如何用人工动鼠标的方式打开滑块验证码?
点击关注公众号,技术干货及时送达
有朋友在下方评论:
他问,能否来一篇处理滑块验证码的文章。我回复说,可以一试。
随后,我便搜索网上有没有类似的文章。如果遍地都是,那我也没有必要再添一份冗余。结果发现有类似的。但是,他们大多采用传统的手段:有通过操作网页html元素识别的,有通过OpenCV二值化轮廓识别的,甚至还有遍历像素点去对比RGB点识别的。
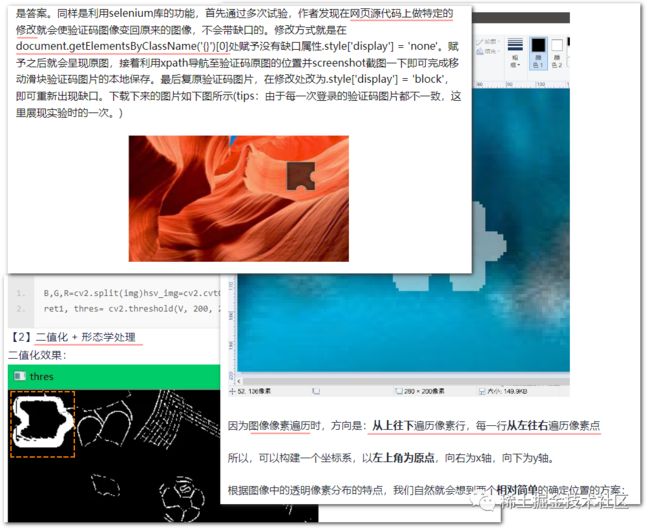
「大家为什么不通过AI视觉处理去识别呢」?传统的识别方式,会受页面缩放、图案颜色、画质清晰度等诸多因素的影响,具有局限性。
因此,我觉得写这么一篇,还是非常有必要的。
❝声明:本文不是破解类文章,不会讲解如何分析或篡改网站的代码。它是模仿最终用户在电脑上的手动操作,这种方式叫「机器人流程自动化」(Robotic Process Automation, RPA)。
❞
RPA不是"外挂",而且差别很大。RPA不去研究程序的成分,没有入侵性,它完全像用户一样去合法操作软件。举个不恰当的例子,就像考试,RPA是找个人替你去考试,外挂或者破解工具则是直接往成绩单里塞入你的名字。
