InfluxDB时序数据库-笔记
本笔记由在Bilibili学习的尚硅谷教学视频后整理得来
文章目录
- 一、InfluxDB基础概念
-
- 1.1InfluxDB是什么
- 1.2为什么选择InfluxDB而不选择关系型数据库
- 1.3下载安装
- 1.4Promethus数据格式
- 1.5时序数据中的数据模型
- 1.6与时间标准相关的知识
- 二、Flux语言
-
- 2.1初识Flux语言
- 2.2基本数据类型
- 2.3Flux基本语法
- 2.4四个复合类型
-
- 2.4.1Record
- 2.4.2Dictionary(字典)
- 2.4.3Array(数组)
- 2.5正则表达式匹配
- 三Flux语言查询
-
- 3.1Flux查询InfluxDB语法
- 四、InfluxDB应用
-
- 4.1命令行方式写入数据
- 4.2用Telegraf将数据收集到InfluxDB
- 4.3使用node_exporter采集数据到InfluxDB
一、InfluxDB基础概念
1.1InfluxDB是什么
- InfluxDB是一种时序数据库。通常被用于监控场景,比如运维和IOT(物联网)领域。主要解决了存储时序数据并能实时处理它们的需求。
- InfulxDB一般不会修改数据
比如我们想查看服务器CPU的监控情况,结果超过阈值X就触发报警。我们可以每隔10秒向InfluxDB写一条数据,然后写一条查询语句,查询CPU最近30秒的平均使用情况,配置一个报警规则,超过阈值X触发报警。查询语句也每隔10秒执行一次。
对于监控场景,最近的数据是热数据(经常查询的),放在内存中,长期不用的冷数据,会做一些处理(比如压缩等),可以节约磁盘空间。
监控场景,一般都是有固定的步骤
- 采集数据
- 存储数据
- 查询数据
- 监控报警
InfluxDB在1.X版本对应了四个组件
- Telegraf:数据采集
- InfluxDB:数据存储
- Chronograf:数据查询展示
- Kapacitor:后台处理报警信息
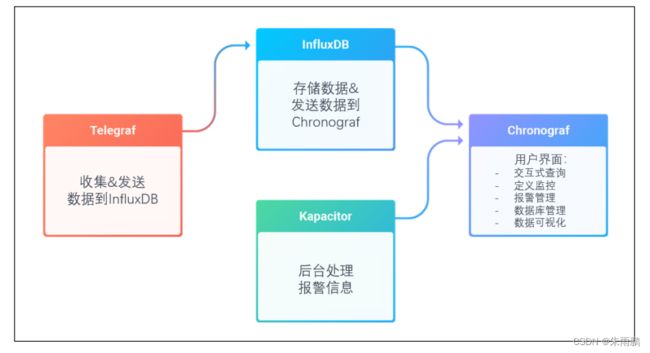
Influx在2.X版本,数据存储,查询,监控报警的部分都融入到了InfluxDB
InfluxDB1.X版本使用InfluxQL进行查询,Influx2.X使用FLUX查询语言,可以使用符号和管道符。
1.2为什么选择InfluxDB而不选择关系型数据库
主要考虑因素是写入性能
关系型数据库也能支持时间戳,根据时间戳进行查询。但是关系型一般是基于B+数的数据结构,在数据写入时,有可能会触发叶裂变,产生对磁盘的随机读写,降低写入性能。而时序数据库一般采用LSM Tree的变种,顺序写入磁盘来提高写入性能
专业的人做专业的事
大多数时序数据库虽然写入性能很好,但是不支持事务,不能删除某条数据,大多数时候也不能更新数据
1.3下载安装
一般下载安装采用的方式:
- 直接下载可执行的二进制程序包
- 通过包管理工具安装,比如apt和yum
启动
下载后,直接命令./influxd 启动即可
进入项目
1.4Promethus数据格式
Prometheus 也是一种时序数据库,不过它通常被用在运维场景下。Prometheus 是开放原子基金会的第二个毕业项目,这个基金会的第一个毕业项目就是大名鼎鼎的 k8s。同 InfluxDB 一样,Prometheus 也有自己的数据格式,只要数据符合这种格式就能被
Prometheus 识别并写入数据库。而且 Prometheus 数据格式也是纯文本的。InfluxDB采用的就是Prometheus 数据格式。
(1)measurement(测量名称),类似于关系数据中的Table
(2)Tag Set(标签集)可选,在measurement之后紧接着逗号隔开,相当于一个用来区分measurement的索引,Tag数量太多会减慢插入速度。
(3)Field Set(字段集),实际插入的内容,key为字符类型,Value为浮点数|整数|无符号整数|字符串|布尔值
(4)Timestamp(时间戳),可选,不指定默认当前系统的时间戳
整个数据有两个空格来区分
第一个空格区分measurement,tage和Field Set,第二个空格区分Field Set和Timestamp

1.5时序数据中的数据模型
这里有一个关系数据库中的简单示例
park_id、planet、time 是创建了索引的列, _foodships 是未创建索引的列。
+---------+---------+---------------------+--------------+
