06:流与并发
一般来说,在CUDA C编程中有两个级别的并发:
(1)内核级并发
单一的内核被GPU的多个线程并行执行。
(2)网格级并发
多个内核在同一设备上同时执行。
一、流和事件概述
CUDA流是一系列异步的CUDA操作,这些操作按照主机代码确定的顺序在设备上执行。
流能封装这些操作,保持操作的顺序,允许操作在流中排队,并使它们在先前的所有操作之后执行,并且可以查询排队操作的状态。流中操作的执行相对于主机总是异步的。
在同一个CUDA流中的操作有严格的执行顺序,而在不同CUDA流中的操作在执行顺序上不受限制。使用多个流同时启动多个内核,可以实现网格级的并发。
1. CUDA流
CUDA操作(内核和数据传输)都在一个流中显示或隐式地运行。流分为:
(1)隐式声明的流(空流)
(2)显式声明的流(非空流)
如果没有显式地指定一个流,内核启动和数据传输将默认使用空流。
cudaMemcpy函数的异步版本:
cudaError_t cudaMemcpyAsync(void *dst, const void *src, size_t count, cudaMemcpyKind kind, cudaStream_t stream = 0);
在非默认流中启动内核,必须在内核执行配置中提供一个流标识符作为第四个参数:
kernel_name<<>>(argument list); 一个非默认流声明如下:
cudaStream_t stream;非默认流可以使用如下方式进行创建:
cudaError_t cudaStreamCreate(cudaStream_t *pStream);cudaStreamCreate(&stream);可以使用如下代码释放流中的资源:
cudaError_t cudaStreamDestroy(cudaStream_t stream);在一个流中,当cudaStreamDestroy函数被调用时,如果该流中仍有未完成的工作,cudaStreamDestroy函数将立即返回,当流中所有的工作都已完成时,与流相关的资源将被自动释放。
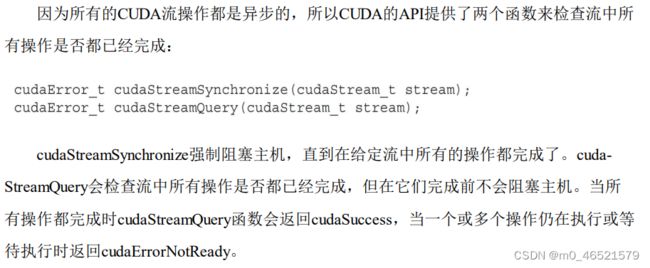
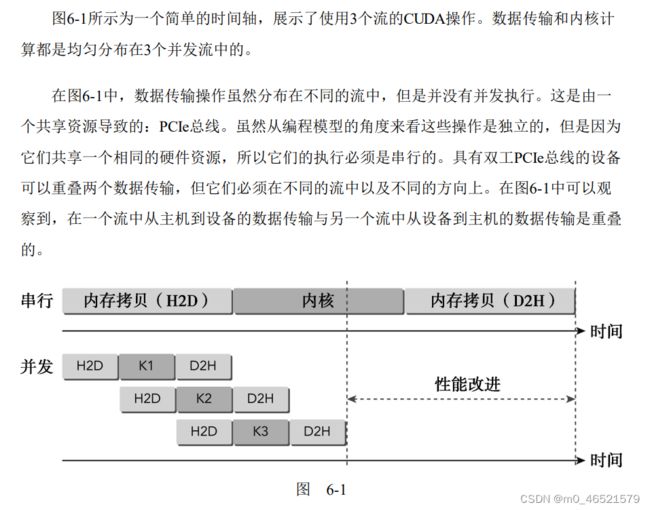
2. 流调度
- 费米架构,GPU支持最高16路并发
- 硬件工作队列只有一个,实际的并发不能达到理论值
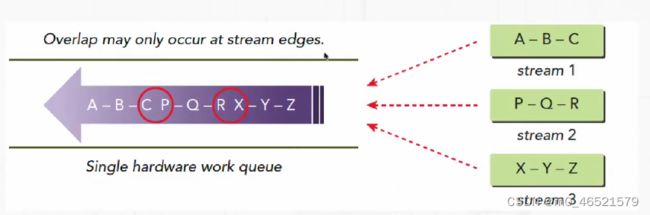
- Kepler架构引入Hyper-Q,避免了单一工作队列问题
- Kepler架构支持32个工作队列
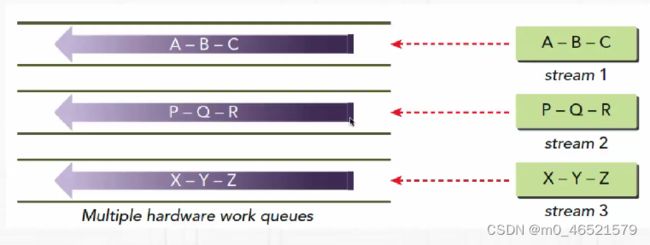
3. 流的优先级
优先级设置:cudaStreamCreateWithPriority
cudaError_t cudaStreamCreateWithPriority(cudaStream_t *pStream, unsigned int flags, int priority);创建一个具有指定整数优先级的流,并在pStream中返回一个句柄。这个优先级是与pStream中的工作调度相关的。高优先级流的网格队列可以有限占用低优先级流已经执行的工作。
cudaError_t cudaDeviceGetStreamPriorityRange(int *leastPriority, int *greatestPriority);一个较低的整数值表示更高的优先级。
4. CUDA事件
