Spark连接Hive读取数据
#系统环境
Ubuntu 16.04 LTS
#镜像文件
ubuntu-16.04.6-desktop-i386.iso
#软件依赖(链接提取码:6666)
spark-3.0.0-bin-without-hadoop.tgz
hadoop-3.1.3.tar.gz
apache-hive-3.1.2-bin.tar.gz
spark-hive_2.12-3.2.2.jar
openjdk 1.8.0_292
mysql-connector-java-5.1.40.tar.gz
VMwareTools-10.3.23-16594550.tar.gz
目录
#系统环境
#镜像文件
#软件依赖(链接提取码:6666)
1. HADOOP环境搭建
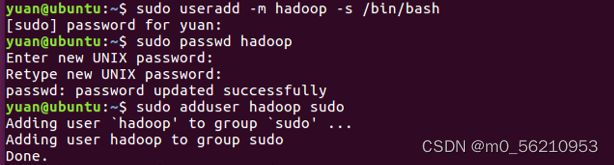
1.1 创建一个hadoop用户
1.2 更新软件源、安装Vim
1.3 安装SSH、配置SSH无密码登陆
1.4 安装Java环境
1.5 安装Hadoop3
2. Spark3环境搭建
2.1 Spark安装及配置
2.2运行实例SparkPi
3. 使用Spark-shell进行交互式编程
3.1 Hadoop伪分布式配置
3.2 使用Spark shell的准备工作
3.3 Spark RDD部分
3.4 Spark SQL部分
4. Hive3环境配置
4.1 安装配置Mysql
4.2 安装Hive
4.3 配置Mysql
4.4 HiveSQL操作
5. Spark连接Hive读写数据
5.1 前期准备
5.2 使用Spark读取Hive数据
1. HADOOP环境搭建
1.1 创建一个hadoop用户
$ sudo useradd -m hadoop -s /bin/bash
$ sudo passwd hadoop
$ sudo adduser hadoop sudo
1.2 更新软件源、安装Vim
$ sudo apt-get update
$ sudo apt-get install vim


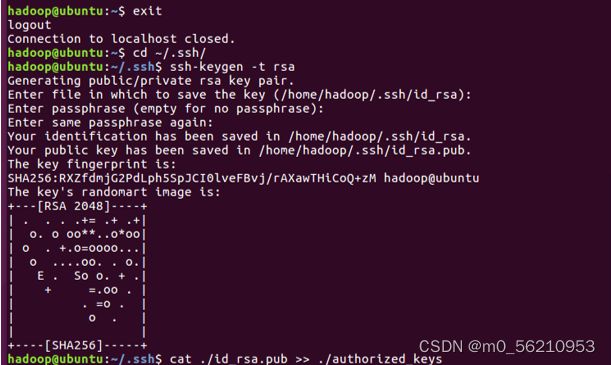
1.3 安装SSH、配置SSH无密码登陆
# 安装 SSH server
$ sudo apt-get install openssh-server

$ ssh localhost # 登陆本机

# 利用 ssh-keygen 生成密钥,并将密钥加入到授权中
$ exit # 退出刚才的ssh localho
$ cd ~/.ssh/
$ ssh-keygen -t rsa
$ cat ./id_rsa.pub >> ./authorized_keys # 加入授权
1.4 安装Java环境
1.4.1 安装JDK
# 安装JDK
$ sudo apt-get install default-jre default-jdk

1.4.2 配置环境变量
$ vim ~/.bashrc # 配置JAVA_HOME环境变量
export JAVA_HOME=/usr/lib/jvm/default-java

$ source ~/.bashrc # 使变量设置生效
$ echo $JAVA_HOME # 检验变量值
$ java -version

1.5 安装Hadoop3
$ cd /Downloads # 进入对应文件夹
$ sudo tar -zxf hadoop-3.1.3.tar.gz -C /usr/local # 解压到/usr/local中
$ cd /usr/local/
$ sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop
$ sudo chown -R hadoop ./hadoop # 修改文件权限

$ cd /usr/local/hadoop
$ /bin/hadoop version
![]()
2. Spark3环境搭建
2.1 Spark安装及配置
2.1.1 解压并赋予权限
$ cd Downloads
$ sudo tar -zxf spark-3.0.0-bin-without-hadoop.tgz -C /usr/local/
![]()
$ cd /usr/local
$ sudo mv ./spark-3.0.0-bin-without-hadoop/ ./spark
$ sudo chown -R hadoop:hadoop ./spark # 此处的 hadoop 为当前用户名

