Oracle SQL 性能优化规范
- SQL 优化总览
1.1.优化中心思想
SQL 优化的中心思想有两点:
1、 少做甚至不做。
少做事情,甚至对不必要的事情干脆不做,自然就能使 SQL 提高效率。
使用索引来减少数据扫描就是少做事思想的最普遍、最形象的运用场景。
2、 集中资源做一件事情。
同样的工作量,相比一个人做,大家一起做自然就快了。并行操作就属于这种情形。
1.2.性能优化两大法宝
在我们看来,意识和技能正是优化的两大法宝(意识和技能)。
意识就是善于思考,善于发现,多问几个能不能。例如怎样才能少做事? 哪些操作是不必要的? 应
用性能还能不能快一点? 服务器能不能少多一点? 用户的真实需求是什么?
很多时候,优化更多是意识方面的,无需任何优化技能就能实现的。
技能指掌握性能优化的基本知识,这些是我们优化时的手段和工具,包括索引、表连接、分区表和数
据库原理等。只有掌握了这些技能,在遇到问题时,我们才能使用这些手段去解决问题。技能是性能优化
时不可或缺的。
2 - 索引介绍
索引对我们来说并不陌生,接触过数据库的开发人员基本都创建过索引。但是,了解索引原理,能创 建好索引的开发人员并不多见。 下面将从介绍索引的原理、特点以及创建最佳索引的方法。
2.1.索引结构图
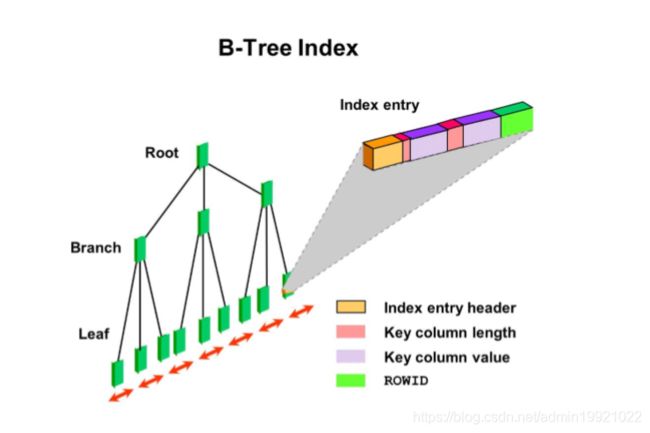
索引就是为了快速查找表中记录所创建的一种特殊数据结构。索引块中包含字段的值和指向对应行的
地址——rowid。
下面通过示例来介绍一下为什么索引会提升 SQL 的执行效率:
1、当执行 select * from t1 where id = 10000 这样的语句时,如果 id 字段上创建了索引,并且 id
字段中的唯一值较多时,SQL 优化器会判断选择走索引。
2、走索引的话,会代入 10000 去索引中匹配,经过根节点、枝干节点,找到叶子节点中对应的 id 字
段值为 10000 的索引项,读取索引项中行记录的地址信息,即 rowid。
3
3、接下来通过 rowid 直接读取表中的行记录,如果 where 后边还有其他条件,将会对行记录进行校验,
并返回最终符合条件的行记录。
如果 id 字段上没有索引,那么 SQL 将如何执行呢?
如果 id 字段上没有索引,那么 SQL 只能选择全表扫描,对表中的所有数据进行过滤,并返回最终符合
条件的行记录。 随着表中数据量的增长,全表扫描所消耗的资源将会越来越多,SQL 执行时间会越来越长。
2.2.索引三大特征
由索引结构图中,我们可以得出索引的三大特征,并借助这三大特征对 SQL 进行优化。
高度较低(可快速定位)
通过索引,小表查询与大表查询性能差异很小。
存储列值(可优化聚合)
count, sum/avg, max/min, 多列索引避免回表
有序(可优化排序)
order by, max/min, union, distinct
2.3.索引用途
快速定位 存储列值,可进行列值的聚合操作,如 count,sum,avg。 避免排序 覆盖索引可直接返回结果,无需回表扫描数据 唯一索引可实现唯一约束
4
2.4.索引查询示例图

2.5.如何理解索引
怎么理解索引呢? 想想新华字典中的拼音索引或部首索引就能理解了。
部首索引中会主要记录了两类信息,即部首和部首出现的页数。同样的,数据库中索引也会记录被索
引字段的值和该值在表中出现的位置。
当我们查找一个不认识的字的时候,我们使用部首索引就可以快速查找到我们要找的文字,而不用将
整个字典从头翻到尾一页一页的找。
新华字典中文字部分可以理解成表,为了快速查找到要找的文字,创建了部首索引。 我们要快速的从
表中找到想要的记录,也同样的需要创建索引。
因为在索引中,数据是有序的,使用索引可以快速的定位到我们要查找的内容。然后通过索引中的 rowid
(可以理解成数据存储的物理位置), 也就可以直接去表中读取数据了。
创建索引时,一般会在 where 条件后的字段上创建索引, 这样就可以通过索引快速查找到相应的记录
了。
5
但是,假如通过查询条件查找到的记录较多,那么,索引效率就不会高。 对于这种情况,就不应该创
建索引了。
与索引查找相对应的是全表扫描,下面就将全表扫描和索引查找的概念简单介绍一下:
全表扫描:全表扫描是数据库服务器用来搜寻表的每一条记录(表中的行)的过程,直到所有符合给定
条件的记录返回为止。因为只有把全表所有记录从头到尾找一个遍,才能确定满足查询条件的记录全被找
到。
全表扫描的一般使用场景:
1、表上没有索引。
2、由于满足查询条件的记录较多,导致使用索引效率也不会高, 这时也会选择全表扫描。
3、对表执行全记录操作,例如没有条件限制的查询表中所有记录,没有条件限制的排序或聚合(groupby,
sum,count) 操作等。
以上场景中,2 和 3 是无法避免的, 也是不应该避免的。 因为在这种情况下,全表扫描相比索引查
询性能会好。
索引扫描:在只需要查询表中少量记录的时候,使用索引扫描效率会高。 因为索引结构的特殊性,通
过索引可以快速定位到要查找的记录,而不用将整个表从头找到尾。
索引的真正意义:索引是优化器在制定执行计划时,为了寻找最优化的路径而使用的战略要素。假如
表上没有索引,那优化器就只能选择全表扫描的执行计划。
2.6.字段可选性
字段值去重之后的个数多的话,称之为可选性高,如:主键、身份证号。 否则,称之为可选性低, 如:性别、状态等。
只有可选性高的字段创建索引才有意义。 或者多个字段的组合可选性高创建组合索引才有意义。
2.7.索引的开销
索引虽然可以帮着我们快速查找记录,但是,索引也是有成本的。
当表中插入、删除记录和更新索引字段的记录时,数据库就会自动维护到索引中,这部分开销是不容
6
忽视的。 随着表上索引个数的增多,索引维护开销对性能的影响会越来越明显。 因此,索引不能盲目的
创建,只有切实发挥有益作用的索引才值得创建。
正因为如此,我们才强调,创建索引要从全局综合性考虑绝大部分 SQL 的数据访问需求,创建战略性
索引,用尽量少的索引来满足绝大部分 SQL 的性能需求。
2.8.索引创建原则
单列索引创建原则:
1、 查询条件中的经常使用列
2、 列的离散度要高或可选性好,即该列的唯一值较多。
3、 通过索引只查询很少一部分数据,小于 5%(这个只是一个大概值)。
4、 查询条件不能是 <>。
复合索引创建原则:(重要程度依据序号所示)
1、是否经常被使用?
2、是否经常为列使用“=”比较查询条件?
3、哪个列具有更好的离散度?
4、经常按照何种顺序进行排序?
5、何种列将作为附加性列被添加?
以上是创建索引的原则,也可以说是创建索引的依据。
2.9.索引定义
非唯一索引按照“ix_字段名称_字段名称[字段名]”进行命名。 唯一索引按照“ux 或 uk_字段名称_字段名称[_字段名]”进行命名。 索引名称使用小写。 索引中的字段数不超过 5 个。 唯一键由 3 个以下字段组成,并且字段都是整形时,使用唯一键作为主键。 没有唯一键或者唯一键不符合 5 中的条件时,使用自增(或者通过发号器获取)id 作为主键。 唯一键不和主键重复。
7
2.10.索引创建步骤
创建索引时,不能只单单关注一条 SQL,而是应该参照表上的所有 SQL 来综合的设计索引,下面是为表创建 索引的步骤: 1、尽可能收集表上所有的 SQL,按照执行频次进行排序,并将执行频次高的 SQL 排在前面。 2、依次对 SQL 进行分析,分析表上现有索引是否满足查询,如果不满足则创建索引。 3、根据后边的 SQL 查询条件,对先前创建的索引进行适当调整。 4、争取用尽量少的索引满足大部分 SQL 的查询优化需求。
2.11.最佳索引
对一个查询语句来说,其最佳的索引我们称之为“三星索引”,那什么是三星索引呢?
