c语言文件操作
一、文件的作用:
1.通讯录一静态的版本,存放的联系人信息是创建时就固定的
2.通讯录一动态增长的版本,引入动态内存函数,根据需要扩容
//通讯录中的联系人信息是存放在[内存]中的,程序退出后,再次运行,又得重新输入信息
3.数据写到[文件]中,就可以持久化了
//文件是存储在硬盘中的,不会随程序结束或者关机而修改
二、为什么使用文件:
我们前面学习结构体时,写了通讯录的程序,当通讯录运行起来的时候,可以给通讯录中增加、删除数
据,此时数据是存放在内存中,当程序退出的时候,通讯录中的数据自然就不存在了,等下次运行通讯
录程序的时候,数据又得重新录入,如果使用这样的通讯录就很难受。
我们在想既然是通讯录就应该把信息记录下来,只有我们自己选择删除数据的时候,数据才不复存在。
这就涉及到了数据持久化的问题,我们一般数据持久化的方法有,把数据存放在磁盘文件、存放到数据
库等方式。
使用文件我们可以将数据直接存放在电脑的硬盘上,做到了数据的持久化
三、什么是文件:
磁盘上的文件是文件。
但是在程序设计中,我们一般谈的文件有两种:程序文件、数据文件(从文件功能的角度来分类的)。
1.程序文件:
包括源程序文件(后缀为.c),目标文件(windows环境后缀为.obj),可执行程序(windows环境后缀为.exe)。
1.1源程序文件:
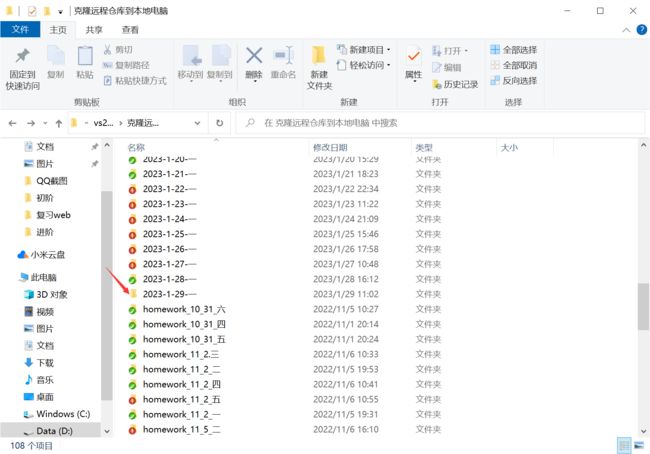
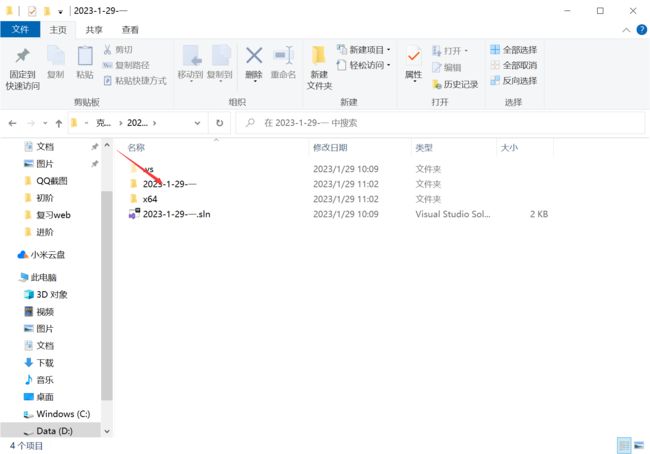
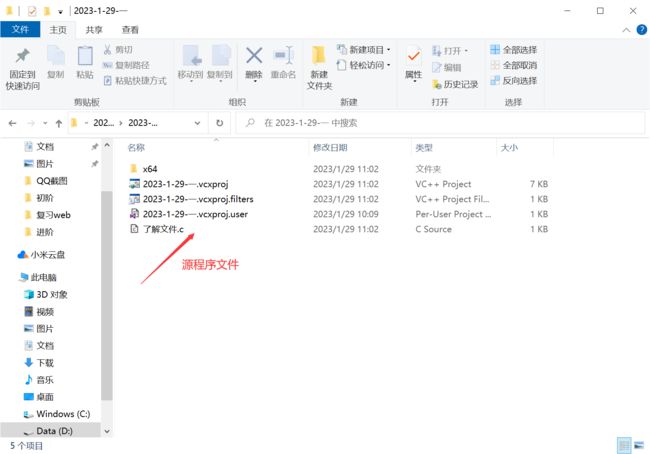
1.2 目标文件:
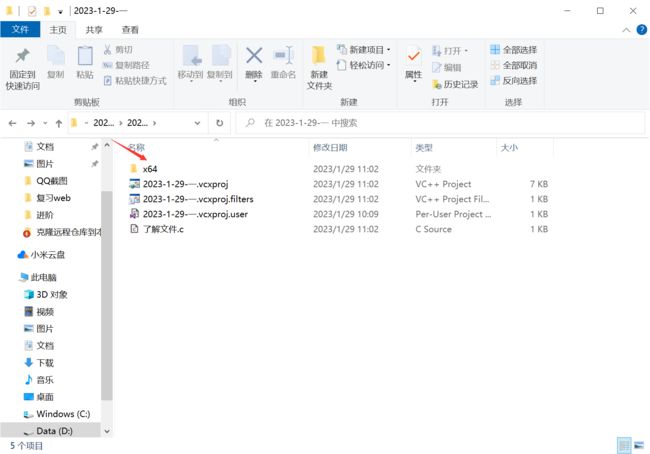
1.3可执行程序
2.数据文件
文件的内容不一定是程序,而是程序运行时读写的数据,比如程序运行需要从中读取数据的文件,或者输出内容的文件

本章讨论的是数据文件。
在以前各章所处理数据的输入输出都是以终端为对象的,即从终端的键盘输入数据,运行结果显示到显
示器上。
其实有时候我们会把信息输出到磁盘上,当需要的时候再从磁盘上把数据读取到内存中使用,这里处理
的就是磁盘上文件。
3.文件名
一个文件要有一个唯一的文件标识,以便用户识别和引用。
文件名包含3部分:文件路径+文件名主干+文件后缀
例如: c:\code\test.txt