2.1.2 配置环境变量(添加时均在首行)
$ cd /usr/local/spark
$ cp ./conf/spark-env.sh.template ./conf/spark-env.sh
$ vim ./conf/spark-env.sh # 编辑spark-env.sh配置文件

export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
![]()
$ vim ~/.bashrc # 修改环境变量
![]()
export JAVA_HOME=/usr/lib/jvm/default-java
export HADOOP_HOME=/usr/local/hadoop
export SPARK_HOME=/usr/local/spark
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH
export PYSPARK_PYTHON=python3
export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH

$ source ~/.bashrc # 让该环境变量生效
![]()
2.2运行实例SparkPi
2.2.1 运行SparkPi
$ cd /usr/local/spark
$ bin/run-example SparkPi # 运行Spark自带实例SparkPi

2.2.2 过滤屏幕信息
$ bin/run-example SparkPi 2>&1 | grep "Pi is" # 过滤屏幕信息

3. 使用Spark-shell进行交互式编程
3.1 Hadoop伪分布式配置
3.1.1 修改配置文件
$ cd /usr/local/hadoop/etc/hadoop/
$ chmod a+rw core-site.xml # 设置可读写权限
$ chmod a+rw hdfs-site.xml
$ gedit core-site.xml # 使用gedit编辑配置文件

# 将其中的
$ gedit hdfs-site.xml # 使用gedit编辑配置文件
![]()
# 将其中的
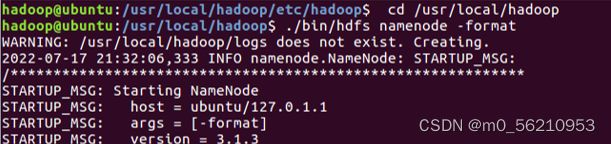
3.1.2 执行 NameNode 的格式化
$ cd /usr/local/hadoop
$ ./bin/hdfs namenode -format # 执行 NameNode 的格式化

3.1.3 报错Authentication failure解决方案(未出现忽略)
#若在切换root用户时出现Authentication failure问题,使用如下命令设置密码即可.
$ sudo passwd root
$ su root

3.1.4 开启NameNode和DataNode守护进程
$ cd /usr/local/hadoop
$ ./sbin/start-dfs.sh # 开启NameNode和DataNode守护进程
# 若在启动和使用期间出现WARN提示:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable WARN可以忽略,不会影响使用.

$ jps # 验证NameNode和DataNode守护进程是否开启成功

3.2 使用Spark shell的准备工作
3.2.1 启动hadoop
$ /usr/local/hadoop/sbin/start-dfs.sh # 启动hadoop

3.2.2 准备本地测试文件
# 本实验要在spark shell中进行词频统计,需准备一个本地文件,其中包含多个英文单词即可.text.txt的内容可随意输入,但不要出现中文字符,可以换行,这里使用安装Spark自带的README.md文件进行实验.
$ cd /home/hadoop
$ mkdir mydir # 创建mydir文件夹,便于下一步验证
$ cd mydir
$ vim text.txt
![]()

3.2.3将本地测试文件上传到HDFS.
$ ./bin/hdfs dfs -mkdir -p /user/hadoop # 创建一个hdfs文件夹

$ /usr/local/hadoop/bin/hdfs dfs -put /home/hadoop/mydir/text.txt /user/hadoop

3.2.4 启动Spark Shell
$ /usr/local/spark/bin/spark-shell #启动spark shell


# 进入Spark Shell需等待一段时间,如果见到scala>命令行,证明Spark Shell已经正常启动了.
3.3 Spark RDD部分
3.3.1 加载本地测试文件
scala> val textFile = sc.textFile("file:///home/hadoop/mydir/text.txt")
scala> textFile.first()

# 练习把textFile变量中的内容再写回到另外一个文本文件newtext.txt中.
scala> textFile.saveAsTextFile("file:///home/hadoop/mydir/newtext.txt")
![]()
3.3.2 加载HDFS文件
scala> val hdfsFile = sc.textFile("hdfs://localhost:9000/user/hadoop/text.txt“)
scala> hdfsFile.first() #查看文件的第一行