| park_id | planet | time | #_foodships |
+---------+---------+---------------------+--------------+
| 1 | Earth | 1429185600000000000 | 0 |
| 1 | Earth | 1429185601000000000 | 3 |
| 1 | Earth | 1429185602000000000 | 15 |
| 1 | Earth | 1429185603000000000 | 15 |
| 2 | Saturn | 1429185600000000000 | 5 |
| 2 | Saturn | 1429185601000000000 | 9 |
| 2 | Saturn | 1429185602000000000 | 10 |
| 2 | Saturn | 1429185603000000000 | 14 |
| 3 | Jupiter | 1429185600000000000 | 20 |
| 3 | Jupiter | 1429185601000000000 | 21 |
| 3 | Jupiter | 1429185602000000000 | 21 |
| 3 | Jupiter | 1429185603000000000 | 20 |
| 4 | Saturn | 1429185600000000000 | 5 |
| 4 | Saturn | 1429185601000000000 | 5 |
| 4 | Saturn | 1429185602000000000 | 6 |
| 4 | Saturn | 1429185603000000000 | 5 |
+---------+---------+---------------------+--------------+
对于的时序数据库
name: foodships
tags: park_id=1, planet=Earth
time #_foodships
---- ------------
2015-04-16T12:00:00Z 0
2015-04-16T12:00:01Z 3
2015-04-16T12:00:02Z 15
2015-04-16T12:00:03Z 15
name: foodships
tags: park_id=2, planet=Saturn
time #_foodships
---- ------------
2015-04-16T12:00:00Z 5
2015-04-16T12:00:01Z 9
2015-04-16T12:00:02Z 10
2015-04-16T12:00:03Z 14
name: foodships
tags: park_id=3, planet=Jupiter
time #_foodships
---- ------------
2015-04-16T12:00:00Z 20
2015-04-16T12:00:01Z 21
2015-04-16T12:00:02Z 21
2015-04-16T12:00:03Z 20
name: foodships
tags: park_id=4, planet=Saturn
time #_foodships
---- ------------
2015-04-16T12:00:00Z 5
2015-04-16T12:00:01Z 5
2015-04-16T12:00:02Z 6
2015-04-16T12:00:03Z 5
对InfluxDB中的对于关系理解:
- InfluxDB中的measurement(foodships)相当于SQL(关系型数据库)中的表
- InfluxDB中的tags(park_id 和 planet),相当于SQL(关系型数据库)中的索引列
- InfluxDB中的fileds(是#_foodships),相当于SQL(关系型数据库)中的未建立索引的列
- InfluxDB 中的数据点(比如,2015-04-16T12:00:00Z 5 )相当于SQL(关系型)数据库中的一行。
对序列的理解:
- 关系型存储数据的数据为一行,而时序数据库存储的数据为1个序列
- 在InfluxDB中,唯一的measurement、tags、fileds组合是一个series(序列)
- 一个序列可以存储相同索引下的多个数据
- 如果我们需求是查询某个设备一段时间内的数据,这个时候对于关系型数据库,需要经过多次寻址找到多个record。而时序数据库,直接通过索引能拿到一个序列的数据。性能是远远强于B+数数据库的。
- 在InfluxDB中,一次性也可以查询多个序列的数据