为了方便起见,文件标识常被称为文件名
四、文件的打开和关闭
- 文件指针
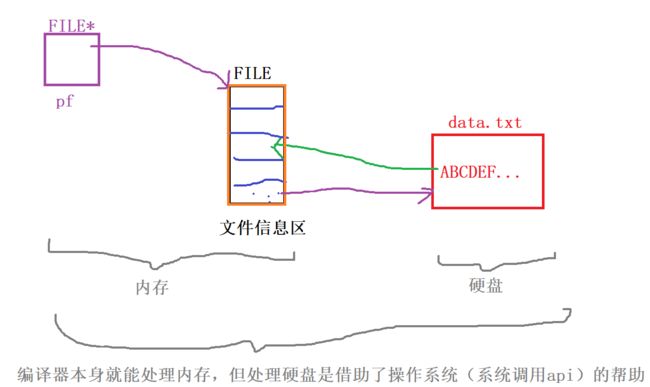
缓冲文件系统中,关键的概念是“文件类型指针”,简称“文件指针”。
每个被使用的文件都在内存中开辟了一个相应的文件信息区,用来存放文件的相关信息(如文件的名
字,文件状态及文件当前的位置等)。这些信息是保存在一个结构体变量中的。该结构体类型是有系统
声明的,取名FILE.
开辟文件信息区示例图说明:
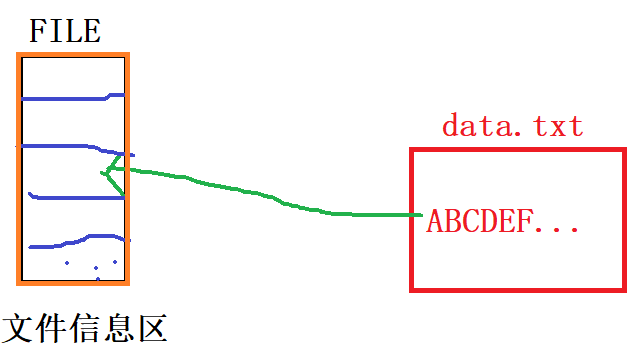
注:
①当文件被使用的时候,就会创建一个与之相关的文件信息区。
②文件信息区是一个FILE类型的结构体
③文件信息区内记录了与这个文件相关的信息
例如,VS2013编译环境提供的 stdio.h 头文件中有以下的文件类型申明:
struct _iobuf {
char *_ptr;
int _cnt;
char *_base;
int _flag;
int _file;
int _charbuf;
int _bufsiz;
char *_tmpfname;
};
typedef struct _iobuf FILE;
FILE* pf;//文件指针变量不同的C编译器的FILE类型包含的内容不完全相同,但是大同小异。
每当打开一个文件的时候,系统会根据文件的情况自动创建一个FILE结构的变量,并填充其中的信息,
使用者不必关心细节。
一般都是通过一个FILE的指针来维护这个FILE结构的变量,这样使用起来更加方便。
下面我们可以创建一个FILE*的指针变量:
FILE* pf;//文件指针变量定义pf是一个指向FILE类型数据的指针变量。可以使pf指向某个文件的文件信息区(是一个结构体变
量)。通过该文件信息区中的信息就能够访问该文件。也就是说,通过文件指针变量能够找到与它关联
的文件。
比如:
图示理解:
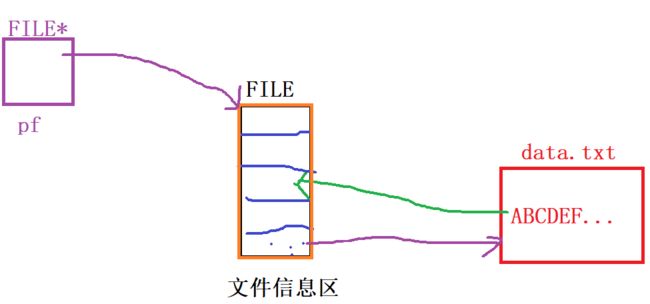
文件信息区详解
- 文件的打开和关闭
文件在读写之前应该先打开文件,在使用结束之后应该关闭文件。
在编写程序的时候,在打开文件的同时,都会返回一个FILE*的指针变量指向该文件,也相当于建立了指
针和文件的关系。
ANSIC 规定使用fopen函数来打开文件,fclose来关闭文件。(注:fopen是file open的简写;fclose是file close的简写)
要记住的是当打开文件后对数据进行处理完一定要关闭文件,否则可能会造成数据的丢失。
//打开文件的定义
FILE * fopen ( const char * filename, const char * mode );
//关闭文件的定义
int fclose ( FILE * stream );解释打开文件的定义:
filename顾名思义就是文件名
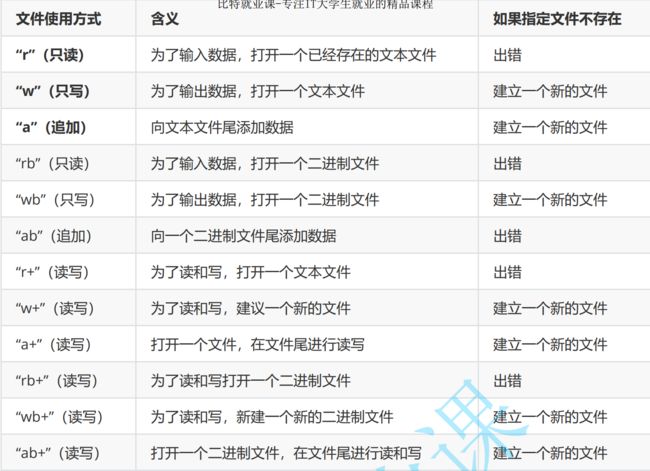
mode(模式),即打开文件的方式,分为两种情况:存放信息与读取信息
mode是char*类型的指针,存放的是字符串首字符的地址,于是出现了输入时的简写:
"r":Opens for reading. If the file does not exist or cannot be found, the fopen call fails
"w":Opens an empty file for writing. If the given file exists, its contents are destroyed.
"a":Opens for writing at the end of the file (appending) without removing the EOF marker before writing new data to the file;
creates the file first if it doesn’t exist.
"r+":Opens for both reading and writing. (The file must exist.)
"w+":Opens an empty file for both reading and writing.
If the given file exists, its contents are destroyed.
"a+":
对于文件的写入和读取方式,重点掌握以下几种即可。
以"r"举例:
FLIE* pf=fopen("test.txt","r");
//fopen函数的作用:①创建文件信息区 ②将文件信息区的起始地址返回
//该代码详解:
//当我们fopen打开一个文件的时候,比如打开text.txt文件。
//我们会在内存里面找一块区域,创建一个FILE类型的空间(即文件信息区),并把这个空间填好。
//然后把这个文件信息区的起始地址返回给FILE*的指针变量里去
//假如打开文件失败,会返回一个空指针
//见文件信息区详解图打开文件:
//打开文件
FILE* pf=fopen("test.txt","r");
//成功与否判断
if(pf==NULL)
{
perror("fopen");
return 1;
}
//操作文件:读文件(因为是"r")
//关闭文件
fclose(pf);
pf=NULL;
pf返回值为NULL
#include
int main()
{
FILE* pf = fopen("text.txt","r");
if (pf == NULL)
{
perror("fopen");
}
return 0;
} 输出结果:
让我们返回文件看看:

那我们现新建一个:
再运行一下程序:
运行结果:运行成功
随便提一嘴:当我们点击查看中的显示,取消文件扩展名时,text.txt会变成text
假如我没将text.txt在text.c(D盘)这个目录里面创建,而是跑C盘创建,怎么办?
答:使用绝对路径
FILE* pf = fopen("C:\\code\\text.txt","r");为什么这里我们要用\\而不是\?
因为\是转义字符,要用两个\才能表示\
6.这一切都是编译器完成的么?
以"w"举例:
FILE* pf=fopen("test.txt","w");运行前:
① 刚创建文件test.txt,还未在里面保存内容,存储大小为0
② 在记事本中添加内容,有了大小