下面我将给大家展示,我是如何利用AI+RPA解决验证码识别这个问题的。学会了它,你可以利用机器人去操作一些固定的流程,从而提高生产效率。
一、实现思路和可行性验证
别看我写到这儿了,其实到目前为止,我也没有把握是否能成功。但是,潜意识里觉得是可以的。因此,想一步,试一步。下面就把我的实践记录公布给大家。
我找来一个滑块验证码的网页。这类网页很多平台都提供,我找的这个是腾讯的。
采用RPA的方式,我们就不去按F12分析元素结构了。我们要和用户一样,按下鼠标拖动它到正确的位置。
这里面需要解决如下几个问题:
1、找到滑块起点与终点的坐标位置。
2、模拟鼠标的按下、拖动、抬起操作。
3、当前状态的判断(什么时机抬鼠标)。
步骤1和步骤3,我有思路,那就是通过图像的目标检测或者分类去实现。因为目标检测的结果中,会包含什么物体在哪个位置。而图片分类,可以给各种状态分类。这两项,假设已经做到了。
继续往下推演。
第2步「模拟鼠标操作」,能实现吗?这对我来说,是一个知识空白。通过百度,我了解到python可以通过pyautogui库,实现模拟鼠标的操作。
先来做一个可行性试验。
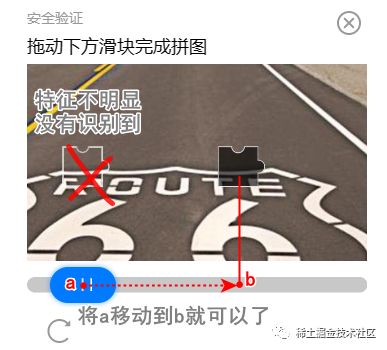
通过聊天软件自带的截图工具,我们可以获取物体的位置坐标(下图POS: (xx, xx)所示)。
