128 -P 80665.创建客户表,并在223跟195上查看
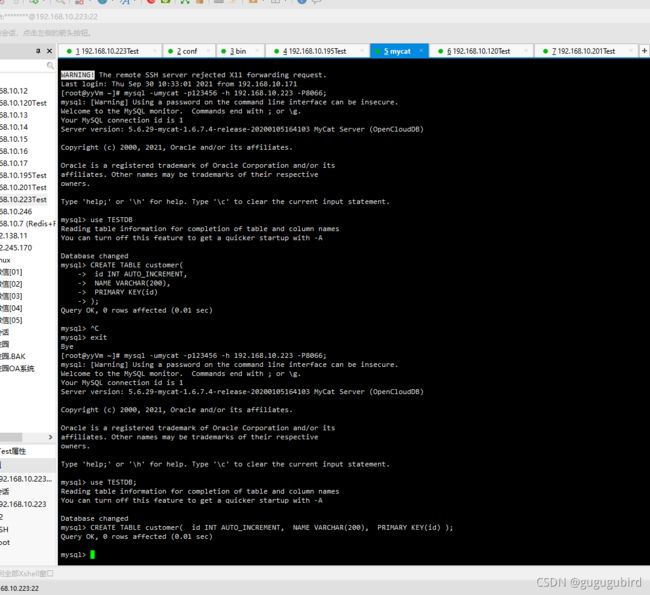
在223上查看
在195上看到已经有了

创建另外3张表查看效果

分库效果成功
5.水平拆分——分表
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的 某种规则来分散到多个库之中, 每个表中 包含一部分数据。简单来说,我们可以将数据的水平切 分理解为是按照数据行的切分,就 是将表中的某些行切分 到一个数据库,而另外的某些行又切分到 其他的数据库中,如图:
1.选择要拆分的表
MySQL 单表存储数据条数是有瓶颈的,单表达到 1000 万条数据就达到了瓶颈,会影响查询效率, 需要进行水平拆分(分表)进行优化。 例如:例子中的 orders、orders_detail 都已经达到 600 万行 数据,需要进行分表优化。
2.以 orders 表为例,可以根据不同自字段进行分表


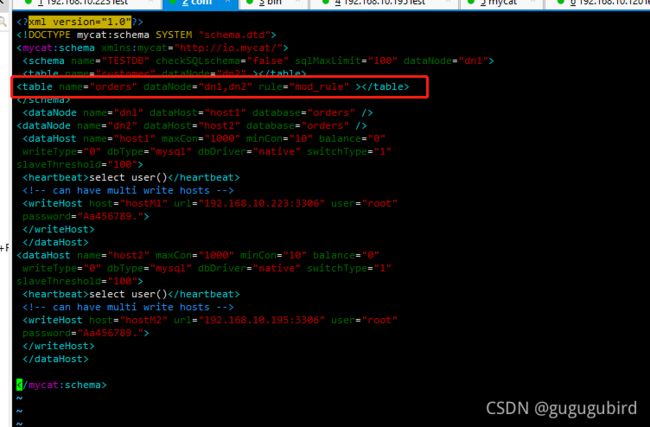
3.修改配置文件 schema.xml
#为 orders 表设置数据节点为
dn1、dn2,并指定分片规则 为 mod_rule(自定义的名字)
#如下图
4.修改rule.xml文件
customer_id
mod-long
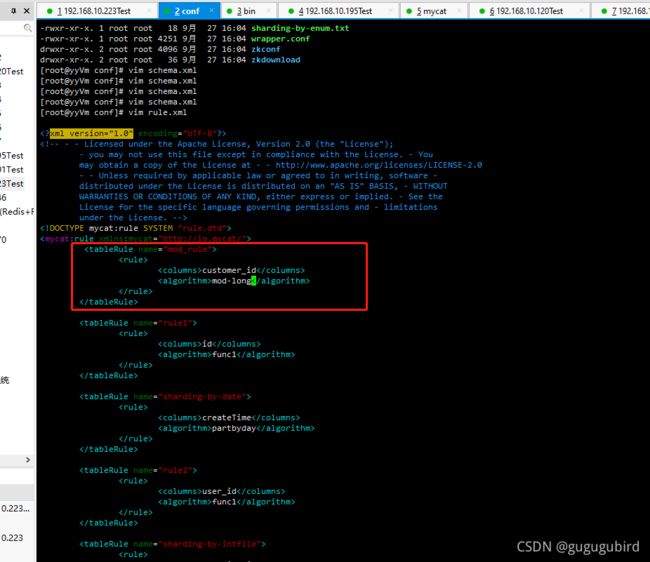
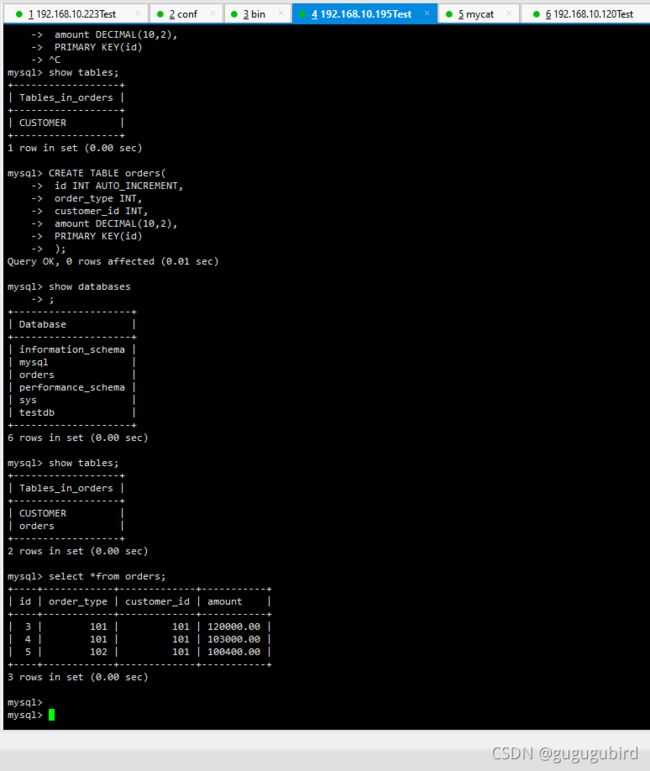
5. 在数据节点 dn2 上建 orders 表
6.重启 Mycat,让配置生效
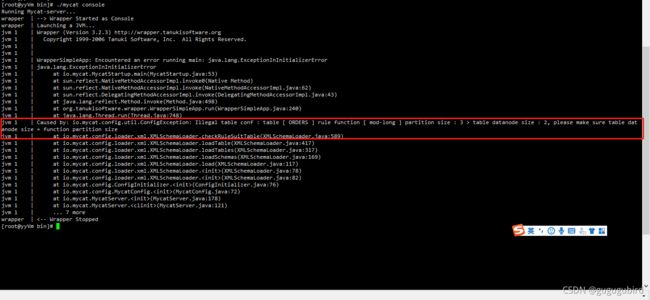
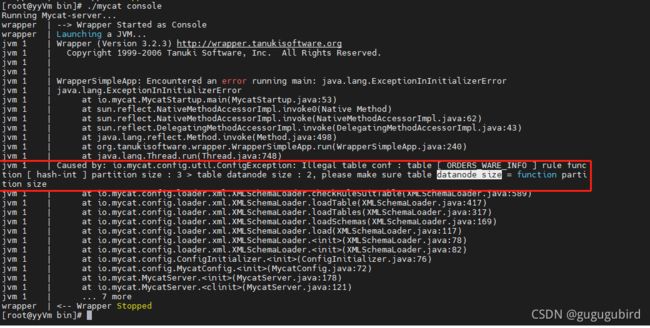
重启mycat报错,可以看到报错信息。在rule.xml文件中修改,mod-long下将name="count" 中3改为2即可,如图
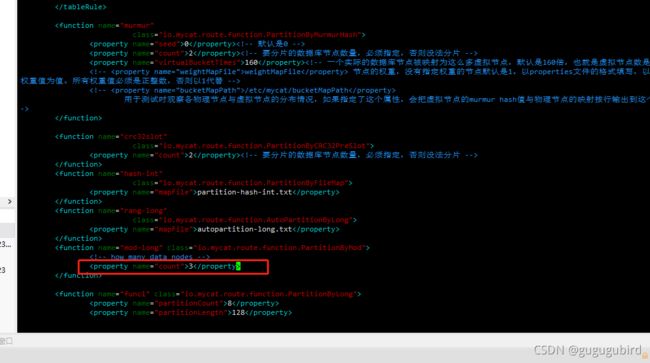

重启成功
7.访问 Mycat 实现分片
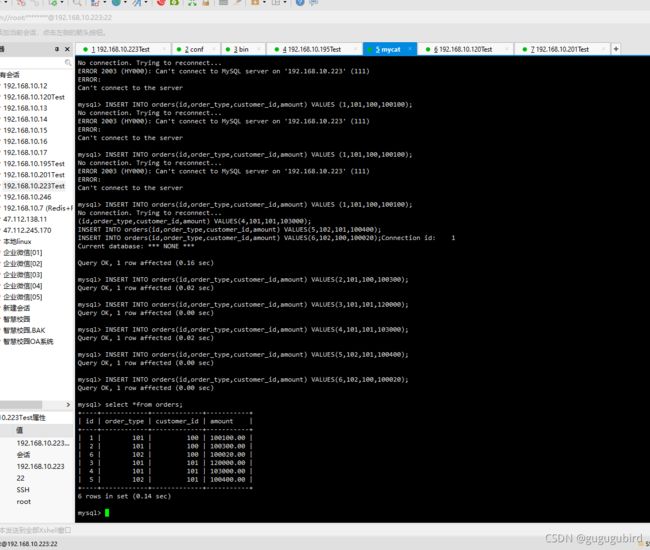
插入数据测试,在 mycat 里向 orders 表插入数据,INSERT 字段不能省略,因为我们根据customer_id进行的分片
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (1,101,100,100100);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(2,101,100,100300);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(3,101,101,120000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(4,101,101,103000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(5,102,101,100400);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(6,102,100,100020);
在mycat、dn1、dn2中查看orders表数据,分表成功
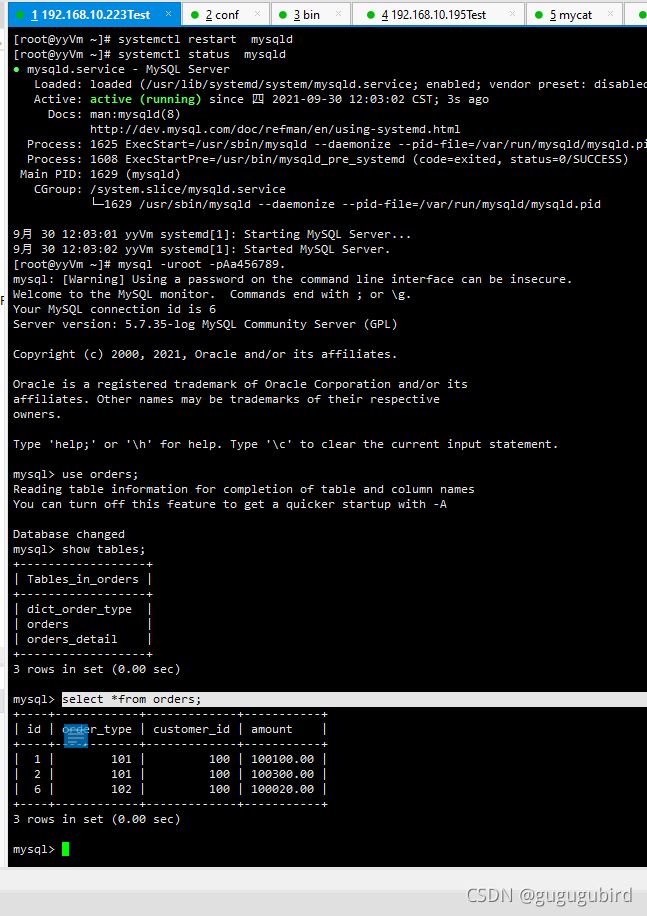
6.水平分表ER表
Orders 订单表已经进行分表操作了,和它关联的 orders_detail 订 单详情表如何进行 join 查询 我们要对 orders_detail 也要进行分片操作。Join 的原理如下图:

1.ER表
Mycat 借鉴了 NewSQL 领域的新秀 Foundation DB 的设计思路,Foundation DB 创新性的提出了 Table Group 的概念,其将子表的存储位置依赖于主表,并且物理上紧邻存放,因此彻底解决了JION 的效率和性能问 题,根据这一思路,提出了基于E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上。
2.修改schema.xml 配置文件
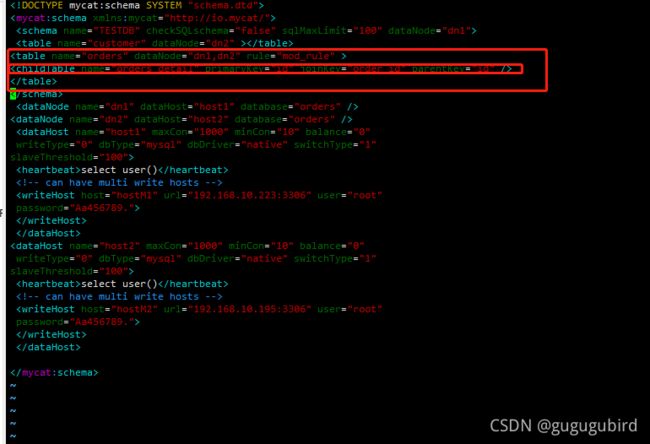