3.3.3 本地词频统计
scala> val wordCount = textFile.flatMap(line => line.split(" ")).map(word =>(word,1)).reduceByKey((a,b)=>a+b)
scala> wordCount.collect()

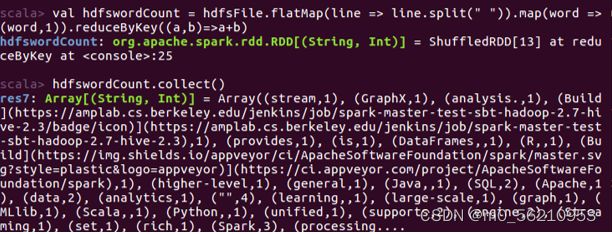
3.3.4 统计HDFS文件词频
scala> val hdfswordCount = hdfsFile.flatMap(line => line.split(" ")).map(word =>(word,1)).reduceByKey((a,b)=>a+b)
scala> hdfswordCount.collect()
完成后可使用:quit或ctrl+c强制退出.
3.4 Spark SQL部分
3.4.1 准备json文件
$ cd /usr/local/spark
$ vim example.json
![]()
{"name":"Michael","age":25,"gender":"male"}
{"name":"Judy","age":27,"gender":"female"}
{"name":"John","age":20,"gender":"male"}
{"name":"Mike","age":25,"gender":"male"}
{"name":"Mary","age":20,"gender":"female"}
{"name":"Linda","age":28,"gender":"female"}
{"name":"Michael1","age":25,"gender":"male"}
{"name":"Judy1","age":27,"gender":"female"}
{"name":"John1","age":20,"gender":"male"}
{"name":"Mike1","age":25,"gender":"male"}
{"name":"Mary1","age":20,"gender":"female"}
{"name":"Linda1","age":28,"gender":"female"}
{"name":"Michael2","age":25,"gender":"male"}
{"name":"Judy2","age":27,"gender":"female"}
{"name":"John2","age":20,"gender":"male"}
{"name":"Mike2","age":25,"gender":"male"}
{"name":"Mary2","age":20,"gender":"female"}
{"name":"Linda2","age":28,"gender":"female"}
{"name":"Michael3","age":25,"gender":"male"}
{"name":"Judy3","age":27,"gender":"female"}
{"name":"John3","age":20,"gender":"male"}
{"name":"Mike3","age":25,"gender":"male"}
{"name":"Mary3","age":20,"gender":"female"}
{"name":"Linda3","age":28,"gender":"female"}

3.4.2 Spark SQL操作(查看)
$ /usr/local/spark/bin/spark-shell # 启动Spark shell

scala> import org.apache.spark.sql.SQLContext # 引入SQLContext类
scala> val sql = new SQLContext(sc) # 声明一个SQLContext的对象

# 读取jason数据文件
scala> val peopleInfo = sql.read.json(“file:///usr/local/spark/example.json”)

scala> peopleInfo.schema # 查看数据
![]()
scala> peopleInfo.show # show方法,只显示前20条记录
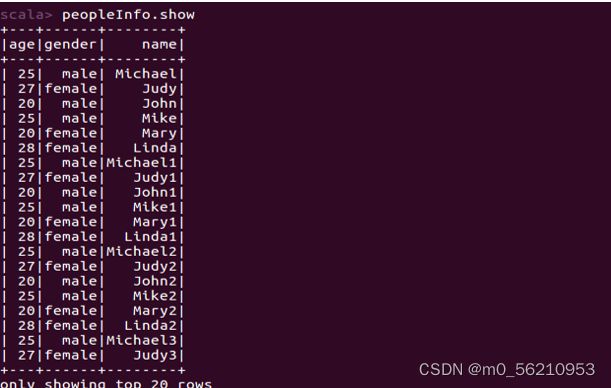
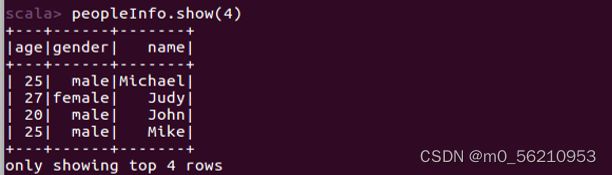
scala> peopleInfo.show(4) # show(numRows:Int),显示前n条记录
# show(truncate: Boolean),是否最多只显示20个字符,默认为true
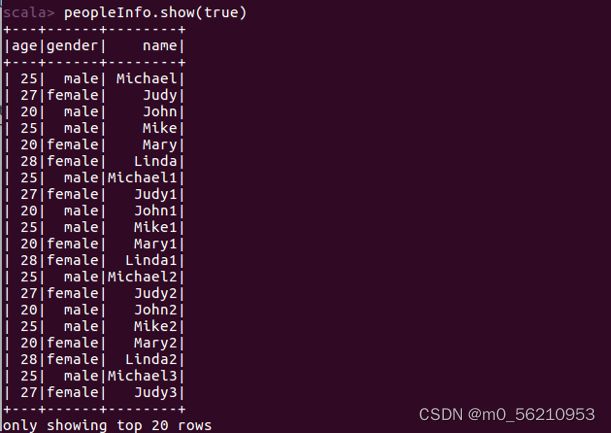
scala> peopleInfo.show(true)
scala> peopleInfo.show(6,false) # show(numRows: Int, truncate: Boolean)

