Pytorch学习系列-04-构建卷积神经网络实现CIFAR-10图片分类
- 对CIFAR-10数据集进行图像分类。数据集中的图像大小为32x32x3。

- 定义卷积神经网络的结构
这里,将定义一个CNN的结构。将包括以下内容:
(1)卷积层:可以认为是利用图像的多个滤波器(经常被称为卷积操作)进行滤波,得到图像的特征。
(2)通常,我们在 PyTorch 中使用 nn.Conv2d 定义卷积层,并指定以下参数:nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0)
(3)池化层:这里采用的最大池化:对指定大小的窗口里的像素值最大值。 在 2x2 窗口里,取这四个值的最大值。于最大池化更适合发现图像边缘等重要特征,适合图像分类任务。
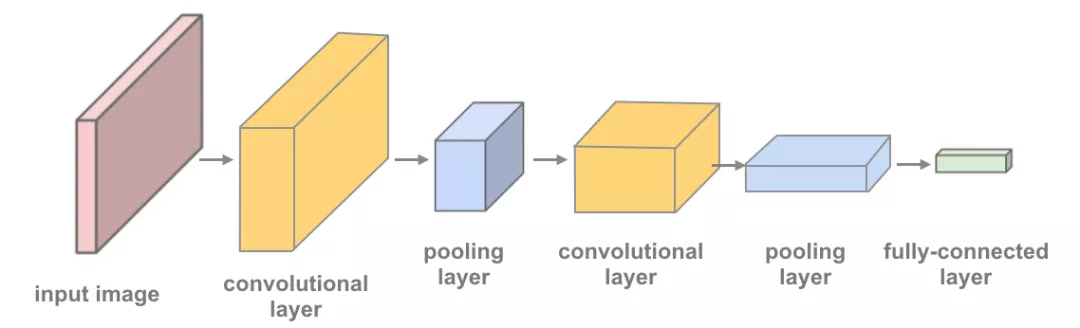
网络结构如下:
下面是完整的训练和测试代码:
import torch
import numpy as np
from torchvision import datasets
import torchvision.transforms as transforms
from torch.utils.data.sampler import SubsetRandomSampler
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
#检查是否可以利用GPU
train_on_gpu = torch.cuda.is_available()
if not train_on_gpu:
print ('CUDA IS NOT AVAILABLE!')
else:
print('CUDA IS AVAILABEL!')
#加载数据
num_workers = 0
#每批加载16张图片
batch_size = 16
# percentage of training set to use as validation
valid_size = 0.2
#将数据转换为torch.FloatTensor,并标准化
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
#选择训练集与测试集的数据
train_data = datasets.CIFAR10(
'data',train=True,
download=True,transform=transform
)
test_data = datasets.CIFAR10(
'data',train=True,download=True,transform=transform
)
#obtain training indices that will be used for validation
num_train = len(train_data)
indices = list(range(num_train))
np.random.shuffle(indices)
split = int (np.floor(valid_size*num_train))
train_idx,valid_idx = indices[split:],indices[:split]
#define samplers for obtaining training and validation batches
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
#perpare data loaders(combine dataset and sampler)
train_loader = torch.utils.data.DataLoader(train_data,batch_size=batch_size,
sampler=train_sampler,num_workers=num_workers)
valid_loader = torch.utils.data.DataLoader(train_data,batch_size=batch_size,
sampler=valid_sampler,num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(test_data,batch_size=batch_size,
num_workers=num_workers)
#10classes
classes = ['airplane','automobile','bird','cat','deer','dog','frog','horse','ship','truck']
# 定义卷积神经网络结构
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
#卷积层(32*32*3的图像)
self.conv1 = nn.Conv2d(3,16,3,padding=1)
#卷积层(16*16*16)
self.conv2 = nn.Conv2d(16,32,3,padding=1)
#卷积层(8*8*32)
self.conv3 = nn.Conv2d(32,64,3,padding=1)
#最大池化层
self.pool = nn.MaxPool2d(2,2)
#LINEAR LAYER(64*4*4-->500)
self.fc1 = nn.Linear(64*4*4,500)
#linear层(500,10)
self.fc2 = nn.Linear(500,10)
#dropout(p=0.3)
self.dropout = nn.Dropout(0.3)
def forward(self,x):
#add sequence of convolutinal and max pooling layers
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
#flatten image input
x = x.view(-1,64*4*4)
#add dropout layer
x = self.dropout(x)
# add 1st hidden layer,with relu activation function
x = F.relu(self.fc1(x))
# add dropout layer
x = self.dropout(x)
# add 2nd hidden layer,with relu activation function
x = self.fc2(x)
return x
#create a complete CNN
model = Net()
print (model)
if train_on_gpu:
model.cuda()
#选择损失函数与优化函数
#使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()
#使用随机梯度下降,学习率为0.01
optimizer = optim.SGD(model.parameters(),lr=0.01)
# 训练模型的次数
n_epochs = 30
valid_loss_min = np.Inf #track change in calidation loss
for epoch in range(1,n_epochs+1):
#keep tracks of training and validation loss
train_loss = 0.0