3.在 dn2 创建 orders_detail 表

4.重启mycat
5.访问 Mycat 向 orders_detail 表插入数据
INSERT INTO orders_detail(id,detail,order_id) values(1,'detail1',1);
INSERT INTO orders_detail(id,detail,order_id) VALUES(2,'detail1',2);
INSERT INTO orders_detail(id,detail,order_id) VALUES(3,'detail1',3);
INSERT INTO orders_detail(id,detail,order_id) VALUES(4,'detail1',4);
INSERT INTO orders_detail(id,detail,order_id) VALUES(5,'detail1',5);
INSERT INTO orders_detail(id,detail,order_id) VALUES(6,'detail1',6);
6.在mycat、dn1、dn2中运行两个表join语句查看效果
Select o.*,od.detail from orders o inner join orders_detail od on o.id=od.order_id;mycat

dn1
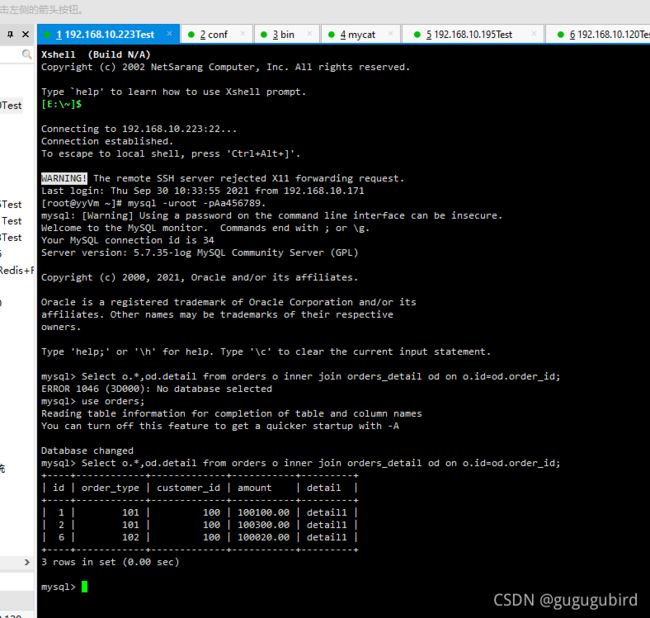
dn2

7.全局分表
在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较 棘手的问题,考虑到字典表具有以下几个特性:
1 变动不频繁
2 数据量总体变化不大
3数据规模不大,很少有超过数十万条记录
鉴于此,Mycat 定义了一种特殊的表,称之为“全局表”,全局表具有以下特性:
1 全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
2 全局表的查询操作,只从一个节点获取
3 全局表可以跟任何一个表进行 JOIN 操作
将字典表或者符合字典表特性的一些表定义为全局表,则从另外一个方面,很好的解决了数据JOIN 的难题。通过全局表+基于 E-R 关系的分片策略,Mycat 可以满足 80%以上的企业应用开发
1.修改schema.xml配置文件
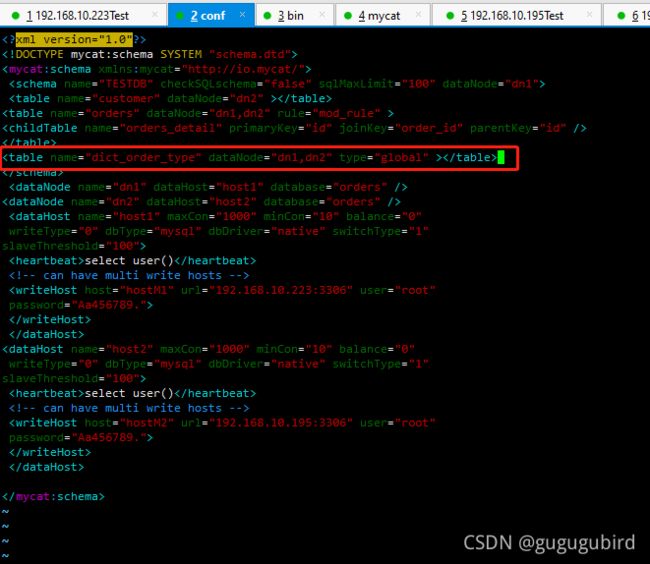
2.在 dn2 创建 dict_order_type 表
3.重启 Mycat
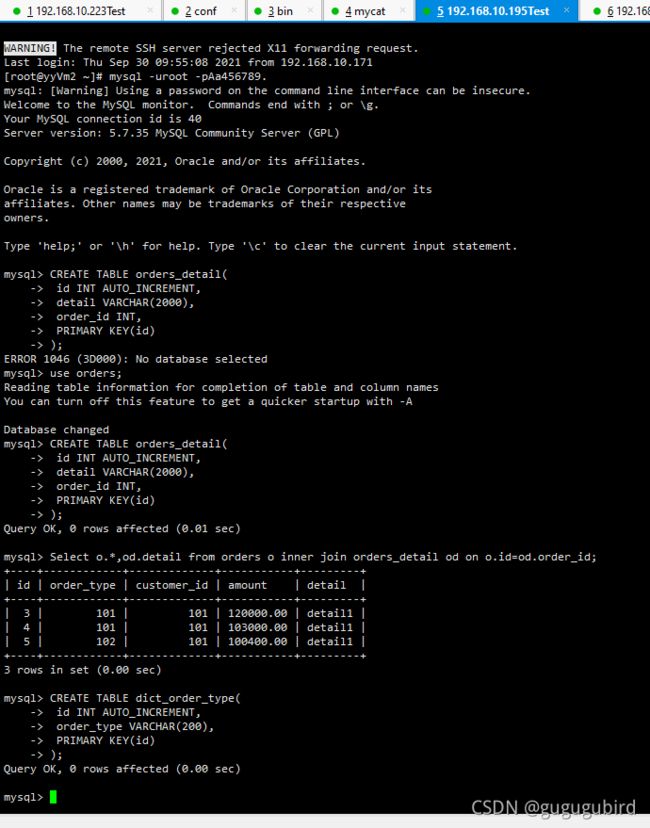
4.访问 Mycat 向 dict_order_type 表插入数据
INSERT INTO dict_order_type(id,order_type) VALUES(101,'type1');
INSERT INTO dict_order_type(id,order_type) VALUES(102,'type2');5.在Mycat、dn1、dn2中查询表数据 查看效果
select *from dict_order_type;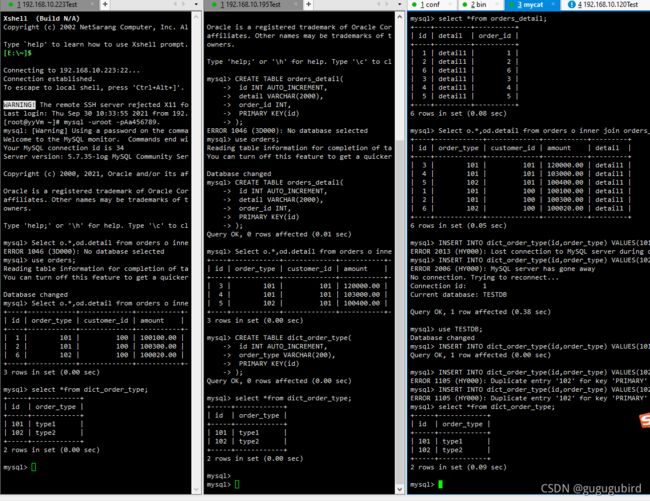
8.分表拓展——分片枚举
1.常用分片规则
取模:此规则为对分片字段求摸运算。也是水平分表最常用规则
分片枚举:通过在配置文件中配置可能的枚举 id,自己配置分片, 本规则适用于特定的场景,比如有些业务 需要按照省份或区县来做保存,而全国省份区县固定的, 这类业务使用本条规则。
2.修改schema.xml配置文件

3.修改rule.xml配置文件
areacode
hash-int
1
0
# columns:分片字段,algorithm:分片函数
# mapFile:标识配置文件名称,type:0为int型、非0为String,
#defaultNode:默认节点:小于 0 表示不设置默认节点,大于等于 0 表示设置默认节点,
# 设置默认节点如果碰到不识别的枚举值,就让它路由到默认节点,如不设置不识别就报错
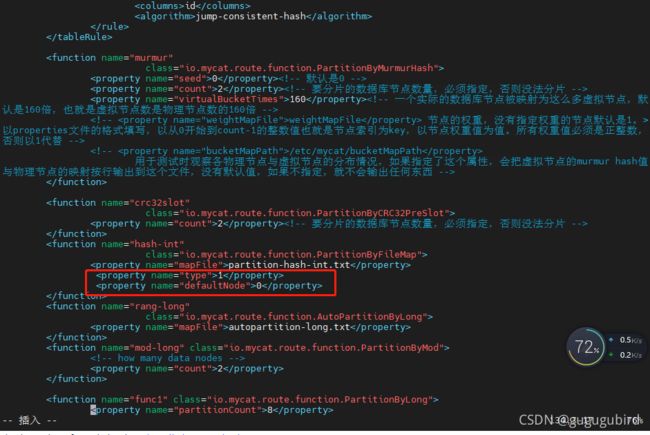
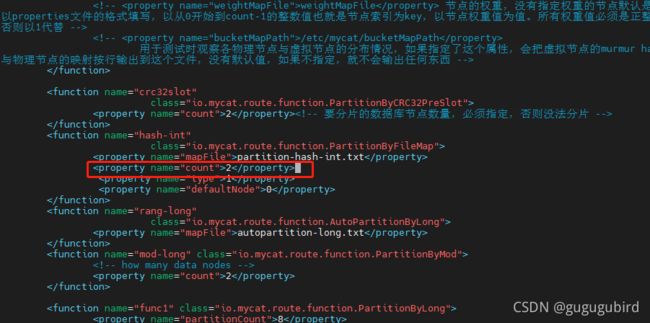
4.修改vim partition-hash-int.txt文件
110=0
120=1