2.11.1.三星索引介绍
如果与一个查询相关的索引行是相邻的,或者至少相距足够近的话,那这个索引就可以被标注为第一颗星。 这最小化了必须扫描的索引片的宽度。
如果索引行的顺序与查询语句的需求一致,则索引可以被标记上第二颗星。这排除了排序操作。
如果索引行包含了查询语句中的所有列,那么索引就可以被标记为第三颗星。这避免了访问表的操作:仅 访问索引就可以了。
对于这三颗星,第三颗星通常是最重要的。将一个列排除在索引之外可能会导致许多速度较慢的磁盘随机 读。
2.11.2.为了满足第一颗星
取出所有等值谓词的列(whereCOL=…),把这些列作为索引最开头的列,以任意顺序都可以。
2.11.3.为了满足第二颗星
将 orderby 列加入到索引中。 不要改变这些列的顺序,但是忽略那些在第一步中已经加入索引中的列。
2.11.4.为了满足第三颗星
将查询语句中剩余的列加入到索引中去,列在索引中添加的顺序对查询语句的性能没有任何影响,但是易 变的列放在最后能够降低更新的成本。
8
2.11.5.范围谓词与三星索引
以下面的 SQL 举例: DECLARECURSOR43CURSORFOR SELECT CNO,FNAME FROM CUST WHERE LNAMEBETWEEN:LNAME1AND:LNAME2 AND CITY=:CITY ORDERBY FNAME
当出现 BETWEEN 谓词或其他任何范围查询时,意味着将无法同时满足第一颗星与第二颗星。这意味着我们 需要在第一颗星与第二颗星之间做出选择。
2.12.最佳索引设计方法
当无法创建满足三星的索引时,我们就需要在第一颗星与第二颗星之间做出选择。因此,也就有了下面两 个候选索引设计方法。
2.12.1.候选 A - 取出对优化器来说并不复杂的等值谓词列。将这些列作为索引的前导列——以任意顺序皆可。 2. 将选择性最好的范围谓词作为索引的下一列,如果存在的话。最好的选择性是指对于最差的输入值有 最低的过滤因子。即对于最差的输入值也要满足性能要求。 3. 以正确的顺序确定 ORDERBY 列(如果 ORDERBY 列有 DESC 的话,加上 DESC) 。 并忽略第 1 步与第 2 步中已经添加的列。 4. 以任意顺序将 SELECT 语句中余下的列添加至索引中(但是需要以不易变的列开始) 。
举例:CURSOR43 根据候选 A 创建的索引为 (CITY,LNAME,FNAME,CNO)。 由于 FNAME 在范围谓词 LNAME 的后面,候选 A 引起了 CURSOR43 的一次排序。
2.12.2.候选 B
如果候选 A 引起了所给查询的一次排序操作,那么还可以设计候选 B。根据定义,对于候选 B 来说第二颗 星比第一颗星更重要。 - 取出对优化器来说并不复杂的等值谓词列。将这些列作为索引的前导列——以任意顺序皆可。 2. 以正确的顺序确定 ORDERBY 列(如果 ORDERBY 列有 DESC 的话,加上 DESC)。 并忽略第 1 步中已经 添加的列。 3. 以任意顺序将 SELECT 语句中余下的列添加至索引中(但是需要以不易变的列开始) 。
9
举例:CURSOR43 根据候选 B 创建的索引为 (CITY,FNAME,LNAME,CNO)。
现在我们有了两个最佳索引的候选对象,一个有第一颗星,一个有第二颗星。对于候选 A 与 候选 B 来说, 我们该选择哪个呢?
还是要根据实际情况来看,如果根据候选 A 选取的数据量不大,那进行排序的开销也是可以接受的。反之, 如果满足条件的数据很多,且要求按照顺序取很少的一部分数据(比如翻页),候选 B 的性能将是不错的。 通常来说候选 A 是不错的,但有时候还是会用到候选 B,会出现两个索引共存的情况。
值得一提的是,现实中不一定要给每个查询都设计最佳索引,或者并不一定将索引都设计成最佳索引的形 式。因为索引也是有开销的,我们需要权衡收益与开销的大小。
总之,在效率与开销之间,需要一个平衡。如果过了,将事与愿违。 - SQL 编写中涉及性能的相关要点
除了创建高效的索引外,编写出高效的 SQL 也是应用高性能的保证。 下面介绍一些常见的影响性能的 SQL 写法,这些是我们需要规避掉的。
3.1.慎用 union/intersect/minus 集合操作
这三类集合操作都会去除重复值,会进行排序操作。 对于 union,优先考虑是否可用 union all 代替。
除了性能考虑之外,对于我们开发人员来说,首先要对 union/union all/intersect/minus 集合运算结果 有个清楚的认识。
以下是对 union/intersect/minus 集合操作的演示:
SQL> select * from t1 order by id;
ID ---------1 1 2 2 3 3 4
10
4 5 5 6 7 8 9
14 rows selected
SQL> select * from t2 order by id;
ID ---------1 2 3 4
上面,是查询中涉及到的两张表 t1 和 t2,下面将对两表进行集合运算。
SQL> select * from t1 2 union 3 select * from t2;
ID ---------1 2 3 4 5 6 7 8 9
9 rows selected
SQL> select * from t1 2 minus 3 select * from t2;
ID
11
---------5 6 7 8 9
SQL> select * from t1 2 intersect 3 select * from t2;
ID ---------1 2 3 4
从执行结果中,我们注意到 union,minus, intersect 集合运算都进行了去除重复值的运算。
SQL> select * from t1 2 union all 3 select * from t2;
ID ---------1 2 3 4 5 6 7 8 9 1 2 3 4 5 1 2 3 4
12
18 rows selected
SQL>
以上执行结果, 是否与你预期的结果一样呢?
3.2.将 where 条件放到 SQL 的最里层
尽可能将 where 条件放到 SQL 最里层,以便在 SQL 执行之初,就将不符合的数据过滤掉。
SELECT COUNT() FROM (SELECT AGENTCODE, IDNO, GREATEST(OFFWORKDATE, NVL(REWORKDATE, DATE ‘2006-01-01’)) AS INDATE, DECODE(AGENTSTATE, ‘0’, LEAD(OFFWORKDATE, 1, ADD_MONTHS(SYSDATE, 12)) OVER(PARTITION BY AGENTCODE ORDER BY DEPARTTIMES), LEAD(OFFWORKDATE, 1, DATE ‘2006-01-01’) OVER(PARTITION BY AGENTCODE ORDER BY DEPARTTIMES)) AS OUTDATE FROM (SELECT A.AGENTCODE, IDNO, A.DEPARTTIMES, A.OFFWORKDATE, A.REWORKDATE, DECODE(B.AGENTSTATE, ‘01’, ‘0’, ‘02’, ‘0’, ‘1’) AS AGENTSTATE FROM LADIMISSION A, LAAGENT B WHERE A.AGENTCODE = B.AGENTCODE AND OFFWORKDATE IS NOT NULL AND B.BRANCHTYPE = ‘1’ UNION ALL SELECT AGENTCODE, IDNO, 0, JOINDATE, NULL, DECODE(AGENTSTATE, ‘01’, ‘0’, ‘02’, ‘0’, ‘1’) AS AGENTSTATE FROM LAAGENT WHERE BRANCHTYPE = ‘1’)) WHERE IDNO = :B3 AND IDNO <> :B2 AND :B1 BETWEEN INDATE AND OUTDATE - 1
13
分析 SQL 语句可以发现, WHERE IDNO = :B3 这个条件部分可以直接从 SQL 的外层放到最里层去。 放到最里层之后,从一开始就将绝大部分数据过滤掉,从而提高效率。
3.3.有意识的减少排序操作
排序操作将严重影响语句执行效率。 排序是 SQL 执行过程中资源开销最大的一类操作,所以要坚决去掉没有必要的排序开销,或者借用索引来 避免排序。
增加排序,意味着需要做怎样的操作? 首先,对全表数据进行扫描,如果排序字段上没有索引的话。 其次,对相关字段应用排序算法,计算出排序的结果。 这个过程中,CPU、内存、磁盘三种资源开销都会 不小。
涉及排序的操作: A、创建索引 B、涉及到索引维护的并行插入 C、order by 或者 group by D、Distinct E、union/intersect/minus F、sort-merge join G、analyze 命令(尽可能使用 estimate 而不是 compute)
示例 SQL: select * from (select a.missionprop1 理赔编号, getCaseState(a.missionprop1) 案件状态, a.missionprop3 出险人客户号, a.missionprop4 出险人姓名, (select codename from ldcode where codetype = ‘sex’ and code = a.missionprop5), to_date(a.missionprop6, ‘yyyy-mm-dd’) 出险日期, (select rptdate from llreport where rptno = a.missionprop1), (select shortname from ldcom where comcode = b.mngcom) 报案机构, (select username from lduser where usercode = b.operator) 报案记录人员, a.missionid, a.submissionid, a.activityid, a.missionprop2,
14
(select case count(1) when 0 then ‘’ else ‘回退案件’ end from LLCaseBack where rgtno = a.missionprop1) 标志, (case (select isEnpAdded from LLRegister where rgtno = (select b.rgtobjno from llregister b, llcase c where caseno = a.missionprop1 and c.rgtno = b.rgtno)) when ‘1’ then ‘是’ else ‘否’ end), (select d.username from lduser d where a.defaultOperator = d.usercode) 当前操作人员, (select shortname from ldcom where comcode = (select ll.mngcom from llregister ll where ll.rgtno = a.missionprop1)) 立案机构, (select username from lduser where usercode = (select ll.operator from llregister ll where ll.rgtno = a.missionprop1)), a.defaultOperator, ‘’ a3, ‘’ a4, a.makedate, a.maketime, (case when isWebCase(a.missionprop1, 1) = ‘1’ then ‘是’ else ‘否’ end),