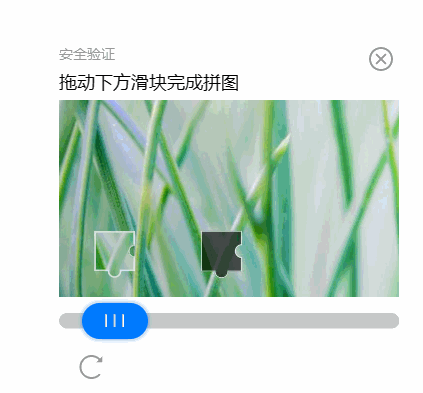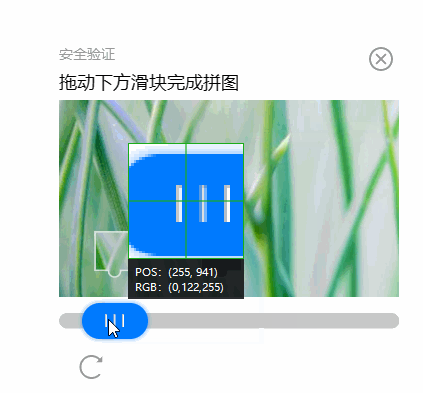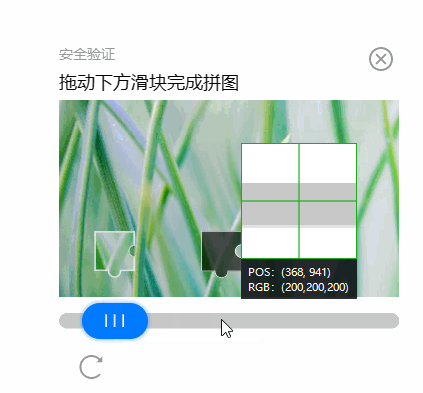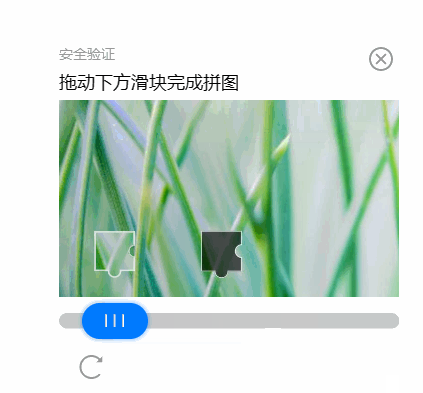
我们通过人工测量的手段,预置已经拿到了滑块的起点和终点,先看看能否通过自动化操作,来通过验证。
我测量的蓝色滑块起点坐标是(260, 940)。从这个位置开始,水平往右拖动,大约X轴到363时,正好补齐。
那整体操作应该就是先将鼠标移动到起点,然后按下鼠标向右拖动363-260=103像素的距离,然后抬起鼠标。
# 首先pip install pyautogui安装库
import pyautogui
# 设置起始位置
start_x = 260
start_y = 940
# 设置拖动距离
drag_distance = 363-260
# 移动到起始位置
pyautogui.moveTo(start_x, start_y, duration=1)
# 按下鼠标左键
pyautogui.mouseDown()
