C++全部基础知识汇总 全篇超3万字超详细!(干货笔记分享)零基础学C++这一篇就够了
创作不易,本篇文章如果帮助到了你,还请点赞 关注支持一下♡><)!!
主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步!
c++系列专栏:C/C++零基础到精通给大家跳段街舞感谢支持!ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ
c语言内容:
专栏:c语言之路重点知识整合
本文是对主页C++专栏的汇总整理:c++系列专栏:C/C++零基础到精通
目录
- 一、C语言和C++的区别 | 面向过程与面向对象
-
- 1.C语言
- 2.C++
- 3.面向过程与面向对象
- 4.封装、继承、多态
- 二、输入输出流iostream
-
- 1.iostream
- 2.c++输入输出
- 3.小结
- 三、命名空间与作用域
-
- 1.作用域
- 2.命名空间
- 3.为什么需要using namespace std ?
- 四、动态申请内存空间new-delete
-
- 1.c语言动态申请内存空间
- 2.new-delete
- 3.new指针、new数组
- 3. 总结
- 五、bool布尔类型
-
- 1.自制BOOL类型
- 2.bool
- 3.BOOL和bool类型的区别
- 六、string字符串
-
- 1.回顾C语言中的字符串
- 2.C++中的字符串
- 3.C语言和C++中字符串的各种区别
- 七、增强for(范围for循环)
-
- 1.增强for概念
- 2.增强for用法
- 3.总结
- 八、函数参数默认值
-
- 1.介绍
- 2.显式提供参数值
- 3.从右向左依次指定!
- 4.声明处赋值!
- 5.总结
- 九、函数重载
-
- 1.概念
- 2.用法
- 3.总结
- 十、关键字nullptr
-
- 1.nullptr介绍✧
- 2.为什么需要nullptr ?
- 3.NULL和nullptr的区别✧
- 十一、引用(&)
-
- 1.概念
- 2.函数值传递、地址传递、引用传递的比较
- 3.引用与指针的区别
- 4.总结
- 十二、类和对象的概念、基本用法
-
- 1.类和对象的概念
- 2.定义和使用类
- 3.类成员访问修饰符
- 十三、构造函数与析构函数
-
- 1.构造函数
- 2.析构函数
- 十四、类成员属性
-
- 1.空类实例占用空间大小
- 2.类成员属性
- 3.类成员属性总结
- 十五、类成员函数和this指针
-
- 1.类成员函数
- 2.this指针
- 十六、类成员函数指针
-
- 1.为什么要使用类函数指针
- 2.类函数指针定义
- 3.全局函数 和类成员函数区别
- 十七、构造函数的分类及调用
-
- 1.按参数分
- 2.按类型分
- 3.三种调用方式:
- 十八、拷贝构造函数
-
- 1.拷贝构造函数的调用
- 2.构造函数的调用规则
- 十九、深拷贝与浅拷贝
-
- 1.浅拷贝
- 2.深拷贝
- 二十、类之间的横向关系
-
- 1.组合
- 2.关联
- 3.依赖
- 4.聚合
- 二十一、类之间的纵向关系——继承
-
- 1.继承的概念
- 2.子类和父类内存空间分布
- 二十二、多态与虚函数
-
- 1.多态的概念
- 2.虚函数
-
- 1.虚函数大小
- 2.虚函数指针
一、C语言和C++的区别 | 面向过程与面向对象
1.C语言
C语言采用了一种有序的编程方法——结构化编程
就是将一个大型程序分解为一个个小型的、易于编写模块,所有的模块有序的调动起来形成了一个程序的完整的运行链。
这种结构化编程反映出来过程性编程的思想,即C语言是一门面向过程的语言,更注重程序实现逻辑、怎么更好、更快、更直接的完成某功能
C语言是种面向过程编程的语言,在编写大型项目时,并不利于程序的复用性、扩展性,导致了在后期维护时带来了很多繁琐的工作,面临巨大挑战。
----》》
针对于此,OOP (Obiect-Oriented Programming)的概念诞生了,与结构化编程不同的是,OOP更注重数据,让语言来满足问题的需求,设计出与问题本质特性相对应的数据格式。
它与结构化编程不同,强调数据的重要性,并设计相应的数据格式来解决问题。
OOP的编程思想是将问题看作是由许多相互关联的对象组成的
每个对象拥有自己的属性和行为,可以与其他对象交互完成任务
C语言作为一门古老但经典的编程语言,拥有简洁、高效、底层等优秀特性
虽然不如C++那么具有面向对象编程的特性,但在许多领域仍然扮演着重要的角色,是必须掌握的基础知识之一。

OOD (Object-Oriented Design) :面向对象的设计
OOA (Object-Oriented Analysis): 面向对象的分析
2.C++
C++ 是一门面向对象编程的语言,把问题分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描述某个事物在整个解决问题的步骤中的行为,更注重的是程序的整体设计。
方便程序后期维护、优化和管理,让一个功能尽可能的通用。
面向对象编程只有一个价值:应对需求的变化,本意是要处理大型复杂系统的设计和实现。
OOP语言提供了构建对象的机制,将问题分解为可的部分,从而更好地满足问题的需求。
关于C++的用途:
-
C++是一门强类型语言,需要进行显式类型声明并支持运算符重载、多态等高级特性;
-
C++支持指针和引用,灵活处理内存管理和数据传递
-
C++具有较好的可移植性和跨平台性,可以编写高效的系统和底层代码
-
C++广泛应用于游戏开发、图形界面设计、嵌入式系统、科学计算、金融工程等领域
-
C++也是许多大型软件系统和框架的基础语言,如OpenGL、Qt、Boost等

3.面向过程与面向对象
面向过程和面向对象,其本质还是在其设计思想上的区别!
面向过程
优点:性能比面向对象高,比如单片机、嵌入式开发、 Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
缺点:没有面向对象易维护、易复用、易扩展

面向对象的优缺点与面向过程相对
面向对象
优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护。
缺点:因为类调用时需要实例化,开销比较大,比较消耗资源,性能比面向过程低。

C++是由C衍生出来的一门语言,不但兼容包含了C语言还增加了一些新特性:函数重载,类、继承、多态,支持泛型编程 (模板函数、模板类),强大的STL库等…
4.封装、继承、多态
面向对象的三大特性:封装、继承、多态
封装
通过将数据和方法存储在类中,隐藏了实现细节,使得代码更加清晰和安全
继承
允许通过继承基类,从而建立更丰富的类层次结构和代码复用机制
多态
使用基类指针或引用来调用派生类方法,实现运行时的动态绑定和更好的可扩展性
STL(标准模板库)提供了泛型算法和数据结构,大大提升了C++语言的表达能力和灵活性。
二、输入输出流iostream
1.iostream
添加c++的头文件#include后,c语言中的scanf和printf仍然可以使用:
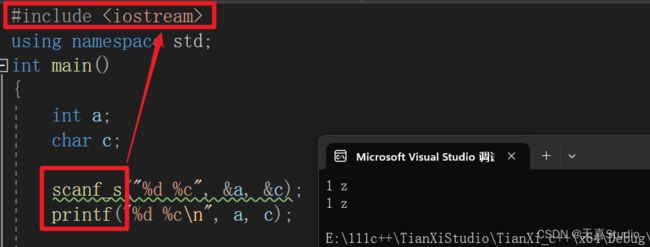
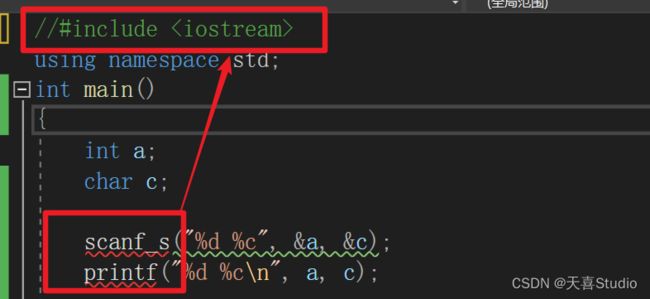
这说明了头文件iostream包含了c语言中的头文件stdio.h,所以仍然可以使用c语言中的scanf和printf函数
2.c++输入输出
1.先包含头文件
#include 2.打开标准命名空间std
using namespace std;
后面会提到命名空间的知识
然后就可以进行输入输出的操作了

cin输入需要结合<<操作符一起使用
cout输出需要结合>>操作符一起使用
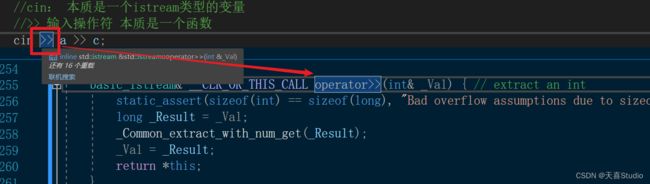
#include 其中:cin本质是一个istream类型的变量 与scanf不同的是cin不需要进行格式化和取地址操作
>> 输入操作符 本质是一个函数
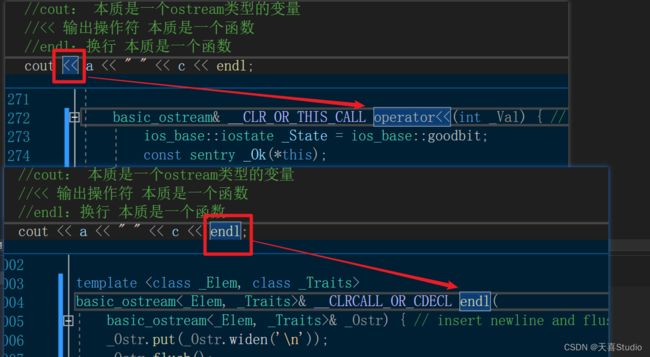
cout本质是一个ostream类型的变量 不要进行类型格式化可以直接输出变量的值
还可以格式化输出 控制数值的进制、小数位数和对齐方式等
<< 输出操作符 本质是一个函数
endl 换行 本质是一个函数 速览定义:插入换行符并刷新输出流
3.小结
C语言的输入输出主要基于stdio库,使用标准I/O函数printf、scanf
而C++继承了C语言中的的标准I/O函数,同时引入了iostream库,还提供了运算符>> 和 <<,方便我们对数据的输入输出流进行处理
C++中常见的输入流有istream、ifstream等,输出流则有ostream、ofstream等,它们都是基于类的方式来实现I/O操作。
-
C++的输入输出更加灵活,提供了简洁的语法和易于理解的接口,使得I/O操作更加方便易用
-
采用了面向对象的思想,通过类的封装和继承机制,可以轻松实现对于不同类型数据的输入输出
-
自动类型转换:根据需要隐式地进行数据类型转换,而不用强制转换
我们可以根据不同的场景,灵活地选择使用哪种输入输出方式
三、命名空间与作用域