15
(case when isWebCase(a.missionprop1, 0) = ‘1’ then ‘是’ else ‘否’ end) from lwmission a, llreport b where 1 = 1 and a.missionprop1 = b.rptno and a.activityid = ‘0000005002’ and a.processid = ‘0000000005’ and a.DefaultOperator is null order by isWebCase(a.missionprop1, 0) desc, getVIPGradeForClaim(missionprop3) desc, a.makedate, a.maketime) where rownum <= 300
SQL 优化分析: 需要想办法规避掉排序操作,尤其这里先进行函数计算后再进行排序,非常消耗资源。 这样的 SQL 明显是不符合性能要求的,效率也绝不会好。如果执行稍微频繁的话,主机资源将会很快被耗 尽。
这里暂且采用了创建函数索引的方式来避免排序: create index ix_lwmission_actid_prcid_dop on lwmission(activityid,processid,defaultoperator,isWebCase(missionprop1,0)) tablespace lisindex;
不过,函数索引的创建有一些风险,我们应尽量从业务角度考虑避免排序操作。
3.4.优先使用等于操作,合理使用 like
使用等于操作时,是可以借助索引来提升性能的。 使用 like 时,尽量避免在左边使用 %,这样还可以用到索引。
在应用程序功能设计时,除了考虑设计完美的功能外,也应该考虑到程序的性能和执行效率。在功能与效 率之间,需要一个平衡。
from LCGrpCont a, LAAgent b, LCCont c where a.AgentCode = b.AgentCode AND 1 = 1 and a.AppFlag = ‘1’ and a.GrpContNo = c.GrpContNo
16
and c.cardflag <> ‘4’ and a.ManageCom like ‘8661%’ and a.GrpName like ‘%宝塔保安服务有限公司%’ and specflag = ‘0’ and a.ManageCom like ‘8661%’ and a.cinvalidate >= ‘2015-01-19’ Order by CValiDate, grpContNo, a.ManageCom, a.GrpContNo, a.PrtNo, a.SignDate, a.CValiDate
分析: 以上 SQL 中,可以考虑将 like 改为等于操作。
3.5.避免隐式转换
where 条件中等号两边数据类型要一致;表连接时,等号两边字段数据类型也要保持一致。
select max(to_number(SUBJECT_SORT)) as count from FOCUS.OBT_OBJECT where PSP_ID = 201403101289 and PSP_VERSION_NUM = 4.4
以上 PSP_ID 字段为字符型,等号两边类型不一致会导致隐式类型转换的发生。这里的隐式转化是字符型向 数值型的隐式转换,所以会导致 PSP_ID 上的索引失效,进而会导致全表扫描。
select * from LISPROD.LJAPAYPERSON where POLNO = 2010000337166021 and PAYNO = 2014001945828031 and DUTYCODE = ‘P28001’ and PAYPLANCODE = ‘P28101’ and PAYTYPE = ‘ZC’
以上 POLNO 字段为字符型, 这会引起隐式转换。 当隐式转换发生时,可能会使索引失效,以及增加无谓的转换操作。
另外,要说明的是, 存储过程中 function 或 procedure 的变量的类型也要与对应表中字段的类型要一致, 否则也可能会导致隐式转换的发生。
17
3.6. OR 改写为 union all
这个看具体情况,一般情况下不需要。 当 semi join 与 or 连用的时候,如果因为 OR 导致 Filter 操作时,就需要改写 SQL 了。
SELECT * FROM LJTempFee WHERE ((OtherNoType = ‘0’ AND OtherNo IN (SELECT PolNo FROM LCPol WHERE PrtNo = ‘10088800971797’)) OR (OtherNoType = ‘4’ AND OtherNo = ‘10088800971797’));
可改写成: SELECT * FROM LJTempFee WHERE OtherNoType = ‘0’ AND OtherNo IN (SELECT PolNo FROM LCPol WHERE PrtNo = ‘10088800971797’) union all select * from LJTempFee where OtherNoType = ‘4’ AND OtherNo = ‘10088800971797’;
注意: 这里使用 union all 的话,将可能存在改写不等价的风险。 因为如果有记录同时满足 OR 前后条件的话,使用 OR 逻辑运算符满足前后两个条件的记录只会出现一次。 但是,如果改成 union all,将会导致记录出现两次。 当然,改成 union 的话,为了保证等价,表上必须有主键。否则,如果表上没有主键的话,也一样没法保 证改写是等价的,因为 union 会对记录去重。
3.7.在查询中禁止使用 ,应使用确定的字段名代替星号
通过指定字段,可以减少不必要字段的查询,减少不必要的资源开销,提高执行效率。尤其是表中包含 LOB 字段类型时效率提升更明显。
select * from LPEdorItem where EdorType=‘LF’ and PolNo=‘000000’;
分析: 该语句需要查询表中所有字段吗? 尽量不要 ,应使用确定的字段名代替星号。
3.8.在多表连接的语句中,所有的表都要使用别名
在多表连接的语句中, 表要使用别名,各个字段都要带上表别名。这个也属于开发规范方面,当分析 SQL
18
时,对字段属于哪个表就很清晰。
3.9.使用 to_date 函数构造日期
对于日期类型字段的赋值或比较时, 推荐使用 to_date 函数构造日期。 不要使用 date ‘2015-01-15’ 或 直接使用字符串的方式,因为这两种写法将会严重依赖数据库的环境变 量设置。
3.10.尽量不要对字段使用函数或进行运算
尽量不要对字段使用函数或进行运算,对字段进行计算将无法使用该字段上的索引。 就单单对字段进行运算来说,也会加重资源开销。 遇到这种情况,一般可通过等价改写来避免,实在无法改写的可创建函数索引。 当然,对语句进行等价改写时,需要高度注意改写的等价性。
示例: where substr(m.polmngcom, 1, 6) = ‘863401’ 可改写为: where m.polmngcom like ‘863401%’;
where addtime + 1 > sysdate 可改写为: where addtime > sysdate - 1;
where trunc(addtime) = trunc(to_date(‘2015-05-01’,‘yyyy-mm-dd’)) 应等价改写为: where addtime <=to_date(‘2015-05-02’,‘yyyy-mm-dd’) and addtime > to_date(‘2015-05-01’,‘yyyy-mm-dd’)
WHERE “PAYPLANCODE” = ‘P69101’ AND “DUTYCODE” = ‘P69001’ AND “PAYTYPE” = ‘ZC’ AND TO_NUMBER(“POLNO”) = 2012001535421021 AND TO_NUMBER(“PAYNO”) = 2015000344156031 以上可等价改写为:POLNO = ‘2012001535421021’ and PAYNO = ‘2012001535421021’
delete from fin_document_sum s where trunc(s.document_date) >= date ‘2015-04-25’ and trunc(s.document_date) <= date ‘2015-04-28’ 可等价改写为: delete from fin_document_sum s
19
where s.document_date >= to_date(‘2015-04-25’, ‘yyyy-MM-dd’) and s.document_date < to_date(‘2015-04-29’, ‘yyyy-MM-dd’)
为什么要避免对字段进行运算或函数操作呢? 如果对字段进行函数运算,那么将会对表中每条记录的对应字段进行运算,其计算量将是非常大的。
以下面 SQL 示例说明: delete from fin_document_sum s where trunc(s.document_date) >= date ‘2015-04-25’ and trunc(s.document_date) <= date ‘2015-04-28’
以上 SQL 将如何执行呢? 首先,对 fin_document_sum 表的每条记录中的 document_date 字段进行 trunc 操作, 然后,将 trunc(s.document_date) 的值与查询条件进行比较,如果满足,则将记录删掉。
就算等价改写后不能使用创建在 document_date 字段上的索引,也一样会有性能上的提升。 因为 trunc(s.document_date) >= date ‘2015-04-25’,会先对 document_date 执行 trunc 操作后,再执 行比较操作。 而 s.document_date >= to_date(‘2015-04-25’, ‘yyyy-MM-dd’) 则不需要执行 trunc 操作,直接进行比较 操作即可。
要有性能优化意识,要尽可能的减少不必要的操作!!