3.4.3 Spark SQL操作(条件查询)
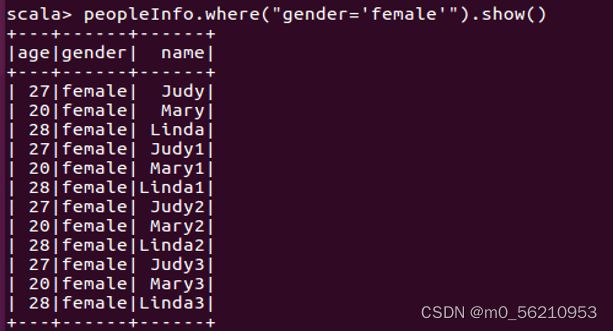
scala> peopleInfo.where("gender='female'").show() # 查询所有性别为女的记录
# 查询所有性别为女且年龄大于25岁的记录.
scala> peopleInfo.where("gender='female' and age>25").show()

scala> peopleInfo.filter("gender='male'").show() # 筛选性别为男的记录
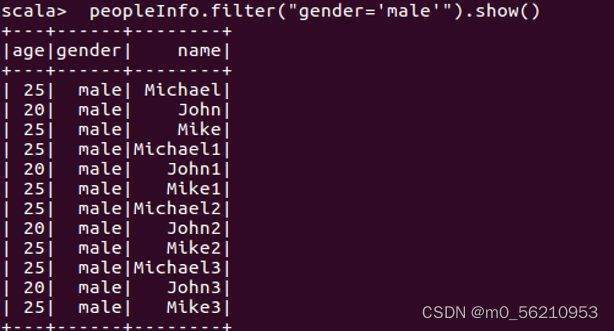
# 查询所有记录的姓名和年龄信息,不显示性别信息.
scala> peopleInfo.select("name","age").show()
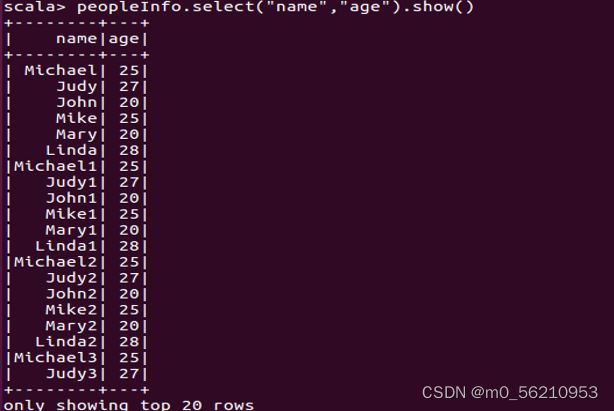
# 但是如果将filter换成where,就不必select出gender字段了.
scala> peopleInfo.select("name","age").where("gender='male'").show()

scala> peopleInfo.select("name","age","gender").filter("gender='male'").show()
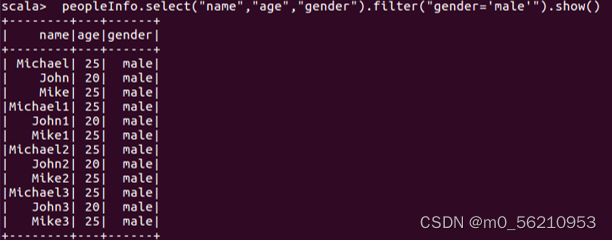
# 统计所有记录的平均年龄、最大年龄、最小年龄、总人数
scala> peopleInfo.describe("age").show()