运行后:
记事本的内容清空
解释:"w"是write的简写,意思是以写的形式打开文件。如果文件存在,则文件内容会被销毁。
即以w的形式打开文件,然后写入。文件里面的相关信息会被销毁与覆盖,重新写
五、文件的顺序读写
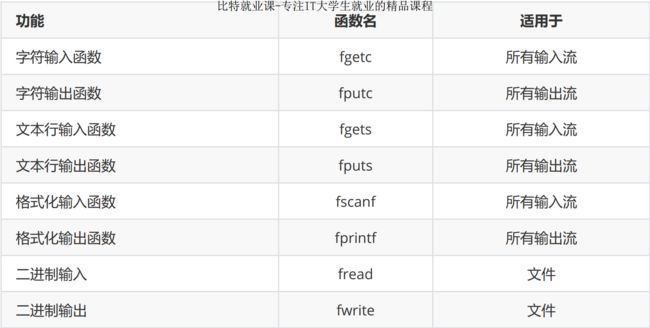
1.fputc:字符输出 fputc() 适用于所有输出流
函数原型:
int fputc ( int character, FILE * stream );函数说明:
fputc是一个字符一个字符去写进去文件,可以考虑循环
并且下一个写进去的字符是跟在前一个写进去的字符的屁股后面,像这样子有顺序的一直往后写,不会这儿写一个,那儿写一个这样子乱写,所以也叫顺序读写
举例:
case 一:以fputc为例,输出abcdefg:
#include
int main()
{
//打开文件
FILE* pf = fopen("test.txt", "w");
//判断
if (pf == NULL)
{
perror("fopen");
return 1;
}
操作文件:写文件--输出操作
fputc('a', pf);
fputc('b', pf);
fputc('c', pf);
fputc('d', pf);
fputc('e', pf);
fputc('f', pf);
fputc('g', pf);
fputc('h', pf);
return 0;
} 运行结果:
但test.txt记事本内容发生改变
case二:上面写文件部分太复杂太慢,简化一下:
#include
int main()
{
FILE* pf = fopen("test.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
char ch='a';
for(ch='a';ch<='z';ch++)
{
fputc(ch,pf);
}
return 0;
} case三、以fgetc为例,将记事本中的内容读进程序
#include
int main()
{
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
int ch=0;
while((ch=fgetc(pf))!=EOF)
{
printf("%c ",ch);
}
} 输出结果:
2.什么是流?

流:可以简单想象、理解成水流。
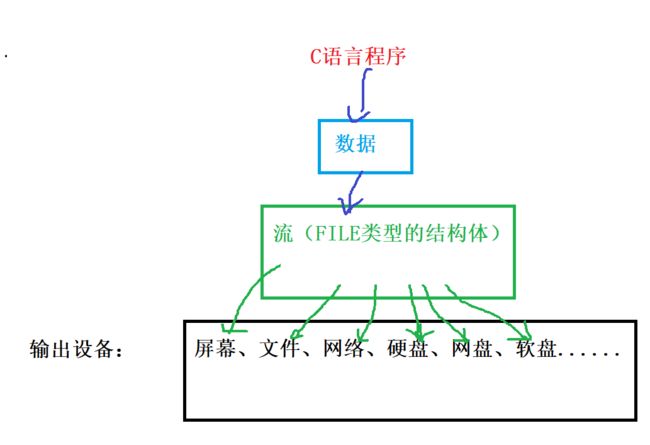
我们在内存中有数据的时候,这些数据我肯定要输出出来,我们可以打印在屏幕上,我们可以写在文件里面去,也可以放到网络上去,也可以放在硬盘网盘软盘上等其他介质上面,我们把这些叫做输出设备
未来我们的内存中的数据可能会输出到不同的各种各样的输出设备上去。我们内存数据打印在屏幕上,或者放在文件里或者放在网络上等等,这些各自的方式方法肯定都不一样,但是我们写C程序的时候,难道我们给这些外部输出设备(文件啊,甚至打印机啊等等)从内存输出数据的方式我都要一一懂吗?如果各种各样外部输出设备读写方式我都要懂的话,对我来说太复杂了。
这个时候我们就不关心外部输出设备了,C语言在这中间呢抽象出“流”这样一个概念,就像一个蓄水池一样,C语言你呢只要关心我把数据放到这个“流”里面去就可以了,至于说这些内存数据是如何到什么文件啊,屏幕啊,打印机啊,网络啊,各种盘啊什么的,不要关心,由C语言帮你分装,所有的这些内存里面要输出的数据我通通放到流里面去就OK了,这样大大简化了C语言程序员写代码的难度。
这个流的类型就是FILE这样一个结构体。这个流其实就是由我们的FILE*stream指针来管理的
流相当于是一个FILE类型的结构体,然后FILE*相当于是维护流的一个指针
3.内存(程序就是载入到内存)与外部输出设备的关系:
任何一个C语言程序运行的时候,默认会打开三个流:stdin(标准输入), stdout(标准输出), stderr(标准错误)。stdin, stdout, stderr就是三个管理标准输入流,标准输出流,标注错误流的FILE*指针

这个stdin针对的外部设备就是键盘,这个stdout针对的就是屏幕,stderr也是针对的屏幕。这三个管理流的指针的类型都是FILE*(流就可以理解为FILE类型的结构体
这也是为什么我每次从键盘上读取数据,从屏幕上打印信息,我们什么也不关心,直接无脑printf printf scanf scanf,那么因为已经默认打开了这三个流stdin,stdout stderr(标准流)。
除了这三个C语言本身默认打开的流以外,如果说内存数据要输出到文件里面,你要去看看针对文件的流有没有被打开, 如果说内存数据要输出到网络里面,你要去看看针对网络的流有没有被打开, 如果说内存数据要输出到软盘里面,你要去看看针对软盘的流有没有被打开........
4.内存(程序就是载入到内存)与文件的关系
1. 但是对于文件这个流来说,C语言是没有默认打开这个流的
2. 我们在操作文件的时候,首先要打开文件拥有这个流
3. 打开文件就好比打开了(没有被C语言默认打开的)针对文件的流,fopen()返回的FILE*指针与维护流的指针是一个道理
4. 打开了这个流就可以对文件输入输出数据了。
5. 这个流与我们打开文件的FILE*文件指针是一个道理的
5.内存与输入输出/读写的关系:
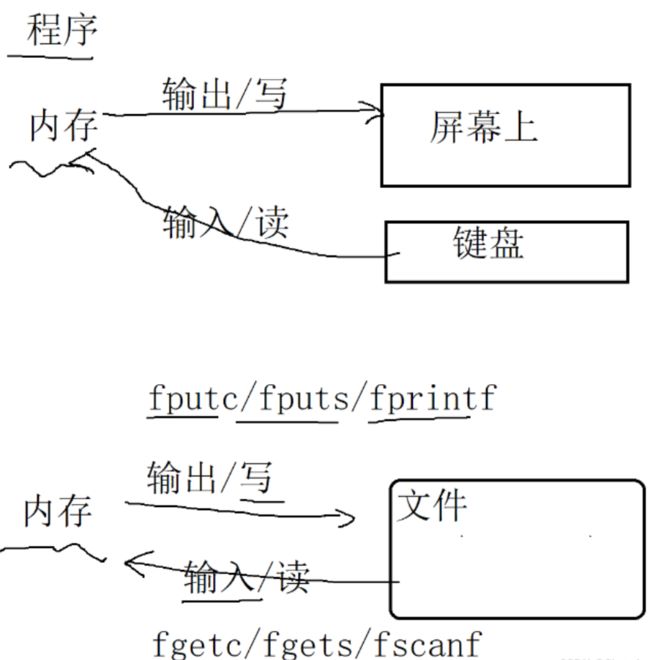
6.fgetc:字符输入 fgetc() 适用于所有输入流
函数原型:
int fgetc ( FILE * stream );函数说明:
读的时候道理一样,用函数fgetc去读字符,也是一个一个单独地这么去读
fgetc返回的是此次读到的那个字符的ASCII值。可以接受一下,用printf%c打印出来
当文件里面有多个字符的时候,我们用fgetc一个个去读取,此时定位文件位置的指针在fgetc每次读取完一次之后,就会后移一个字节往后走了一步指到下一个字符去了,因此fgetc一个个读取的话不需要顾虑太多,每次读取的时候只需要传参同一个FILE*结构体指针(事实上你其他的也传不了)
举例:
case 一:
#include
int main()
{
int ch=fgetc(stdin);//stdin表示键盘,fgetc(stdin)表示读到从键盘输入的那个字符的ASCLL码值
printf("%c\n",ch);
} 输出结果:我输入一个字符e,屏幕也输出一个e
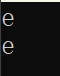
case 二:那我想输入字符串,同时输出字符串怎么办?
#include
int main()
{
int ch;
while ((ch = fgetc(stdin)) != EOF)
{
printf("%c",ch);
}
} 输出结果:

注意:
1. fgetc与fputc是针对字符的,读一个字符或者写一个字符。
2. fgetc如果读取成功,那么读取的字符的ASCII码值就会被返回,若读取失败,EOF就会被返回。
3. fputc的返回内容与fgetc雷同。
4. 字符与ASCII码要灵活转化,不要太死板
case 三:继续举例
#include
int main()
{
int ch=fgetc(stdin);
fputc(ch, stdout);//stdout表示屏幕,fputc(ch,stdout)表示将ch对应的ASCLL码值转成字符打印到屏幕上
} 输出结果:
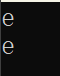
7.fputc:文本行(一行字符串)输出 fputs() 适用于所有输出流
函数原型:
int fputc ( int character, FILE * stream );函数说明:
fputs有两个参数,一个是字符串的首字符的地址,一个是要写进去的文件对应的文件信息区的文件指针。
字符串常量=字符串首字符的地址。
多个fputs使用写字符串进去的时候,如果你想要在互相之间有换行,fputs是不会自己给你弄的,你自己在写入字符串的时候就要自己输入\n换行符。
举例:
case 一:举个没有\n的例子
#include
int main()
{
FILE* pf = fopen("test.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
fputs("qwertyuiop", pf);
fputs("asdfghjkl", pf);
return 0;
} 输出结果:
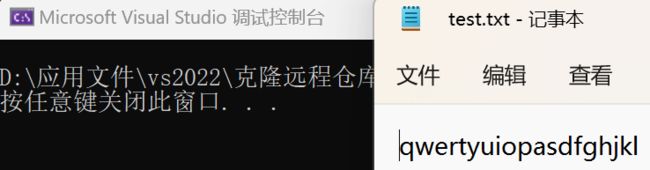
case 二:举个有\n的例
#include
int main()
{
//打开文件
FILE* pf = fopen("test.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//写文件:写一行
fputs("qwertyuiop\n", pf);//\n是换行用的,没有\n写入文件里时,俩字符串是紧接在一行的
fputs("asdfghjkl\n", pf);
return 0;
} 输出结果:
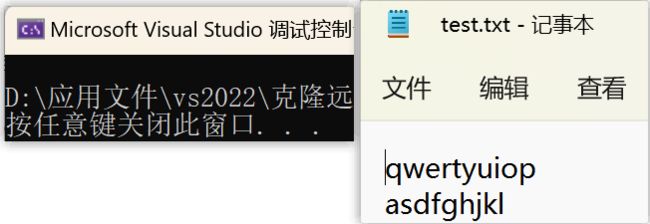
case 三:再举个例
#include
int main()
{
char ch[20] = { "study hard,please" };
fputs(ch,stdout);
} 输出结果:
8.fgets:文本行(一行字符串)输入 fgets() 适用于所有输入流
函数原型:
int fgetc ( FILE * stream );函数说明:
1. fgets参数有文件指针,还有char* str字符指针(这个就是说把从文件指针指向的文件信息区对应的文件里面读取到的东西拷贝到字符指针),还有num(这个就是说在读取文件的时候读取多少个字符)
2. 读取的时候要考虑一下\0,当你写参数说给我读五个字符,而真正发现屏幕上就只有4个字符,是因为它硬要在你的末尾放上一个\0,导致占用了你一个字符。因此,以后你想要读取5个的时候,你就写6就OK了,其他道理一样的。
3. 读取字符串的时候,空格也属于一个字符
4. 注意:这两个函数是只处理一行的,一行处理完了之后我就不会继续去处理下一行的,下一行与我一点关系没有。反正我只处理一行。
5. 并且如果我在读的时候碰着了\n(我们上面的fputs函数能写\n进去的从而导致换行),那么我也就直接换行了。
举例:
case 一:承接上面的”举个带\n的例“
#include
int main()
{
char arr[256] = { 0 };
//打开文件
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//操作文件:读文件 - 读一行
fgets(arr, 256, pf);
printf("%s",arr);//读的那一行末尾带\n,所以这里%S后面不用写\n
fgets(arr, 5, pf);//它最多给你读到5-1个字符,因为最后一个字符的位置是留给\0占用的
printf("%s", arr);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
} 输出结果:
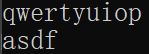
对应文件内容:
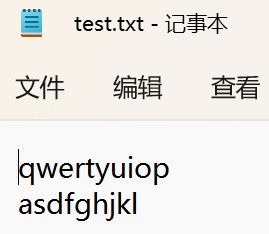
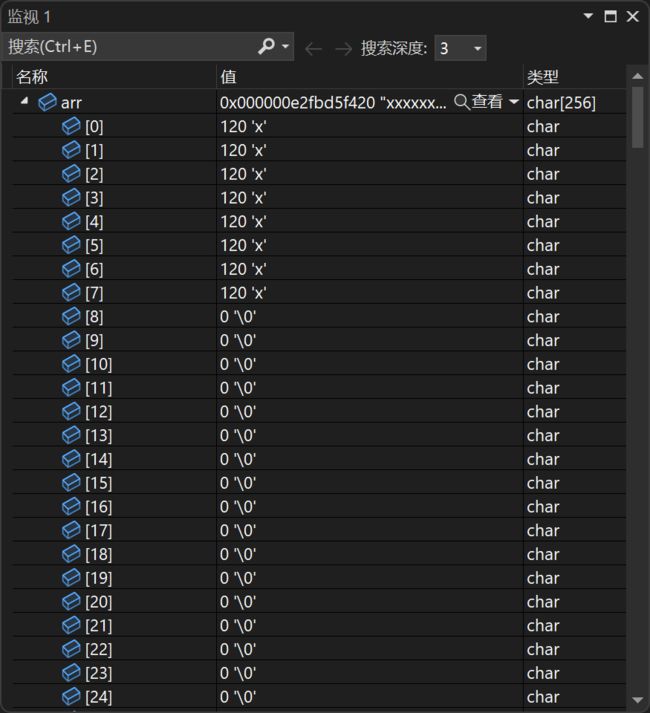
case 二:验证\0那个结论
#include
int main()
{
char arr[256] = "xxxxxxxx";
//打开文件
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//操作文件:读文件 - 读一行
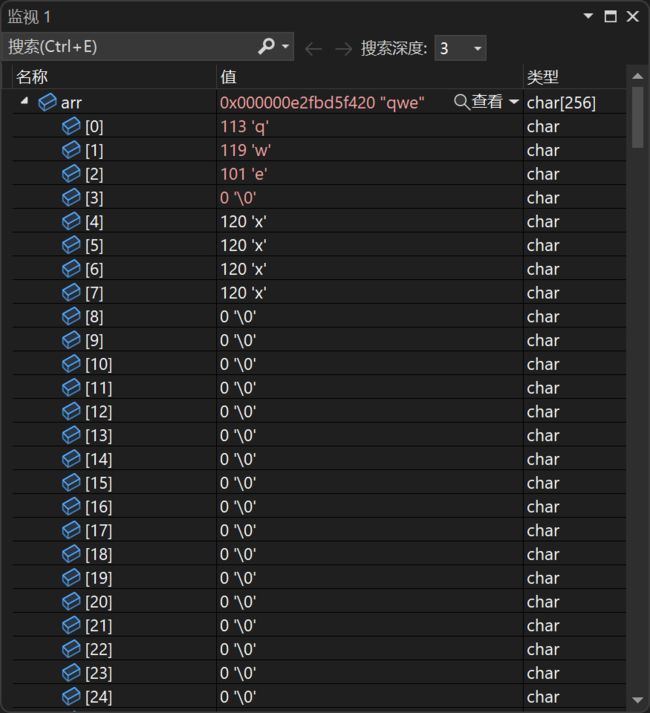
fgets(arr, 4, pf);
printf("%s",arr);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
} 覆盖前:
覆盖后:
case 三:假如我们不知道文件有几行,怎么写才能把文件读完?
#include
int main()
{
char arr[256] = "xxxxxxxx";
//打开文件
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//操作文件:读文件 - 读完文件内容
while (fgets(arr, 256, pf) != NULL)//遇到错误或者文件结束会返回空指针
{
printf("%s",arr);
}
//关闭文件
fclose(pf);
pf = NULL;
return 0;
输出结果:

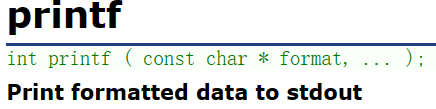
9.fprintf:格式化输出 fprintf() 适用于所有输出流
函数原型:
int fprintf ( FILE * stream, const char * format, ... );函数说明:
1. fprintf写入数据的话是带有格式化的数据
2. 对于fprintf与printf是非常类似的,我们去看一下它们的函数原型,发现参数里面后面有... ,这个东西其实比较奇怪的,叫做“可变参数列表"。其实也没有什么高级的,我们去回顾一下已经熟悉的不得了的printf的参数,你发现它的参数可以有1个,也可以有2个,3个,4个.....都可以有。后面的参数设计是为了具象化格式化里的模板。
3. 如果用fprintf的话非常简单,就先正常按照printf去写,然后在括号最前面再加上一个参数,即:指向要写入文件的文件信息区的文件指针。这就是把格式化的信息写到文件里面去。
printf与fprintf相比,就少了一个stream
举例:
case 一:
#include
struct S
{
char name[20];
int age;
double d;
};
int main()
{
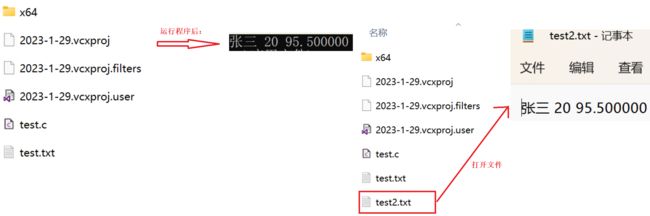
struct S s = { "张三",20,95.5 };
//打开文件
FILE* pf = fopen("test2.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//操作文件:写文件
//先写它:printf("%s %d %lf", s.name, s.age, s.d);
//再将其修改一下,就变成了fprintf:
fprintf(pf, "%s %d %lf", s.name, s.age, s.d);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
} 输出结果:
10.fscanf:格式化输入 fscanf() 适用于所有输入流
函数原型:
int fscanf ( FILE * stream, const char * format, ... );函数说明:
1. 格式化输出文件有了,那么如何格式化地读取文件呢?用fscanf。
2. fscanf就是从文件里面把里面的信息拿到内存里面去。这个函数又与scanf十分相似,参数比scanf多了一个FILE*指针。
3. 因此你先用scanf一如既往像以前那样正常写好,注意:scanf/fscanf的末尾几个参数都必须是地址形式,因为我是要把数据真真切切地读入到内存里面去,必须给我传地址!当然,数组名是首元素地址就不用&了。再在最前面加上参数:文件指针就OK了。
举例:
case 一:
#include
struct S
{
char name[20];
int age;
double d;
};
int main()
{
struct S s ={0};
//打开文件
FILE* pf = fopen("test2.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//操作文件:读文件:读取上个代码存在文件里的 ‘张三 20 95.500000’ 内容
//scanf("%s %d %lf", s.name, &(s.age), &(s.d));
fscanf(pf,"%s %d %lf", s.name, &(s.age), &(s.d));
printf("%s %d %lf", s.name, s.age, s.d);// fprintf(stdout,"%s %d %lf", s.name, s.age, s.d);这俩等价
//关闭文件
fclose(pf);
pf = NULL;
return 0;
} 输出结果:
11.sprintf:
函数原型:
int sprintf ( char * str, const char * format, ... );举例:
case 一:
#include
struct S
{
char name[20];
int age;
double d;
};
int main()
{
char str[256] = { 0 };
struct S s = { "zhangsan",20,95.5};
sprintf(str,"%s %d %lf",s.name,s.age,s.d);//把结构体数据转换成字符串
printf("%s",str);
return 0;
} 输出结果:
12.sscanf
函数原型:
int sscanf ( const char * s, const char * format, ...);举例:
case 一:
#include
struct S
{
char name[20];
int age;
double d;
};
int main()
{
char str[256] = "zhangsan 20 95.500000";
struct S tmp = { 0 };
//从str字符串中提取结构体数据
sscanf(str, "%s %d %lf", tmp.name, &(tmp.age), &(tmp.d));//把字符串转换成结构体数据
printf("%s %d %lf", tmp.name, tmp.age, tmp.d);//格式化的形式打印
return 0;
} 输出结果:
13.fwrite:二进制输出 fwrite() 只适用于针对文件的流
函数原型:
size_t fwrite ( const void * ptr, size_t size, size_t count, FILE * stream );函数说明:
1. 它是只能针对文件这个流的。
2. 当此时在打开文件的时候,这个打开方式可不能就用w与r了,因为那是打开一个文本文件.而我现在要打开一个二进制文件,应该用wb或者rb。
3. fwrite有四个参数,我此时此刻是从内存中往文件里面写入二进制数据,那我这个二进制数据到底是什么类型的呢?有各种各样的类型可能,但无论如何,二进制本身而言它就是死的。
4. 勤用sizeof
fwrite() 函数用来向文件中写入块数据
对参数说明:
ptr 为内存区块的指针,它可以是数组、变量、结构体等。fread() 中的 ptr 用来存放读取到的数据,fwrite() 中的 ptr 用来存放要写入的数据。
size:表示每个数据块的字节数。
count:表示要读写的数据块的块数。
stream:表示文件指针。
理论上,每次读写 size*count 个字节的数据。
size_t 是在 stdio.h 和 stdlib.h 头文件中使用 typedef 定义的数据类型,表示无符号整数,也即非负数,常用来表示数量
所谓块数据,也就是若干个字节的数据,可以是一个字符,可以是一个字符串,可以是多行数据,并没有什么限制举例:
case 一:
#include
struct S
{
char name[20];
int age;
double d;
};
int main()
{
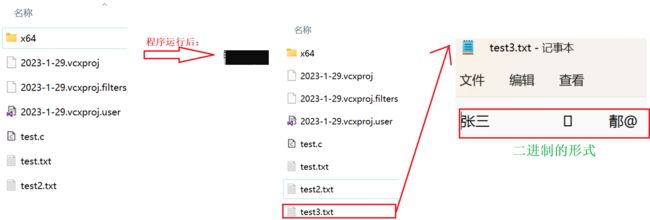
struct S s = { "张三",20,95.5 };
FILE* pf = fopen("test3.txt", "wb");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//操作文件:写文件 - 用二进制的方式写文件
fwrite(&s, sizeof(struct S), 1, pf);
fclose(pf);
pf = NULL;
return 0;
} 输出结果:
剖析 fwrite(&s, sizeof(struct S), 1, pf):
&S:告诉函数等会儿写入文件(test3.txt)的数据(内容)来自哪里,(这里是来自结构体数据)
sizeof(struct S):写进文件的数据大小
1:告诉函数等会儿写进文件的内容写1遍
pf:告诉函数等会儿把&s的内容写到哪个文件里去5. 我们以二进制的形式把内存中的数据写入到文件里面去,然后我们点开文件,确实里面的内容有些貌似可以看懂,有些是看不懂的。那我就让电脑通过二进制的方式在读出来。
6. 道理一样的,虽然我们肉眼看不懂,那就让程序去读。
14.fread:二进制输入 fread() 只适用于针对文件的流
函数原型:
size_t fread ( void * ptr, size_t size, size_t count, FILE * stream );函数说明:
fread() 函数用来从指定文件中读取块数据。
举例:
case 一:
#include
struct S
{
char name[20];
int age;
double d;
};
int main()
{
struct S s = {0};
FILE* pf = fopen("test3.txt", "rb");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//操作文件:读文件 - 用二进制的方式读文件
fread(&s, sizeof(struct S), 1, pf);
printf("%s %d %lf\n", s.name, s.age, s.d);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
} 剖析 fread(&s, sizeof(struct S), 1, pf):
&S:告诉函数等会儿去哪里读
sizeof(struct S):写进文件的数据大小
1:告诉函数等会儿写进文件的内容写1遍
pf:告诉函数等会儿数据写(内容)到哪里(test3.txt)去输出结果:

注:fgets() 有局限性,每次最多只能从文件中读取一行内容,因为 fgets() 遇到换行符就结束读取。如果希望读取多行内容,需要使用 fread() 函数;相应地写入函数为 fwrite()。
15.对比一组函数:

第一组:scanf与printf

第二组:fscanf与fprintf
fscanf - 针对所有输入流的格式化的输入函数
fprintf - 针对所有输出流的格式化的输出函数
第三组:sscanf与sprintf
sscanf - 把一个字符串转换成格式化的数据
sprintf - 把一个格式化的数据转换成字符串
注:这一组函数日后在前后端数据转换时会经常用到
顺带着一提:这是两组非常奇葩的函数
它们并不是流指针在与内存数据打交道了,而是内存数据与内存数据在自己打交道了
一个格式化的数据与字符串在打交道,站在格式化数据的立场上
改造通讯录:
六、文件的随机读写:
文件的随机读写也就是说我指哪打哪
1.fseek:人为调整指针指向的位置
函数原型:
int fseek ( FILE * stream, long int offset, int origin );stream:当前打开的文件
offset:相对当前地址的偏移量(右偏为正,左偏为负),单位是字节
origin:表示起始位置,是有选项的,关于这个参数有三个选项:
a.SEEK_SET,就是说从文件的起始位置开始算起;
b.SEEK_CUR,从当前文件指针的位置算起;
c.SEEK_END,就是说从文件的末尾开始算起
描 述: 函数设置文件指针stream的位置。如果执行成功,stream将指向以origin为基准,偏移offset个字 节的位置。如果执行失败(比如offset超过文件自身大小),则不改变stream指向的位置
返回值: 成功,返回0,否则返回其他值。
函数说明:
1. 根据文件指针FILE*的当前位置和你给出的偏移量来让它这个文件指针呢定位到你想要的位置上去。
2. 就是说我想让文件指针偏移到哪里,你就给我偏移到哪里
补充:文件指针的正常运走
1. 一旦打开文件,有个闪烁的光标(其实就是说刚开始打开文件的时候,文件指针是默认指向第一个字符的),这是最开始的状态。
2. 然后当你用fgetc()输入一个字符后,此时文件指针就不指向第一个字符了,往后走一步指向第二个字符去了。
3. 再用fgetc()不断去读,文件指针就不断往后偏移,一个一个字符不断读下去。这就是顺序读写,那如果说你想控制顺序跳过字符或者回去读之类的.....
举例:
#include
struct S
{
char name[20];
int age;
double d;
};
int main()
{
FILE* pf = fopen("test3.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
int ch = fgetc(pf);//指向文件第一个字符a的地址,并返回读到字符的ASCLL码值,存放到整型ch里面。作用后指针向后偏移
printf("%c\n",ch);//输出结果:a
ch = fgetc(pf);//指向第二个字符b的地址
printf("%c\n", ch);//输出结果:b
//关闭文件
fclose(pf);
pf = NULL;
return 0;
} 5. 这时候就用fseek去手动调整指针指向的位置,有三种写法。随着你第三个参数的不同,偏移量也不同(往左偏移,偏移量为负数;往右偏移,偏移量为正数)。
6. 然后不管你怎么去调整,默认的"读一下,往右偏移一个字符"这个铁律永远都在。但不管怎么说,fseek就是能调整指针指向的位置,读一位的话往右偏移一位那就让它偏呗。
举例:
case 一:
#include
struct S
{
char name[20];
int age;
double d;
};
int main()
{
FILE* pf = fopen("test3.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//随机读
fseek(pf, 2, SEEK_SET);//从文件的起始位置向后偏移2个字节
printf("%c\n",fgetc(pf));
//关闭文件
fclose(pf);
pf = NULL;
return 0;
} 输出结果:
case 二:偏移量为负
#include
struct S
{
char name[20];
int age;
double d;
};
int main()
{
//打开文件
FILE* pf = fopen("test3.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//随机读
fseek(pf, -2, SEEK_END);//从文件的末尾向前偏移2个字节
printf("%c\n",fgetc(pf));
//关闭文件
fclose(pf);
pf = NULL;
return 0;
} 输出结果:
case 三:随机读
#include
struct S
{
char name[20];
int age;
double d;
};
int main()
{
FILE* pf = fopen("test3.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
fputc('a', pf);
fputc('b', pf);
fputc('c', pf);
fputc('d', pf);
fseek(pf, -3, SEEK_CUR);//改变当前指针的位置。如果没有它,文件里写入abcd
fputc('w', pf);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
} 输出结果:
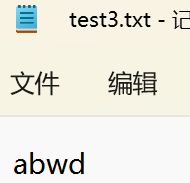
注:这里我们可以看到,fseek()函数只能帮我们覆盖字符,而不能在内容中插一个字符
2.ftell:当前指针位置相当于起始位置的偏移量
函数原型:
long int ftell ( FILE * stream );函数说明:
1. 如果我用fseek()的时候,里面内容很多,我弄着弄着也不知道偏移量多少了怎么办?
2.ftell就是来返回当前文件指针相对于起始位置的偏移量。这样子你可以得到偏移量,然后用fseek嘎嘎乱杀
举例:
case一:
#include
struct S
{
char name[20];
int age;
double d;
};
int main()
{
FILE* pf = fopen("test3.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
fputc('a', pf);
fputc('b', pf);
fputc('c', pf);
fputc('d', pf);
fseek(pf, -3, SEEK_CUR);//改变当前指针的位置。如果没有它,文件里写入abcd
fputc('w', pf);//文件中写入abwd,指针指向w
//从上面那个案例开始计算偏移量:
long pos= ftell(pf);
printf("%ld\n",pos);//ld是long的输出格式
//关闭文件
fclose(pf);
pf = NULL;
return 0;
} 输出结果:
补充:如果不知道函数类型,怎么写接收变量对应的类型
可以把鼠标虚浮在函数上面,VS会悬浮函数原型
图解:

3.rewind:让指针回到文件的起始位置
函数原型:
void rewind ( FILE * stream );函数说明:
1. 让我们的文件指针回到起始位置,当然了,fseek本身就具备这个能力。然而rewind也可以做到。
举例:
case 一:承接上个案例
#include
struct S
{
char name[20];
int age;
double d;
};
int main()
{
FILE* pf = fopen("test3.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
fputc('a', pf);
fputc('b', pf);
fputc('c', pf);
fputc('d', pf);
fseek(pf, -3, SEEK_CUR);//改变当前指针的位置。如果没有它,文件里写入abcd
fputc('w', pf);
//从上面那个案例开始计算偏移量:
long pos= ftell(pf);
printf("%ld\n",pos);
//返回起始位置:
rewind(pf);
//计算偏移量:
pos= ftell(pf);
printf("%ld\n", pos);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
} 输出结果:

七、文本文件和二进制文件
说明:
1. 根据数据的组织形式,数据文件又被称为文本文件与二进制文件。
举个浅显的例子,帮助区别文本文件和二进制文件:
文本文件:打开它的记事本咱能看懂
二进制文件:打开它的记事本,咱看不懂。跟个火星文一样......
顺便提一下目标文件(后缀为.obj的文件)就是二进制文件
图解:
打开test.txt记事本:
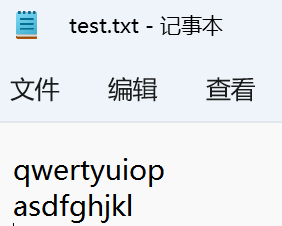
再打开test.obj记事本:

2. 我们知道,数据在电脑内存里面是以二进制补码形式存储,如果对内存里面的数据(纯纯的二进制)不加任何转换输出到外存(比如说输出到硬盘上啊文件里面去,反正就是写到文件里面去),这个时候就叫做二进制文件(即以二进制形式存储的文件即为二进制文件)。
3. 如果要求在外存上以ASCII码值的形式存储,则需要在存储前转换。以ASCII字符的形式存储的文件就是文本文件。(把字符对应的ASCII码值存到文件里面去,即以ASCII码值的形式存储)。
4. 当然,这里面还有一个大小端的问题,如果你在内存里面以小端形式存储,那么也会直接以小端的形式写到文件里面去
5.一个数据在内存中是怎么存储的呢?
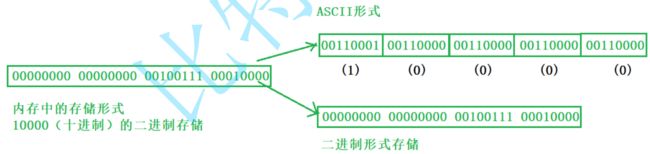
字符一律以ASCII形式存储,数值型数据既可以用ASCII形式存储,也可以使用二进制形式存储。
如有整数10000,如果以ASCII码的形式输出到磁盘,则磁盘中占用5个字节(每个字符一个字节),而
二进制形式输出,则在磁盘上只占4个字节(VS2013测试)
图解:
疑惑:ASCLL码形式的数值怎么得来的?
以1为例:字符1的ASCLL码值为49,49对应的二进制为0011 0001
举例:
case 一:
#include
int main()
{
int a = 10000;
FILE* pf = fopen("test.txt", "wb");//翻译:打开二进制文件test.txt
if (pf == NULL)
{
perror("fopen");
return 1;
}
fwrite(&a, 4, 1, pf);//翻译:把a这个整型,大小4个字节,写1次,写到pf指向的文件中去
fclose(pf);
pf = NULL;
return 0;
} 运行结果:
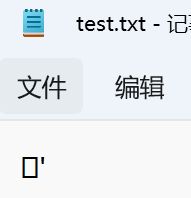
疑惑:可这是乱码,也不是我们要的二进制呀?
图解:
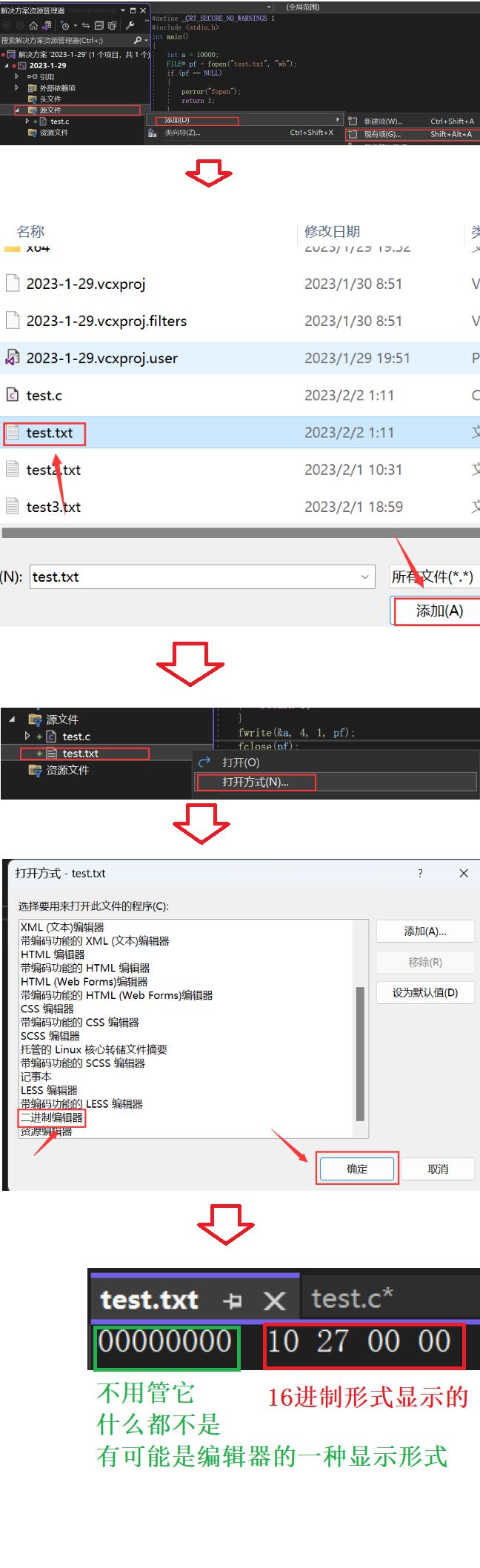
可这结果也不是我们想要的呀?
图解:10000是怎么转换成10 27 00 00的
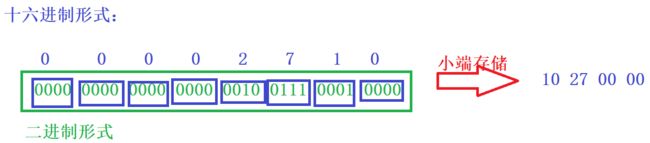
注:
在显示的时候一般都是十六进制的形式显示,很少二进制。因为二进制显示数据会太长
之所以打开二进制文件后10000对应的不是它的二进制形式,而是乱码。是因为记事本只能解读文本文件,无法解读二进制
八、文件读取结束的判定
1.被错误使用的feof (注:file end of file的简写)
牢记:在文件读取过程中,不能用feof函数的返回值直接用来判断文件的读取是否结束。
而是应用于当文件读取结束的时候,判断是读取失败结束,还是遇到文件尾结束。
1. 文本文件读取是否结束,判断返回值是否为 EOF ( fgetc ),或者 NULL ( fgets )
例如:
fgetc 判断是否为 EOF .fgetc()返回ASCII码值
fgets 判断返回值是否为 NULL .fgets()返回字符串地址
2. 二进制文件的读取结束判断,判断返回值是否小于实际要读的个数。
例如:
fread判断返回值是否小于实际要读的个数。fread()返回读到的实际元素个数
size_t fread ( void * ptr, size_t size, size_t count, FILE * stream );
二进制文件的读取结束:size_t对应的返回变量 < count- ferror:判断是不是碰到了异常错误导致读取结束
函数原型:
int ferror ( FILE * stream );函数说明:
1. 判断这个文件结束的原因是不是因为读取的时候碰到了错误。
2. ferror()如果返回真,就说明是因为IO错误结束的(也就是说文件在读取过程中出错了),这是一种外因异常结束。
- feof: 判断是不是碰到了文件结尾而正常读取结束
函数原型:
int feof ( FILE * stream );函数说明:
1. 可以用它去判断一下。
2. feof()如果返回真,就说明文件正常读取,在读取的时候碰到文件结束标志EOF而结束的。
举例:
case 一:正确的使用
#include
#include
int main(void)
{
int c; // 注意:int,非char,要求处理EOF
FILE* fp = fopen("test.txt", "r");//如果读取失败,返回NULL
if(!fp) //NULL的ASCLL码值为0,!NULL即!0,永真的意思
{
perror("File opening failed");
return EXIT_FAILURE;
}
//fgetc 当读取失败的时候或者遇到文件结束的时候,都会返回EOF
while ((c = fgetc(fp)) != EOF) // 标准C I/O读取文件循环-读一个判断一个再打印一个
{
putchar(c);
}
//判断是什么原因结束的
if (ferror(fp))
puts("I/O error when reading");
else if (feof(fp))
puts("End of file reached successfully");
fclose(fp);
} 注:判断顺序
首先文件读取结束了
结束后想知道读取结束的原因:
feof - 返回真,就说明是文件正常读取遇到了结束标志,而结束的
ferror - 返回真,就说明是文件读取过程中出错了,而结束的
case 二:二进制文件的例子
#include
enum { SIZE = 5 };
int main(void)
{
double a[SIZE] = { 1.,2.,3.,4.,5. };
FILE* fp = fopen("test.bin", "wb"); // 必须用二进制模式
fwrite(a, sizeof * a, SIZE, fp); // 写 double 的数组
fclose(fp);
double b[SIZE];
fp = fopen("test.bin", "rb");
size_t ret_code = fread(b, sizeof * b, SIZE, fp); // 读 double 的数组
if (ret_code == SIZE)
{
puts("Array read successfully, contents: ");
for (int n = 0; n < SIZE; ++n) printf("%f ", b[n]);
putchar('\n');
}
else
{ // error handling
if (feof(fp))
printf("Error reading test.bin: unexpected end of file\n");
else if (ferror(fp))
perror("Error reading test.bin");
}
fclose(fp);
} 九、文件缓冲区
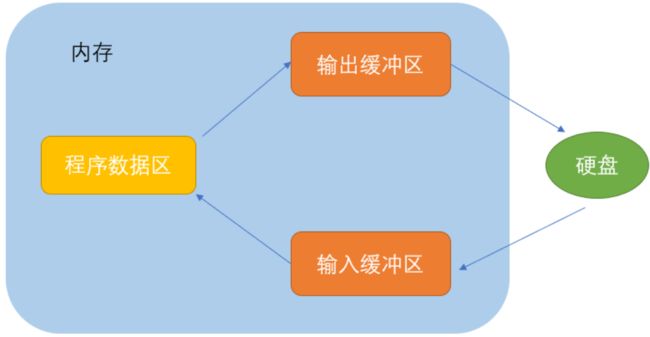
说明:
1. ANSIC标准采用“缓冲文件系统”来处理数据文件。
2. 所谓“缓冲文件系统”,指系统自动地在内存中为程序中正在运行的每一个文件开辟一块“文件缓冲区”。
(文件就是在电脑磁盘里面)
3. 内存数据输出/写到磁盘里面,其会先被送到内存中的输出缓冲区,装满缓冲区后再一次性送到磁盘里面/或者说我主动刷新一下缓冲区里面的数据然后放到硬盘里面去。
(然后假设我缓冲区一直没满,但是我要关闭文件了,这时候没关系,系统会刷新一份缓冲区的数据,这时候不管满没满了,文件都要关闭了,直接把数据放到文件里面去,然后才关闭文件,所以fclose本身关闭文件的时候也会刷新缓冲区的)
4. 如果从磁盘里面往内存输入/读数据,数据也是先放到缓冲区。充满缓冲区后,然后再从缓冲区里面逐个地将数据送到程序数据区(程序变量等)。
5. 缓冲区大小根据C编译系统决定。
6. 缓冲区也是在内存里面的,当然了,摸不着看不到的。
图解:
文件缓冲区存在的意义:
文件缓冲区就是:读写文件时数据传输过程的一个中间环节。那有人就要问了:内存中的数据难道不因该是直接输出到外存上去的吗,为什么中间还需要多一层文件缓冲区?那文件缓冲区存在的目的是什么呀?为什么文件缓冲区需要装满后再输送?
先问大家一个问题:当我们用fwrite()这样的函数写数据时,难道真的光靠它就能将数据直接扔到文件里去了吗? 当然不是,像fwrite()这样的函数是要进行系统调用后才能将数据最终写到文件中去(所谓系统调用就是:由操作系统来代替我们去做一些事情,譬如代替我们写文件之类的)。既然我们在写数据的过程中,会让操作系统调用接口来替我们做一些事情,那么写数据这个操作就必然会打断操作系统。如果频繁的写数据,就譬如4个字节写一次,4个字节写一次,那么操作系统必然会被频繁的打断。操作系统啥事都不用干了,天天来服务你一个就够了!!!这是不现实的。
所以为了不会因为频繁的操作而打断操作系统,我们会在内存中另外开辟一块空间,用于存放需要传输的数据,直到缓冲区被放满,再由操作系统一次性全部输送到硬盘中去。可以这么理解:文件缓冲区在写文件的时候提高整个操作系统的效率,在读文件的时候提高了程序的效率。
证明文件缓冲区的存在:
#include
#include
//VS2013 WIN10环境测试
int main()
{
FILE*pf = fopen("test.txt", "w");
fputs("abcdef", pf);//先将代码放在输出缓冲区
printf("睡眠10秒-已经写数据了,打开test.txt文件,发现文件没有内容\n");
Sleep(10000);//10000毫秒=10秒
printf("刷新缓冲区\n");
fflush(pf);//fflush作用是主动刷新缓冲区,一旦刷新缓冲区,那么缓冲区不必填满,就能将输出缓冲区的数据写到文件(磁盘)
//注:fflush 在高版本的VS上不能使用了
printf("再睡眠10秒-此时,再次打开test.txt文件,文件有内容了\n");
Sleep(10000);
fclose(pf);
//注:fclose在关闭文件的时候,也会刷新缓冲区
pf = NULL;
return 0;
} 运行结果:

这里可以得出一个结论:
因为有缓冲区的存在,C语言在操作文件的时候,需要做刷新缓冲区或者在文件操作结束的时候关闭文
件。作用:把剩下的数据从缓冲区放到硬盘里去
如果不做,可能导致读写文件的问题。因为剩下的数据留在了缓冲区,没有进入目的地硬盘,造成了数据丢失