5.重启mycat
报错,我因为
但是这里提示的是partition-size =3
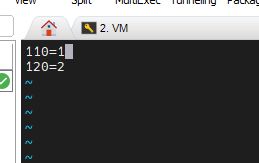
可以看到我这里的文件是从1开始,将其改为0跟1上边的代码是对的。

7.访问Mycat创建表
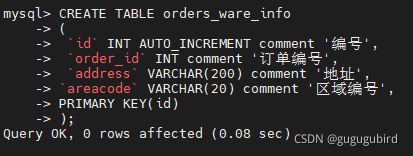
CREATE TABLE orders_ware_info
(
`id` INT AUTO_INCREMENT comment '编号',
`order_id` INT comment '订单编号',
`address` VARCHAR(200) comment '地址',
`areacode` VARCHAR(20) comment '区域编号',
PRIMARY KEY(id)
);
插入数据进行测试
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (1,1,"北京","110");
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (2,2,"天津","120");8.查询Mycat、dn1、dn2可以看到数据分片效果
![]()
插入数据时候报了乱码错误,
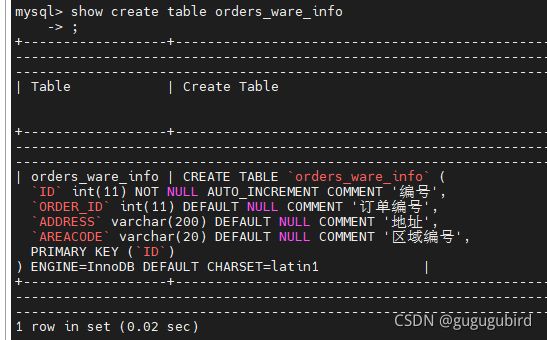
发现建表语句 latin1
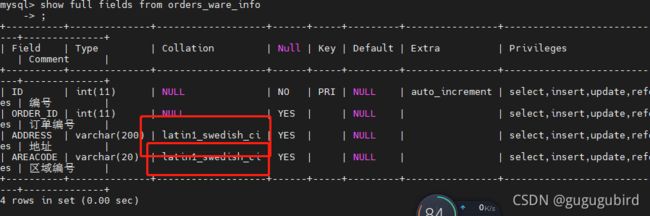
发现地址的Collation属性为latin1;
本人在mycat执行这些语句发现执行不了

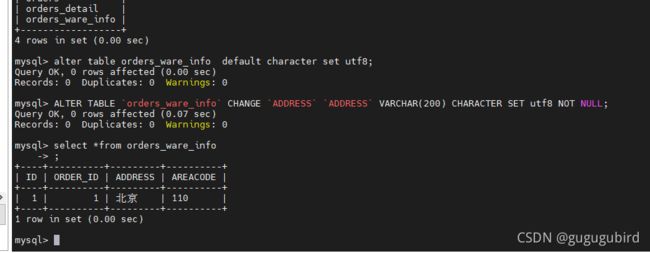
然后在223跟195的orders_ware_info表上修改字段编码
ALTER TABLE `orders_ware_info` CHANGE `ADDRESS` `ADDRESS` VARCHAR(200) CHARACTER SET utf8 NOT NULL;
然后在mycat上执行,成功。看效果

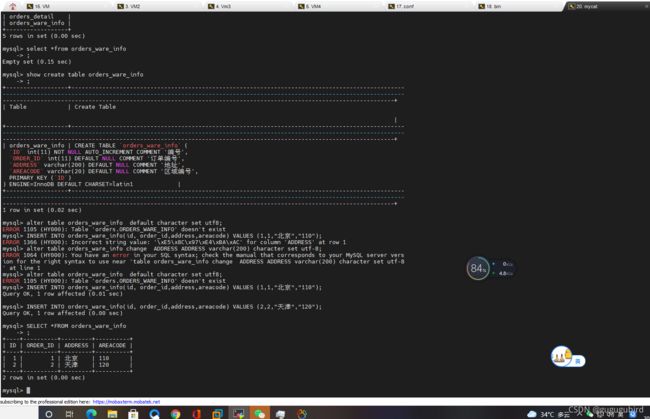
9.分表拓展-范围约定
此分片适用于,提前规划好分片字段某个范围属于哪个分片。
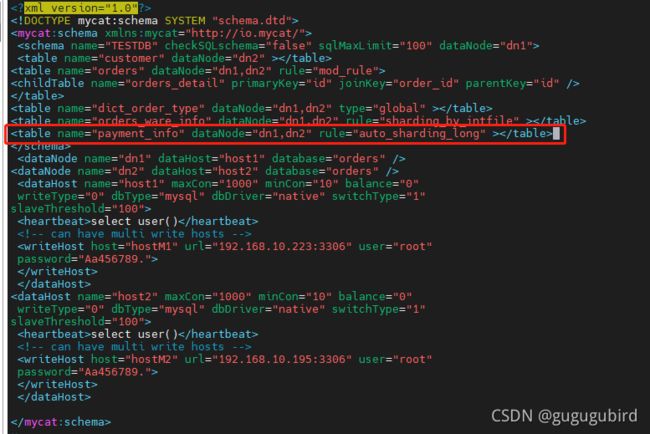
1.修改schema.xml文件
2.修改rule.xml配置文件
# columns:分片字段,algorithm:分片函数
# mapFile:标识配置文件名称
#defaultNode:默认节点:小于 0 表示不设置默认节点,大于等于 0 表示设置默认节点,
# 设置默认节点如果碰到不识别的枚举值,就让它路由到默认节点,如不设置不识别就
报错
order_id
rang-long
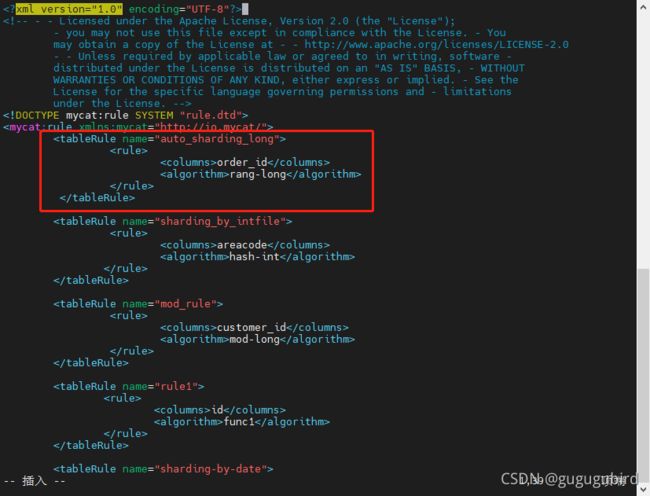
0 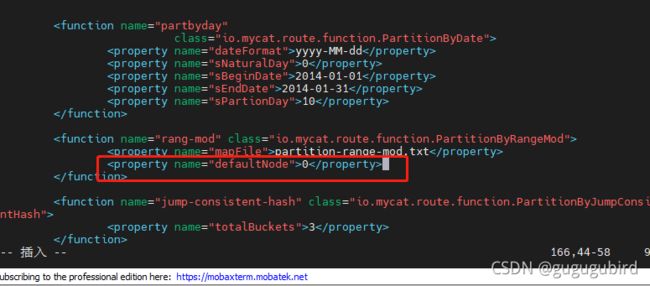
3. 修改autopartition-long.txt文件
0-102=0
103-200=1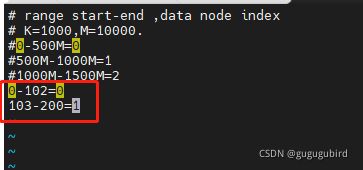
4.重启 Mycat
5.访问Mycat创建表
支付信息表
CREATE TABLE payment_info
(
`id` INT AUTO_INCREMENT comment '编号',
`order_id` INT comment '订单编号',
`payment_status` INT comment '支付状态',
PRIMARY KEY(id)
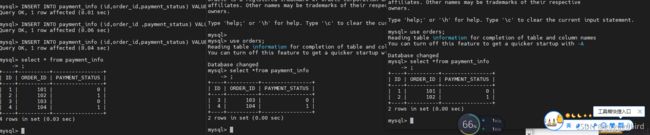
);6.插入数据,进行测试
INSERT INTO payment_info (id,order_id,payment_status) VALUES (1,101,0);
INSERT INTO payment_info (id,order_id,payment_status) VALUES (2,102,1);
INSERT INTO payment_info (id,order_id ,payment_status) VALUES (3,103,0);
INSERT INTO payment_info (id,order_id,payment_status) VALUES (4,104,1);
