七、高并发内存池--Page Cache
七、高并发内存池–Page Cache
7.1 PageCache的工作原理
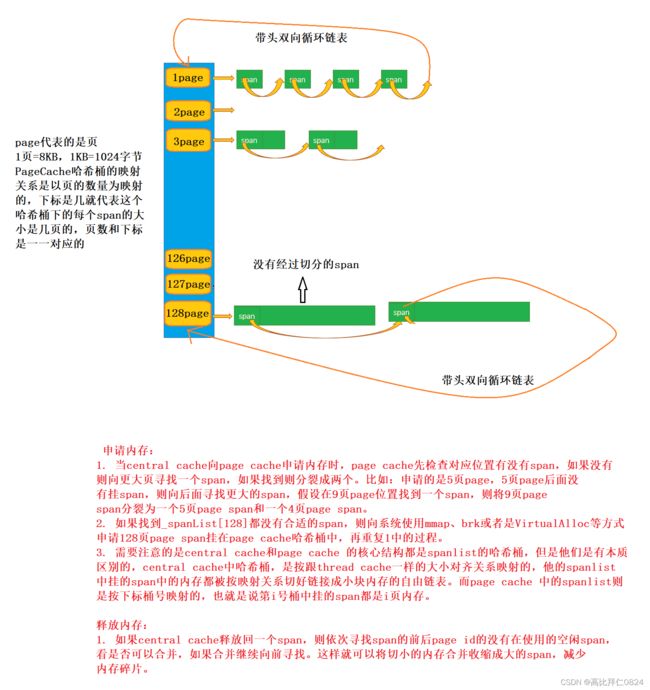
PageCache是以span的大小(以页为单位)和下标一一对应为映射关系的哈希桶,下标是几就说明这个哈希桶下挂的span的大小就是几页的,是绝对映射的关系。因为PageCache也是全局只有唯一一个的,所以为了防止出现线程安全的问题,在访问PageCache之前要先加上一把大锁锁住整个PageCache,为什么这里是加一把大锁锁住整个PageCache而不是加桶锁锁住要访问的那个桶呢?
因为当Central Cache向PageCache获取一个K页的span的时候,在PageCache中下标为K的哈希桶中不一定有span,此时PageCache并不是直接向系统堆中申请一块K页的span内存,因为如果这样处理的话会出现频繁地向系统申请内存的情况,并且每次向堆申请的内存都只是K页大小的,如果每一次的K都是1或者2,这样会使堆申请出来的内存都是很碎片化的,不便于堆做内存管理,所以PageCache的处理策略是如果当前下标的哈希桶中没有span对象,那么就从当前位置开始往后遍历,如果后面的哈希桶中有span对象就把这个span切成一个K页的kspan和一个(n-k)页的span,把kspan切成一个一个的小对象连接到kspan中的自由链表并把这个切好的kspan返回给CentralCache对应位置的哈希桶,剩下的(n-k)页大小的span就挂到PageCache中n-k位置的哈希桶。
如果把PageCache中剩下的所有的哈希桶都遍历完都没有找到一个span,那么就向系统申请一个128(这个128是自定义的)页大小的大span,重复上面的切分操作,最后返回一个切好的K页的span给CentralCache对应位置的哈希桶中,再让CentralCache分若干个小对象给ThreadCache,ThreadCache再返回一个给上层。
综上,也就不难发现PageCache不能用桶锁而是要用一把大锁,因为在CentralCache向PageCache中获取一个span时不仅仅是会访问PageCache中的某一个位置的哈希桶,而是有可能往后遍历其它的哈希桶并访问,所以加桶锁只是锁住了一个桶,并不能锁住后续遍历的其它位置的哈希桶,所以这里要加一把大锁。其实从技术上来说用桶锁也是可以的,只不过在遍历PageCache后面的每一个哈希桶前都要对先对这个桶加上桶锁,访问完之后还要解掉桶锁,如此一来,必然会出现大量的上锁解锁的操作,反而会降低了内存池的效率,所以加一把大锁就行了。
7.2 PageCache.h
//页缓存,CentralCache需要向PageCache申请K页大小的span,PageCache向系统申请128页大小的span
//因为PageCache也是全局只有唯一一个的,所以也把PageCache设计成单例模式
class PageCache
{
public:
static PageCache* GetInstance()
{
return &_sInst;
}
//提供给CentralCache向PageCache获取一个k页的span时使用
Span* NewSpan(size_t k);
//根据obj的地址转换成页号,进而通过哈希表找到页号对应的Span
Span* MapObjectToSpan(void* obj);
//CentralCache把span还回来给PageCache
void ReleaseSpanToPageCache(Span* span);
//PageCache是整个进程唯一的,所以所有的线程都有可能
//访问PageCache,存在线程安全问题,所以需要加锁,这里是加一把大锁而不是桶锁
std::mutex _pageMtx;
private:
//单例模式需要把构造函数私有化,防止别人创建对象
PageCache()
{}
PageCache(const PageCache&) = delete;
private:
SpanList _spanLists[NPAGES];//有多少也大小的span数组就有多大,下标和span的大小一一对应
//声明静态对象
static PageCache _sInst;
//如果PageCache中所有的哈希桶都没有span,需要从系统堆中申请内存时
//要脱离malloc,所以直接用我们写好的定长内存池申请内存即可,定长内存
//池中封装了系统调用接口,直接向堆申请内存和释放内存
ObjectPool<Span> _spanPool;
//保存页号和span的映射关系,为了后续能找到每一个还回来的小对象属于哪一个span
std::unordered_map<PAGE_ID, Span*> _idSpanMap;
};
7.3 PageCache.cpp
//静态对象需要在类内声明,类外面定义
PageCache PageCache::_sInst;
//k代表的是这个span的大小k页
Span* PageCache::NewSpan(size_t k)
{
assert(k > 0);