- 在InfluxDB中,序列的需要在一个可枚举的范围内,因为如果序列过多,则会影响插入和查询性能。
双索引设计
在InfluxDB中,可以把measurement、tags看做索引,还有时间也是索引。在InfluxDB中,一般查询数据的思路:
- 指定要从哪个存储桶查询数据,相当于选择好数据库。
- 通过时间索引缩短要查询的数据范围
- 再通过指定measurement、tags查到要查询的序列
- 然后得到数据
1.6与时间标准相关的知识
GMT(格林威治标准时间)
格林威治(又译格林尼治)它是一个位处英国伦敦的小镇。17 世纪,英国航海事业发展迅速,当时海上航行亟需精确的精度指示,于是英国皇家在格林威治这个地方设立了一个天文台负责测量正确经度的工作。后来 1884 年,在美国华盛顿召开的国际经度会以决定以经过格林尼治天文台(旧址)的经线为本初子午线(0 度经线)。同时这次会以也将全球划分为了 24 个时区。0 度经线所在的时区为 0 时区。现在,有时候你要买一个机械表,如果它说支持 GMT,意思就是支持显示格林威治标
UT(世界时)
1928 年,国际天文联合会提出了 UT 的概念,UT 主要用来衡量一天究竟有多长。一旦一天的长度可以确定,那么将这个长度除以 24 就能确定一小时的长度。以此类推、分钟、秒的长度我们就都能确定了。UT 也是以格林威治时间作为标准的,它规定格林威的子夜为 0 点。在当时,衡量一天长度的方法就是通过天文观测,看地球多久转一圈。但一来天文观测存在误差。二来,地球的自转越来越慢。计时方法亟需革新。
UTC(世界协调时)
UTC,universal Time Coordinated。世界协调时,世界统一时间、国际协调时。它以国际原子时的秒长为基准。但是我们知道,UT 基于天文观测,地球越来越慢那 UT 的秒长应该越来越长。如果不进行干预那么 UTC 和 UT 之间就会有越来也大的误差。
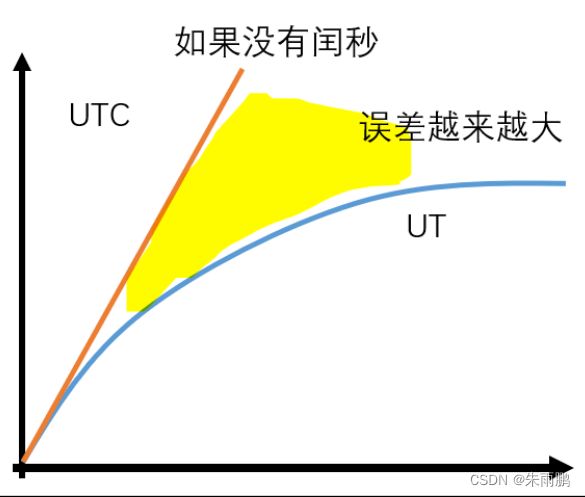
如果这种状况持续下去,在好多好多好多好多年后,人类可能就是 UTC 时间凌晨 3 点起床挤地铁上班了。因此,让 UTC 符合人类生活习惯,就必须控制 UTC 和 UT 的误差大小,于是 UTC 引入了闰秒。所谓闰秒,也就是让在某个时间点上,人为规定这一分钟比普通的分钟多一秒,它有 61 秒。这个时候 1 分 59 秒过了应该接着是 2 分 0 秒,但是在遇到秒时会遇到 1 分 60 秒。

总结
- GMT是最早的国际时间标准,后来是UTC。
- 因为UTC要逼近UT,而UT又以GMT为标准。十分严格地说,UTC和GMT不是一个东西。但宽松地说,你可以把UTC等同于GMT,而且有些网站和应用程序就是这么干的。
- 闰秒之所以存在,源于人类使用的标准时间计量工具原子钟的一天为86400秒,该数字与实际地球自转一天时间并不完全一致,随时间累积,误差就会慢慢增大。为保证我们使用的时间与真实地球自转保持同步,1972年开始,人们引入闰秒。
二、Flux语言
2.1初识Flux语言
Flux 是一种函数式的数据脚本语言,它旨在将查询、处理、分析和操作数据统一为一种语法。可以类比水处理的过程。我们从源头把水抽取出来,然后按照我们的用水需求,在管道上进行一系列的处理修改(去除沉积物,净化)等,最终以消耗品的方式输送到我们的目的地(饮水机、灌溉等)。
InfluxData 公司对 FLUX 语言构想并不是仅仅让它作为 InfluxDB 的特定查询语言,而是希望它像 SQL 一样,成为一种标准。按照这个计划,FLUX 语言应该具备处理来自不同数据源的数据的能力。目前还任重道远。

InfluxDB1.8版本之后才开始兼容Flux语言。而且Flux语言的不同版本的用法不同,高版本也并没有完全兼容低版本的一些功能。所以使用的时候要到官网看准不同InfluxDB对应的不同版本Flux。
https://docs.influxdata.com/flux/v0.x/influxdb-versions/ 这个链接里面有InfluxDB对应的Flux版本。
虽然,FLUX 语言的自我定位一个脚本语言,它也是一个查询语言。一个 FLUX 脚本想要成功执行,它就必须返回一个表流。就像是 SQL 语言想要正确执行,它就必须返回一张表。
2.2基本数据类型
字符串
import "strings"
import "array"
import "date"
a = "\x61\x62"
b = "字符串"
c="字符串"+string(v:1)
d=strings.joinStr(arr:["张三","李四"],v:"-")