# 拖动鼠标
pyautogui.moveRel(drag_distance, 0, duration=1)
# 松开鼠标左键
pyautogui.mouseUp()看看效果如何。
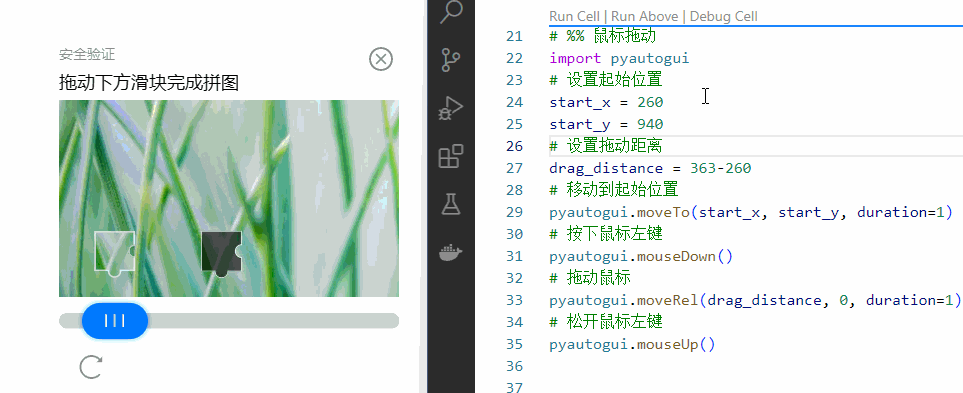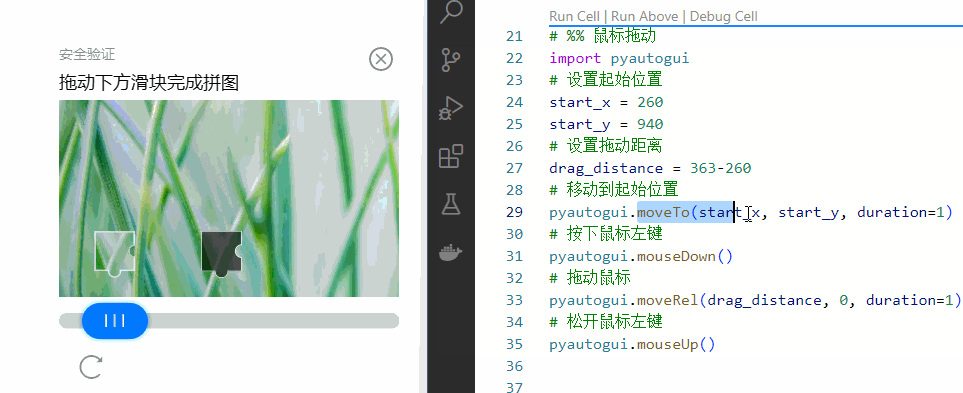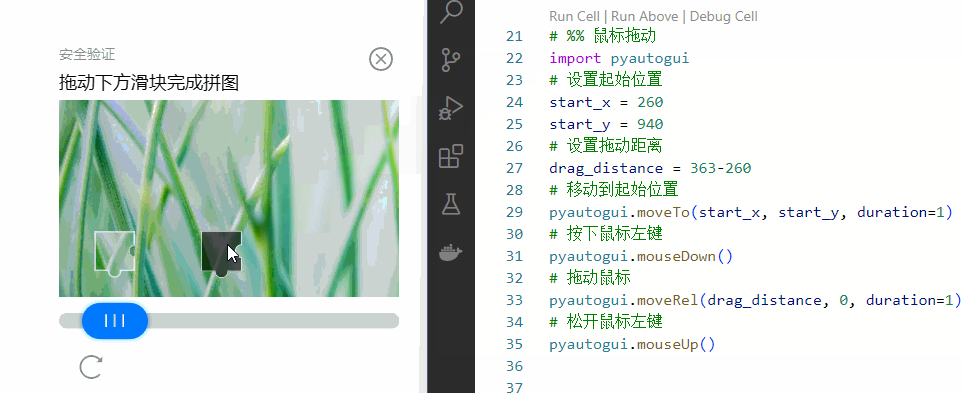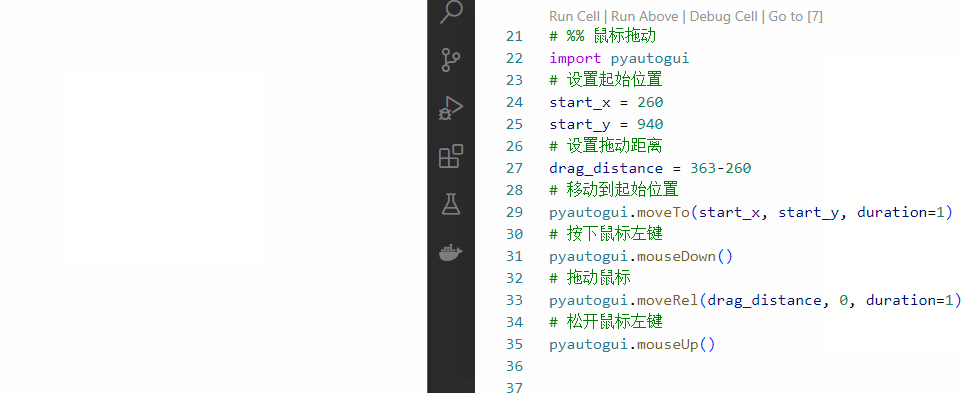
OK!这一步走通了。技术点验证通过,后面我们去处理人工智能识别图像。
二、 训练实施与应用
我们要做哪些目标的检测识别呢?这还是要取决于实现思路。
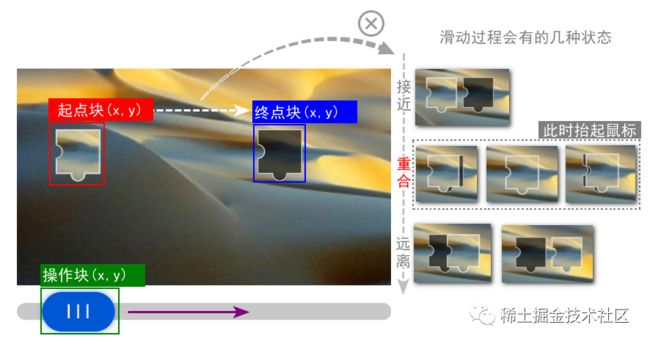
从上图可以看出,起点块、终点块、操作块,我们肯定是要做检测的。我们需要获取它们的坐标信息,从而进一步通过鼠标去操作它们。
除此之外,还有一种状态我们最好也要检测。那就是重合状态。这类状态决定了我们拖动过程中,什么时机松手。可能有人会觉得这一步是多余的。因为通过计算,我们将起点块移动到终点块松手就可以了。这……理论上是这样。但是在实践中,即便你算得很对,如果AI识别的坐标有误差呢?