1.作用域
在之前的c语言中提到过全局变量 【c语言】全局变量的生命周期与作用域
全局变量的生命周期长,从程序启动到程序关闭
在主函数外定义为全局变量,存放在全局/静态区,未初始化默认是0
我们也可以在C++中定义一个全局变量:
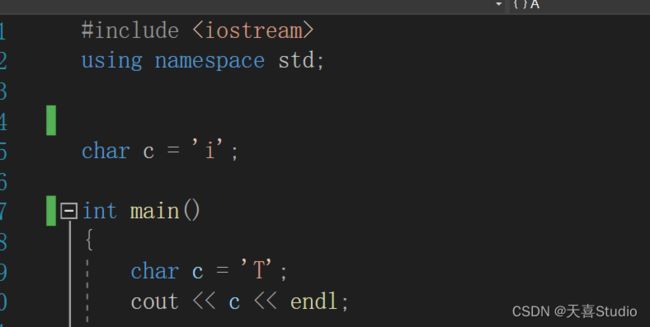
根据【c语言】全局变量的生命周期与作用域 中提到的就近原则,这段代码的输出结果为字符T
如果此时在主函数中有这样一个需求:既要输出局部变量’ T ‘,又要输出全局变量’ i ',应该如何实现呢?
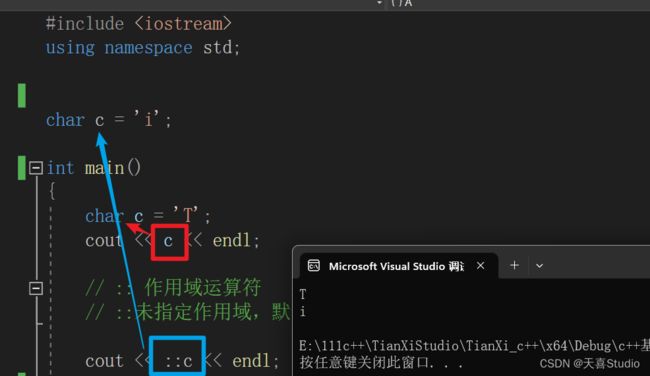
可以使用::即作用域运算符来控制输出
**作用域运算符 **
某个作用域 :: 成员变量 使用该作用域内的成员变量
::未指定作用域,默认全局作用域
#include 使用::来指定一个作用域,std就是一个作用域,即全局作用域,直接使用:c就能输出全区变量中的字符c(i)
而未添加::直接输出的就是局部变量中的字符c(T)
常用的作用域有命名空间、结构体、类等
对于全局和局部作用域可以定义相同的成员
但如果是同一个作用域中存在相同的成员,则会报重定义的错误
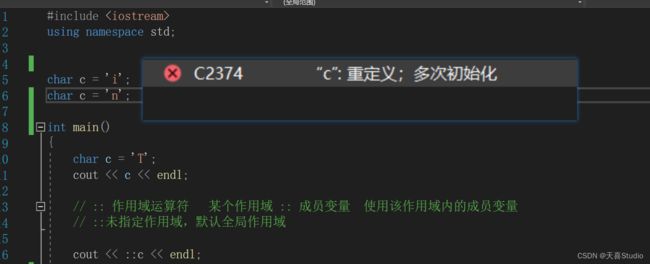
此时可以使用命名空间去区分
2.命名空间
命名空间可以用来区分同一作用域下的相同成员
通过
namespace 命名空间名 {
变量..
函数..
结构体...
};
这种格式来定义命名空间
其中,namespace是C++中的关键字,用来定义命名空间。

例如:定义A B两个命名空间,并定义成员 字符c:
#include 使用命名空间
使用命名空间有两种方法
1.打开命名空间 using namespace…
这种方法就是我们使用的的using namespace std;
同理,打开命名空间A就是using namespce A;打开命名空间B就是using namespace std;
#include 打开命名空间 A后,
#include 这里的::c输出结果就为命名空间A中的字符’a’
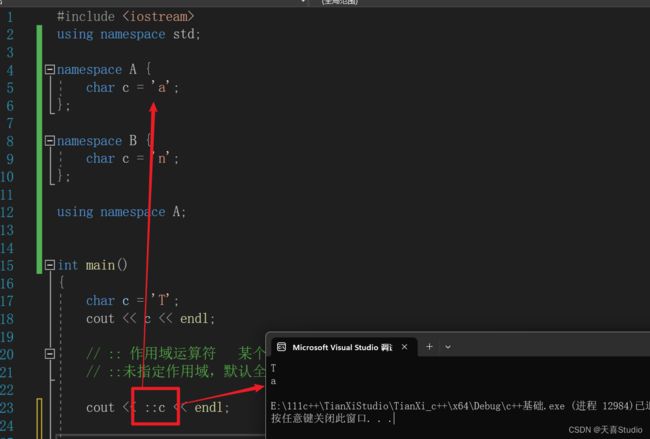
使用命名空间的另一种方法:
2.使用作用域 某作用域::成员
前面提到了作用域操作符::可以通过这种方法来控制输出A或B作用域中的成员输出
例如:使用A命名空间中的字符c输出,结果也是命名空间A中的字符’a’
cout << A::c << endl;
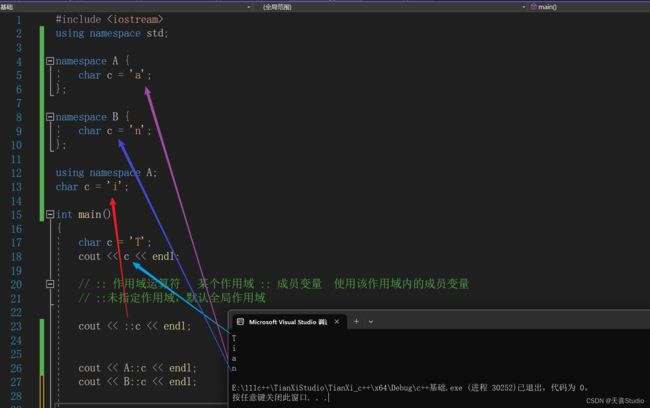
3.为什么需要using namespace std ?
其实,观察我们常用的cin和cout输入输出函数还有endl换行,他们就是使用了std这个标准命名空间:
因此,如果没有添加using namespace std;这句话,即没有打开标准命名空间,直接使用cin 和cout endl就会进行报错
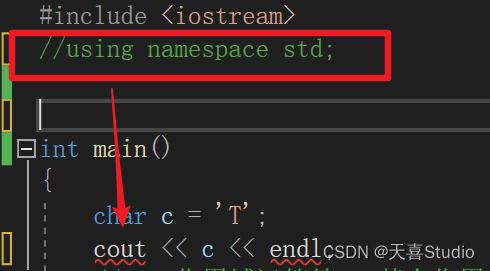
在我们了解了使用命名空间的方法后,也就理解了为什么在编写C++程序时,需要在头文件下面添加using namespace std;
就是因为输入输出cin cout依赖std标准命名空间
我们学习了两种打开命名空间的方法,另一种使用作用域操作符::是否可行呢?

答案是 当然可以,这两种方法都可以打开某个命名空间
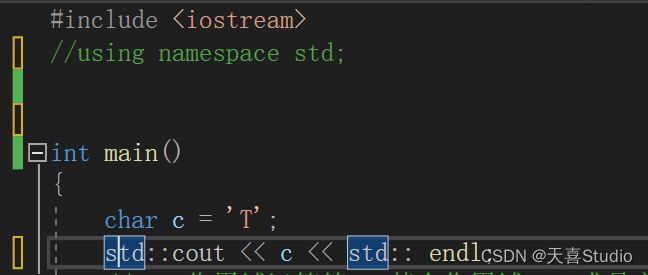
这种方式简单直接,但是每次使用的时候都需要指明命名空间
注:using namespace 命名空间,这是一种懒惰的做法
打开一次里面的成员将全部对外开放。打开了多个命名空间如果成员名相同会出现二义性
四、动态申请内存空间new-delete
1.c语言动态申请内存空间
c语言堆区malloc相关知识点:【c语言】五大内存区域 | 堆区详解
使用malloc将堆区创建一个存储空间并把局部变量存放进去,该数据如果不被手动回收,就会一直存放在堆区中。
释放完后将指针p赋值为NULL,避免野指针的出现
int* p = (int*)malloc(sizeof(int));
//...........
free(p);
p = NULL;
在C++中,有一种全新的方式用来在堆区动态申请内存空间——new和delete关键字

2.new-delete
使用new关键字动态在堆区申请内存空间,new关键字后 放 类型,返回的是对应类型的地址!!!
格式:new关键字 后加上类型名,在堆区申请该类型空间大小的空间
代替c语言中的malloc 还不用进行强转
例如:
int* p1 = new int;
*p1 = 1;
cout << *p1 << endl;
使用delete代替c语言中的free释放空间
但是delete不是函数,关键字后直接加上要释放空间的指针地址,仍然将指针p赋值为NULL:
int* p1 = new int;
*p1 = 1;
cout << *p1 << endl;
delete p1;
p1 = NULL;
基本数据
在int类型后加(),可以赋予初始值
int* p2 = new int(7);
cout << *p2 << endl;
delete p2;
p2 = NULL;
如果未指定初始值,则初始值为0:
int* p3 = new int();
cout << *p3 << endl;
delete p3;
p3 = NULL;

数组
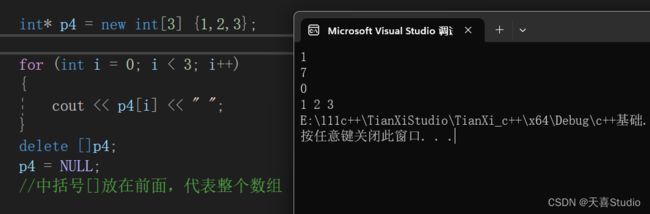
申请一个int型数组的堆区空间:
int* p4 = new int[3];
同样可以赋予初始值:
int* p4 = new int[3] {1,2,3};
for (int i = 0; i < 3; i++)
{
cout << p4[i] << " ";
}
与基本数据类型不同的是:在delete数组的时候,需要在指针前加[]用来代表数组,二维数组同样
中括号[]放在前面,代表整个数组
例如:
delete []p4;
p4 = NULL;
注:
delete回收空间并不包含指针本身,而是指针指向的内存空间,同一块内存空间不要重复释放,除非指针已经被赋空,对空指针使用delete是安全的。
对栈区的内存空间不能使用delete来释放!
3.new指针、new数组
只需要牢记:
使用new关键字动态在堆区申请内存空间,new关键字后 放 类型,返回的是对应类型的地址!!!
就两种情况
- new指针——
- new数组——
1.new 整型指针
整型指针对应的地址:二级指针,因此为int ** p1
int** p1 = new int*;
delete p1;
p1 = NULL;
2.new 指针数组
指针数组相关知识点:【c语言】指针数组
指针数组对应的地址也是二级指针,因此为int ** p2
int** p2 = new int* [3];
delete []p2;
p2 = NULL;
** 3.new 数组指针**
数组指针相关知识点:【c语言】数组指针
数组指针int(*p3)[3]的指针 在类型上再加*:int(**p3)[3]
int(**p3)[3] = new (int(*)[3]);
delete p3;
p3 = NULL;
** 4.new 整型的二维数组**
指向二维数组的指针为:一维数组指针int(*p4)[3]
int(*p4)[3] = new int[2][3];
delete[]p4;
p4 = NULL;
** 5.new 函数指针**
先随便定义一个函数:
void fun(int a)
{
cout << "TianXi Studio" << endl;
}
指向函数指针的地址:在函数指针void(*p5)(int)基础上加*:void(**p5)(int)
void(**p5)(int) = new (void (*)(int));
delete p5;
p5 = NULL;
3. 总结
malloc-free和new-delete的区别
-
new、delete是关键字,需要C++的编译器支持,malloc()、free()是函数,需要头文件支持 -
new申请空间不需要指定申请大小,根据类型自动计算,new返回的是申请类型的地址,不需要强转,malloc()需要显式的指定申请空间的大小(字节),返回void*,需要强转成我们需要的类型。 -
new申请空间的同时可以设置初始化,而malloc 需要手动赋值 -
malloc()和free()则不会调用构造、析构函数
在C语言中,常用的动态申请内存空间的函数是malloc、calloc和realloc,并且需要手动free释放已分配的内存空间
而在C++中,可以使用new操作符来动态创建一个对象或一段对象数组
new可以自动调用构造函数初始化对象,而delete操作符则会自动调用析构函数,释放分配的内存空间(后面会提到)
使用delete释放动态分配的对象数组时记得加上方括号,否则只会释放首个元素并不会将整个数组的内存空间都释放掉。
五、bool布尔类型
1.自制BOOL类型
在c语言中没有布尔类型,但我们使用过宏定义来创建一个布尔型数据【c语言】详解宏定义
#include
这种方式太不优雅,C++中优化提出了boolean类型供我们直接使用