CUDA事件本质上是CUDA流中的标记,它与流内操作流中特定点相关联。可以使用事件来执行以下两个基本任务:
(1)同步流的执行
(2)监控设备的进展
CUDA的API提供了在流中任意点插入事件以及查询事件完成的函数。只有当一个给定CUDA流中先前的所有操作都执行结束后,记录在该流的事件才会起作用。
一个事件的声明:
cudaError_t event;一旦被声明,创建:
cudaError_t cudaEventCreate(cudaEvent_t *event);使用如下代码销毁一个事件:
cudaError_t cudaEventDestroy(cudaEvent_t event);当cudaEventDestroy函数被调用时,如果事件尚未起作用,则调用立即返回,当事件被标记完成时,自动释放与该事件相关的资源。
事件在流执行中标记了一个点。它们可以用来检查正在执行的流操作是否已经到达了给定点。它们可以看作是添加到CUDA流中的操作,当从工作队列中取出时,这个操作的唯一作用就是通过主机端标志来指示完成的状态。
事件排队进入CUDA流:
cudaError_t cudaEventRecord(cudaEvent_t event, cudaStream_t stream = 0);cudaError_t cudaEventSynchronize(cudaEvent_t event);cudaError_t cudaEventQuery(cudaEvent_t event);cudaError_t cudaEventElapsedTime(float *ms, cudaEvent_t start, cudaEvent_t stop);此函数返回事件启动和停止之间的运行事件,以毫秒为单位。事件的启动和停止不必在同一个CUDA流中。

5. 流同步
二、并发内核执行
1. CUDA流
- 从主机代码中发起,在同一个GPU设备上执行的一系列异步CUDA操作
- CUDA流封装CUDA操作,维持操作在队列中的顺序,查询操作状态
- CUDA流中的操作与主机程序异步执行
- 同一CUDA流中的操作具有严格执行顺序
- 使用多个CUDA流执行不同内核可以实现网格层面的并发执行
- CUDA操作包含:(1)主机和设备间数据传输;(2)内核执行;(3)其他由主机代码发起。由GPU执行的操作
- 内核执行、数据传递都是在CUDA流中执行
- CUDA流分为显式流和隐式流
- 如果没有显式定义流,在启动内核或者传递数据时都使用隐式流
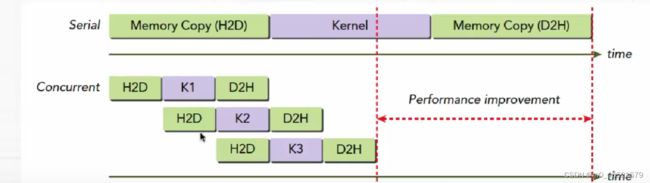
- 如果需要CUDA操作的重叠(overlap),就必须使用显示流:(1)主机和GPU计算重叠’;(2)主机计算和GPU数据传递重叠;(3)GPU计算和数据传递重叠;(4)GPU计算重叠
- 从主机和GPU角度分析如下代码执行:

2. CUDA流创建
(1)流对象
- CUDA平台流对象:cudaStream_t
- typedef struct CUstream_st *cudaStream_t;
(2)流对象创建
- 流对象创建:cudaStreamCreate
- 流对象释放:cudaStreamDestroy
3. 异步数据拷贝
(1)异步拷贝特点
- 异步数据拷贝在显式创建的CUDA流中完成
- 异步数据拷贝过程与主机线程异步执行
- 用于异步数据拷贝的主机内存必须是页锁定内存
(2)异步拷贝方法
- 异步拷贝:cudaMemcpyAsync
- 与主机同步:cudaStreamSynchronize