array.from(rows: [{"value":a},{"value":b},{"value":c},{"value":d}])
浮点数
FLUX 中的浮点数是 64 位的浮点数。一个浮点数包含整数位,小数点,和小数位。
将其他基本类型转换为 float
float(v: "1.23")
// 1.23
float(v: true)
// Returns 1.0
float(v: 123)
// Returns 123.0
整数
一个 integer 的变量是一个 64 位有符号的整数。
将数据类型转换为整数
int(v: "123")
// 123
int(v: true)
// Returns 1
int(v: 1d3h24m)
// Returns 98640000000000
int(v: 2021-01-01T00:00:00Z)
// Returns 1609459200000000000
int(v: 12.54)
// Returns 12
无符号整数
FLUX 语言里不能直接声明无符号整数,但这却是一个 InfluxDB 中具备的类型。在FLUX 语言中,我们需要使用 uint 函数来讲字符串、整数或者其他数据类型转换成无符号整数。
uint(v: "123")
// 123
uint(v: true)
// Returns 1
uint(v: 1d3h24m)
// Returns 98640000000000
uint(v: 2021-01-01T00:00:00Z)
// Returns 1609459200000000000
uint(v: 12.54)
// Returns 12
uint(v: -54321)
// Returns 18446744073709497295
基本数据类型-null
FLUX 语言并不能在语法上直接支持声明一个 Null,但是我们可以通过 debug.null 这个
函数来声明一个指定类型的空值。
import "internal/debug"
// Return a null string
debug.null(type: "string")
// Return a null integer
debug.null(type: "int")
// Return a null boolean
debug.null(type: "bool")
判断是否为null
使用关键字exists
import "array"
import "internal/debug"
x = debug.null(type: "string")
y = exists x
// Returns false
2.3Flux基本语法
Flux中只有单行注释,没有多行注释。
FLUX 支持基本的表达式,比如:数字相加或字符串拼接、数字减法、数字相乘、数字除法、取模
import "array"
add=0+1
sub=3-1
str=int(v:"4"+"6")
array.from(rows: [{"value":add},{"value":sub},{"value":str}])
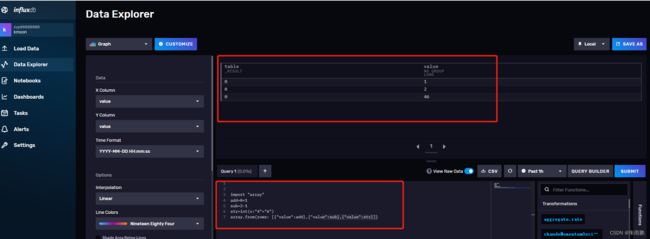
from(bucket: "example-bucket")
|> range(start: -1d)
|> filter(fn: (r) => r._measurement == "example-measurement")
|> mean()
|> yield(name: "_results")
- from( )函数可以指定数据源。
- | > 管道转发符,将一个函数的输出转发给下一个函数。
- range( ),fliter( )两个函数在根据列的值对数据进行过滤
- mean( )函数在计算所剩数据的平均值。
- yield( ) 将最终的计算结果返回给用户。
谓词表达式
"John" == "John"
// Returns true
41 < 30
// Returns false
"John" == "John" and 41 < 30
// Returns false
"John" == "John" or 41 < 30
// Returns true
//=~可以判断一个字符串时候能被正则表达式匹配上。
// !~是=~的反操作,判断一个字符串是不是不能被某个正则表达式匹配。
"abcdefg" =~ "abc|bcd"
// Returns true
"abcdefg" !~ "abc|bcd"
// Returns false
控制语句
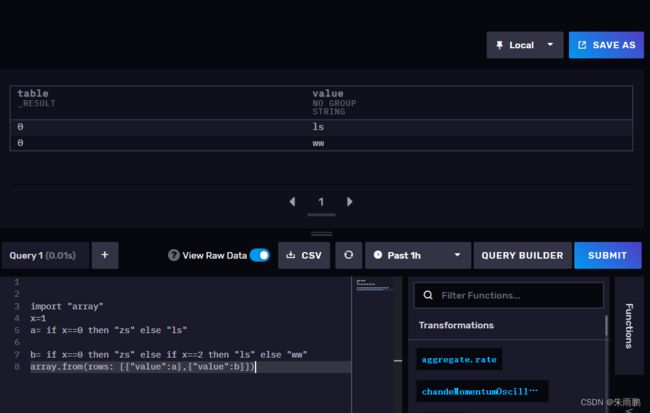