3.11.使用多个字段更新写法替代多个单字段的更新
update laprecontinue a set managecom = (select managecom from laagent where branchtype = tBranchType and agentcode = a.agentcode), branchcode = (select branchcode from laagent where branchtype = tBranchType and agentcode = a.agentcode), branchattr = (select branchattr from laagent b, labranchgroup c where b.branchcode = c.agentgroup and b.agentcode = a.agentcode and c.branchtype = tBranchType and b.branchtype = tBranchType)
20
where not exists (select 1 from laagent d, labranchgroup e where d.branchtype = tBranchType and agentcode = a.agentcode and d.branchcode = e.agentgroup and e.branchtype = tBranchType and d.branchcode = a.branchcode and e.branchattr = a.branchattr) and a.branchtype = tBranchType;
语句没有较好的过滤条件,优化空间不大,但仍可以稍微改进一点。 以上可改写为: update laprecontinue a set (managecom,branchcode) = (select managecom,branchcode from laagent b where b.branchtype = tBranchType and b.agentcode = a.agentcode), branchattr = (select branchattr from laagent b, labranchgroup c where b.branchcode = c.agentgroup and c.branchtype = tBranchType and b.branchtype = tBranchType and b.agentcode = a.agentcode ) where not exists (select 1 from laagent d, labranchgroup e where d.branchtype = tBranchType and d.agentcode = a.agentcode and d.branchcode = e.agentgroup and e.branchtype = tBranchType and d.branchcode = a.branchcode and e.branchattr = a.branchattr) and a.branchtype = tBranchType;
以上只是对 update 更新写法进行了简单修改,但是其性能仍然是不理想的。 关联更新要想获得理想的性能提升,应该使用 merge 方式。
21
3.12.避免使用 update 语句进行关联更新
对于关联更新,要使用视图更新或 merge 方式,避免使用 update 语句进行关联更新。 示例如下: UPDATE POSDATA.POS_VIP_CLIENT_PREPARE PVCP SET PVCP.STANDARD_PREM = (SELECT T1.CURRENT_ACCOUNT_VALUE FROM (SELECT T. FROM (SELECT PFC.POLICY_NO, PFC.PROD_SEQ, PFC.PRODUCT_CODE, PAVCH.CURRENT_ACCOUNT_VALUE, ROW_NUMBER() OVER(PARTITION BY PFC.POLICY_NO ORDER BY PAVCH.TRADING_NO DESC) AS SUBCOUNT FROM POS_ACCOUNT_VALUE_CHG_HIST PAVCH, POS_FIN_CONTRACT PFC WHERE PAVCH.FINANCIAL_CONTRACT_NO = PFC.FINANCIAL_CONTRACT_NO) T WHERE T.SUBCOUNT = 1) T1 WHERE T1.POLICY_NO = PVCP.POLICY_NO AND T1.PROD_SEQ = PVCP.PROD_SEQ AND T1.PRODUCT_CODE = PVCP.PROD_SEQ) WHERE PVCP.PRODUCT_CLASS = ‘Y’ AND EXISTS (SELECT 1 FROM POS_FIN_CONTRACT PFC, POS_ACCOUNT_VALUE_CHG_HIST PAVCH WHERE PVCP.POLICY_NO = PFC.POLICY_NO AND PVCP.PRODUCT_CODE = PFC.PRODUCT_CODE AND PVCP.PROD_SEQ = PFC.PROD_SEQ AND PFC.FINANCIAL_CONTRACT_NO = PAVCH.PRODUCT_TRADING_NO)
应改写为: merge into POSDATA.POS_VIP_CLIENT_PREPARE PVCP using (SELECT T. FROM (SELECT PFC.POLICY_NO, PFC.PROD_SEQ, PFC.PRODUCT_CODE, PAVCH.CURRENT_ACCOUNT_VALUE, ROW_NUMBER() OVER(PARTITION BY PFC.POLICY_NO ORDER BY PAVCH.TRADING_NO DESC) AS SUBCOUNT FROM POS_ACCOUNT_VALUE_CHG_HIST PAVCH, POS_FIN_CONTRACT PFC
22
WHERE PAVCH.FINANCIAL_CONTRACT_NO = PFC.FINANCIAL_CONTRACT_NO) T WHERE T.SUBCOUNT = 1) T1
on (…) when matched then update …
另外,对于表中记录上千万表的关联更新, merge into 也会力不从心, 应该使用 PL/SQL forall 方式分 批对数据进行更新。
3.13.在使用 rownum 时,尽量减少嵌套
如果只嵌套一层的话,rownum 限制条件可以谓词推进到里层,这样就可以保证在里层就对数据进行很好的 过滤。
常见的分页写法有如下两种: 第一种: select a. from (select rownum rn, o.owner, o.object_type, o.object_name, o.object_id from objects O where owner = ‘LIFEBASE’) a where rn <=20 and rn >=1
第二种推荐写法: select a.* from (select rownum rn, o.owner, o.object_type, o.object_name, o.object_id from objects o where owner = ‘LIFEBASE’) a where rownum <=20 and rn >=1 或 select a.* from (select rownum rn, o.owner, o.object_type, o.object_name, o.object_id from objects o where owner = ‘LIFEBASE’ where rownum <=20) a where rn >=1
下面通过执行计划和执行统计信息来说明两种写法的区别: SQL> select a.* from 2 (select rownum rn, o.owner, o.object_type, o.object_name, o.object_id from objects o 3 where owner = ‘LIFEBASE’) a 4 where rn <=20 and rn >=1;
RN OWNER OBJECT_TYPE OBJECT_NAME OBJECT_ID
1 LIFEBASE INDEX IX_BRANCH_INFO_1 352123
2 LIFEBASE INDEX IX_BRANCH_INFO_2 352124
23
3 LIFEBASE INDEX IX_CHNL_DETAIL_TBL_CODE 352125
4 LIFEBASE INDEX IX_AREA_DEFINE_1 352126
5 LIFEBASE INDEX IX_CITY_1 352127
6 LIFEBASE INDEX IX_DEPARTMENT_INFO_1 352128
7 LIFEBASE INDEX IX_DEPARTMENT_INFO_2 352129
8 LIFEBASE INDEX IX_PROVINCE_1 352130
9 LIFEBASE INDEX IX_COUNTRY_1 352131
10 LIFEBASE INDEX PK_EMP_JOB_TYPE_TBL 346137
11 LIFEBASE INDEX PK_BRANCH_LEVEL_TBL 346139
12 LIFEBASE INDEX PK_BUSINESS_NO 346141
13 LIFEBASE INDEX PK_EMAIL_TYPE 346143
14 LIFEBASE INDEX PK_ID_TYPE 346145
15 LIFEBASE INDEX PK_PREM_PERIOD_TYPE 346147
16 LIFEBASE INDEX PK_DUTY_STATUS 346149
17 LIFEBASE INDEX PK_FIN_ACCOUNT_NO_TYPE 346151
18 LIFEBASE INDEX PK_ADDRESS_TYPE 346153
19 LIFEBASE INDEX PK_INTEREST_UNIT 346155
20 LIFEBASE INDEX PK_DEAL_TYPE 346157
20 rows selected.
Execution Plan
Plan hash value: 3882339809
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
| 0 | SELECT STATEMENT | | 292 | 35040 | 23 (0)|
|* 1 | VIEW | | 292 | 35040 | 23 (0)|
| 2 | COUNT | | | | |
| 3 | TABLE ACCESS BY INDEX ROWID| OBJECTS | 292 | 10512 | 23 (0)|
|* 4 | INDEX RANGE SCAN | IX_OBJECTS_OWNER_TYPE | 292 | | 2 (0)|
Predicate Information (identified by operation id):
1 - filter(“RN”>=1 AND “RN”<=20)
4 - access(“OWNER”=‘LIFEBASE’)
Statistics
0 recursive calls
0 db block gets
22 consistent gets
24
0 physical reads
0 redo size
1653 bytes sent via SQLNet to client
531 bytes received via SQLNet from client
3 SQLNet roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
20 rows processed
SQL> select a. from 2 (select rownum rn, o.owner, o.object_type, o.object_name, o.object_id from objects o 3 where owner = ‘LIFEBASE’) a 4 where rownum <=20 and rn >=1;
RN OWNER OBJECT_TYPE OBJECT_NAME OBJECT_ID
1 LIFEBASE INDEX IX_BRANCH_INFO_1 352123
2 LIFEBASE INDEX IX_BRANCH_INFO_2 352124
3 LIFEBASE INDEX IX_CHNL_DETAIL_TBL_CODE 352125
4 LIFEBASE INDEX IX_AREA_DEFINE_1 352126
5 LIFEBASE INDEX IX_CITY_1 352127
6 LIFEBASE INDEX IX_DEPARTMENT_INFO_1 352128
7 LIFEBASE INDEX IX_DEPARTMENT_INFO_2 352129
8 LIFEBASE INDEX IX_PROVINCE_1 352130
9 LIFEBASE INDEX IX_COUNTRY_1 352131
10 LIFEBASE INDEX PK_EMP_JOB_TYPE_TBL 346137
11 LIFEBASE INDEX PK_BRANCH_LEVEL_TBL 346139
12 LIFEBASE INDEX PK_BUSINESS_NO 346141
13 LIFEBASE INDEX PK_EMAIL_TYPE 346143
14 LIFEBASE INDEX PK_ID_TYPE 346145
15 LIFEBASE INDEX PK_PREM_PERIOD_TYPE 346147
16 LIFEBASE INDEX PK_DUTY_STATUS 346149
17 LIFEBASE INDEX PK_FIN_ACCOUNT_NO_TYPE 346151
18 LIFEBASE INDEX PK_ADDRESS_TYPE 346153
19 LIFEBASE INDEX PK_INTEREST_UNIT 346155
20 LIFEBASE INDEX PK_DEAL_TYPE 346157
20 rows selected.