//如果申请的span的大小大于128页,则需要直接向堆申请
//因为PageCache只有128个有效的哈希桶
if (k > NPAGES - 1)
{
//向堆申请k页内存
void* ptr = SystemAlloc(k);
Span* kSpan = _spanPool.New();//_spanPoll是定长内存池对象,直接向堆申请内存
//地址转化成页号
kSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;
kSpan->_n = k;
//把页号和Kspan的映射关系放进Map中
_idSpanMap[kSpan->_pageId] = kSpan;
return kSpan;
}
else
{
//如果PageCache第k个位置的哈希桶上有k页大小的span,则直接返回一个span
if (!_spanLists[k].Empty())
{
Span* kSpan = _spanLists[k].PopFront();
//把kSpan的页号和对应的Span*的映射关系存放到哈希桶中去,方便
//CentralCache回收小块内存时,查找对应的span
//kSpan代表的是一个k页大小的Span的大块内存,kSpan->_pageId
//代表这个大块内存的起始地址,有k页,所以这k页映射到的都是这个Span
//
//这里曾经没有存映射关系,导致归还小内存块的时候找不到所属的span(细节)
for (PAGE_ID i = 0; i < kSpan->_n; i++)
{
_idSpanMap[kSpan->_pageId + i] = kSpan;
}
return kSpan;
}
//走到这里说明PageCache第k个位置的哈希桶没有k页大小的span,则需要遍历
//后面的大于k页的哈希桶,找到了一个n页大小的span就把这个span切分成一个
// k页大小的span和一个n-k页大小的span,k页的返回,n-k页的挂到对应的哈希桶中
//遍历后面的哈希桶
for (size_t i = k + 1; i < NPAGES; i++)
{
//找到了一个不为空的i页的哈希桶,就对它进行切分
if (!_spanLists[i].Empty())
{
//k页的span
Span* kSpan = _spanPool.New();
//n页的span
Span* nSpan = _spanLists[i].PopFront();//把这个i页大小的span拿出来进行切分
//开始把一个n页的span切分成一个k页的span和一个n-k页的span
//
//从nSpan的头上切k页给kSpan,所以kSpan的页号就是nSpan的页号
kSpan->_pageId = nSpan->_pageId;
kSpan->_n = k;//kSpan的页数是k
//被切分以后nSpan的页号需要+=k页,因为头nSpan的头k页已经切分给了kSpan
nSpan->_pageId += k;
nSpan->_n -= k;//nSpan的页数要-=k页,因为nSpan被切走了k页
//把kSpan的页号和对应的Span*的映射关系存放到哈希桶中去,方便
// CentralCache回收小块内存时,查找对应的span
//kSpan代表的是一个k页大小的Span的大块内存,kSpan->_pageId
//代表这个大块内存的起始地址,有k页,所以这k页映射到的都是这个Span
for (PAGE_ID i = 0; i < kSpan->_n; i++)
{
_idSpanMap[kSpan->_pageId + i] = kSpan;
}
//nSpan被切分后的首页和尾页的页号和nspan的映射关系也需要保存起来
//以便后续合并,因为合并的方式是前后页合并,往前找肯定找到的是一个span的
//最后一页,往后找一定找的是一个span的第一页,所以挂在PageCache对应哈希桶
//的span的第一页和最后一页与span的关系也需要保存起来
_idSpanMap[nSpan->_pageId] = nSpan;
_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan;
//把剩余的n-k页的span头插到对应下标的哈希桶中,nSpan->_n已经是改过的了,不用再-k
_spanLists[nSpan->_n].PushFront(nSpan);
return kSpan;
}
}
//走到这里说明前面的NPAGES个哈希桶中都没有Span,(例如第一次申请内存时)
//则需要向堆申请一个128页大小的span大块内存,挂到对应的哈希桶中
void* ptr = SystemAlloc(NPAGES - 1);
Span* bigSpan = _spanPool.New();
bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;//内存的地址需要转换成页号映射到对应的哈希桶中
bigSpan->_n = NPAGES - 1;//大块内存的页数,描述这个bigspan的大小