# 统计性别为”male”和”female”的人数并显示结果
scala> peopleInfo.groupBy("gender").count().show()
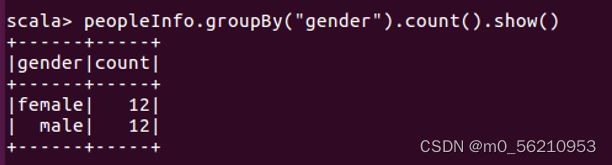
# 统计男性、女性分别的最大年龄并显示结果
scala> peopleInfo.groupBy("gender").max("age").show()

# 还可以试着统计一下女性的平均年龄并显示结果
scala> peopleInfo.where("gender='female'").groupBy("gender").mean("age").show()

4. Hive3环境配置
4.1 安装配置Mysql
4.1.1 更新软件源
$ sudo apt-get update #更新软件源
![]()
4.1.2 安装mysql
$ sudo apt-get install mysql-server #安装mysql

$ service mysql start # 启动Mysql服务器
$ service mysql stop # 关闭Mysql服务器
![]()
$ sudo netstat -tap | grep mysql #确认是否启动成功

4.2 安装Hive
4.2.1 下载并解压Hive安装包
$ sudo tar -zxvf ./apache-hive-3.1.2-bin.tar.gz -C /usr/local # 解压到/usr/local中

$ cd /usr/local/
$ sudo mv apache-hive-3.1.2-bin hive # 将文件夹名改为hive
![]()
$ sudo chown -R dblab:dblab hive # 修改文件权限
![]()
# 上面的hadoop: hadoop是用户组和用户名,如果当前使用其他用户名登录了Linux系统,则把hadoop替换成其他.
4.2.2 配置环境变量
$ vim ~/.bashrc
$ export HIVE_HOME=/usr/local/hive
$ export PATH=$PATH:$HIVE_HOME/bin
$ export HADOOP_HOME=/usr/local/hadoop

$ source ~/.bashrc
![]()
4.2.3 修改Hive配置文件
$ cd /usr/local/hive/conf
$ mv hive-default.xml.template hive-default.xml # 重命名为hive-default.xml
![]()
$ cd /usr/local/hive/conf
$ vim hive-site.xml # 新建一个配置文件hive-site.xml
![]()
# 在hive-site.xml中添加如下配置信息:

4.3 配置Mysql
4.3.1 解压并拷贝mysql jdbc包
$ tar -zxvf mysql-connector-java-5.1.40.tar.gz # 解压

# 将mysql-connector-java-5.1.40-bin.jar拷贝到/usr/local/hive/lib目录下
$ cp mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar /usr/local/hive/lib
![]()
4.3.2 启动并登陆Mysql shell
$ service mysql start #启动mysql服务
$ mysql -u root -p #登陆shell界面
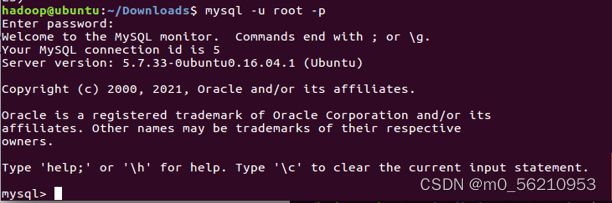
4.3.3 报错Access denied for user 'root'@'localhost'解决方案(未出现忽略)
$ sudo vim /etc/mysql/debian.cnf # 查看机器中的密码并复制
![]()