10.分表拓展——按日期分片
1.修改schema.xml文件
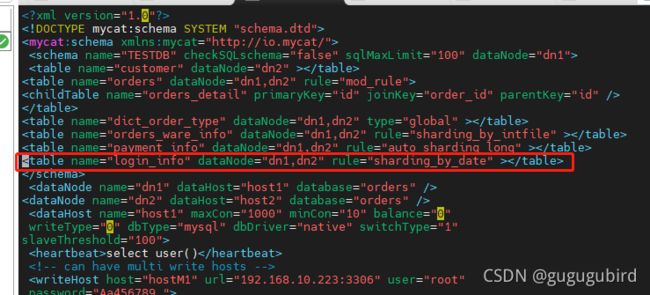
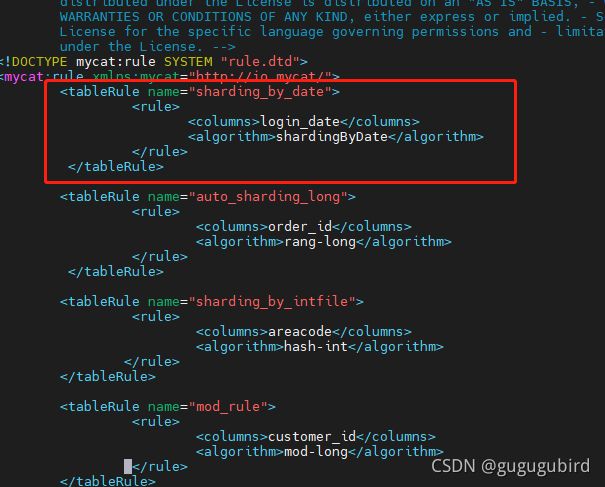
2.修改rule.xml配置文件
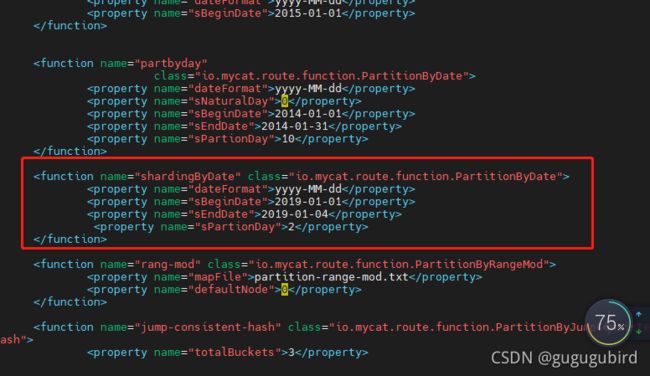
columns:分片字段,algorithm:分片函数
dateFormat :日期格式
sBeginDate :开始日期
sEndDate:结束日期,则代表数据达到了这个日期的分片后循环从开始分片插入
sPartionDay :分区天数,即默认从开始日期算起,分隔 2 天一个分区
login_date
shardingByDate
yyyy-MM-dd
2019-01-01
2019-01-04
2
3.重启 Mycat
4.访问Mycat创建表
#用户信息表
CREATE TABLE login_info
(
`id` INT AUTO_INCREMENT comment '编号',
`user_id` INT comment '用户编号',
`login_date` date comment '登录日期',
PRIMARY KEY(id)
);
5.插入数据,查看效果
INSERT INTO login_info(id,user_id,login_date) VALUES (1,101,'2019-01-01');
INSERT INTO login_info(id,user_id,login_date) VALUES (2,102,'2019-01-02');
INSERT INTO login_info(id,user_id,login_date) VALUES (3,103,'2019-01-03');
INSERT INTO login_info(id,user_id,login_date) VALUES (4,104,'2019-01-04');
INSERT INTO login_info(id,user_id,login_date) VALUES (5,103,'2019-01-05');
INSERT INTO login_info(id,user_id,login_date) VALUES (6,104,'2019-01-06');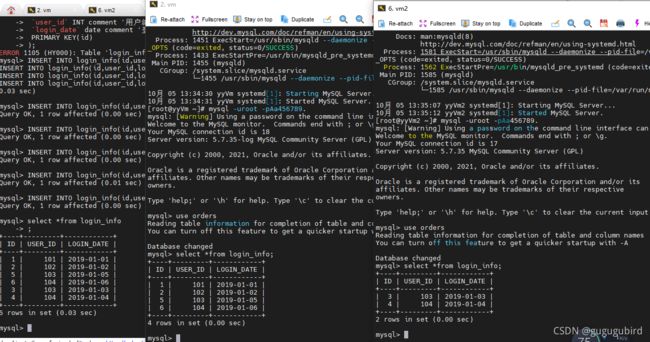
11.分表拓展——全局序列
在实现分库分表的情况下,数据库自增主键已无法保证自增主键的全局唯一。为此,Mycat 提供 了全局 sequence,并且提供了包含本地配置和数据库配置等多种实现方式。
实现全局序列方式:
方式一:本地文件
此方式 Mycat 将 sequence 配置到文件中,当使用到 sequence 中的配置后,Mycat 会更下
classpath 中的 sequence_conf.properties 文件中 sequence 当前的值。
① 优点:本地加载,读取速度较快
② 缺点:抗风险能力差,Mycat 所在主机宕机后,无法读取本地文件。
方式二:数据库方式(推荐这种方式)
2、 数据库方式 利用数据库一个表 来进行计数累加。但是并不是每次生成序列都读写数据库,这样效率太低。 Mycat 会预加载一部分号段到 Mycat 的内存中,这样大部分读写序列都是在内存中完成的。 如果内存中的号段用完了 Mycat 会再向数据库要一次。
问:那如果 Mycat 崩溃了 ,那内存中的序列岂不是都没了? 是的。如果是这样,那么 Mycat 启动后会向数据库申请新的号段,原有号段会弃用。 也就是说如果 Mycat 重启,那么损失是当前的号段没用完的号码,但是不会因此出现主键重复
方式三:时间戳
时间戳方式 全局序列ID= 64 位二进制 (42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加) 换算成十进制为 18 位数的 long 类型,每毫秒可以并发 12 位二进制的累加。
1 优点:配置简单
2 缺点:18 位 ID 过长
方式四:自主生成全局序列
自主生成全局序列 可在 java 项目里自己生成全局序列,如下:
1 根据业务逻辑组合
2 可以利用 redis 的单线程原子性 incr 来生成序列 但,自主生成需要单独在工程中用 java 代码实现,还是推 荐使用 Mycat 自带全局序列。
1.在dn1上创建表