Execution Plan
Plan hash value: 781058506
25
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)
| 0 | SELECT STATEMENT | | 20 | 2400 | 4 (0)
|* 1 | COUNT STOPKEY | | | |
|* 2 | VIEW | | 21 | 2520 | 4 (0)
| 3 | COUNT | | | |
| 4 | TABLE ACCESS BY INDEX ROWID| OBJECTS | 21 | 756 | 4 (0)
|* 5 | INDEX RANGE SCAN | IX_OBJECTS_OWNER_TYPE | 292 | | 2 (0)
Predicate Information (identified by operation id):
1 - filter(ROWNUM<=20)
2 - filter(“RN”>=1)
5 - access(“OWNER”=‘LIFEBASE’)
Statistics
1 recursive calls
0 db block gets
9 consistent gets
0 physical reads
0 redo size
1653 bytes sent via SQLNet to client
531 bytes received via SQLNet from client
3 SQLNet roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
20 rows processed
通过比较可知, 第二种写法效率比第一种好。
3.14.尽量避免在 SQL 中进行逻辑判断
SELECT CUSTOMERNO FROM LDPERSON WHERE (NAME = :B5 AND SEX = :B4 AND BIRTHDAY = :B3 AND (IDTYPE <> :B2 OR (IDNO <> CONCAT(SUBSTR(UPPER(:B1), 1, 6), SUBSTR(UPPER(:B1), 9, 9)) AND CONCAT(SUBSTR(IDNO, 1, 6), SUBSTR(IDNO, 9, 9)) <> UPPER(:B1) AND
26
IDNO <> UPPER(:B1)) AND (IDNO <> CONCAT(SUBSTR(LOWER(:B1), 1, 6), SUBSTR(LOWER(:B1), 9, 9)) AND CONCAT(SUBSTR(IDNO, 1, 6), SUBSTR(IDNO, 9, 9)) <> LOWER(:B1) AND IDNO <> LOWER(:B1))))
UNION SELECT /+INDEX(LDPERSON LDPERSON_IDX02)/ CUSTOMERNO FROM LDPERSON WHERE (IDTYPE = :B2 AND (IDNO = UPPER(:B1) OR IDNO = LOWER(:B1) OR (IDNO = CONCAT(SUBSTR(UPPER(:B1), 1, 6), SUBSTR(UPPER(:B1), 9, 9)) OR IDNO = CONCAT(SUBSTR(LOWER(:B1), 1, 6), SUBSTR(LOWER(:B1), 9, 9))) OR (IDNO LIKE (SUBSTR(LOWER(:B1), 1, 6) || ‘’ || SUBSTR(LOWER(:B1), 7, 9) || ‘_’) OR IDNO LIKE (SUBSTR(UPPER(:B1), 1, 6) || '’ || SUBSTR(UPPER(:B1), 9, 9) || '’))) AND (NAME <> :B5 OR SEX <> :B4 OR BIRTHDAY <> :B3)) AND IDTYPE IN (‘0’, ‘1’) UNION SELECT CUSTOMERNO FROM LDPERSON WHERE (NAME = :B5 AND SEX = :B4 AND BIRTHDAY = :B3 AND (IDTYPE <> :B2 OR (IDNO <> UPPER(:B1) AND IDNO <> LOWER(:B1))) AND IDTYPE NOT IN (‘0’, ‘1’)) OR (((IDNO = LOWER(:B1) OR IDNO = UPPER(:B1)) AND IDTYPE = :B2) AND (NAME <> :B5 OR SEX <> :B4 OR BIRTHDAY <> :B3) AND IDTYPE IN (‘2’, ‘3’, ‘4’, ‘A’))
分析: 该语句判断逻辑过于复杂,这将给后期维护带来较大困难。 另外,SQL 参与逻辑判断,会增加 SQL 复杂度,容易引起 SQL 性能问题。 建议不要将业务逻辑判断引入 SQL,尽量保持 SQL 简单。
3.15.谨慎使用标量子查询
当查询结果集不大时,可以使用。 但是,当结果集很大时,使用标量子查询的效率就会变得非常糟糕。 当 结果集大时,应该用外连接方式对其进行等价改写!
select t.INT_B as INT58_4280_0, t.FLOAT_A as FLOAT59_4280_0_, t.FLOAT_B as FLOAT60_4280_0_, t.ST R_AP as STR46_4280_0_,
27
t.STR_AQ as STR47_4280_0_, --标量子查询写法 (select d.TASK_ID from OBT_TASK_LIST d where d.BUS_ID = t.BUS_ID) as formula164_0_, (select d.TASK_NAME from OBT_TASK_LIST d where d.BUS_ID = t.BUS_ID) as task_name
from OBT_BUS_LIST t where 1 = 1 and t.str_j <> ‘0293661920’ and substr(t.str_b, 1, 4) = ‘8632’ and substr(t.batch, 1, 8) >= to_char(add_months(sysdate, -6), ‘YYYYMMDD’) and substr(t.batch, 1, 8) <= to_char(sysdate, ‘YYYYMMDD’) and (replace(t.str_N, ‘-’, ‘’) = ‘13770359984’ or replace(t.Str_o, ‘-’, ‘’) = ‘13770359984’ or replace(t.str_P, ‘-’, ‘’) = ‘13770359984’ or replace(t.str_An, ‘-’, ‘’) = ‘13770359984’)
分析: 简单来看,查询同一个表的两个字段,导致对 OBT_TASK_LIST 表访问了两次,为减少访问,可改写为关联 查询。
3.16.使用嵌套视图对表连接进行优化
该优化的逻辑为, 使用嵌套视图优化对一个表的数据进行处理后,再取出部分结果去连接另一张表。
示例如下: select a.fld1, … , b.col1, … from tab2 b, tab1 a where a.key1 = b.key2 and a.fld1 = ‘10’ order by a.fld2;
以上 SQL 将如何执行呢? 在连接条件索引没有异常的情况下, 首先从 tab1 表中取出满足 a.fld1 = ‘10’ 的记录,然后根据连接条 件进行关联验证, 最后对关联结果集按照 a.fld2 进行排序。
如果这个 SQL 是在分页场景中,取第一页数据的话, 这样的执行顺序就是低效的, 因为虽然只取第一页 数据,但是也必须在两表关联之后,对所有数据进行排序。 以上假定在 tab1 表上没有创建 fld1,fld2 的复合索引。
如果单独先处理 tab1 表,根据 a.fld1 = ‘10’ 条件过滤数据,并按照 fld2 进行排序之后,如果在分页场 景中,只需取出少量数据去与 tab2 进行连接验证就可以将结果返回给客户端了。 这样就省掉了大量的表关联操作。
28
通过嵌套视图的方式可以达到这种效果: select a.fld1, … , b.col1, … from tab2 b,(select a. from tab1 a where a.fld1 = ‘10’ order by a.fld2) a where a.key1 = b.key2;
另一种使用嵌套视图的场景:
select b.部门名, sum(a.销售额) from tab1 a, tab2 b where a.部门编号 = b.部门编号 and a.销售日期 like ‘201505%’ group by b.部门名;
以上可以拆解为以下两个 SQL: select a.部门编号,sum(a.销售额) 部门销售额 from tab1 a where a.销售日期 like ‘201505%’ group by a.部门编号;
select b.部门编号, b.部门名 from tab2 b where b.部门编号 = :a.部门编号;
以上两个 SQL 合并的写法为: select b.部门编号, b.部门名, a.部门销售额 ( select a.部门编号,sum(a.销售额) 部门销售额 from tab1 a where a.销售日期 like ‘201505%’ group by a.部门编号 ) a, tab2 b where a.部门编号 = b.部门编号;
这种写法将先对表进行聚合操作,再去进行表关联, 将会大大减少不必要的表连接次数。
3.17.将范围查询条件转换为多个等于查询条件
这个是借助使用索引等值查询效率高的特点。 注意,需要在逻辑等价前提条件下,将范围查询条件转换为多个等于查询条件。
29
select * from tab1 where id between 10 and 13; 可转换为: select * from tab1 where id in (10,11,12,13);
select … from tab1 x, tab2 y where x.key1 = y.key1 and y.key2 between 200501 and 200503; --这里使用 number 类型存储日期值。 可改写为: select … from tab1 x, tab2 y where x.key1 = y.key1 and y.key2 in (200501,200502,200503);
这种改写,将会使索引查询变得高效, 避免对索引引导列进行范围扫描。
3.18.理解需求对 SQL 进行极限优化
declare v_cnt pls_integer; begin select count() into v_cnt from objects; if v_cnt > 0 then … else … end;
以上 select count() into v_cnt from objects 如何优化呢? 创建索引?