//把NPAGES-1页大小的span头插到对应NPAGES-1号桶中去
_spanLists[bigSpan->_n].PushFront(bigSpan);
//本质是运用了复用的设计,避免代码中出现重复的逻辑
return NewSpan(k);
}
}
Span* PageCache::MapObjectToSpan(void* obj)
{
//计算出obj对应的页号
PAGE_ID id = (PAGE_ID)obj >> PAGE_SHIFT;
//访问_idSpanMap的时候需要加锁,避免线程安全的问题
//这里使用C++11的RAII锁,出了这个函数这把锁会自动解掉
std::unique_lock<std::mutex> lock(_pageMtx);
//通过页号查找该内存块对应的是哪一个span
auto ret = _idSpanMap.find(id);
if (ret != _idSpanMap.end())
{
return ret->second;
}
else
{
assert(false);
return nullptr;
}
}
//CentralCache把span还回来给PageCache
void PageCache::ReleaseSpanToPageCache(Span* span)
{
//如果span的页数大于128页,则说明这个span是从堆上直接申请的,
//直接释放给堆即可,不能挂到PageCache的哈希桶中,因为PageCache一个只有128个桶
if (span->_n > NPAGES - 1)
{
void* ptr = (void*)(span->_pageId << PAGE_SHIFT);
SystemFree(ptr);
_spanPool.Delete(span);
return;
}
while (1)
{
//找前一页的span,看是否能够和当前页合并,如果能,则循环向前合并,直到不能合并为止
PAGE_ID prevId = span->_pageId - 1;
auto ret = _idSpanMap.find(prevId);
//_idSpanMap中没找到前一页和对应span,说明前一页的内存没有被申请,结束合并
if (ret == _idSpanMap.end())
{
break;
}
Span* prevSpan = ret->second;
//如果前一页对应的span在CentralCache中正在被使用,结束合并
if (prevSpan->_isUse == true)
{
break;
}
//如果和前一页合并之后会超过哈希桶的最大的映射返回,结束合并
if (prevSpan->_n + span->_n > NPAGES - 1)
{
break;
}
//合并span和prevSpan
span->_pageId = prevSpan->_pageId;
span->_n = prevSpan->_n + span->_n;
//合并之后需要把prevSpan在对应的哈希桶中删除掉
_spanLists[prevSpan->_n].Erase(prevSpan);
//因为prevSpan已经被合并到了span中,所以prevSpan对应的内存可以delete掉了
_spanPool.Delete(prevSpan);
}
while (1)
{
//找span的下一个span的起始页号
PAGE_ID nextId = span->_pageId + span->_n;
auto ret = _idSpanMap.find(nextId);
if (ret == _idSpanMap.end())
{
break;
}
Span* nextSpan = ret->second;
if (nextSpan->_isUse == true)
{
break;
}
if (nextSpan->_n + span->_n > NPAGES - 1)//曾经写成NPAGES+1了
{
break;
}
//span的起始页号不变,页数相加
span->_n = span->_n + nextSpan->_n;
//合并之后需要把prevSpan在对应的哈希桶中删除掉
_spanLists[nextSpan->_n].Erase(nextSpan);
_spanPool.Delete(nextSpan);
}
//合并得到的新的span需要挂到对应页数的哈希桶中
_spanLists[span->_n].PushFront(span);
//在PageCache中的span要设置为false,好让后面相邻的span来合并
span->_isUse = false;
//为了方便后续的合并,需要把span的起始页号和尾页号和span建立映射关系
_idSpanMap[span->_pageId] = span;
_idSpanMap[span->_pageId + span->_n - 1] = span;
}
以上就是高并发内存池三层模型的核心部分,后面的文章是对该高并发内存池的性能测试以及针对性能的瓶颈区做出相应的优化策略。