CREATE TABLE MYCAT_SEQUENCE (
NAME VARCHAR(50) NOT NULL,
current_value INT NOT NULL,
increment INT NOT NULL DEFAULT 100,
PRIMARY KEY(NAME)
) ENGINE=INNODB;
2.创建全局序列所需函数
DELIMITER $$
CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
DECLARE retval VARCHAR(64);
SET retval="-999999999,null";
SELECT CONCAT(CAST(current_value AS CHAR),",",CAST(increment AS CHAR)) INTO retval FROM
MYCAT_SEQUENCE WHERE NAME = seq_name;
RETURN retval;
END $$
DELIMITER;
DELIMITER $$
CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),VALUE INTEGER) RETURNS
VARCHAR(64)
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = VALUE
WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END $$
DELIMITER;
DELIMITER $$
CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END $$
DELIMITER;
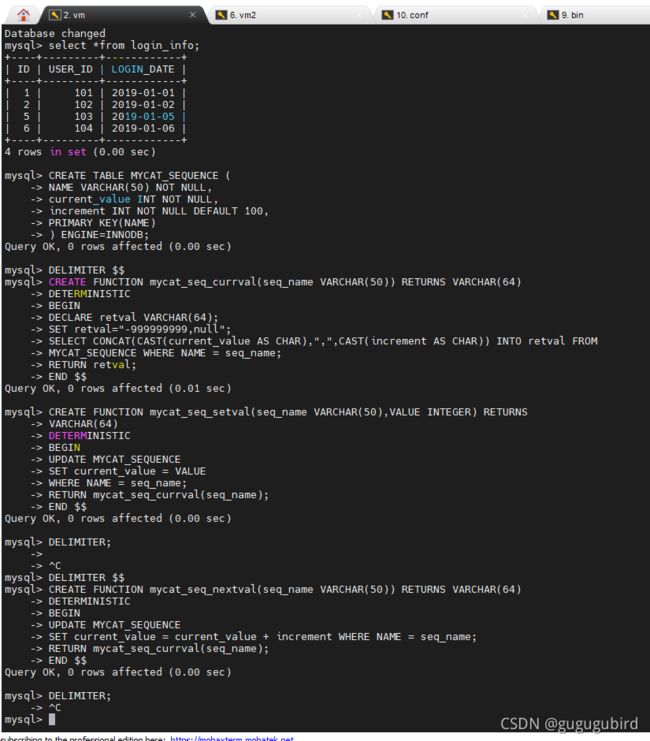
3.初始化序列表记录
INSERT INTO MYCAT_SEQUENCE(NAME,current_value,increment) VALUES ('ORDERS', 400000,
100);
4.修改mycat配置,sequence_db_conf.properties文件
意思是 ORDERS这个序列在dn1这个节点上
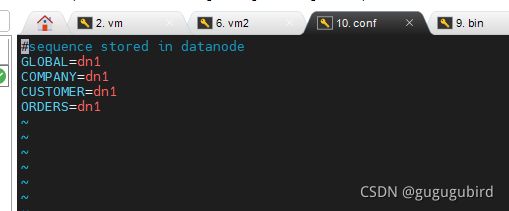
5.修改server.xml
将system标签下的改为
1
全局序列类型:0-本地文件,1-数据库方式,2-时间戳方式。此处应该修改成1。
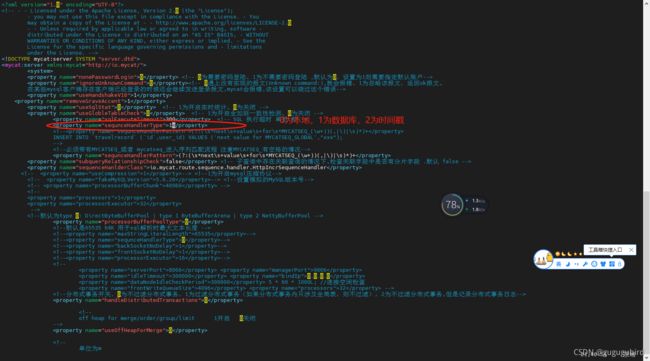
6.重启Mycat
7.插入数据,验证全局序列
insert into orders(id,amount,customer_id,order_type) values(next value for
MYCATSEQ_ORDERS,1000,101,102);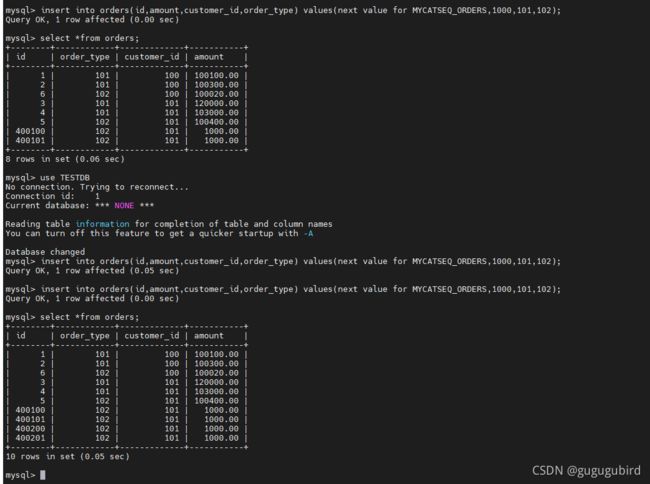
三.基于 HA 机制的 Mycat 高可用
在实际项目中,Mycat 服务也需要考虑高可用性,如果 Mycat 所在服务器出现宕机,或 Mycat 服 务故障,需要有备机提供服务,需要考虑 Mycat 集群。
高可用方案:
我们可以使用 HAProxy + Keepalived 配合两台 Mycat 搭起 Mycat 集群,实现高可用性。HAProxy 实现了 MyCat 多节点的集群高可用和负载均衡, 而 HAProxy 自身的高可用则可以通过 Keepalived 来 实现。
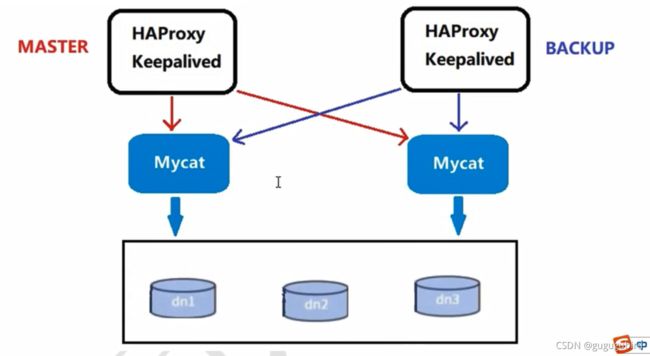
| 编号 | 角色 | IP地址 | 机器名 |
| 1 | mycat1 | 192.168.10.223 | yyvm |
| 2 | mycat2 | 192.168.10.120 | yyvm3 |
| 3 | Haproxy(master) | 192.168.10.195 | yyvm2 |
| 4 | Keepalived(master) | 192.168.10.195 | yyvm2 |
| 5 | Haproxy(backup) | 192.168.10.201 | yyvm4 |
| 6 | Keepalived(backup) | 192.168.10.201 | yyvm4 |
1.安装配置 HAProxy