根据上下文可知,v_cnt 就是用来判断表中是否有数据, 完全没必要将表中有多少条记录查询出来。 所以,可以将查询语句改写为 select count() into v_cnt from objects where rownum=1, 这样改写之后,就无需汇总查询了,只要在表中看到记录,查询语句就结束了。
3.19.复杂 SQL 要使用注释进行必要的逻辑说明
系统中很多 SQL 语句都比较长,动辄几十行,甚至几百行。 不过,这么长的 SQL 普遍缺少注释以进行必要的的逻辑说明。 面对这类 SQL,无论是日后维护,还是进行性能调优,都将是非常耗费精力的。
30
所以,使用注释对 SQL 进行必要的逻辑说明是非常必要且非常重要的事情。 写 SQL 时,不光要关注实现,还要考虑到以后的易维护性。
4. 索引创建示例
4.1.在可以有效过滤数据的条件上创建索引
有效过滤数据,就是通过查询条件,从表中只取出很小一部分数据,这样的字段也称为具有很好的可选性, 或离散度高。 创建索引时,就是要选择这样具有很好可选性的列上来创建索引。
select t.BUS_ID as BUS1_4280_0_, t.BATCH as BATCH4280_0_, t.BUS_TYPE as BUS3_4280_0_, t.POLICYNUM as POLICYNUM4280_0_, t.STR_A as STR5_4280_0_, t.STR_B as STR6_4280_0_, t.STR_C as STR7_4280_0_, t.STR_D as STR8_4280_0_, t.STR_E as STR9_4280_0_, t.STR_F as STR10_4280_0_, t.STR_G as STR11_4280_0_, t.STR_H as STR12_4280_0_, t.STR_I as STR13_4280_0_, t.STR_J as STR14_4280_0_, t.STR_K as STR15_4280_0_, t.STR_L as STR16_4280_0_, t.STR_M as STR17_4280_0_, t.STR_N as STR18_4280_0_, t.STR_O as STR19_4280_0_, t.STR_P as STR20_4280_0_, t.STR_Q as STR21_4280_0_, t.STR_R as STR22_4280_0_, t.STR_S as STR23_4280_0_, t.STR_T as STR24_4280_0_, t.STR_U as STR25_4280_0_, t.STR_V as STR26_4280_0_, t.STR_W as STR27_4280_0_, t.STR_X as STR28_4280_0_, t.STR_Y as STR29_4280_0_,
31
t.STR_Z as STR30_4280_0_, t.STR_AA as STR31_4280_0_, t.STR_AB as STR32_4280_0_, t.STR_AC as STR33_4280_0_, t.STR_AD as STR34_4280_0_, t.STR_AE as STR35_4280_0_, t.STR_AF as STR36_4280_0_, t.STR_AG as STR37_4280_0_, t.STR_AH as STR38_4280_0_, t.STR_AI as STR39_4280_0_, t.STR_AJ as STR40_4280_0_, t.STR_AK as STR41_4280_0_, t.STR_AL as STR42_4280_0_, t.STR_AM as STR43_4280_0_, t.STR_AN as STR44_4280_0_, t.STR_AO as STR45_4280_0_, t.STR_AV as STR52_4280_0_, t.STR_AW as STR53_4280_0_, t.STR_AX as STR54_4280_0_, t.STR_AY as STR55_4280_0_, t.STR_AZ as STR56_4280_0_, t.INT_A as INT57_4280_0_, t.INT_B as INT58_4280_0_, t.FLOAT_A as FLOAT59_4280_0_, t.FLOAT_B as FLOAT60_4280_0_, t.ST R_AP as STR46_4280_0_, t.STR_AQ as STR47_4280_0_, (select d.TASK_ID from OBT_TASK_LIST d where d.BUS_ID = t.BUS_ID) as formula164_0_ from OBT_BUS_LIST t where 1 = 1 and t.str_j <> ‘0293661920’ and substr(t.str_b, 1, 4) = ‘8632’ and substr(t.batch, 1, 8) >= to_char(add_months(sysdate, -6), ‘YYYYMMDD’) and substr(t.batch, 1, 8) <= to_char(sysdate, ‘YYYYMMDD’) and (replace(t.str_N, ‘-’, ‘’) = ‘13770359984’ or replace(t.Str_o, ‘-’, ‘’) = ‘13770359984’ or replace(t.str_P, ‘-’, ‘’) = ‘13770359984’ or replace(t.str_An, ‘-’, ‘’) = ‘13770359984’)
分析: 上面标红部分中, 创建索引: create index focus.ix_obt_bus_list_str_n_f on
32
focus.OBT_BUS_LIST(replace(t.str_n, ‘-’, ‘’)) ; create index focus.ix_obt_bus_list_str_o_f on focus.OBT_BUS_LIST(replace(t.str_o, ‘-’, ‘’)) ; create index focus.ix_obt_bus_list_str_p_f on focus.OBT_BUS_LIST(replace(t.str_p, ‘-’, ‘’)) ; create index focus.ix_obt_bus_list_str_an_f on focus.OBT_BUS_LIST(replace(t.str_an, ‘-’, ‘’));
创建索引前,单次执行 6 秒, 创建后,单次执行 0.3 秒。
4.2.排序字段加入索引消除排序操作
select * from (select a.summary_id as SUMMARY1_4147_0_, a.summary_time as SUMMARY3_4147_0_, a.agent_id as AGENT4_4147_0_, a.ani as ANI4147_0_, a.cust_name as CUST5_4147_0_, c.name as CUST8_4147_0_, a.channal_type as CHANNAL9_4147_0_, a.call_type as CALL6_4147_0_, ‘0’ as HIS7_4147_0_ from focus.SUMMARY_DAY a, focus.BAS_DIC c where 1 = 1 and c.no = a.cust_type and c.dic_id = ‘CUSTOM_FL’ and a.summary_time >= ‘20150205150027’ and a.summary_time <= ‘20150205153419’ and a.agent_id = ‘党静’ order by a.summary_time desc) where rownum <= 10
创建索引: create index focus.ix_summary_day_agid_subtime on focus.summary_day(agent_id,summary_time desc) nologging tablespace datafocus;
4.3.创建索引优化聚合操作
因为索引相对表来说体积较小,所以,创建索引,可以减少数据读取,提高聚合操作的执行效率。
33
SELECT COUNT() FROM RN_PAID_INFO S WHERE S.PREM_ACTURAL_DATE >= TO_DATE(‘2014-01-01’, ‘yyyy-mm-dd’) AND S.PREM_ACTURAL_DATE <= TO_DATE(‘2014-04-01’, ‘yyyy-mm-dd’) AND S.AMT_TYPE IN (‘005’, ‘901’, ‘801’, ‘02F’, ‘03F’, ‘222’, ‘22A’)
索引测试情况: PREM_ACTURAL_DATE 有索引,不添加 amt_type 查询时,0.1s 就能查出结果。添加 amt_type 条件后,10 秒以上。
为什么多条件一个条件,反而效率更差了呢? 因为要进行额外的校验操作。
在 amt_type 上添加索引后,4 秒查出结果。 改用 amt_type、PREM_ACTURAL_DATE 复合索引后,0.04 秒查询出结果。
SQL> set timing on;
SQL> SELECT COUNT()
2 FROM RN_PAID_INFO S
3 WHERE S.PREM_ACTURAL_DATE >= TO_DATE(‘2014-01-01’, ‘yyyy-mm-dd’)
4 AND S.PREM_ACTURAL_DATE <= TO_DATE(‘2014-04-01’, ‘yyyy-mm-dd’);
COUNT()
1073075
Elapsed: 00:00:00.06
Execution Plan
Plan hash value: 2105428200
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
| 0 | SELECT STATEMENT | | 1 | 8 | 2528 (1)| 00:00:31 |
| 1 | SORT AGGREGATE | | 1 | 8 | | |
|* 2 | INDEX RANGE SCAN| IX_RN_PAID_INFO_3 | 1058K| 8269K| 2528 (1)| 00:00:31 |
Predicate Information (identified by operation id):
2 - access(“S”.“PREM_ACTURAL_DATE”>=TO_DATE(’ 2014-01-01 00:00:00’,
34
‘syyyy-mm-dd hh24:mi:ss’) AND “S”.“PREM_ACTURAL_DATE”<=TO_DATE(’ 2014-04-01
00:00:00’, ‘syyyy-mm-dd hh24:mi:ss’))
Statistics
0 recursive calls
0 db block gets
2558 consistent gets
0 physical reads
0 redo size
529 bytes sent via SQLNet to client
519 bytes received via SQLNet from client
2 SQLNet roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> SELECT /+ no_index(s ix_rn_paid_info_amt_pradate) / COUNT()
2 FROM RN_PAID_INFO S
3 WHERE S.PREM_ACTURAL_DATE >= TO_DATE(‘2014-01-01’, ‘yyyy-mm-dd’)