Flux没有if else,for while,try catch等语法。有一个和三目表达式比较像的
三目表达式可以嵌套
import "array"
x=1
a= if x==0 then "zs" else "ls"
b= if x==0 then "zs" else if x==2 then "ls" else "ww"
array.from(rows: [{"value":a},{"value":b}])
展示日期
import "array"
a = 2023-01-02T05:10:00.000Z
array.from(rows: [{"value":a}])
日期函数
import "array"
import "date"
a = 2023-01-02T05:10:00.000Z
b=1d
c=string(v:duration(v: int(v: 32m10s) * 10))
array.from(rows: [{"value":c}])
2.4四个复合类型
2.4.1Record
- 一个记录是一堆键值对的集合,其中键必须是字符串,值可以是任意类型,在键上没 有空白字符的前提下,键上的双引号可以省略。record 需要使用{}声明,键值对之间使用英文逗号(,)分开。另外,一个Record 的内容可以为空,也就是里面没有键值对。
- record类型变量中的 key 是静态的,一旦声明,其中的 key 就被定死了。
- record 在语法层面上和 json 语法是统一的,而且FLUX 语言提供了一个 json 函数库,借助这个库中的 encode 函数,我们可以轻易地将一个 record 转为 json 字符串然后发送出去。
{foo: "bar", baz: 123.4, quz: -2}
{"Company Name": "ACME", "Street Address": "123 Main St.", id: 1123445}
从Record中取值
使用.key的方式
c = {name: "John Doe", address: "123 Main St.", id: 1123445}
c.name
// Returns John Doe
c.id
// Returns 1123445
使用[“”]的方式
c = {"Company Name": "ACME", "Street Address": "123 Main St.", id:
1123445}
c["Company Name"]
// Returns ACME
c["id"]
// Returns 1123445
Record 类型可以进行嵌套引用
嵌套后可以多级获得数据
customer =
{
name: "John Doe",
address: {
street: "123 Main St.",
city: "Pleasantville",
state: "New York"
}
}
customer.address.street
// Returns 123 Main St.
customer["address"]["city"]
// Returns Pleasantville
customer["address"].state
// Returns New York
with关键字
使用 with 操作符可以拓展一个 record,当原始的 record 中有这个 key 时,原先 record的值会被覆盖如果原先的 record 中没有制定的 key,那么会将旧 record 中的所有元素和with 中指定的元素复制到一个新的 record 中。
c = {name: "John Doe", id: 1123445}
{c with name: "Xiao Ming", pet: "Spot"}
// Returns {id: 1123445, name: Xiao Ming, pet: Spot}
列出所有key
import "experimental"
c = {name: "John Doe", id: 1123445}
experimental.objectKeys(o: c)
// Returns [name, id]
== ==比较两个 record 是否相等
{id: 1, msg: "hello"} == {id: 1, msg: "goodbye"}
// Returns false
{foo: 12300.0, bar: 34500.0} == {bar: float(v: "3.45e+04"), foo:
float(v: "1.23e+04")}
// Returns true
将 record 转为字符串