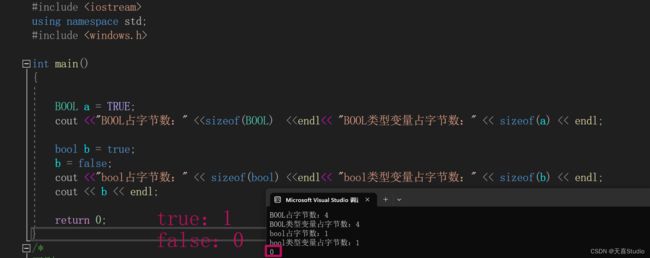
注:(C++中的BOOL类型,需要包含头文件#include
在Windows API和MFC(Microsoft基础类库)中广泛使用BOOL类型)
2.bool
bool是C++中内置的布尔类型,其值只能是true或false,通常使用1和0表示
bool b = true;
b = false;
由于BOOL类型是int类型的typedef,因此需要占用int(4字节)的内存空间
true和false只是代表了1和0,不需要占用4字节的空间,造成空间浪费
bool关键字的提出就解决了这个问题,他不再是int的重命名,而是一个独立的数据类型
bool只占用最小的:1字节 的内存空间
3.BOOL和bool类型的区别
在现代的C++标准中,可以使用bool类型代替BOOL类型,因为bool更好地表达了真/假这个概念,并且在运行时使用bool类型需要更少的内存
- 本质: BOOL是整型的别名 typedef
-而bool 是关键字 - BOOL 定义变量申请空间大小4字节
bool 1字节
六、string字符串
先来复习C语言中的字符串:
【c语言】字符串的基本概念 | 字符串存储原理
【c语言】字符串常用函数组件化封装
1.回顾C语言中的字符串
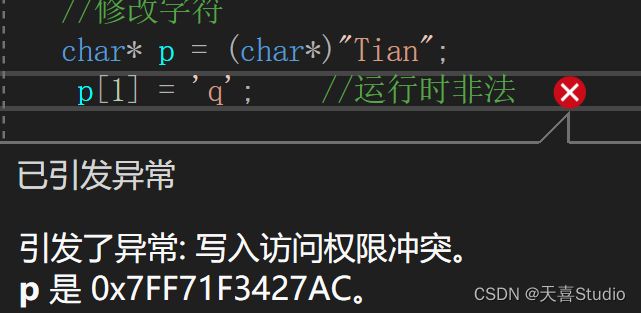
1.修改字符
定义一个char类型指针p指向字符串Tian
C语言中字符串是常量,不能通过指针修改字符串中的字符:
char* p = (char*)"Tian";
p[1] = 'q';
这段代码会在运行时出错(编译时不会):
再定义一个指针p2指向字符串Xi
通过改变指针的指向可以改变输出的字符串:
char* p2 = (char*)"Xi";
p2 = (char*)"Studio";
将指针p2的值更改为指向字符串字面值“Studio”的第一个字符
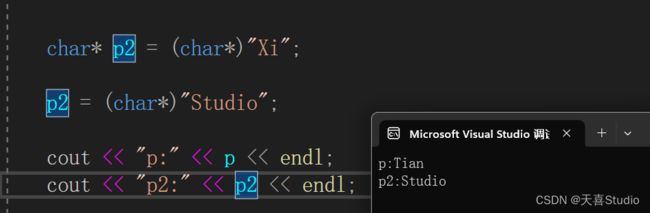
p和p2在栈区被创建,由于字符串在程序刚开始运行时在常数区被创建,所以p、p2可以直接来指向Hello\0。
再定义一个字符数组arr,存放字符串TianXi(字符数组与字符串的区别是 是否有'\0')
char arr[7] = "TianXi";
arr[1] = 'V';
cout << "arr:" << arr << endl;
通过对字符数组arr的第二个字符修改,可以得到修改后的字符数组

如果直接使用数组名修改字符数组:
arr="123";
将会产生编译错误,不可以对数组分配新的字符串
数组名是地址常量,字符串是字符串常量,将一个字符串常量赋给另一个地址常量,会出现左值不可更改的错误
2.比较字符串
字符串比较是对两个或多个字符串进行逐个字符的比较判断是否相等
strcmp() 函数根据两个字符串的第一个不同字符的 ASCII 码对比大小
返回 1 代表 大于关系 ; 返回 0代表等于关系;返回-1代表小于关系
【c语言】字符串比较知识点
通过库函数strcmp函数进行字符串的比较:
if (strcmp(p, p2)==0)
{
cout << "p==p2" << endl;
}
else
{
cout << "p!=p2" << endl;
}
直接使用==比较的是地址 不是字符串
if(p==p2)
2.C++中的字符串
C++中内置了字符串string类型
需要包含字符串的头文件#include 再打开标准命名空间using namespace std;
然后就可以直接使用string定义字符串:
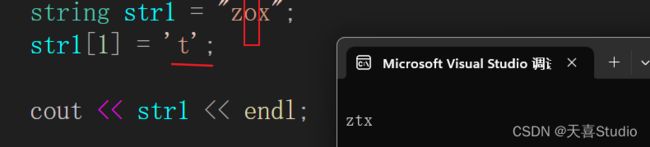
#include 1.修改字符
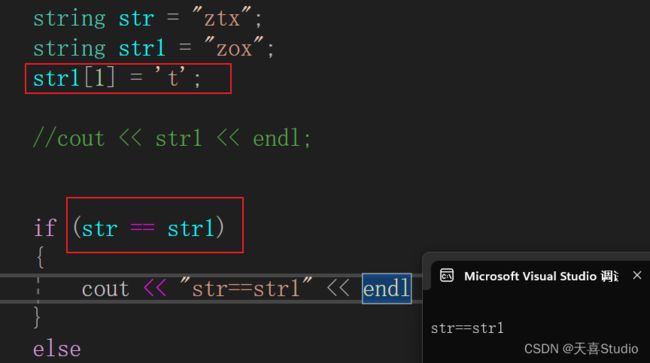
直接通过str1[1] = 't';就可以修改字符串中的某个字符
2.字符串比较
直接通过字符串的名字就可以进行对字符串的比较:
if (str == str1)
{
cout << "str==str1" << endl;
}
else
{
cout << "str!=str1" << endl;
}
3.字符串拼接
在C++中,不需要再使用C语言中的标准库函数strcat,直接使用+号就可以完成字符串拼接的操作
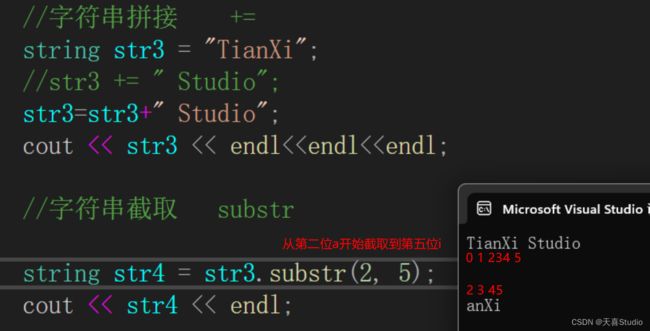
string str3 = "TianXi";
str3=str3+" Studio"; //str3 += " Studio";
cout << str3 << endl;

4.字符串截取
需要使用到.substr函数

string str4 = str3.substr(2, 5);
cout << str4 << endl;
5.字符串长度(大小)
使用.length()和.size()函数
string str3 = "TianXi";
cout << endl << "str3的长度:" << str3.length() << " " << str3.size() << endl;

6.字符串转换为const char*并返回
使用.c_str函数
str3=str3.c_str();
cout << str3 << endl;
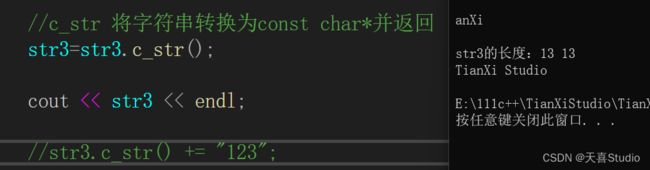
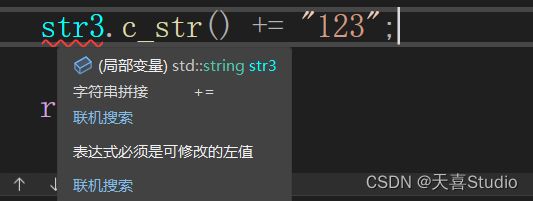
const常量不可修改: 产生不可修改的左值错误
3.C语言和C++中字符串的各种区别
C语言:字符串是以字符数组的形式存储的,以'\0'结尾
字符串比较通常使用strcmp函数,字符串拼接使用strcat函数,字符串长度计算使用strlen函数
C++:字符串类型被视为对象,并且C++STL库中提供了string类来实现字符串操作。与C语言不同,在C++中使用string类时可以使用运算符重载函数来完成字符串操作
例如使用+运算符进行字符串连接,使用==运算符比较两个字符串是否相等,并使用size()函数获取字符串的长度
七、增强for(范围for循环)
1.增强for概念
通常在我们遍历数组的时候,常用的写法是:
int main()
{
char arr[7] = "TianXi";
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
cout << arr[i] << " ";
}cout << endl;
}
在C++新标准中,简化后的写法为:
type iterable[n];
for(type val:iterable) //type val = arr[i]
{
// do something with val
}
这种for循环就被称为增强for,也叫范围for循环
在增强for循环中,我们不需要再通过计算数组长度遍历数组,增强for循环会自动根据数组长度将数组中的每一个数据赋值给同类型的val,我们只需要输出val就遍历了数组
iterable不止可以为数组,还可以是迭代的对象(比如支持begin、end操作的容器、string类型等)

2.增强for用法
上面遍历数组的代码通过简化就可以写成这样:
for (char v : arr)
{
cout << v << " ";
}cout << endl;
char类型的v变量存储了arr数组中的每一位
自动根据数组长度遍历数组
输出结果为:

容器类型、数组类型
增强for循环可以遍历支持迭代器的容器类型或数组类型,例如std::vector、std::list、std::array、int[]
而指针类型既不是容器类型又不是数组类型,不能使用增强范围for,可以使用传统的for循环
char* p = new char[7] {"TianXi"};
for (char v : p)
{
cout << v << " ";
}cout << endl;
这个例子中p 是一个 char 类型指针,指向一个拥有7个元素的字符数组并且进行了初始化
由于 p 是一个指针变量,而非容器类型,无法直接使用范围for循环进行遍历操作