$ mysql -udebian-sys-maint -p
$ gkyTUQlkhgFMUrWm # 输入刚才复制的密码

mysql> select version(); # 查看数据库版本

mysql> use mysql; # 使用名为mysql的数据库

mysql> select user, plugin from mysql.user; # 查看root对应的plugin值
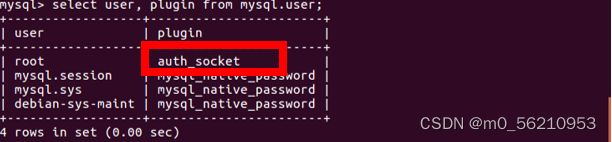
# 如果上一步中root对应的plugin的值是mysql_native_password,那么使用命令update user set authentication_string =password('666666') where user='root';否则使用update user set authentication_string =password('666666'),plugin='mysql_native_password' where user='root';
# 这里并非为mysql_native_password,选择后者作为命令.
mysql> update user set authentication_string =password('666666'),plugin='mysql_native_password' where user='root'; # 更新用户名为root的密码为666666

mysql> FLUSH PRIVILEGES; # 刷新,使之生效
![]()
4.3.4 配置Mysql
# hive数据库与hive-site.xml中localhost:3306/hive的hive对应,用来保存hive元数据
mysql> create database hive;
![]()
# 将所有数据库的所有表的所有权限赋给hive用户,后面的hive是配置hive-site.xml中配置的连接密码
mysql> grant all on *.* to hive@localhost identified by 'hive';
![]()
mysql> flush privileges; #刷新mysql系统权限关系表
![]()
4.3.5 启动Hive
$ /usr/local/Hadoop/sbin/start-dfs.sh #启动hadoop

$ cd /usr/local/hive
$ ./bin/schematool -dbType mysql -initSchema # 初始化数据库

$ hive # 启动hive

# 启动进入Hive的交互式执行环境以后,会出现如下命令提示符:hive>
4.3.6 出现java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument.报错的解决方案(未出现忽略)
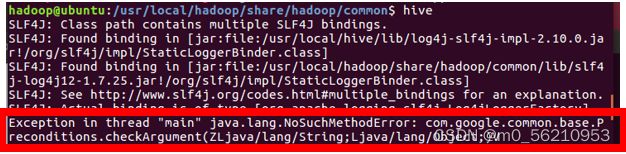
# 原因:com.google.common.base.Preconditions.checkArgument 这是因为hive内依赖的guava.jar和hadoop内的版本不一致造成的.
# 分别查看hadoop安装目录下share/hadoop/common/lib内guava.jar版本


# 如果两者版本不一致,删除版本低的,并拷贝高版本.
$ sudo rm -rf /usr/local/hive/lib/guava-19.0.jar # 删除低版本
$ cp -r /usr/local/Hadoop/share/hadoop/common/lib/guava-27.0-jre.jar/usr/local/hive/lib/ # 拷贝高版本guava-27.0-jre.jar
![]()
![]()
4.3.7 出现Hive-WARN: Establishing SSL connection without server‘s identity verification is not recommended. 报错的解决方案(未出现忽略)
# 进入hive-site.xml和hive-env.sh.template修改配置.
$ cd /usr/local/hive/conf
$ vim hive-site.xml
![]()
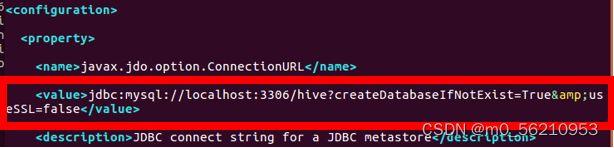
# 修改数据库配置为不使用SSL,将原有代码修改
Jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=True&useSSL=false
$ vim hive-env.sh.template
export HADOOP_HOME=/usr/local/hadoop # 首行添加配置
![]()

4.4 HiveSQL操作
hive> create database if not exists sparktest; # 创建数据库sparktest

hive> show databases; # 显示一下是否创建出了sparktest数据库

# 下面在数据库sparktest中创建一个表student
hive> create table if not exists sparktest.student(id int,name string,gender string,age int);