x = {a: 1, b: 2, c: 3}
display(v: x)
// Returns "{a: 1, b: 2, c: 3}"
2.4.2Dictionary(字典)
定义一个字典
字典和记录很像,但是 key-value 上的要求有所不同。一个字典是一堆键值对的集合,其中所有键的类型必须相同,且所有值的的类型必须相同。在语法上,dictionary 需要使用方括号[ ]声明,键的后面跟冒号(:)键值对之间需要使用英文逗号( , )分隔。
示例
[0: "Sun", 1: "Mon", 2: "Tue"]
["red": "#FF0000", "green": "#00FF00", "blue": "#0000FF"]
[1.0: {stable: 12, latest: 12}, 1.1: {stable: 3, latest: 15}]
引用字典中的值
(1)导入 dict 包
(2)使用 dict.get( )并提供下述参数:
a) dict:要取值的字典
b) key:要用到的 key
c) default:默认值,如果对应的 key 不存在就返回该值
import "dict"
positions =
[
"Manager": "Jane Doe",
"Asst. Manager": "Jack Smith",
"Clerk": "John Doe",
]
dict.get(dict: positions, key: "Manager", default: "Unknown
position")
// Returns Jane Doe
dict.get(dict: positions, key: "Teller", default: "Unknown
position")
// Returns Unknown position
从列表创建字典
(1)导入 dict 包
(2)使用 dict.fromList( )函数从一个由 records 组成的数组中创建字典。其中,数组中
的每个 record 必须是{key:xxx,value:xxx}形式
import "dict"
list = [{key: "k1", value: "v1"}, {key: "k2", value: "v2"}]
dict.fromList(pairs: list)
// Returns [k1: v1, k2: v2]
向字典中插入键值对
(1)导入 dict 包
(2)使用 dict.insert( )函数添加一个新的键值对,如果 key 早就存在,那么就会覆盖这
个 key 对应的 value。
import "dict"
exampleDict = ["k1": "v1", "k2": "v2"]
dict.insert(dict: exampleDict, key: "k3", value: "v3")
// Returns [k1: v1, k2: v2, k3: v3]
从字典中移除键值对
(1)引入 dict 包
(2)使用 dict.remove 方法从字典中删除一个键值对
import "dict"
exampleDict = ["k1": "v1", "k2": "v2"]
dict.remove(dict: exampleDict, key: "k2")
// Returns [k1: v1]
2.4.3Array(数组)
定义
数组是一个由相同类型的值构成的有序序列。在语法上,数组是用方括号[ ]起来的一堆同类型元素,元素之间用英文逗号( , )分隔,并且类型必须相同。
["1st", "2nd", "3rd"]
[1.23, 4.56, 7.89]
[10, 25, -15]
从 Array 中取值
可以使用中括号 [ ] 加索引的方式从数组中取值,数组索引从 0 开始。
arr = ["one", "two", "three"]
arr[0]
// Returns one
arr[2]
// Returns two
检查一个数组中是否包含某元素
使用 contains( )函数可以检查一个数组中是否包含某个元素。
names = ["John", "Jane", "Joe", "Sam"]
contains(value: "Joe", set: names)
// Returns true
2.5正则表达式匹配
- FLUX 语言是 GO 语言实现的,因此使用 GO 的正则表达式语法。正则表达式需要声明在正斜杠之间 / /
- 使用正则表达式进行逻辑判断,需要使用 =~ 和 != 操作符。=~ 的意思是左值(字符串)能够被右值匹配,!~表示左值(字符串)不能被右值匹配。
import "strings"