HAProxy - The Reliable, High Performance TCP/HTTP Load Balancer (官方网站)
https://www.haproxy.org/download/1.8/src/haproxy-1.8.14.tar.gz (下载地址)
HAProxy version 1.8.30 - Configuration Manual (文档Haproxy 1.8 文档)
1.准备好HAProxy安装包,传到/opt目录下(2台用到haproxy都需要)
2.解压到/usr/local/src
tar -zxvf haproxy-1.8.14.tar.gz -C /usr/local/src
3.进入解压后的目录,查看内核版本,进行编译
查看内核版本
uname -r
进行编译
ARGET=linux310,内核版本,使用uname -r查看内核,
如:3.10.0-514.el7,此时该参数就为linux310; #ARCH=x86_64,系统位数;
make TARGET=linux310 PREFIX=/usr/local/haproxy ARCH=x86_64
4.编译完成后,进行安装
make install PREFIX=/usr/local/haproxy
5.安装完成后,创建目录、创建HAProxy配置文件
mkdir -p /usr/data/haproxy/vim /usr/local/haproxy/haproxy.conf6.向配置文件中插入以下配置信息,并保存
global # 全局参数的设置
log 127.0.0.1 local0 info
# log语法:log [max_level_1] # 全局的日志配置,使用log关键字,指定使用127.0.0.1上的syslog服务中的local0日志设备,记录日志等级为info的日志
user haproxy
group haproxy
# 设置运行haproxy的用户和组,也可使用uid,gid关键字替代之
daemon
# 以守护进程的方式运行
nbproc 16
# 设置haproxy启动时的进程数,根据官方文档的解释,我将其理解为:该值的设置应该和服务器的CPU核心数一致,即常见的2颗8核心CPU的服务器,即共有16核心,则可以将其值设置为:<=16 ,创建多个进程数,可以减少每个进程的任务队列,但是过多的进程数也可能会导致进程的崩溃。这里我设置为16
maxconn 4096
# 定义每个haproxy进程的最大连接数 ,由于每个连接包括一个客户端和一个服务器端,所以单个进程的TCP会话最大数目将是该值的两倍。
#ulimit -n 65536
# 设置最大打开的文件描述符数,在1.4的官方文档中提示,该值会自动计算,所以不建议进行设置
pidfile /var/run/haproxy.pid
# 定义haproxy的pid
defaults # 默认部分的定义
mode http
# mode语法:mode {http|tcp|health} 。http是七层模式,tcp是四层模式,health是健康检测,返回OK
log 127.0.0.1 local3 err
# 使用127.0.0.1上的syslog服务的local3设备记录错误信息
retries 3
# 定义连接后端服务器的失败重连次数,连接失败次数超过此值后将会将对应后端服务器标记为不可用
option httplog
# 启用日志记录HTTP请求,默认haproxy日志记录是不记录HTTP请求的,只记录“时间[Jan 5 13:23:46] 日志服务器[127.0.0.1] 实例名已经pid[haproxy[25218]] 信息[Proxy http_80_in stopped.]”,日志格式很简单。
option redispatch
# 当使用了cookie时,haproxy将会将其请求的后端服务器的serverID插入到cookie中,以保证会话的SESSION持久性;而此时,如果后端的服务器宕掉了,但是客户端的cookie是不会刷新的,如果设置此参数,将会将客户的请求强制定向到另外一个后端server上,以保证服务的正常。
option abortonclose
# 当服务器负载很高的时候,自动结束掉当前队列处理比较久的链接
option dontlognull
