Flink详解系列之九--反压机制和处理
反压是什么
反压是在实时数据处理中,数据管道某个节点上游产生数据的速度大于该节点处理数据速度的一种现象。反压会从该节点向上游传递,一直到数据源,并降低数据源的摄入速度。这在流数据处理中非常常见,很多场景可以导致反压的出现,比如, GC导致短时间数据积压,数据的波动带来的一段时间内需处理的数据量大增,甚至是checkpoint本身都可能造成反压。
反压的原理

上面是一个Flink任务的流程图,我们将反压过程拆分成两个部分:跨TaskManager的反压过程和TaskManager内的反压过程,最后再介绍一下基于Credit的反压过程。
跨TaskManager的反压过程
跨TaskManager的反压是怎么向上游传播的呢?在这之前我们先了解一下Flink中TaskManager 之间数据的网络传输过程。
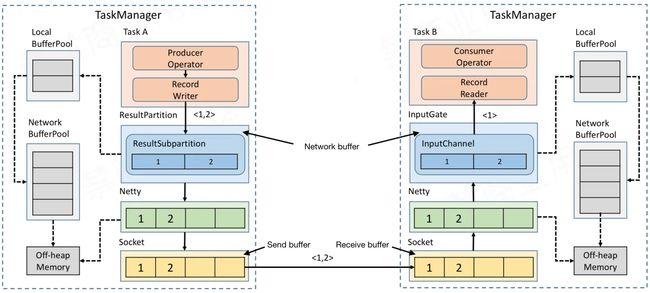
从上图可知,TaskManager A给TaskManager B发送数据,TaskManager A做为Producer,TaskManager B做为Consumer。Producer处理完的数据首先输出到Producer对应的NetWork Buffer中,NetWorkBuffer就是图中的ResultSubPartition和InputChannel。
ResultSubPartition和InputChannel都向LocalBufferPool申请Buffer空间,然后LocalBufferPool再向NetWork BufferPool申请内存空间。这里,NetWork BufferPool是TaskManager内所有Task共享的BufferPool,TaskManager初始化时就会向堆外内存申请NetWork BufferPool。LocalBufferPool是每个Task自己的BufferPool,假如一个TaskManager内运行着5个Task,那么就会有5个LocalBufferPool,但TaskManager内永远只有一个NetWork BufferPool。
Netty的Buffer也是初始化时直接向堆外内存申请内存空间。虽然可以申请,但是必须明白内存申请肯定是有限制的,不可能无限制的申请,我们在启动任务时可以指定该任务最多可能申请多大的内存空间用于NetWorkBuffer。
经过netty的buffer后,数据又会被拷贝到Socket的Send Buffer中,最后通过Socket发送网络请求,把Send Buffer中的数据发送到Consumer端的 Receive Buffer,并依图中所示,在Consumer端向上传递直到Consumer Operator。
假设Producer端生产速率为2,Consumer端消费速率为1。那么一段时间后消费端(Task B)的Network buffer会打满,即使向LocalBufferPool和Network BufferPool申请可用的资源,也会逐渐被用完。由于Network buffer已满,Netty也就不会从receive buffer读数据了,也即socket到netty的数据传输会阻塞。这样receive buffer很快会用完,TCP的Socket通信有动态反馈的流控机制,会把容量为0的消息反馈给上游发送端,所以上游的Socket就不会往下游再发送数据了。Producer端从send buffer向上传递过程类似,直到network buffer无空间可用,RecordWriter输出就被wait,Task A不再生产数据。
TaskManager内部的反压过程
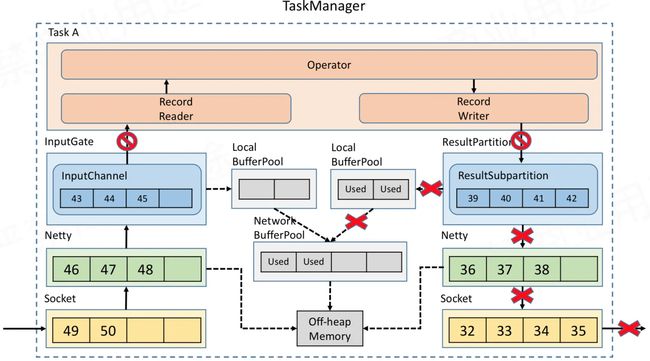
由于operator下游的buffer耗尽,此时Record Writer就会被阻塞,又由于Record Reader、Operator、Record Writer 都属于同一个线程,所以Record Reader也会被阻塞。这时上游数据还在不断写入,不多久network buffer就会被用完,然后跟前面类似,经是netty和socket,压力就会向上游传递。
基于Credit的反压过程