import "array"
a = "abcdefg"
b = /abc|bcd|edf/
c = a=~b
array.from(rows: [{"value":c}])
将字符串转为正则表达式
import "regexp"
regexp.compile(v: "^- [a-z0-9]{7}")
// Returns ^- [a-z0-9]{7} (regexp type)
将匹配的子字符串全部替换
import "regexp"
r:正则表达式
v:要搜索的字符串
t: 一旦匹配,就替换为该字符串
regexp.replaceAllString(r: /a(x*)b/, v: "-ab-axxb-", t: "T")
// Returns "-T-T-"
得到字符串中第一个匹配成功的结果
import "regexp"
正则表达式
要进行匹配的字符串
regexp.findString(r:"abc|bcd",v:"xxabcwwed")
三Flux语言查询
3.1Flux查询InfluxDB语法
先往buckets(数据库)database_query导入一批测试数据

在数据看板Data Explorer中,查询过去1小时至今的数据
from(bucket: "database_query")
|> range(start: -1h)
会发现,这里有8条数据
前面的table,代表着有8个序列,这里需要注意一个点,就是measure+tag+field代表一个唯一序列,并且同一时刻只能插入一条最新的数据。什么意思呢,就是说原始数据
car,code=01 rate=30
car,code=01 rate=35
car,code=02 rate=36
car,code=01 rate=37,temp=18
car,code=02 rate=38,temp=20
bus,code=01 rate=38,temp=20
bus,code=02 rate=37,temp=21
这个里面的
car,code=01 rate=30
car,code=01 rate=35
car,code=01 rate=37
这三个的measure+tag+field都相同,同一时刻只会插入最新的一条car,code=01 rate=37。
需要注意的是:
原本插入的一条数据car,code=01 rate=37,temp=18在influxDB存储的时候,会存储到两个序列
car,code=01 rate=37和car,code=01 temp=18

我们继续插入数据
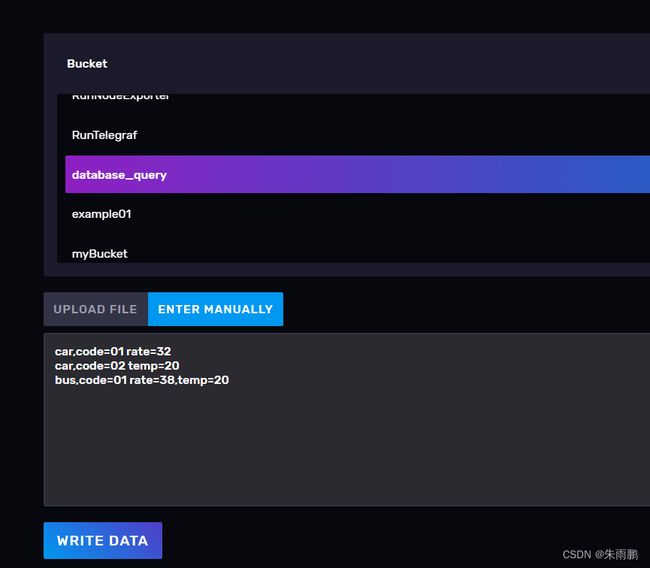
在数据看板Data Explorer中,查询过去1小时至今的数据
from(bucket: "database_query")
|> range(start: -1h)
我们发现,table值0-7,仍然还是8个序列
加入的值
car,code=01 rate=32
car,code=02 temp=20
bus,code=01 rate=38,temp=20
会被influxdb拆成
car,code=01 rate=32
car,code=02 temp=20
bus,code=01 rate=38
bus,code=01 temp=20
在加入influxdb后,出现了同一个序列存了多个值(在不同的时间存了一个),比如
属于一个序列(table都为0)不同时间点存了2个值
bus,code=01 rate=38
bus,code=01 rate=38
属于一个序列(table都为4)不同时间点存了2个值
car,code=01 rate=32
car,code=01 rate=37
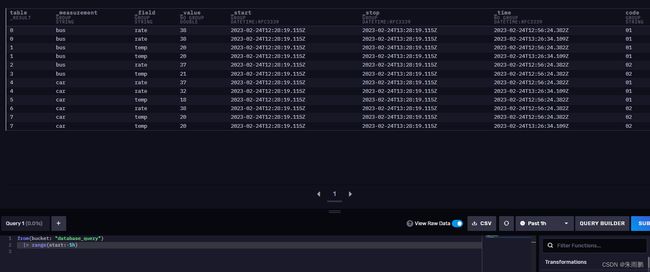
表、表流、序列
- 关系型数据库用表
- 时序数据库用序列
- influx语言为了更好的处理关系型数据库和时序数据库,使用了表流。表流可以理解为用表形成的数组。
- 我们用语句:select * from 全表 group by _measurement,_field,code可以得到整个表的所有序列。
使用influxdb语言查询,from后面接我们的bucket(数据库)
|>是管道符 range()函数查询时间范围,这里查询2小时至今的范围 group()函数代表分组
把原始数据对measurement分组
from(bucket: "database_query")
|> range(start:-2h)
|> group(columns: ["_measurement"])