4 AND S.PREM_ACTURAL_DATE <= TO_DATE(‘2014-04-01’, ‘yyyy-mm-dd’)
5 AND S.AMT_TYPE IN (‘005’, ‘901’, ‘801’, ‘02F’, ‘03F’, ‘222’, ‘22A’);
COUNT(*)
329066
Elapsed: 00:00:02.86
Execution Plan
Plan hash value: 2779815793
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
| 0 | SELECT STATEMENT | | 1 | 12 | 146K (1)| 00:29:23 |
| 1 | SORT AGGREGATE | | 1 | 12 | | |
|* 2 | TABLE ACCESS FULL| RN_PAID_INFO | 353K| 4137K| 146K (1)| 00:29:23 |
Predicate Information (identified by operation id):
35
2 - filter(“S”.“PREM_ACTURAL_DATE”<=TO_DATE(’ 2014-04-01 00:00:00’,
‘syyyy-mm-dd hh24:mi:ss’) AND “S”.“PREM_ACTURAL_DATE”>=TO_DATE(’
2014-01-01 00:00:00’, ‘syyyy-mm-dd hh24:mi:ss’) AND (“S”.“AMT_TYPE”=‘005’
OR “S”.“AMT_TYPE”=‘02F’ OR “S”.“AMT_TYPE”=‘03F’ OR “S”.“AMT_TYPE”=‘222’ OR
“S”.“AMT_TYPE”=‘22A’ OR “S”.“AMT_TYPE”=‘801’ OR “S”.“AMT_TYPE”=‘901’))
Statistics
1 recursive calls
0 db block gets
538344 consistent gets
538249 physical reads
0 redo size
528 bytes sent via SQLNet to client
519 bytes received via SQLNet from client
2 SQLNet roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> SELECT COUNT()
2 FROM RN_PAID_INFO S
3 WHERE S.PREM_ACTURAL_DATE >= TO_DATE(‘2014-01-01’, ‘yyyy-mm-dd’)
4 AND S.PREM_ACTURAL_DATE <= TO_DATE(‘2014-04-01’, ‘yyyy-mm-dd’)
5 AND S.AMT_TYPE IN (‘005’, ‘901’, ‘801’, ‘02F’, ‘03F’, ‘222’, ‘22A’);
COUNT(*)
328516
Elapsed: 00:00:00.03
Execution Plan
Plan hash value: 3408632279
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
| 0 | SELECT STATEMENT | | 1 | 12 | 1237 (1)|
| 1 | SORT AGGREGATE | | 1 | 12 | |
| 2 | INLIST ITERATOR | | | | |
36
|* 3 | INDEX RANGE SCAN| IX_RN_PAID_INFO_AMT_PRADATE | 386K| 4528K| 1237 (1)|
Predicate Information (identified by operation id):
3 - access((“S”.“AMT_TYPE”=‘005’ OR “S”.“AMT_TYPE”=‘02F’ OR “S”.“AMT_TYPE”=‘03F’ OR
“S”.“AMT_TYPE”=‘222’ OR “S”.“AMT_TYPE”=‘22A’ OR “S”.“AMT_TYPE”=‘801’ OR
“S”.“AMT_TYPE”=‘901’) AND “S”.“PREM_ACTURAL_DATE”>=TO_DATE(’ 2014-01-01 00:00:00’,
‘syyyy-mm-dd hh24:mi:ss’) AND “S”.“PREM_ACTURAL_DATE”<=TO_DATE(’ 2014-04-01 00:00:00’,
‘syyyy-mm-dd hh24:mi:ss’))
Statistics
0 recursive calls
0 db block gets
1069 consistent gets
0 physical reads
0 redo size
528 bytes sent via SQLNet to client
520 bytes received via SQLNet from client
2 SQLNet roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> SELECT COUNT() FROM RN_PAID_INFO S;
COUNT(*)
15460103
Elapsed: 00:00:00.39 --为什么这个查询比上面的还慢呢?
Execution Plan
Plan hash value: 1747368817
| Id | Operation | Name | Rows | Cost (%CPU)|
| 0 | SELECT STATEMENT | | 1 | 7314 (2)|
| 1 | SORT AGGREGATE | | 1 | |
37
| 2 | INDEX FAST FULL SCAN| IX_RN_PAID_INFO_CHANNEL_TYPE | 15M| 7314 (2)|
Statistics
1 recursive calls
0 db block gets
27234 consistent gets
0 physical reads
0 redo size
529 bytes sent via SQLNet to client
519 bytes received via SQLNet from client
2 SQLNet roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
为什么带有查询条件的 count() 比不带查询条件的 count(*) 执行还快呢? 因为要查询的数据少啊。
4.4.在表关联字段上创建索引,避免全表或全索引扫描
select rsk.riskname RiskName, case when (select SubRiskFlag from LMRiskApp b where b.riskcode = rsk.riskcode) = ‘M’ then 1 else 0 end IsMainProd, rsk.risktype RiskType, rsk.risktype1 RiskType1, rsk.risktype3 RiskType3, rsk.risktype4 RiskType4, rsk.risktype5 RiskType5, rsk.riskperiod RiskPeriod, rsk.risktypedetail RiskTypeDetail, case when exists (select 1 from lcpol l
38
where riskcode = rsk.riskcode and riskcode in (select code from ldcode1 where codetype = ‘HMCP’)) then
1 else 0 end IsWaivedProd, ‘411403’ MainRiskCode, (select * from (select salestartdate from ldrisksalestate where riskcode = ‘411403’ and managecom in (‘86’, ‘8611’, ‘861101’) order by managecom desc) where rownum = 1) salestartdate, (select * from (select saleenddate from ldrisksalestate where riskcode = ‘411403’ and managecom in (‘86’, ‘8611’, ‘861101’) order by managecom desc) where rownum = 1) saleenddate, (select * from (select SaleState from ldrisksalestate where riskcode = ‘411403’ and managecom in (‘86’, ‘8611’, ‘861101’) order by managecom desc) where rownum = 1) SaleStatus from LMRiskApp rsk where rsk.riskcode = ‘411403’
Elapsed: 00:00:34.62
Execution Plan
Plan hash value: 1485715133
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
| 0 | SELECT STATEMENT | | 1 | 48 | 1 (0)|
| 1 | TABLE ACCESS BY INDEX ROWID | LMRISKAPP | 1 | 9 | 1 (0)|
39
|* 2 | INDEX UNIQUE SCAN | PK_LMRISKAPP | 1 | | 0 (0)|
| 3 | NESTED LOOPS | | 1 | 26 | 5464 (1)|
|* 4 | INDEX RANGE SCAN | PK_LDCODE1 | 1 | 19 | 3 (0)|
|* 5 | INDEX FAST FULL SCAN | PK_LCPOL_2 | 2 | 14 | 5461 (1)|
|* 6 | COUNT STOPKEY | | | | |
| 7 | VIEW | | 1 | 9 | 2 (0)|
| 8 | TABLE ACCESS BY INDEX ROWID | LDRISKSALESTATE | 1 | 14 | 2 (0)|
|* 9 | INDEX RANGE SCAN DESCENDING| SYS_C0045869 | 1 | | 1 (0)|
|* 10 | COUNT STOPKEY | | | | |
| 11 | VIEW | | 1 | 9 | 2 (0)|
| 12 | TABLE ACCESS BY INDEX ROWID | LDRISKSALESTATE | 1 | 17 | 2 (0)|
|* 13 | INDEX RANGE SCAN DESCENDING| SYS_C0045869 | 1 | | 1 (0)|
|* 14 | COUNT STOPKEY | | | | |
| 15 | VIEW | | 1 | 3 | 2 (0)|
| 16 | TABLE ACCESS BY INDEX ROWID | LDRISKSALESTATE | 1 | 13 | 2 (0)|
|* 17 | INDEX RANGE SCAN DESCENDING| SYS_C0045869 | 1 | | 1 (0)|
| 18 | TABLE ACCESS BY INDEX ROWID | LMRISKAPP | 1 | 48 | 1 (0)|