还以之前的图为例,在每一次ResultSubPartition向InputChannel发送消息时,都会发送一个backlog size告诉下游准备发送多少消息,下游会计算 Buffer空间大小去接收消息,如果有充足的Buffer就返还给上游一个Credit告知可以发送消息的大小(图中ResultSubPartition和InputChannel之间的虚线表示最终还是需要通过Netty和Socket去通信,并不是直接通信)。
相同的场景,上游生产的速率为2,下游消费的速率为1,这样InputChannel中的内存很快就会耗尽,通信过程中就会返回credit=0给ResultSubPartition告知上游,下游已经没有空间了,上游也就不再继续发送数据给netty,直到下游消费给InputChannel腾出空间了,数据才会继续发送。
基于credit的反压过程,效率比之前要高,因为只要下游InputChannel空间耗尽,就能通过credit让上游ResultSubPartition感知到,不需要在通过netty和socket层来一层一层的传递。另外,它还解决了由于一个Task反压导致 TaskManager和TaskManager之间的Socket阻塞的问题。
反压的影响
一般短时间的反压并不会对实时任务太大影响,如果是持续性的反压就需要注意了,意味着任务本身存在瓶颈,可能导致潜在的不稳定或者数据延迟,尤其是数据量较大的场景下。
反压的影响主要体现在Flink中checkpoint过程上,主要影响两个方面:
- 反压出现时,相关数据流阻塞,会使数据管道中数据处理速度变慢,按正常数据量间隔插入的barrier也会被阻塞,进而拉长,checkpoint时间,可能导致checkpoint超时,甚至失败。
- 在对齐checkpoint场景中,算子接收多个管道输入,输入较快的管道数据state会被缓存起来,等待输入较慢的管道数据barrier对齐,这样由于输入较快管道数据没被处理,一直积压可能导致OOM或者内存资源耗尽的不稳定问题。
如何定位反压
定位造成反压问题的节点,通常有两种途径。
- 压监控面板;
- Flink Task Metrics
前者简单易上手,适合简单分析,后者信息丰富,但需要更多背景知识,适合系统分析。
反压监控面板
Flink Web UI 的反压监控提供了 SubTask 级别的反压监控,通过周期性对 Task线程的栈信息采样,得到线程被阻塞在请求 Buffer(意味着被下游队列阻塞)的比例来判断该节点是否处于反压状态。默认配置如下:
- OK: 0 <= Ratio <= 0.10
- LOW: 0.10 < Ratio <= 0.5
- HIGH: 0.5 < Ratio <= 1
值得注意的是,反压的根源节点并不一定会在反压监控面板体现出高反压,因为反压面板监控的是发送端,如果某个节点是性能瓶颈并不会导致它本身出现高反压,而是导致它的上游出现高反压。总体来看,如果我们找到第一个出现反压的节点,那么反压根源要么是就这个节点,要么是它紧接着的下游节点。

Task Metrics
由于各指标在不同版本里,具体含义并不一致,在这里就先不列了,感兴趣的可以参考官网的介绍
分析反压的具体原因
根据上面介绍的方法,可以定位到反压问题的节点,也即数据处理的瓶颈,然后可以分析造成反压的原因。下面列出了一些从基本到复杂的原因。也要注意到,反压也可能是短暂的,比如,短时负载过大,检查点生成或者任务重启时处理积压的数据等,都会造成反压,但这些场景通常可以忽略。另外需要注意的是,分析和解决反压问题的过程也会受瓶颈本身非连续性的影响。
系统资源
首先,需要检查机器的资源使用情况,像CPU、网络、磁盘I/O等。如果一些资源负载过高,就可以进行下面的处理:
1、尝试优化代码;
2、针对特定资源对Flink进行调优;
3、增加并发或者增加机器
垃圾回收
性能问题常常源自过长的GC时长。这种情况下可以通过打印GC日志,或者使用一些内存/GC分析工具来定位问题。
CPU/线程瓶颈
有时候,如果一个或者一些线程造成CPU瓶颈,而此时,整个机器的CPU使用率还相对较低,这种CPU瓶颈不容易发现。比如,如果一个48核的CPU,有一个线程成为瓶颈,这时CPU的使用率只有2%。这种情况下可以考虑使用代码分析工具来定位热点线程。
线程争用
跟上面CPU/线程瓶颈问题类似,一个子任务可能由于对共享资源的高线程争用成为瓶颈。同样的,CPU分析工具对于探查这类问题也很有用。
负载不均
如果瓶颈是数据倾斜造成的,可以尝试删除倾斜数据,或者通过改变数据分区策略将造成数据的key值拆分,或者也可以进行本地聚合/预聚合。
上面几项并不是全部场景。通常,解决数据处理过程中的瓶颈问题,进而消除反压,首先需要定位问题节点(瓶颈所在),然后找到原因,寻找原因,一般从检查资源过载开始。