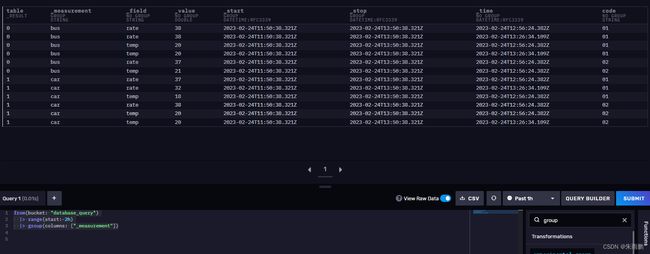
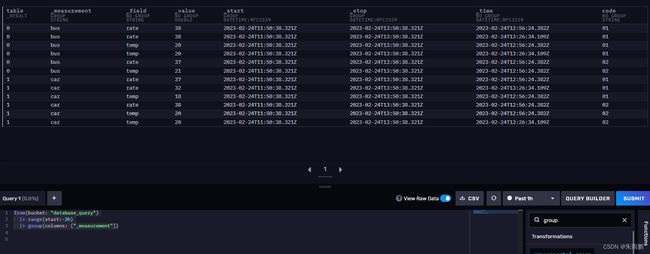
max()函数会得到所有序列里面的最大值
from(bucket: "database_query")
|> range(start:-2h)
|> max()
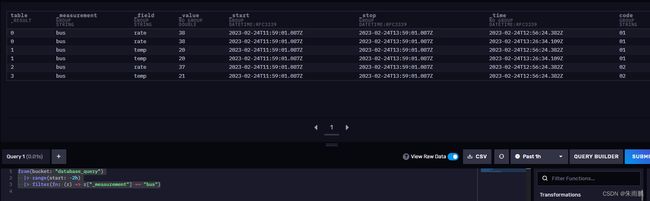
filter()函数会对序列里面的值进行过滤
我们只要measurement为bus的数据
from(bucket: "database_query")
|> range(start: -2h)
|> filter(fn: (r) => r["_measurement"] == "bus")
四、InfluxDB应用
4.1命令行方式写入数据
进入InfluxDB后,首先需要配置一个Buckets,类似数据库。
写一个案例,向InfulxDB插入一条数据。并且能查看。
先创建一个BUCKET
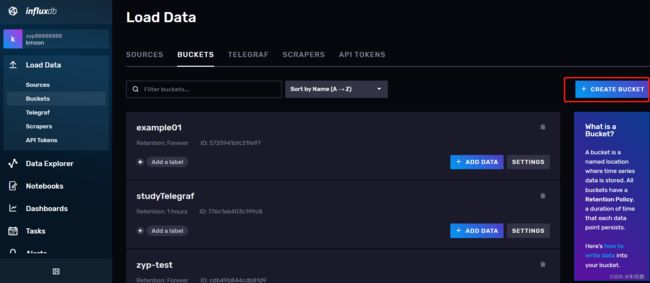
配置名字,以及是否要定期删除数据。坐标NEVER代表数据永久保留,右边可以选择数据定期删除

创建后可以添加数据
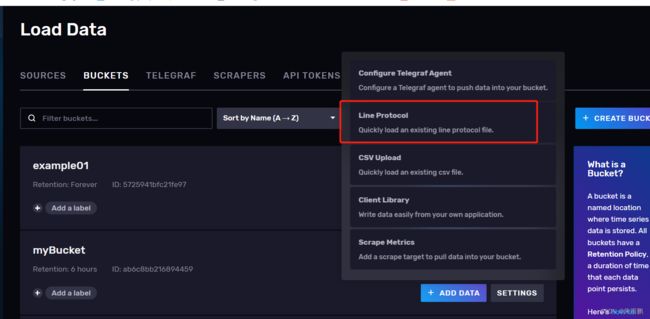
这里选择命令行方式插入数据
这是另外一个入口
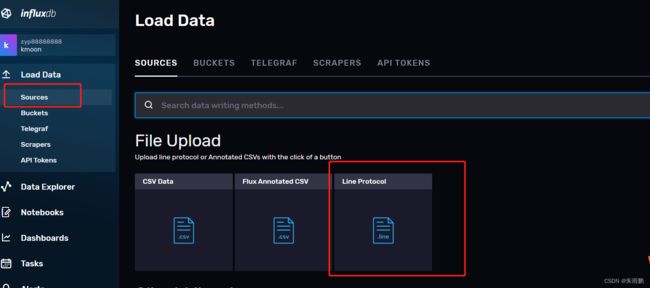
命令行写入数据
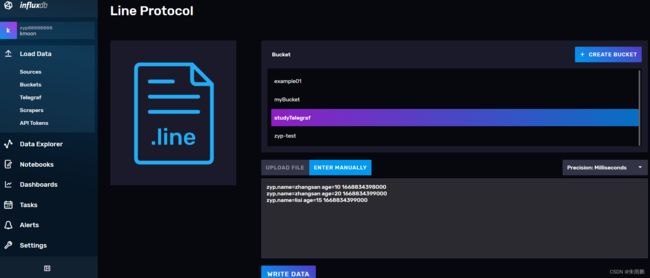
zyp,name=zhangsan age=10 1668834398000
zyp,name=zhangsan age=20 1668834399000
zyp,name=lisi age=15 1668834399000
数据可在视图中查看
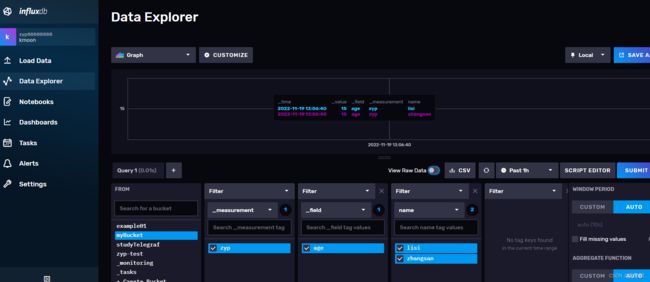
4.2用Telegraf将数据收集到InfluxDB
在InfluxDB上配置Telegraf,主要是配置Telegraf的配置文件,然后暴露一个URL给Telegraf启动时进行访问
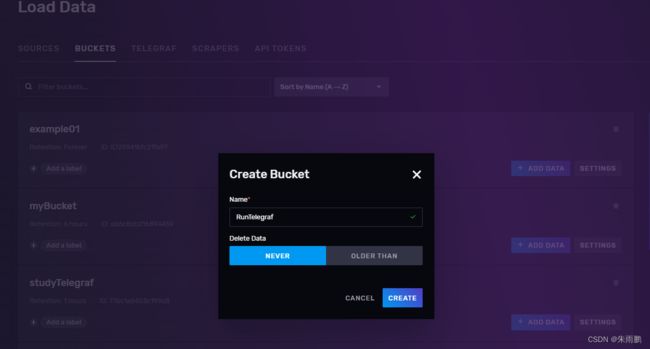
1.首先建一个Bucket便于测试
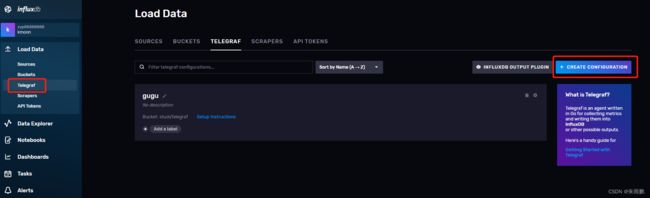
2.在InfluxDB中创建并配置Telegraf的配置文件
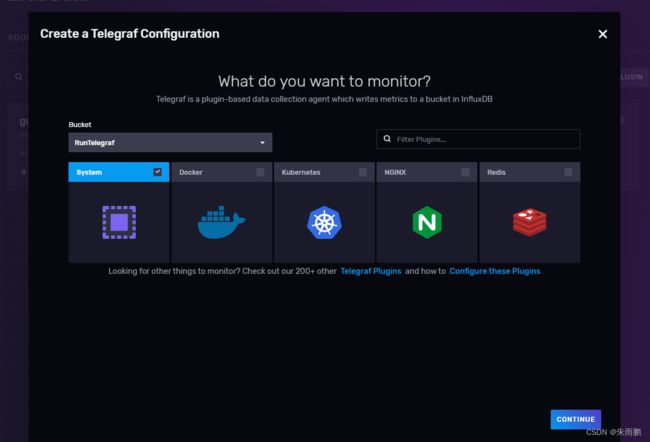
3.这里选择监控虚拟机系统的cpu,磁盘等
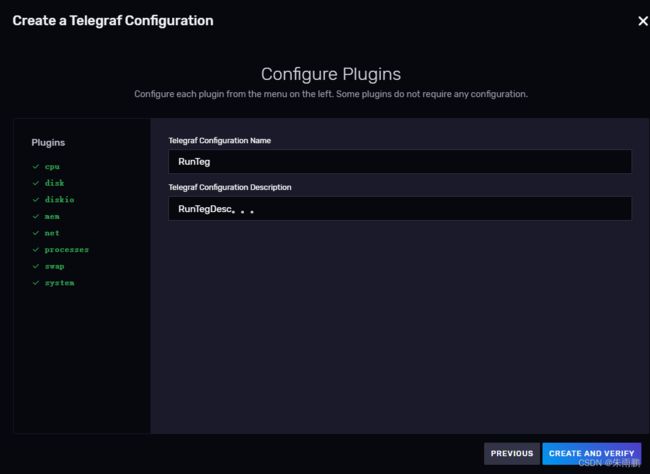
这里就是InfluxDB配置好的Telegraf配置文件,告诉了需要去安装Telegraf,然后配置Token后进行连接访问
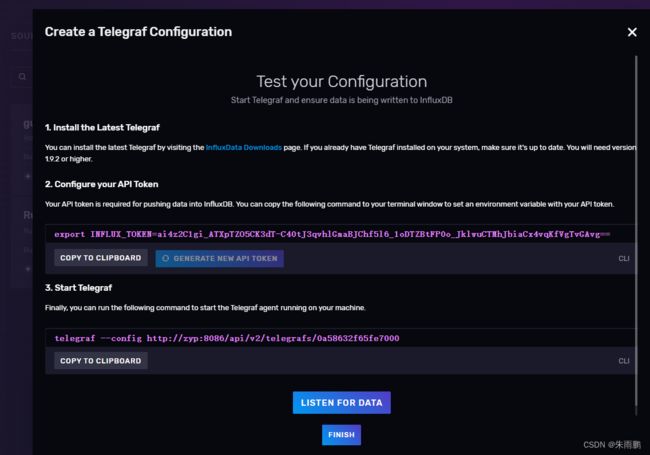
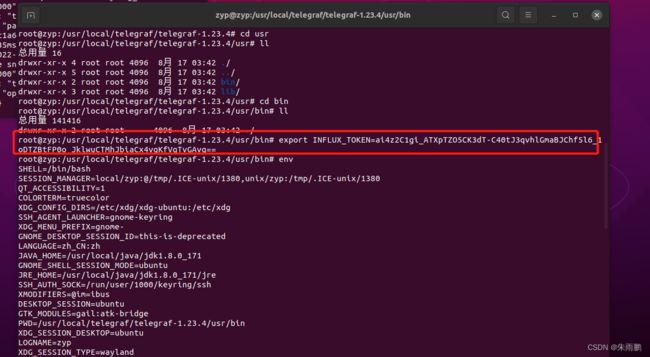
4.安装Telegraf后,配置连接InfluxDB的环境Token
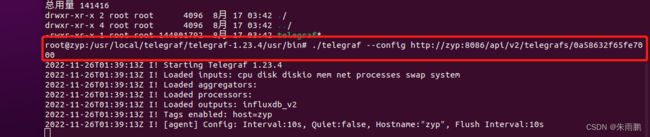
5.启动telegraf
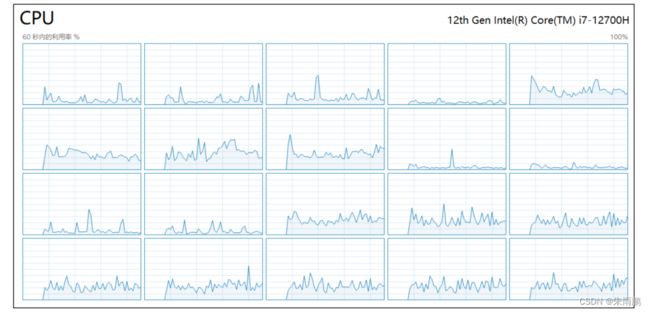
6.在InfulxDB中查看telegraf收集到的虚拟机cpu,磁盘等情况
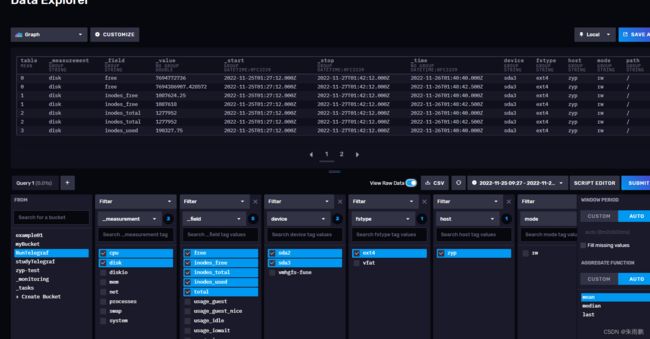
4.3使用node_exporter采集数据到InfluxDB
在Prometheus的架构设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据的收集,存储并且对外提供数据查询支持。因此为了能够能够监控到某些东西,如主机的CPU使用率,我们需要使用到Exporter采集数据,这里node_exporter就是采集数据的作用。
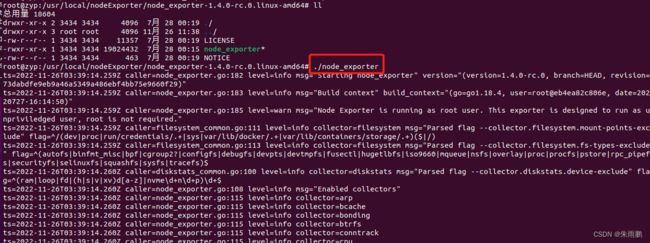
1.安装并启动node_exporter
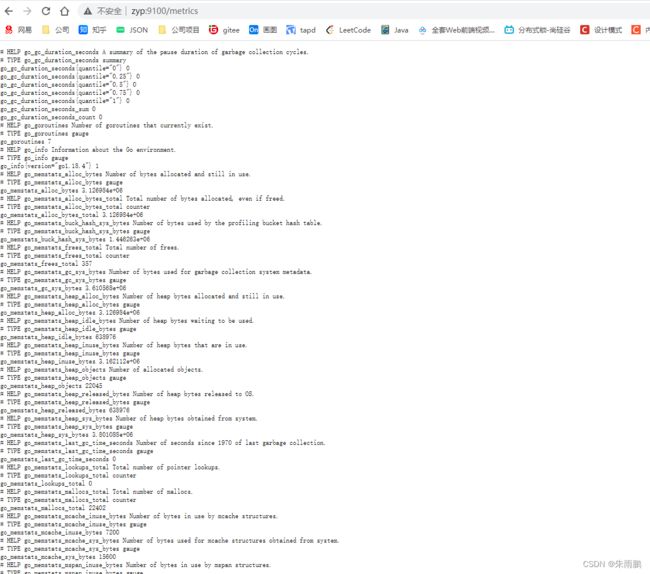
2.node_exporter收集的数据
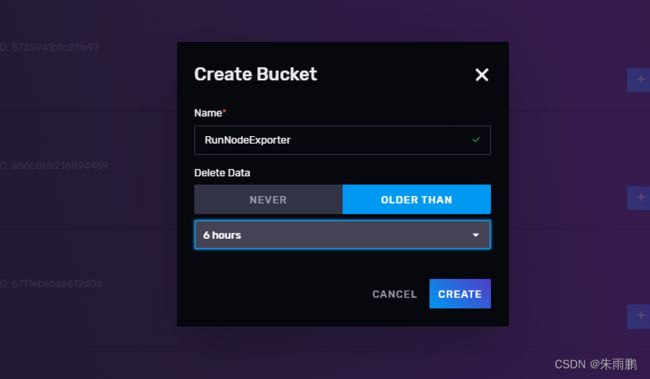
3.InfluxDB中配置展示node_exporter收集的数据
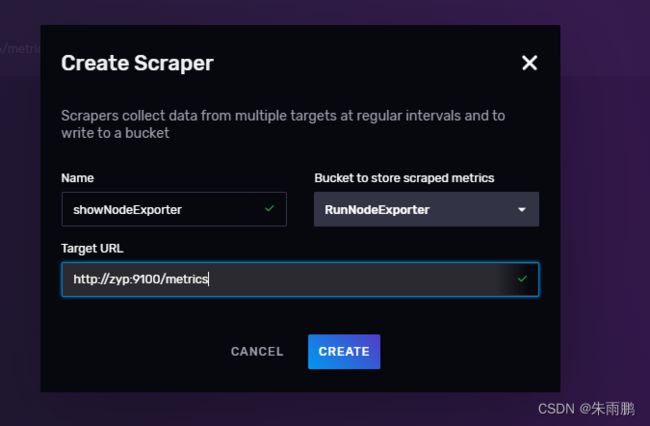
3.InfluxDB中查看node_exporter收集的数据