# 启用该项,日志中将不会记录空连接。所谓空连接就是在上游的负载均衡器或者监控系统为了探测该服务是否存活可用时,需要定期的连接或者获取某一固定的组件或页面,或者探测扫描端口是否在监听或开放等动作被称为空连接;官方文档中标注,如果该服务上游没有其他的负载均衡器的话,建议不要使用该参数,因为互联网上的恶意扫描或其他动作就不会被记录下来
option httpclose
# 这个参数我是这样理解的:使用该参数,每处理完一个request时,haproxy都会去检查http头中的Connection的值,如果该值不是close,haproxy将会将其删除,如果该值为空将会添加为:Connection: close。使每个客户端和服务器端在完成一次传输后都会主动关闭TCP连接。与该参数类似的另外一个参数是“option forceclose”,该参数的作用是强制关闭对外的服务通道,因为有的服务器端收到Connection: close时,也不会自动关闭TCP连接,如果客户端也不关闭,连接就会一直处于打开,直到超时。
contimeout 5000
# 设置成功连接到一台服务器的最长等待时间,默认单位是毫秒,新版本的haproxy使用timeout connect替代,该参数向后兼容
clitimeout 3000
# 设置连接客户端发送数据时的成功连接最长等待时间,默认单位是毫秒,新版本haproxy使用timeout client替代。该参数向后兼容
srvtimeout 3000
# 设置服务器端回应客户度数据发送的最长等待时间,默认单位是毫秒,新版本haproxy使用timeout server替代。该参数向后兼容
listen status # 定义一个名为status的部分
bind 0.0.0.0:1080
# 定义监听的套接字
mode http
# 定义为HTTP模式
log global
# 继承global中log的定义
stats refresh 30s
# stats是haproxy的一个统计页面的套接字,该参数设置统计页面的刷新间隔为30s
stats uri /admin?stats
# 设置统计页面的uri为/admin?stats
stats realm Private lands
# 设置统计页面认证时的提示内容
stats auth admin:password
# 设置统计页面认证的用户和密码,如果要设置多个,另起一行写入即可
stats hide-version
# 隐藏统计页面上的haproxy版本信息
frontend http_80_in # 定义一个名为http_80_in的前端部分
bind 0.0.0.0:80
# http_80_in定义前端部分监听的套接字
mode http
# 定义为HTTP模式
log global
# 继承global中log的定义
option forwardfor
# 启用X-Forwarded-For,在requests头部插入客户端IP发送给后端的server,使后端server获取到客户端的真实IP
acl static_down nbsrv(static_server) lt 1
# 定义一个名叫static_down的acl,当backend static_sever中存活机器数小于1时会被匹配到
acl php_web url_reg /*.php$
#acl php_web path_end .php
# 定义一个名叫php_web的acl,当请求的url末尾是以.php结尾的,将会被匹配到,上面两种写法任选其一
acl static_web url_reg /*.(css|jpg|png|jpeg|js|gif)$
#acl static_web path_end .gif .png .jpg .css .js .jpeg
# 定义一个名叫static_web的acl,当请求的url末尾是以.css、.jpg、.png、.jpeg、.js、.gif结尾的,将会被匹配到,上面两种写法任选其一
use_backend php_server if static_down
# 如果满足策略static_down时,就将请求交予backend php_server
use_backend php_server if php_web
# 如果满足策略php_web时,就将请求交予backend php_server
use_backend static_server if static_web
# 如果满足策略static_web时,就将请求交予backend static_server
backend php_server #定义一个名为php_server的后端部分