hive> use sparktest; # 切换到sparktest
hive> show tables; # 显示sparktest数据库下面有哪些表

hive> insert into student values(1,'Xueqian','F',23); # 插入一条记录

hive> insert into student values(2,'Weiliang','M',24); # 再插入一条记录

hive> select * from student; # 显示student表中的记录

5. Spark连接Hive读写数据
5.1 前期准备
5.1.1 修改配置文件
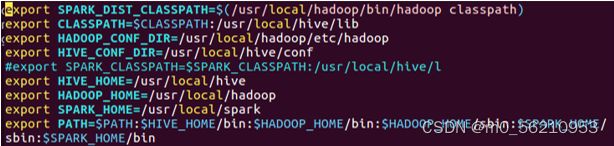
$ .bashrc
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export CLASSPATH=$CLASSPATH: /usr/local/hive/lib
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export HIVE_CONF_DIR=/usr/local/hive/conf
export HIVE_HOME=/usr/local/hive
export HADOOP_HOME=/usr/local/hadoop
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$HIVE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/sbin: $SPARK_HOME/bin
5.1.2 补充Jar包
# 将mysql-connector-java-5.1.40-bin.jar拷贝一份到 /usr/local/spark/jars 路径
$ cp /usr/local/hive/lib/mysql-connector-java-5.1.40-bin.jar .
![]()
# 补充spark-hive_2.12-3.2.2.jar包到/usr/local/spark/jars路径
$ cp -r /home/Downloads/spark-hive_2.12-3.2.2.jar /usr/local/spark/jars/
![]()
5.2 使用Spark读取Hive数据
5.2.1 进入spark-shell
$ cd /usr/local/spark/
$ ./bin/spark-shell

5.2.2 读取数据
Scala> import org.apache.spark.sql.Row
Scala> import org.apache.spark.sql.SparkSession
Scala> case class Record(key: Int, value: String)

Scala> val warehouseLocation = "spark-warehouse"
![]()
Scala>val spark = SparkSession.builder().appName("Spark Hive Example").config("spark.sql.warehouse.dir",warehouseLocation).enableHiveSupport().getOrCreate()

Scala> import spark.implicits._
Scala> import spark.sql

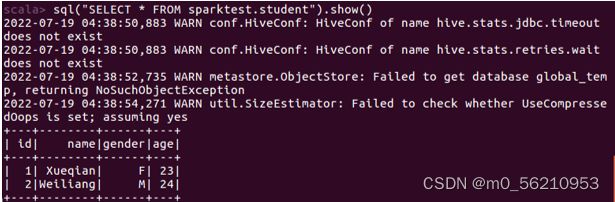
scala> sql("SELECT * FROM sparktest.student").show() # 显示运行结果
$ cd /usr/local/hive
$ ./bin/hive # 启动Hive对比插入数据前后Hive中的数据变化

hive> use sparktest;
hive> select * from student; # 令查看sparktest.student表中的数据

# 下面,我们编写程序向Hive数据库的sparktest.student表中插入两条数据,请切换到
spark-shell终端,输入以下命令:
scala> import java.util.Properties
scala> import org.apache.spark.sql.types._
scala> import org.apache.spark.sql.Row

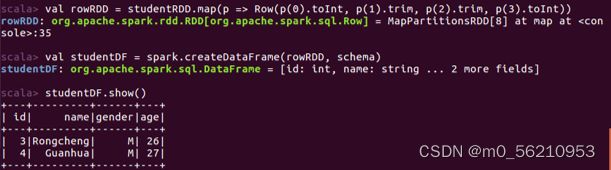
scala> val studentRDD = spark.sparkContext.parallelize(Array("3 Rongcheng M 26","4 Guanhua M 27")).map(_.split(" ")) # 设置两条数据表示两个学生信息
scala> val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("gender", StringType, true),StructField("age", IntegerType, true))) # 设置模式信息

scala> val rowRDD = studentRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).trim, p(3).toInt)) # 创建Row对象,每个Row对象都是rowRDD中的一行
# 建立Row对象和模式之间的对应关系,把数据和模式对应起来
scala> val studentDF = spark.createDataFrame(rowRDD, schema)
scala> studentDF.show() # 查看studentDF
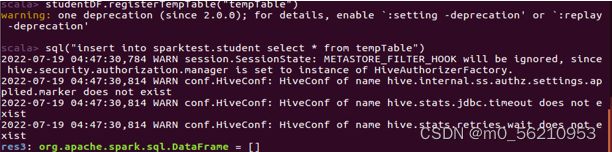
# 注册临时表
scala> studentDF.registerTempTable("tempTable")
scala> sql("insert into sparktest.student select * from tempTable")
# 切换到刚才的hive终端窗口,输入命令查看Hive数据库内容的变化可以看到插入数据操作执行成功了.
hive> select * from student;