如果要遍历字符串,不用char指针指向char数组,直接使用string字符串:
(string字符串相关知识点:【C/C++】基础知识之string字符串)
char* p = new char[7] {"TianXi"};
//for(char v:p) 无法遍历
string str = "TianXi";
for (char v : str)
{
cout << v << " ";
}cout << endl;
3.总结
- 增强for循环可以遍历支持迭代器容器类型或数组类型,不支持指针类型
使用增强for循环能够简化代码编写和阅读,并且可以避免因手动控制迭代器而带来的错误。
在需要进行下标访问、修改元素等操作时还是传统for循环更方便,不适合使用增强for循环
因此,使用哪种for循环,如何使用for循环,需要根据具体情况选择使用
八、函数参数默认值
1.介绍
C++中的函数参数可以设置默认值,这意味着在调用函数时,如果没有提供该参数的值,则将使用默认值
例如:对一个函数fun1赋予参数默认值,格式为:
void fun1(int a=1)
{
//something...
}
对这个已有默认值的函数调用查看(输出函数名和默认参数):
#include 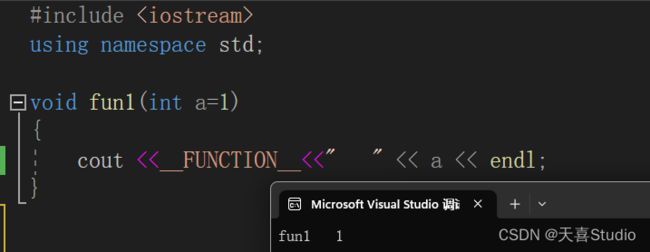
2.显式提供参数值
如果不想使用声明的默认值,只需要在调用时提供参数,就会根据你提供的参数执行,而不是默认值
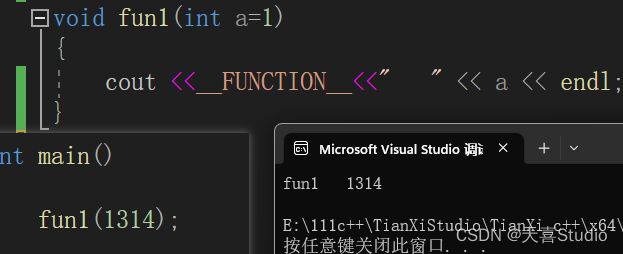

3.从右向左依次指定!
函数参数指定默认值顺序:从右向左依次指定,中间不能有间断
void fun(int a, int b=2, int c=3)
{ //函数参数指定默认值顺序:从右向左依次指定,中间不能有间断
cout << __FUNCTION__ << " " << a<<" "<<b<<" "<<c << endl;
}
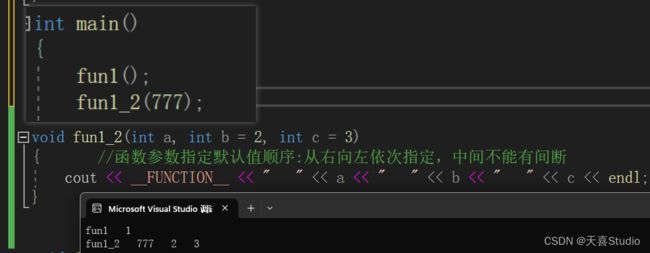
如果不是从右向左指定,函数调用时就会出现二义性
void fun1_2(int a, int b = 2, int c ); //error
当调用该函数时编译器无法确定应该为a和c哪个参数传入缺失的值:
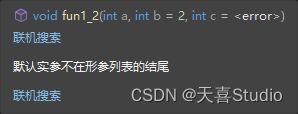
因此对函数设置参数默认值时,要按照从右到左的顺序!
4.声明处赋值!
当函数的声明和定义分开时,一般在声明处赋予函数参数默认值
void fun2(int a=2); //声明
int main()
{
fun2(); //调用
return 0;
}
void fun2(int a) //定义
{
//something...
}
重定义
如果在声明和定义都赋值,将会出现重定义的错误
void fun2(int a=2); //声明
int main()
{
fun2(); //调用
return 0;
}
void fun2(int a=1) //定义
{
//something...
}

函数不接受 0 个参数
如果是在定义处赋值,错误原因:函数不接受 0 个参数
void fun2(int a); //声明
int main()
{
fun2(); //调用
return 0;
}
void fun2(int a=1) //定义
{
//something...
}

因此,在对函数设置参数默认值时,要在声明处进行赋值!
5.总结
使用函数参数默认值,可以使得某些参数可以在调用函数时省略,使用预设好的默认值。
设定函数参数默认值时,要注意以下几点:
-
在函数调用如果不想采用默认值,则需要显式地提供参数值!
-
如果函数有多个参数,从右向左依次指定默认值,中间不能有间断!
-
一般只在声明处指定一次,否则会产生二义性错误!
九、函数重载
1.概念
函数重载是指 在同一个作用域下,函数名相同,参数列表不同(类型、数量、顺序),返回值类型无所谓 的函数
重载的函数在调用时,编译器可以根据实参自动去匹配对应的函数
2.用法
根据函数重载的定义,定义一组函数:
他们函数名相同,但是返回值和参数列表都不同
int add(int a, int b)
{
return a + b;
}
double add(double a, double b)
{
return a + b;
}
这两个函数就构成了函数重载,在主函数中可以直接调用add函数进行加法计算,编译器会根据参数列表的不同自动匹配不同的函数(根据int型参数匹配int add函数,根据double类型参数匹配double add函数)
int main()
{
cout << add(1, 2) << endl;
cout << add(1.1, 1.2) <<endl;
return 0;
}
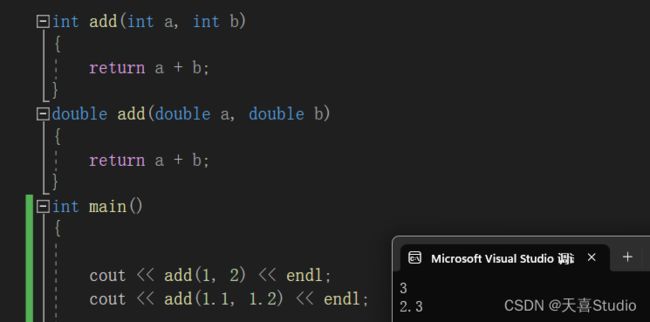
选中第一条add(1, 2)语句,可以看到匹配了int add函数
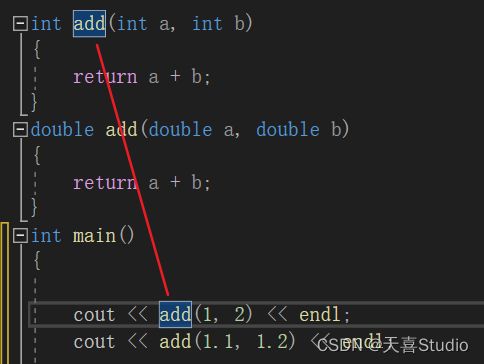
选中第二条add(1.1, 1.2)语句,就匹配了double add函数

输出结果:
以下是一些函数重载的例子
void fun(int a)
{
cout << __FUNCSIG__ << endl;
}
void fun(char a, int b)
{
cout << __FUNCSIG__ << endl;
}
void fun(int a,char b) {
cout << __FUNCSIG__ << endl;
}
在学过【C/C++】函数参数默认值 的知识后,我们再来研究一下有函数参数默认值的函数重载:
有函数参数默认值的函数重载
void fun(int a)
{
cout << __FUNCSIG__ << endl;
}
void fun(int a,char b) {
cout << __FUNCSIG__ << endl;
}
//对上面的函数指定一个默认值:
void fun(int a, char b='b')
{
cout << __FUNCSIG__ << endl;
}
int main()
{
fun(7,x);
return 0;
}
如果给void fun函数中的参数b指定默认值:char b='b'
此时的void fun(int a, char b='b')函数与void fun(int a,char b)函数构成函数重载吗?还是与void fun(int a)函数构成函数重载?
通过运行可以查看到错误为 函数“void fun(int,char)”已有主体,因此void fun(int a, char b='b')函数与void fun(int a,char b)并不构成函数重载,他们的参数列表和返回值都相同!

如果是void fun(int a)函数与void fun(int a, char b='b')函数呢?构成重载吗?
初步思考,这两个函数参数列表好像不同,只是这两个函数与调用时的参数列表匹配
void fun(int a)
{
cout << __FUNCSIG__ << endl;
}
void fun(int a, char b='b')
{
cout << __FUNCSIG__ << endl;
}
int main()
{
fun(7);
return 0;
}
此时运行查看:错误为C2668 “fun”: 对重载函数的调用不明确,看来他们构成了函数重载,只是调用不明确,如何对某一个函数明确调用呢?

类比局部变量声明,函数也可以进行局部函数声明!
只需要在主函数中进行局部函数声明,使用{ }指定在某段代码块中使用该函数
比如,我现在要使用void fun(int a)函数
void fun(int a)
{
cout << __FUNCSIG__ << endl;
}
void fun(int a, char b='b')
{
cout << __FUNCSIG__ << endl;
}
int main()
{
{
//函数局部声明
void fun(int a);
fun(7); //void __cdecl fun(int)
}
return 0;
}

如果同时需要在主函数中使用void fun(int a)和void fun(int a, char b='b')这两个函数
只需要在不同的位置都进行函数声明,使用{ }分隔开
void fun(int a)
{
cout << __FUNCSIG__ << endl;
}
void fun(int a, char b='b')
{
cout << __FUNCSIG__ << endl;
}
int main()
{
//.....
{
//函数局部声明
void fun(int a);
fun(7); //void __cdecl fun(int)
}
//.....
{
//函数局部声明
void fun(int a, char b = 'b');
fun(7); //void __cdecl fun(int,char)
}
return 0;
}
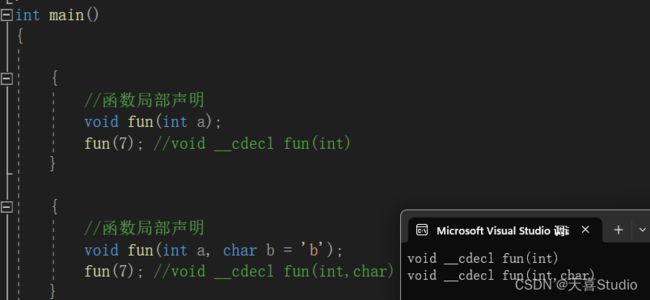
这样就在同一个主函数中使用了 在指定函数参数默认值后导致参数列表相同的重载函数
不构成函数重载的例子
*p和p[]都是地址p,参数列表相同,不构成函数重载
void fun(int* p)
{
//...
}
void fun(int p[])
{
//...
}
char 与 const char 相同,类型和常量修饰符都相同,认为是相同的函数签名,不构成函数重载
void fun(char a)
{
//...
}
void fun(const char a)
{
//...
}
(错误原因都是函数已有主体,也就是函数重定义)

在学过函数参数默认值的函数重载后,上面的代码可以改成如下,就构成了函数重载
void fun(const char a, int b = 0)
{
//...
}
3.总结
函数重载是指 在同一个作用域下,函数名相同,参数列表不同(类型、数量、顺序),返回类型可同可不同 的函数
-
重载的函数在调用时,编译器可以根据实参自动去匹配对应的函数
-
对于
指定函数参数默认值后导致参数列表相同的重载函数,主函数调用时只需要对要调用的函数进行局部函数声明 -
函数重载可以提高代码的可读性,使得代码更加清晰明了
十、关键字nullptr
1.nullptr介绍✧
在C++中,引入了一个新的关键字——nullptr,用来代替旧版本的NULL
nullptr用于代表空指针,对于指针初始化时使用如下:
int* p1 = nullptr; //关键字,代表空指针
之前用指针指向的new出来的堆空间,在回收时就可以将指针指向nullptr
int** p = new int*;
free(p);
p=nullptr;
既然nullptr与之前的NULL使用的方法一致,为什么还要引入nullptr关键字?