mode http
# 设置为http模式
balance source
# 设置haproxy的调度算法为源地址hash
cookie SERVERID
# 允许向cookie插入SERVERID,每台服务器的SERVERID可在下面使用cookie关键字定义
option httpchk GET /test/index.php
# 开启对后端服务器的健康检测,通过GET /test/index.php来判断后端服务器的健康情况
server php_server_1 10.12.25.68:80 cookie 1 check inter 2000 rise 3 fall 3 weight 2
server php_server_2 10.12.25.72:80 cookie 2 check inter 2000 rise 3 fall 3 weight 1
server php_server_bak 10.12.25.79:80 cookie 3 check inter 1500 rise 3 fall 3 backup
# server语法:server [:port] [param*] # 使用server关键字来设置后端服务器;为后端服务器所设置的内部名称[php_server_1],该名称将会呈现在日志或警报中、后端服务器的IP地址,支持端口映射[10.12.25.68:80]、指定该服务器的SERVERID为1[cookie 1]、接受健康监测[check]、监测的间隔时长,单位毫秒[inter 2000]、监测正常多少次后被认为后端服务器是可用的[rise 3]、监测失败多少次后被认为后端服务器是不可用的[fall 3]、分发的权重[weight 2]、最后为备份用的后端服务器,当正常的服务器全部都宕机后,才会启用备份服务器[backup]
backend static_server
mode http
option httpchk GET /test/index.html
server static_server_1 10.12.25.83:80 cookie 3 check inter 2000 rise 3 fall 3
global
log 127.0.0.1 local0
#log 127.0.0.1 local1 notice
#log loghost local0 info
maxconn 4096
chroot /usr/local/haproxy
pidfile /usr/data/haproxy/haproxy.pid
uid 99
gid 99
daemon
#debug
#quiet
defaults
log global
mode tcp
option abortonclose
option redispatch
retries 3
maxconn 2000
timeout connect 5000
timeout client 50000
timeout server 50000
listen proxy_status
bind :48066
mode tcp
balance roundrobin
server mycat_1 192.168.10.223:8066 check inter 10s
server mycat_2 192.168.10.120:8066 check inter 10s
frontend admin_stats
bind :7777
mode http
stats enable
option httplog
maxconn 10
stats refresh 30s
stats uri /admin
stats auth admin:123123
stats hide-version
stats admin if TRUE
7.启动验证
/usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/haproxy.conf
8.查看HAProxy进程
ps -ef|grep haproxy

9.打开浏览器访问
http://192.168.10.195:7777/admin 在弹出框输入用户名:admin密码:123123

10.验证负载均衡,通过HAProxy访问Mycat
mysql -umycat -p123456 -h 192.168.10.195 -P 48066