valid_loss = 0.0
##################
# 训练集的模型 #
##################
model.train()
for data,target in train_loader:
#move tensors to gpu if cuda is available
if train_on_gpu:
data,target = data.cuda(),target.cuda()
#clear the gradients of all optimized variables
optimizer.zero_grad()
#forward pass:compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the batch loss
loss = criterion(output,target)
#backward pass:compute gradient of the loss with respect to model parameters
loss.backward()
#perform a single optimization step(parameters updata)
optimizer.step()
#updata training loss
train_loss += loss.item()*data.size(0)
###############
# 验证集模型 #
##################
model.eval()
for data,target in valid_loader:
if train_on_gpu:
data,target = data.cuda(),target.cuda()
output = model(data)
loss = criterion(output,target)
valid_loss += loss.item()*data.size(0)
#计算平均损失
train_loss = train_loss/len(train_loader.sampler)
valid_loss = valid_loss/len(valid_loader.sampler)
#显示训练集与验证集的损失函数
print('Epoch:{} \tTraining loss:{} \tValidation loss:{}'.format(
epoch,train_loss,valid_loss
))
#如果验证集损失函数减少,就保存模型
if valid_loss <= valid_loss_min:
print ('Validation loss decreased ({} --> {}). Saving model ...'.format(
valid_loss_min,valid_loss
))
torch.save(model.state_dict(),'model_cifar.pt')
valid_loss_min = valid_loss
model.load_state_dict(torch.load('model_cifar.pt',map_location=torch.device('cpu')))
# track test loss
test_loss = 0.0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
model.eval()
# iterate over test data
for data, target in test_loader:
# move tensors to GPU if CUDA is available
if train_on_gpu:
data, target = data.cuda(), target.cuda()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
# calculate the batch loss
loss = criterion(output, target)
# update test loss
test_loss += loss.item()*data.size(0)
# convert output probabilities to predicted class
_, pred = torch.max(output, 1)
# compare predictions to true label
correct_tensor = pred.eq(target.data.view_as(pred))
correct = np.squeeze(correct_tensor.numpy()) if not train_on_gpu else np.squeeze(correct_tensor.cpu().numpy())
# calculate test accuracy for each object class
for i in range(batch_size):
label = target.data[i]
class_correct[label] += correct[i].item()
class_total[label] += 1
# average test loss
test_loss = test_loss/len(test_loader.dataset)
print('Test Loss: {:.6f}\n'.format(test_loss))
for i in range(10):
if class_total[i] > 0:
print('Test Accuracy of %5s: %2d%% (%2d/%2d)' % (
classes[i], 100 * class_correct[i] / class_total[i],
np.sum(class_correct[i]), np.sum(class_total[i])))
else:
print('Test Accuracy of %5s: N/A (no training examples)' % (classes[i]))
print('\nTest Accuracy (Overall): %2d%% (%2d/%2d)' % (
100. * np.sum(class_correct) / np.sum(class_total),
np.sum(class_correct), np.sum(class_total)))
网络结构:
Net(
(conv1): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=1024, out_features=500, bias=True)
(fc2): Linear(in_features=500, out_features=10, bias=True)
(dropout): Dropout(p=0.3, inplace=False)
)
训练30epcoh的模型在测试集上的结果:

参考链接:https://mp.weixin.qq.com/s?__biz=MzA4MDExMDEyMw==&mid=2247488531&idx=1&sn=1b081c828f09400538d9116c7751f2d8&chksm=9fa86357a8dfea41599e5b877cd9039fb84fbc0357ed2b9b4364bdc88278d0299f4dd5f9100b&scene=178#rd