2.为什么需要nullptr ?
在学过【C/C++】函数重载的知识后,我们就能理解为什么需要nullptr关键字用来代替NULL宏定义
先来写一个函数重载的例子:
这两个函数的函数名相同,参数列表不同(一个是整型参数,一个是指针参数),构成函数重载
void fun9(int a)
{
cout << __FUNCSIG__ << endl;
}
void fun9(int* p)
{
cout << __FUNCSIG__ << endl;
}
此时我们在主函数中调用fun9函数,传参为空指针NULL
int main()
{
fun9(NULL);
return 0;
}
查看运行结果:
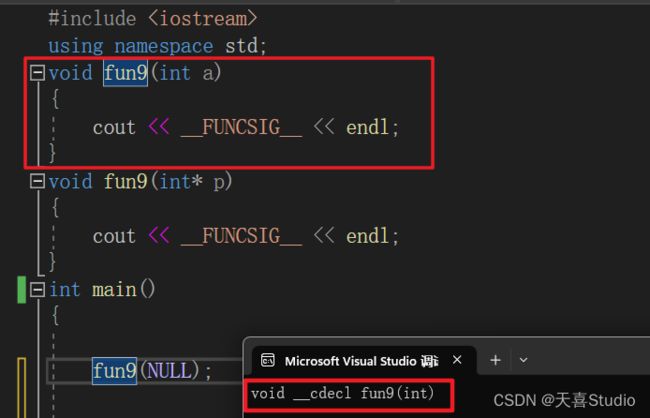
输出的结果是void fun9(int a)函数

此时我不想调用指向整型的函数,而是要调用指向指针的函数,可传参又为空指针NULL,该如何实现呢?
在函数重载中提到过函数的函数的局部变量声明,可以实现调用指向指针的函数
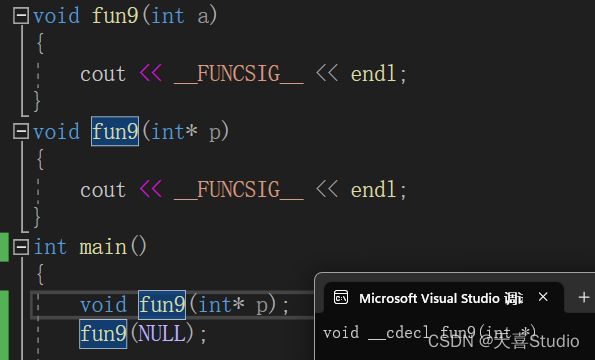
我们来探究一下空指针NULL调用了void fun9(int a)(传参为整型)函数的原因
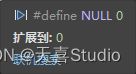
NULL为宏定义,其本质是整数0,这也就是在函数调用中,把NULL当作0调用了函数,而不是当作一个空指针 的原因。
(define宏替换知识点:【c语言】详解宏定义#define)
因此我们需要一个代表空指针的关键字,而不是对整型0的宏替换

C++11中引入了空指针nullptr,专门用来代表空指针
使用nullptr成功地达到了调用传参为指针函数的目的:
总结为:
-
在函数重载中,
宏替换NULL和整型0造成歧义 需要nullptr代表空指针而非整型0 -
关键字
nullptr提高了程序的类型安全性和可读性,与NULL宏定义相比,具有更强的可靠性和扩展性。
3.NULL和nullptr的区别✧
NULL和nullptr都能当作空指针进行使用,他们之间本质的区别是什么呢?
-
NULL是一个宏,替换的是0 ,而nullptr是关键字,代表空指针
-
含义不同,nullptr 代表是空指针,NULL 代表整型数字0
-
nullptr可以清晰地表达代码的意图,能够避免在类型检查时出现一些歧义问题
nullptr只能用于指针类型,不能与整数类型混淆~
十一、引用(&)
1.概念
引用就是对一块已存在的空间(变量)起了一个别名!!!能够简化程序编写,优化内存使用和提高程序效率。
定义引用的符号:&
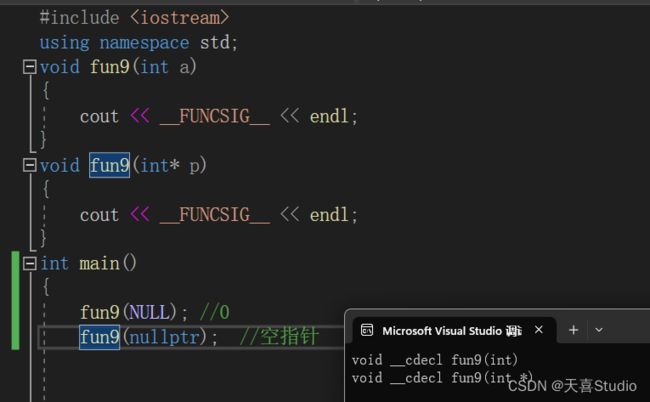
char a = 'V';
char& b = a;
和取地址符长得相同,在上面的用法中是定义了一个引用而非取地址的意思。
定义了引用就要初始化,不存在空的引用!
int main()
{
// &不是取地址 定义引用
char a = 'V';
char& b = a;
//int& c; error:定义了就要初始化,不存在空的引用
const int& d = 10; //常量也可以引用常量
cout << a << " " << b << endl;
return 0;
}
输出字符a和a的引用b,输出结果相同,引用只是起了一个别名!!
引用 与 原变量 指向 同一块内存空间,对 引用 操作就是对 原变量 进行操作
(改变a的值,引用b也会随之改变)
2.函数值传递、地址传递、引用传递的比较
三种传参方式:- 值传递 - 地址传递 - 引用传递
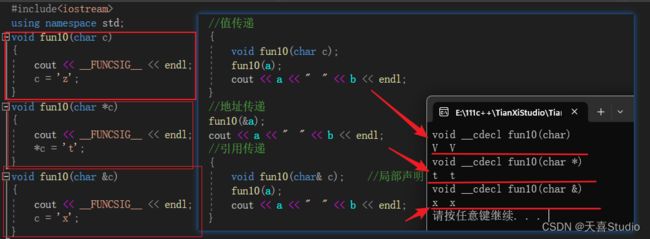
分别使用值传递、地址传递、引用传递创建三个函数,它们构成函数重载
void fun10(char c)
{
cout << __FUNCSIG__ << endl;
c = 'z';
}
void fun10(char *c)
{
cout << __FUNCSIG__ << endl;
*c = 't';
}
void fun10(char &c)
{
cout << __FUNCSIG__ << endl;
c = 'x';
}
在主函数中分别调用这三个函数:
int main()
{
char a = 'V';
char& b = a;
//值传递
{
void fun10(char c); //函数局部声明
fun10(a);
cout << a << " " << b << endl;
}
//地址传递
fun10(&a);
cout << a << " " << b << endl;
//引用传递
{
void fun10(char& c); //函数局部声明
fun10(a);
cout << a << " " << b << endl;
}
return 0;
}
//----------------------------值传递和引用传递调用时会有歧义,需要进行函数局部声明
/* (如果不想进行函数局部声明可以通过指针间接使用):
void (*p_fun1)(char c) = &fun10;
void (*p_fun2)(char &c) = &fun10;
int main()
{
p_fun1(a); //void __cdecl fun10(char)
p_fun2(b); //void __cdecl fun10(char&)
} */
通过运行可以看出,值传递并不能改变实参
而地址传递和引用传递都通过函数内的形参改变了实参!!!
如果通过地址传递,我们需要额外申请(指针大小的)内存空间
现在通过引用传递,不需要额外申请空间,因为引用只是变量的别名
( 传递也额外申请空间,大小不确定要根据类型,才能确定其大小)
并且不通过地址传递,可以省略解引用符(*),避免因指针操作失误而导致的内存问题
如果是查看,这三种都可以
如果要修改实参,不能采用值传递,可选择地址、引用传递
推荐使用不额外申请空间的引用传递
3.引用与指针的区别
引用类似于指针,但还是有很多区别:
- 指针存在空指针; 而定义了引用就要初始化,不存在空的引用! 错误写法: int &c;
- 指针的指向可以改变; 引用了某个空间,引用的指向不能再改变 错误写法: int c = 12; b = c;
- 与指针不同的是,指针可以有多级,引用只能有一级 错误写法: int a; int& b = a; int& c = b; 不能定义一个指向其间接引用的引用
- 指针变量额外占用空间;引用不额外申请空间。
4.总结
引用与原变量指向同一块内存空间,对引用操作就是对原变量进行操作
引用能够简化程序编写,优化内存使用和提高程序效率。
使用引用可以避免复制数据而产生额外的内存开销
注意事项
- 引用初始化!并且只能指向已经存在的变量
- 指向不能变!
十二、类和对象的概念、基本用法
1.类和对象的概念
在【C语言和C++的区别】中提到过:
C++ 是一门面向对象编程的语言,把问题分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描述某个事物在整个解决问题的步骤中的行为,更注重的是程序的整体设计。
专注于对象与对象之间的交互(而不是数据和方法、方法与方法),建立对象的目的不是为了完成个步骤,而是为了描述某个对象在解决整个问题步骤中的属性和行为。
涉及到的属性和方法都被封装到一起包含在其内部。
在C语言中,程序一般是由数据和算法组成,数据和算法彼此独立,关联性不强;
而在C++中将相互关联数据和算法封装起来,形成结构体或类,无论类还是结构体都是一个抽象的概念
只有定义类的变量时,数据才会真实存在,这个变量我们称之为对象
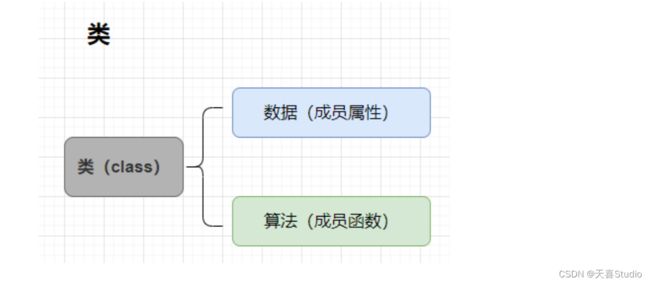
类(class): 完成某一功能的数据和算法的集合,是一个抽象的概念
对象:类的一个实例,具体的概念,是真正存在于内存中的。
举例:房产售楼处的沙盘就是将各种设施集合在一起,代表抽象的概念——类
其中的每个设施就是类的一个实例——对象
世界上的每个事物都可以是一个独立的对象,其都有自己的属性和行为,对象与对象之间通过方法来交互
面向对象编程的分析问题步骤:
- 分析问题中参与其中的有哪些实体
- 这些实体应该有什么属性和方法
- 我们如何通过调用这些实体的属性和方法去解决问题
现实世界中,任何一个操作或者是业务逻辑的实现都需要一个实体来完成,实体就是动作的支配者,没有实体,就没有动作发生。
2.定义和使用类
定义类的关键字class,类名一般以大写的C开头,成员属性一般以m开头
定义一个类的基本格式:
#include 定义了Test类后,如何使用这个类?
与结构体的用法相似,在主函数中,使用类定义一个变量,然后使用.操作符进行使用类内成员
int main()
{
CTest peo;
peo.m_strName = "天喜";
peo.show();
//...
return 0;
}
但是编译器报错为:
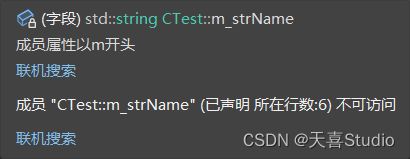
这是因为类成员访问修饰符的问题,下面介绍类成员访问修饰符:
3.类成员访问修饰符
类成员访问修饰符: 描述了类成员的访问控制,即所能使用的一个范围
- 共有的public:没有访问限制,其他类可以访问公有成员变量和方法。
- 保护的protected:只能在当前类和继承该类的子类中访问,受保护成员变量和方法对于其他类不可见。
- 私有的private (默认):只能在当前类中访问,其他类无法直接访问。
如果不对类成员变量或函数进行访问修饰,默认就是私有的private,只能在当前类中访问,因此在主函数中不可以进行访问,所以会报错为类成员不可访问
只需要对类成员进行修饰:
#include 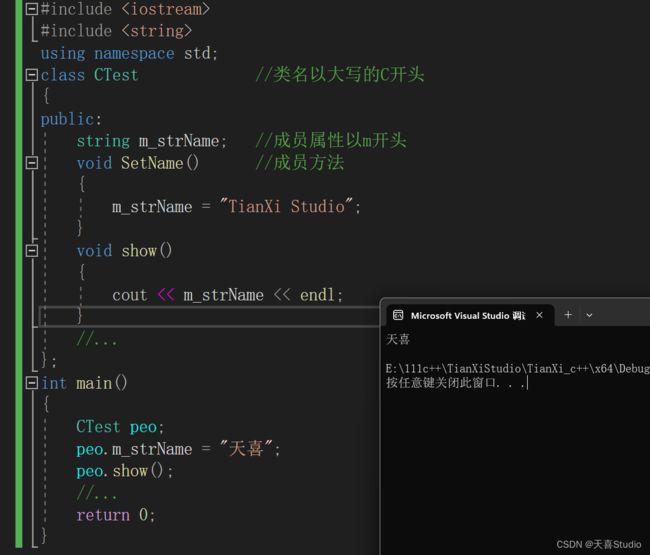
类成员修饰符会持续到下个修饰符为止,例如:
public:公有的m_steName可以进行访问,而SetName()并没有进行修饰,也可以进行访问,是因为前面的public也修饰了他
protected:受保护的show()就不能进行访问
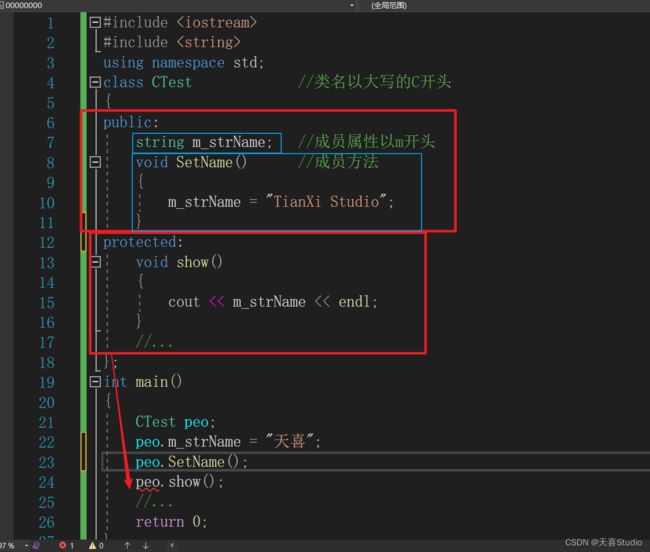
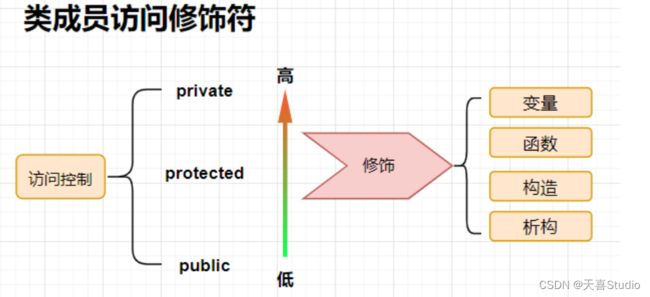
对于类内的私有成员,也可以提供访问接口 (getxxx,setxxx) 来按照一定的规则进行访问
访问修饰符可以控制对类的成员的访问级别,提供了更好的封装性和安全性。
十三、构造函数与析构函数
1.构造函数
构造函数: 其作用是用来初始化类成员属性。
空类中存在一个默认的无参数的构造,函数名为当前类名,无返回值(并不是返回空void,而是没有返回值!)
书写格式如下:
class CTest //类名
{
CTest() //构造函数名与类名相同,默认无参数
{
//默认无参构造
}
};
构造函数并不需要我们手动调用,在定义对象的时候会自动调用,默认的无参构造是编译器提供的
函数体代码为空,所以在定义对象时虽然调用了,但并没有这正给成员初始化
所以需要我们手动重构构造函数,进行初始化的成员属性写在构造函数体内就可以在程序执行时被初始化