|* 19 | INDEX UNIQUE SCAN | PK_LMRISKAPP | 1 | | 0 (0)|
Predicate Information (identified by operation id):
2 - access(“B”.“RISKCODE”=:B1)
4 - access(“CODETYPE”=‘HMCP’ AND “CODE”=:B1)
5 - filter(“RISKCODE”=:B1 AND “RISKCODE”=“CODE”)
6 - filter(ROWNUM=1)
9 - access(“RISKCODE”=‘411403’)
filter(“MANAGECOM”=‘86’ OR “MANAGECOM”=‘8611’ OR “MANAGECOM”=‘861101’)
10 - filter(ROWNUM=1)
13 - access(“RISKCODE”=‘411403’)
filter(“MANAGECOM”=‘86’ OR “MANAGECOM”=‘8611’ OR “MANAGECOM”=‘861101’)
14 - filter(ROWNUM=1)
17 - access(“RISKCODE”=‘411403’)
filter(“MANAGECOM”=‘86’ OR “MANAGECOM”=‘8611’ OR “MANAGECOM”=‘861101’)
19 - access(“RSK”.“RISKCODE”=‘411403’)
Statistics
0 recursive calls
0 db block gets
1020699 consistent gets
128050 physical reads
2004 redo size
40
1450 bytes sent via SQLNet to client
505 bytes received via SQLNet from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL 优化分析: 执行计划标红部分 cost 值最高,其执行路径是索引快速全扫描,这是因为缺少合适的索引导致的。
创建索引: create index lisprod.ix_lcpol_riskcd on lisprod.lcpol(riskcode) nologging tablespace lisindex;
创建索引后执行时间: Elapsed: 00:00:00.04
Execution Plan
Plan hash value: 1228450184
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
| 0 | SELECT STATEMENT | | 1 | 48 | 1 (0)|
| 1 | TABLE ACCESS BY INDEX ROWID | LMRISKAPP | 1 | 9 | 1 (0)|
|* 2 | INDEX UNIQUE SCAN | PK_LMRISKAPP | 1 | | 0 (0)|
| 3 | NESTED LOOPS | | 1 | 26 | 35 (3)|
|* 4 | INDEX RANGE SCAN | PK_LDCODE1 | 1 | 19 | 3 (0)|
|* 5 | INDEX RANGE SCAN | IX_LCPOL_RISKCD | 2 | 14 | 32 (4)|
|* 6 | COUNT STOPKEY | | | | |
| 7 | VIEW | | 1 | 9 | 2 (0)|
| 8 | TABLE ACCESS BY INDEX ROWID | LDRISKSALESTATE | 1 | 14 | 2 (0)|
|* 9 | INDEX RANGE SCAN DESCENDING| SYS_C0045869 | 1 | | 1 (0)|
|* 10 | COUNT STOPKEY | | | | |
| 11 | VIEW | | 1 | 9 | 2 (0)|
| 12 | TABLE ACCESS BY INDEX ROWID | LDRISKSALESTATE | 1 | 17 | 2 (0)|
|* 13 | INDEX RANGE SCAN DESCENDING| SYS_C0045869 | 1 | | 1 (0)|
|* 14 | COUNT STOPKEY | | | | |
| 15 | VIEW | | 1 | 3 | 2 (0)|
| 16 | TABLE ACCESS BY INDEX ROWID | LDRISKSALESTATE | 1 | 13 | 2 (0)|
|* 17 | INDEX RANGE SCAN DESCENDING| SYS_C0045869 | 1 | | 1 (0)|
| 18 | TABLE ACCESS BY INDEX ROWID | LMRISKAPP | 1 | 48 | 1 (0)|
|* 19 | INDEX UNIQUE SCAN | PK_LMRISKAPP | 1 | | 0 (0)|
41
Predicate Information (identified by operation id):
2 - access(“B”.“RISKCODE”=:B1)
4 - access(“CODETYPE”=‘HMCP’ AND “CODE”=:B1)
5 - access(“RISKCODE”=“CODE”)
filter(“RISKCODE”=:B1)
6 - filter(ROWNUM=1)
9 - access(“RISKCODE”=‘411403’)
filter(“MANAGECOM”=‘86’ OR “MANAGECOM”=‘8611’ OR “MANAGECOM”=‘861101’)
10 - filter(ROWNUM=1)
13 - access(“RISKCODE”=‘411403’)
filter(“MANAGECOM”=‘86’ OR “MANAGECOM”=‘8611’ OR “MANAGECOM”=‘861101’)
14 - filter(ROWNUM=1)
17 - access(“RISKCODE”=‘411403’)
filter(“MANAGECOM”=‘86’ OR “MANAGECOM”=‘8611’ OR “MANAGECOM”=‘861101’)
19 - access(“RSK”.“RISKCODE”=‘411403’)
Statistics
322 recursive calls
0 db block gets
110 consistent gets
0 physical reads
0 redo size
1450 bytes sent via SQLNet to client
492 bytes received via SQLNet from client
2 SQLNet roundtrips to/from client
5 sorts (memory)
0 sorts (disk)
1 rows processed
效果对比: 索引创建后,执行时间从 34 秒下降到 0.04 秒,数据读取量从 1020699 下降到 110,下降到原来的近 1/10000, 效率提升千倍。
42
5. 对开发人员的性能优化要求
5.1.写好 SQL,不犯低级错误。
SQL 书写中常见的低级错误有:
对列进行运算(这里的意思是能避免就避免)
对列使用函数(这里的意思是能避免就避免)
数据类型不一致导致列发生隐式转化
查询列表中直接使用 * 查询所有字段,而间接包含了不需要的字段
进行不必要的排序
union 可用 union all 代替
使用不必要的 distinct
如果我们能避免以上低级错误,就算是写好了 SQL。
注意,以上并没有提到多表关联查询时表的顺序以及 where 后的条件的前后顺序编写。在 oracle 现有
主流版本中,表顺序、where 条件顺序对 SQL 执行没有任何影响,oracle 会自动分析判断使用最高效的执
行路径。
除了一些低级错误之外,下面对 SQL 书写方面普遍存在的讹传进行一下辟谣:
表的连接顺序、表的条件顺序
这种说法在 oracle9i 之后就过时了,现在已经很难找到 oracle8i 的数据库了,现在已经不在区分
书写顺序了。
Count() 与 count(列) 的性能比较
首先,要注意以上两种写法本身就不等价。 count() 是查询表中的记录数,空值也会被统计到;
而 count(列) 是统计该列值的个数,空值是不被统计的。
其次,性能比较的话,也会因为是否会使用到索引而不同。 如果表上有主键,count()、count(1),
count(主键列) 的性能是一样的,其执行计划都是选择主键索引进行快速索引全扫描。Count(其他
列) 的话,如果对应列上没有索引,列序越靠后,则用时越长。如果有索引,则将不会有什么差异。
In 与 exists 性能之争
43
在现有 oracle 主流版本中,已经没有什么区别了。
Not in 与 not exists 之争
以上两者性能上并没有明显差异。 但是,鉴于 not in ( ) 中存在空值时查询结果为空,推荐使用
not exists。
给大家辟谣之后,以后写 SQL 就不用再顾忌那么多了,是不是轻松许多? 那是肯定的!
5.2.会创建索引,尤其是要综合总体考虑,战略性的创建索引。
我们创建索引时,不但要着眼于某一条 SQL,更要着眼于访问表的绝大部分 SQL,根据 SQL 的占比,执
行频次来进行综合的分析考量。
索引是有成本的,索引不是越多越好。
正确的创建索引的理念力,是力求用最少量的索引,满足绝大部分 SQL 的性能要求。
5.3.理解索引对应用程序性能的重要性。
大家试想一下,在表中数据大幅增长的情况下,如何保证应用性能仍然可控? 即保证 SQL 性能不会明
显下降。
如果表上没有索引,也就是对数据的访问是全表扫描的方式,那么,随着表中数据量的增长,性能会
持续下降,应用的执行时间会增长,用户体验会越来越不好。
可以预见的是,这样的应用程序的生命周期是非常短暂的。
如果 SQL 使用到索引,那情形就不一样了。 因为对于索引访问方式,即使表中数据增长十倍的情况下,
SQL 性能也不会有明显下降。这就是索引的优势!!
开发人员将 SQL 写好后,还需要负责创建适当的索引吗? 当然!
因为就算你将 SQL 写好了,如果缺少必要的索引,oracle 优化器也不会创建出高效的执行计划。你让
oracle 将事情做好,最起码的优化手段得提供给他吧?
44
5.4.理解应用对表中数据的访问方式
如何理解访问方式呢?有以下几点:
通过哪些列对数据进行访问?
各种访问方式的频率如何?
访问列的离散程度如何?
理解之后做什么呢?
在应用开发阶段,就应该创建好相关索引。
综合考量对表的访问方式,创建战略性索引。
由于开发人员对表中数据的多少、数据的分布、数据的访问方式是最了解的,因此,我们可以说,开
发人员对 SQL 进行性能优化,比其他人员具有无可比拟的先天优势!
5.5.可发现 SQL 中存在的问题,能进行简单调优。
性能优化一个渐进的过程,这种能力,需要在掌握基本优化技能的基础上,多多练习体会。对开发人
员来说,具备优化意识,能发现 SQL 的性能问题,进行简单调优就基本可以了。
6. 结语
开发人员在 SQL 书写过程中规避掉一些低级错误,就基本上算是写好了 SQL。接下来,数据库优化器负责给 SQL 提供一个高效率的执行计划。
但是,假如开发人员没有创建合适的索引,数据库就没有办法提供最高效率的执行计划,因为高效执行计 划是建立在合适访问路径存在的基础之上的。
所以,开发工程师除了写好 SQL,还应该负责在适当的字段上创建索引。因为开发最了解应用程序对表中数 据的使用方式和表中数据的分布情况。
作为一个合格的开发人员,不仅应该关注完美功能的实现,还应该关注应用程序的执行效率、用户体验。 如果应用响应缓慢,那么,用户一定会失去耐心的。
45
其实,性能优化的过程,就是一个学会判断哪些是最消耗资源的操作,并想办法绕过它的过程。 只要这样, 我们就实现了优化。