在CPeople类中添加构造函数:
CPeople()
{
m_strName = "天喜Studio";
m_nAge = 19;
m_bSex = 1;
m_strNote = "CSDN上分享知识";
}

可以使用不同的参数列表创建多个构造函数,他们构成函数重载,重构的构造函数可以指定参数来符合我们需要的初始化过程。
CPeople()
{
m_strName = "天喜Studio";
m_nAge = 19;
m_bSex = 1;
m_strNote = "CSDN上分享知识";
}
CPeople(int id)
{
m_strName = "CoCo";
m_nAge = 20;
m_bSex = 0;
m_strNote = "这是一个带参构造函数例子";
}
在主函数中,如果要调用带参的构造函数,在定义对象时指定,就会根据参数的类型数量自动匹配对应的构造
int main()
{
CPeople peo;
peo.show();
peo.doing();
CPeople peo2(2);
peo2.show();
peo2.doing();
return 0;
}
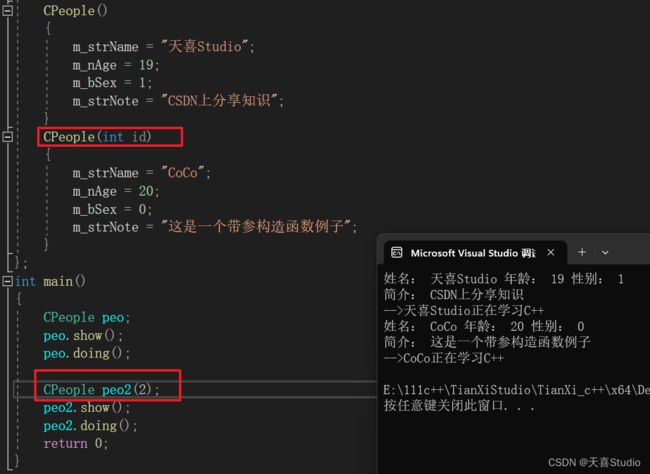
只要重构了任何的构造函数,编译器将不会再提供那个默认的无参构造了
定义多个对象可能会执行不同的构造,但一个对象最终只能执行其中一个构造
如果在类中使用new在堆区给类中的成员创建了额外的内存空间,应该在何时进行delete呢?
char* node = new char[20] {'a'};
下面介绍用来回收类中成员申请额外空间的特殊成员函数——析构函数
2.析构函数
析构函数:与构造函数相对应的析构函数,其作用是回收类中成员申请的额外空间,而不是对象本身!
空类中存在一个默认的析构函数,函数名为~类名,无返回值,无参数。
书写格式如下:
class CTest //类名
{
~CTest() //构造函数名与类名相同,无参数!
{
//默认析构函数
}
};
析构函数在对象的生命周期结束的时候,自动调用,编译器提供的默认析构函数函数体代码也为空我们可以手动重构,一旦重构,编译器就不会再提供那个默认析构了,与构造不同的是析构函数只允许存在一个!
在CPeople类中添加析构函数:
~CPeople()
{
if (node)
{
delete[]node;
node = nullptr;
}
}
注:析构在真正回收对象内存空间之前去调用,额外的空间回收完后,才真正回收对象内存空间。
十四、类成员属性
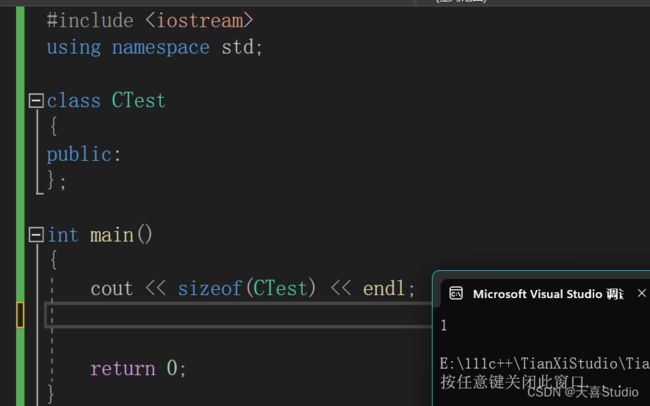
1.空类实例占用空间大小
先创建一个空类:
class CTest
{
};
然后在主函数中使用CTest这个空类创建一个对象
并使用sizeof()函数计算这个空类创建的对象和空类的字节大小
int main()
{
CTest test1;
cout << sizeof(test1) << " " << sizeof(CTest) << endl;
return 0;
}

通过运行可以发现:空类对象和空类都占用1个字节的空间大小
这是因为:
C++标准规定,凡是一个独立的(非附属)对象都必须具有非零大小
所以一个空类即使没有任何数据存储其大小不能为0,空类实例占用内存的大小为1,是用来在内存中占位的
2.类成员属性
如果在类中定义一个类成员:
class CTest
{
public:
int m_a;
};
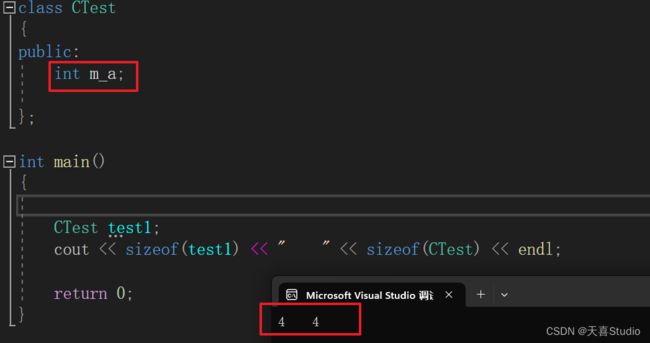
再次运行字节数就为类成员int类型的4字节
sizeof(类型)表示,分配当前类型的变量所占用的空间大小
当一个类中存在非静态成员变量的时候,sizeof(类)占位用的一个字节就不会单独存在
因为变量的地址已经起到了占位、标识的作用;
对象地址
在主函数中再定义一个对象test2,输出查看两个对象的地址:
CTest test1;
CTest test2;
cout << "对象test1的地址:" << &test1<< " 对象test2的地址:" << &test2 << endl;
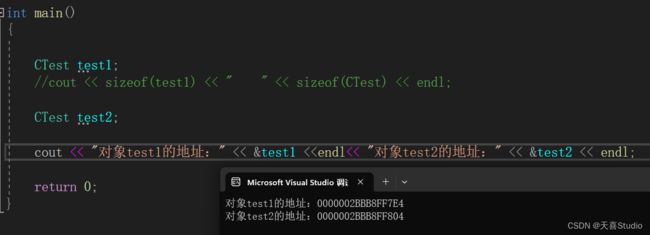
不同的对象在内存中的地址不同!
3.类成员属性总结
当定义一个类时,其中的成员属性只是类的一分,在没有创建对象之前,这些属性并不存在的内存空间
通过创建对象来实例化类时,每个对象都有自己独立的成员属性。
在为每个对象分配内存空间时,会为对象的成员属性分配相应的内存
class CTest
{
public:
int m_a;
};
int main()
{
CTest test1;
CTest test2;
cout << "类成员test1的地址:" << &test1.m_a <<endl<< "类成员test2的地址:" << &test2.m_a << endl;
return 0;
}
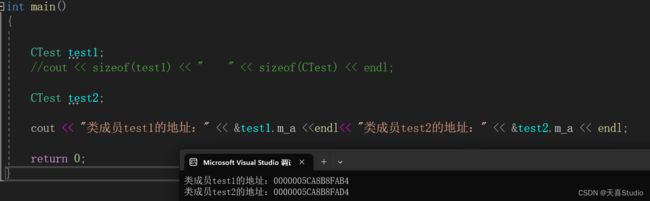
类成员属性:属于对象,当定义对象时,属性才会真正的存在(在内存中分配空间),才开辟对应的空间
多个对象会存在多份的成员属性(表现为在内存中的地址不同),彼此独立,互不扰
十五、类成员函数和this指针
1.类成员函数
类成员函数属于类本身,在编译期间存在,并且每个类只有一份。
它们与是否定义对象无关,可以通过类名直接访问调用。
类成员函数属于类的一部分,在对象创建时并不会分配内存空间
类成员函数只有一份,多个对象共享同一个函数!
class CTest
{
public:
int m_a;
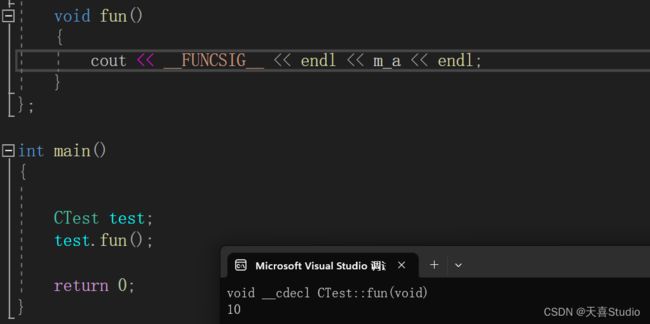
void fun()
{
cout << __FUNCSIG__ << endl << m_a << endl;
}
CTest()
{
m_a = 10;
}
};
int main()
{
CTest test;
test.fun();
return 0;
}
void fun(CTest* pTest)
{
cout << __FUNCSIG__ << pTest->m_a << endl;
}
CTest* ptst = nullptr;
ptst->fun(); //CTest::fun ,空指针对象也可以调用一般的类成员函数,但是不推荐这样写
2.this指针
类成员函数与 this 指针密切相关,this 指针是一个隐式参数,指向调用该成员函数的对象。
类中的非静态成员函数包括构造、析构函数,会有一个默认的隐藏的参数this 指针
它是编译器默认加上的在所有参数之前,类型为当前类的指针 即:类 * const this

当我们在用对象调用函数的时候,this指针就指向了调用的对象
在函数中使用类成员属性或其他类成员函数都是默认通过this指针调用的
在平时写代码的时不用显示的指明this,因为编译器会默认加上
void fun(/* CTest * const this */)
{
cout << __FUNCSIG__ << endl << m_a << endl;
this->m_a; // 等价于 m_a;
show();
this->show(); // 等价于 show();
}
void show()
{
cout << "show" << endl;
}

this指针的作用:
-
指向调用该函数的对象,函数中使用类成员都是通过this指针调用
-
连接对象和成员函数,可以在函数中
无感知的使用成员
使用:
既可以显式访问 this 指针,也可以省略它,并直接使用成员变量和其他成员函数的名称访问
-
可以使用 this->成员名
-
或者省略 this-> 直接使用成员名来访问类的成员变量和调用其他成员函数
十六、类成员函数指针
1.为什么要使用类函数指针
类成员函数指针是指指向类中成员函数的指针
调用函数的两种方式:
- 通过函数名直接调用
- 通过函数指针间接调用
通过函数指针调用的好处:真正的函数指针可以将实现同一功能的多个模块统一起来标识,使系统结构更加清晰,后期更容易维护。
总结为:便于分层设计、利于系统抽象、降低耦合度以及使接口与实现分开,提高代码的复用性、扩展性。

2.类函数指针定义
普通函数指针是这样定义和使用的:
void fun(int v)
{
cout << __FUNCTION__ << v << endl;
}
int main()
{
void (*p_fun)(int) = &fun;
(*p_fun)(10);
return 0;
}

类函数指针又如何定义呢?
先定义一个CTest类
class CTest
{
public:
void fun(/* CTest const * this */int v)
{
cout << __FUNCTION__ << v << endl;
}
};
根据普通的函数指针,类函数指针应该是如下这样定义
void (*p_fun2)(int) = &CTest::fun;
但是编译器报错为:
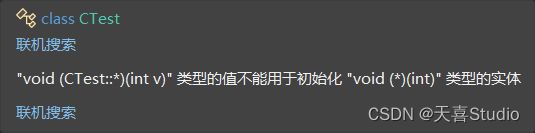
根据报错,可以看出类函数指针p_fun2缺少CTest::,与普通的函数指针定义不同
类函数指针应该这样定义:
void (CTest:: * p_fun2)(int) = &CTest::fun;
//定义类成员函数指针并初始化,注意&和类名作用域 都不能省略
其中::* 是C++提供的整体操作符,用于定义类成员函数指针
创建对象使用该类成员函数指针调用函数时又出现了问题:

类函数指针与普通的函数指针调用不同
通过函数指针间接调用成员函数应该如下使用:
CTest test;
(test.*p_fun2)(20); //普通对象通过指针调用类成员函数
CTest*pTst = new CTest;
(pTst->*p_fun2)(); //指针对象通过指针调用类成员函数
其中 .* 也是整体操作符,用于调用类成员函数指针指向的函数
3.全局函数 和类成员函数区别
-
作用域不同
-
类成员函数有隐藏的this指针作为第一个参数,全局函数没有this指针参数
十七、构造函数的分类及调用
1.按参数分
- 有参构造
有参构造是指一个类中可以接受参数的构造函数。
它允许在创建对象时向构造函数传递参数,以初始化对象的成员变
有参构造使得对象在创建时可以具有不同的初始状态。
- 无参构造
无参构造是指一个类中没有参数的构造函数。
通过无参构造函数来创建对象,该构造函数不接收任何参数并按照默认的方式初始化对象的成员变量。
当对象的成员变量都有默认值或初始化逻辑不需要额外的参数时,可以使用无参构造函数来创建对象。
class Person
{
public:
int age;
//无参(默认)构造函数
Person()
{
cout << "无参-构造函数" << endl;
}
//有参构造函数
Person(int a)
{
age = a;
cout << "有参-构造函数" << endl;
}
//析构函数
~Person() {
cout << "析构函数" << endl;
}
};
2.按类型分
- 普通构造
普通构造函数在创建对象时初始化对象的成员变量,并返回一个新的对象
- 拷贝构造
拷贝构造接受同一类的对象作为参数,并创建一个新的对象,新对象的成员变量与原始对象相同
拷贝构造函数能够确保新对象具有独立的数据副本而不是共享原始对象的引用
class Person
{
public:
int age;
// 普通构造函数
Person()
{
cout << "普通构造函数" << endl;
}
//拷贝构造函数
Person(const Person& p)
{
age = p.age;
cout << "拷贝构造函数" << endl;
}
//析构函数
~Person() {
cout << "析构函数" << endl;
}
};
普通构造函数和拷贝构造函数使用不同的参数类型
普通构造用于创建新对象并初始化其成员变量
拷贝构造用于基于现有对象创建新对象的副本
3.三种调用方式:
-
括号法
-
显式法
-
隐式转换法
//调用无参构造函数
void test01()
{
Person p; //调用无参构造函数
}
//调用有参的构造函数
void test02()
{
//括号法 常用
Person p1(10);
//error:Person p2(); 调用无参构造函数不能加括号,如果加了编译器认为这是一个函数声明
//显式法
Person p2 = Person(10);
Person p3 = Person(p2);
//Person(10)单独写就是匿名对象 当前行结束之后,马上析构
//隐式转换法
Person p4 = 10; // Person p4 = Person(10);
Person p5 = p4; // Person p5 = Person(p4);
//Person p5(p4); 不能利用 拷贝构造函数 初始化匿名对象 编译器认为是对象声明
}
int main()
{
test01();
test02();
return 0;
}

十八、拷贝构造函数
1.拷贝构造函数的调用
拷贝构造函数调用有三种情况:
-
使用一个已经创建完毕的对象来初始化一个新对象
-
值传递的方式给函数参数传值
-
以值方式返回局部对象
根据构造函数的分类创建一个Person类:
class Person
{
public:
int mAge;
Person()
{
cout << "调用无参构造函数Person() " << endl;
mAge = 0;
}
Person(int age)
{
cout << "调用有参构造函数Person(int age) " << endl;
mAge = age;
}
Person(const Person& p)
{
cout << "调用拷贝构造函数Person(const Person& p) " << endl;
mAge = p.mAge;
}
//析构函数在释放内存之前调用
~Person()
{
cout << "调用析构函数" << endl;
}
};
使用一个已经创建完毕的对象来初始化一个新对象
//1. 使用一个已经创建完毕的对象来初始化一个新对象
void test01()
{
Person man(100); //p对象已经创建完毕
Person newman(man); //调用拷贝构造函数
Person newman2 = man; //拷贝构造
//Person newman3;
//newman3 = man; //不是调用拷贝构造函数,赋值操作
}
int main()
{
test01();
return 0;
}

使用值传递的方式给函数参数传值
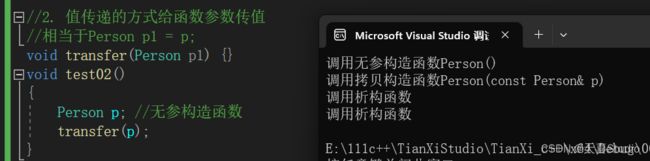
//2. 值传递的方式给函数参数传值
//相当于Person p1 = p;
void transfer(Person p1) {}
void test02()
{
Person p; //无参构造函数
transfer(p);
}
int main()
{
test02();
return 0;
}
以值方式返回局部对象
//3. 以值方式返回局部对象
Person transfer2()
{
Person p1;
cout << (int*)&p1 << endl;
return p1;
}
void test03()
{
Person p = transfer2();
cout << (int*)&p << endl;
}
int main()
{
test03();
return 0;
}

2.构造函数的调用规则
默认情况下,c++编译器至少给一个类添加3个函数
1.默认构造函数(无参,函数体为空)
2.默认析构函数(无参,函数体为空)
3.默认拷贝构造函数,对属性进行值拷贝
void test01()
{
Person p1(18);
//如果不写拷贝构造,编译器会自动添加拷贝构造,并且做浅拷贝操作
Person p2(p1);
cout << "p2: " << p2.mAge << endl;
}
int main()
{
test01();
return 0;
}

void test02()
{
//如果提供有参构造,编译器不会提供默认构造,会提供拷贝构造
Person p1; //此时如果用户自己没有提供默认构造,会出错
Person p2(10); //用户提供的有参
Person p3(p2); //此时如果用户没有提供拷贝构造,编译器会提供
//如果提供拷贝构造,编译器不会提供其他构造函数
Person p4; //此时如果用户自己没有提供默认构造,会出错
Person p5(10); //此时如果用户自己没有提供有参,会出错
Person p6(p5); //用户自己提供拷贝构造
}
int main()
{
test02();
return 0;
}

构造函数的调用规则:
-
如果用户定义有参构造函数,c++不再提供默认无参构造,但是会提供默认拷贝构造
-
如果用户定义拷贝构造函数,c++不再提供其他构造函数
拷贝构造函数内部可以执行适当的操作来确保新对象的独立性
拷贝构造函数可能会在以下情况下被调用:
-
在创建一个新对象时,用已存在的同一类的对象初始化
-
将一个对象作为参数传递给一个函数,并以值传递的方式进行函数调用
-
在返回一个对象副本的函数中,将该对象作为返回值
十九、深拷贝与浅拷贝
1.浅拷贝
浅拷贝是简单的赋值拷贝操作
浅拷贝是指在对象复制过程中,只会简单地复制对象的值,包括指针的地址,而不复制指针所指向的内容
新对象和原对象将共享同一块内存,如果其中一个对象修改了这块内存,那么另一个对象也会受到影响
#include 
由于浅拷贝只复制了指针地址,所以两个对象共享同一块内存,因此修改test1.data导致了test2.data也被修改
在修改一个对象时,另一个对象也受到影响
2.深拷贝
深拷贝是在堆区重新申请空间,进行拷贝操作
深拷贝是指在对象复制过程中,不仅复制对象的值,还复制指针所指向的内容
这意味着新对象将有其独立的内存副本,对其中一个对象进行修改不会影响到另一个对象
拷贝构造函数中通过为m_height分配新存并复制p.m_age和p.m_height的值来执行深拷贝:
#include二十、类之间的横向关系
1.组合
组合(Composition):表示一种拥有的关系,它使一个类成为另一个类的一部分。
组合关系是一种强依赖关系,如果父对象销毁,则子对象也将被销毁。
组合是包含与被包含的关系。组合是一个类中包含另一个类对象。
组合是一种强所属关系,组合关系的两个对象往往具有相同的生命周期,被组合的对象是在组合对象创建的同时或者创建之后创建,在组合对象销毁之前销毁。
一般来说被组合对象不能脱离组合对象独立存在,整体不存在,部分一定不存在。
例如:人与手、人与头之间的关系,人需要包含头和手,头、手是人的一部分且不能脱离人独立而存在

2.关联
关联(Association) 关联是指一个类与另一个类存在连接关系,但是两个类的对象之间不是强制性的,一个类的对象可以独立存在。关联关系可以是单向的或者双向的。在双向关联中,两个类对象互相包含对方的引用。
关联不是从属关系,而是平等关系,可以拥有对方,但不可占有对方
。完成某个功能与被关联的对象有关,但是可有可无。
被关联的对象与关联的对象无生命周期约束关系,被关联对象的生命周期由谁创建就由谁来维护。
只要二者同意,可以随时解除关系或是进行关联,被关联的对象还可以再被别的对象关联,所以关联是可以共享的
举例:人和朋友的关系,人要完成玩游戏这个功能,没有朋友可以自己玩游戏,如果交到朋友了就可以和朋友一起玩游戏。
3.依赖
依赖(Dependency) 依赖是指一个类使用另一个类的对象,但是这种依赖关系是暂时性的,不会持久存在。如果一个类的方法需要调用另一个类的对象,那么这种调用就是一种依赖关系。
一个对象的某种行为依赖于另一个类对象,被依赖的对象视为完成某个功能的工具,并不持有对他的引用,只有在完成某个功能的时候才会用到,而且是必不可少的。
依赖之间没有生命周期约束关系。
举例:人要完成玩电脑,就需要用到电脑,电脑作为一个工具,其他的时候不需要,电脑也不可能作为人的属性而存在(非组合关系) ,人必须依赖于电脑才能玩电脑。

4.聚合
聚合(Aggregation) 聚合是指一个类包含另一个类的对象,但是这个对象的生命周期可以独立存在。聚合是一种弱关联,一个类的对象可以存在,即使包含这个对象的类对象不在了。
多个被聚合的对象聚集起来形成一个大的整体,聚合的目的是为了统一进行管理同类型的对象,聚合是一种弱所属关系,被聚合的对象还可以再被别的对象关联,所以被聚合对象是可以共享的。
虽然是共享的,聚合代表的是一种更亲密的关系,相当于强版本的关联。
举例:多个人一起玩游戏进行统一管理

二十一、类之间的纵向关系——继承
1.继承的概念
继承是类之间的纵向关系,是C++面向对象中的重要特性
继承的类称为派生类(子类),被继承的类称为基类(父类)
在子类类名后加: 继承方式 父类
class CFather{};
class CSon:public CFather{}; //class 子类名:继承方式 父类名
子类继承父类 可以使用父类的成员,也会包含父类
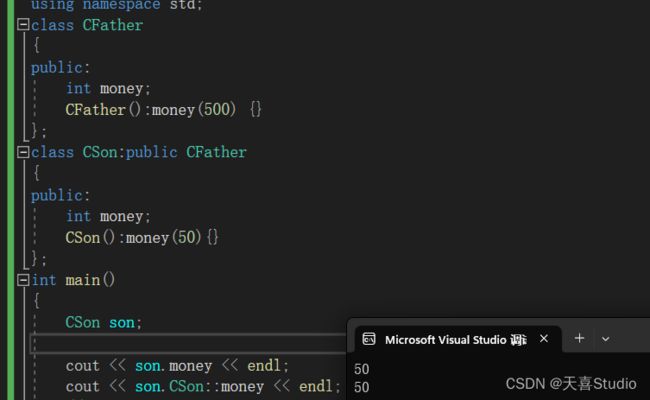
- 如果子类和父类有同名的成员,默认使用子类的成员
class CFather
{
public:
int money;
CFather():money(500) {}
};
class CSon:public CFather
{
public:
int money;
CSon():money(50){}
};
int main()
{
CSon son;
cout << son.money << endl; //子类成员
cout << son.CSon::money << endl; //子类成员
return 0;
}
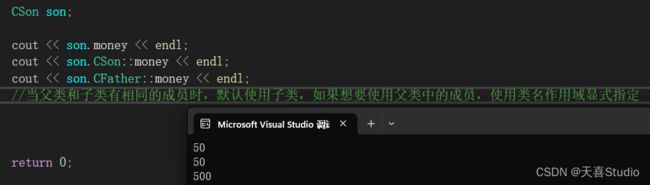
如果想使用重名父类中的成员,可以通过类名作用域显式指定
cout << son.CFather::money << endl;
2.子类和父类内存空间分布
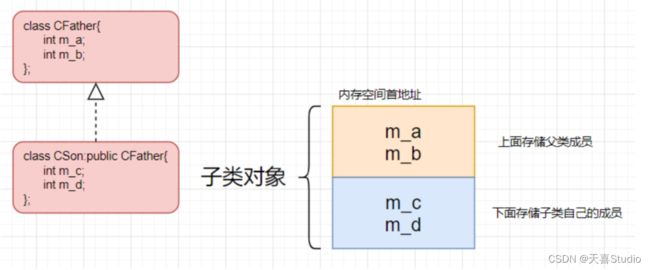
成员在内存空间分布为:先父类成员后子类成员,而每个类中的成员分布与在类中声明的顺序一致。
子类对象所占用的空间:子类继承父类,相当于将父类的成员包含到自己的类里,所以定义子类对象所占用的空间大小除了子类自身的成员还包括父类的成员。
- 父类对象的内存空间只包含父类自己的属性和方法,不包含任何子类的属性和方法
class CFather
{
public:
int m_dad;
int money;
};
class CSon :public CFather
{
public:
int m_son;
int money;
CSon() :m_son(5)
{
m_dad = 30;
CFather::money = 200;
}
};
CSon son;
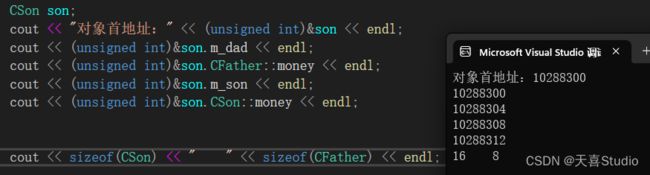
cout << "对象首地址:" << (unsigned int)&son << endl;
cout << (unsigned int)&son.m_dad << endl;
cout << (unsigned int)&son.CFather::money << endl;
cout << (unsigned int)&son.m_son << endl;
cout << (unsigned int)&son.CSon::money << endl;
cout << sizeof(CSon) << " " << sizeof(CFather) << endl;
return 0;
}
父类空间在前,子类空间在后,排布顺序:父类->子类自上而下
初始化成员属性,父类成员在父类中进行初始化,子类成员在子类中进行初始化
二十二、多态与虚函数
1.多态的概念
多态是C++面向对象编程中重要的特性。相同的行为方式可能导致不同的行为结果,即产生了多种形态行为,即多态。
就是不同的类可以共享一个函数,但是各自的实现不同
为了实现多态,首先要有继承关系,在基类中声明一个虚函数,然后再派生类中进行不同的实现
根据继承中的父类指针可以指向子类对象:继承的条件下,父类的指针可以指向任何继承于该类的子类对象,多种子类对象具有多种形态由父类的指针统一管理 父类的指针也会具有多种形态
多种子类表现为多种形态由父类的指针进行统一,那么这个父类指针就具有了多种形态。(多态)
总结一下C++多态的必要条件:
- 存在继承关系,并且父类类型的指针指向某个子类,通过该指针调用虚函数
- 父类中存在虚函数 (virtual修饰) ,且子类中重写了父类的虚函数
重写:虚函数存在的前提下,子类中定义了和父类中一模一样的虚函数
举个栗子:

定义两个子类CSon和CSon2继承于父类CFather,父类中定义两个虚函数
只在CSon子类中进行重写,在CSon2中不重写
#include 其中:重写过父类中虚函数的CSon类中的funSon()实现多态,而未重写的funSon2()未实现多态

2.虚函数
1.虚函数大小
定义虚函数需要使用virtual关键字,虚函数的定义格式: virtual 返回类型 函数名();
virtual void fun();
当只定义一个空类时,输出类对象的大小为1 :为占位作用
如果在类中定义虚函数后,对象的内存空间会变为多少呢?
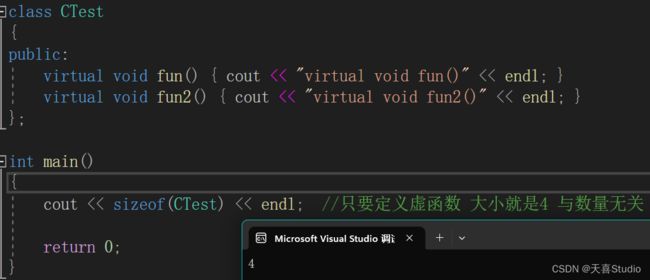
定义后执行发现,不管定义几个虚函数,对象的内存空间大小都为4
即
虚函数属于类,在编译器存在
2.虚函数指针
当我们在基类中定义了一个虚函数后并定义对象后(不定义对象没有虚函数指针),在调试下可以发现编译期自动添加了一个类型为void**的二级指针_vfptr

再定义一个对象,虚函数指针也随之增加了一个

但是查看地址,这两个虚函数指针指向了同一个内存空间,
即
虚函数指针属于对象,占用对象内存空间,定义多个对象就会存在多份的虚函数指针
-
定义对象才会存在虚函数指针
-
每个对象的虚函数指针都指向了同一个虚函数列表
-
虚函数指针在构造函数中的初始化参数列表进行初始化(编译期自动完成)

| 大家的点赞、收藏、关注将是我更新的最大动力! 欢迎留言或私信建议或问题。 |
| 大家的支持和反馈对我来说意义重大,我会继续不断努力提供有价值的内容!如果本文哪里有错误的地方还请大家多多指出(●'◡'●) |