我们人类是看到图像重合才松手的,所以还是模拟得像一些。关于软件的RPA方案,过度保障才能够更健壮一些。
我们可以设计多种算法来保障操作的准确率:
直接法:当重合特征的数量大于0时(出现一个重合)。
间接法:当图片的终点块数量为0时(被覆盖才出现)。
计算法:操作块和终点块水平方向对齐时(拖到终点位置)。
具体哪种方式最准确,还得结合干扰项、识别准确率。那是后话。
下面,我们就来标记和训练数据。
2.1 标记与训练数据
采用YOLOv8进行标记、训练以及使用的流程,我在上一篇文章介绍过了。那一篇是专门讲这个的,此处我就只讲流程,不讲细节,简单一笔带过。
首先是准备素材。我先截图保存了很多验证码区域的图片,然后用labelImg对截图进行标记。
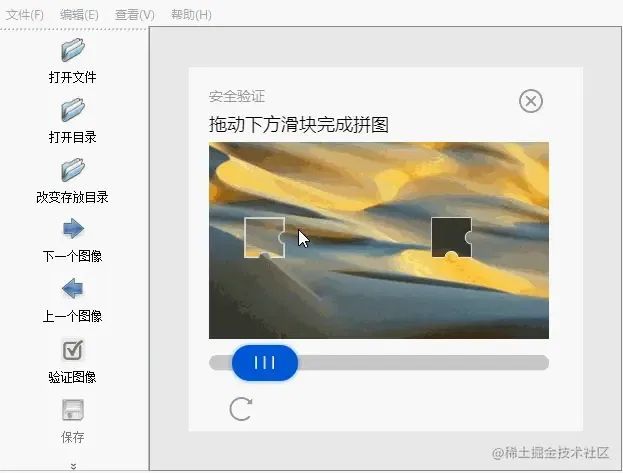
可能大家看到我把刷新按钮又标记上了,这是规划之外的。因为在标记的过程中,我忽然想到,如果某种异常导致识别不到滑动块,我们可以点一下刷新按钮。
大约制作了100多份样本。
然后对样本进行训练。训练100轮后,可获取一份最优的best.pt权重文件。
看看验证集的效果,还不错。

这说明,找到我们关注区域的位置不成问题。
接下来,我们就要开始使用它了。
2.2 分析结果和获取坐标
YOLOv8调用model.predict(……)进行预测后,会返回识别结果。假设我们将结果保存在results中。
通过这个结果results,我们可以拿到有什么物体出现在什么位置。
拿下面这个test.png图片举例子:
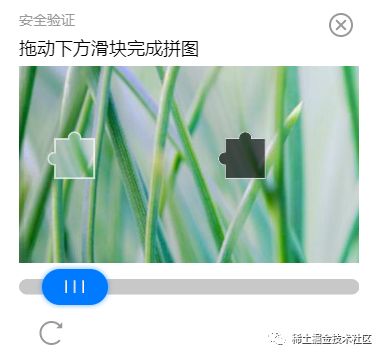
我们用新训练的模型进行检测,代码如下:
from ultralytics import YOLO
from PIL import Image
model = YOLO('best.pt')
image = Image.open("test.png")
results = model.predict(source=image)最终结果如下:
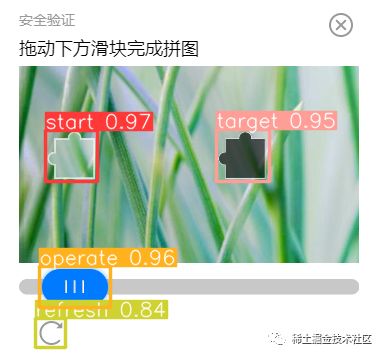
我们来看数据。results是多张图片的合集。results[0]是第一张,我们定义为result。
在result中,有一个result.names,它是所有的分类,打印结果如下:
{0: 'start', 1: 'target', 2: 'fill', 3: 'operate', 4: 'refresh'}result.boxes.data是检测到的目标框的信息,打印出来的话,格式是这样的:
[[ 45.1437, 130.0680, 97.8794, 181.8184, 0.9665, 0.0000],
[ 39.4141, 266.4925, 110.9030, 307.4121, 0.9565, 3.0000],
[216.0383, 129.7685, 269.5766, 181.7017, 0.9546, 1.0000],
[ 35.7875, 318.4604, 65.9167, 347.1984, 0.8392, 4.0000]]这是一个数组。里面有4组数据,每组数里又有6个元素。这4组数据,就是上图中的4个框。
我们拿第一组数据举例,解释下每个数据的含义:
| 索引 | 数值 | 含义 |
|---|---|---|
| 0 | 45.1437 | 矩形框左上角x坐标:x1 |
| 1 | 130.0680 | 矩形框左上角y坐标:y1 |
| 2 | 97.8794 | 矩形框右下角x坐标:x2 |
| 3 | 181.8184 | 矩形框右下角y坐标:y2 |
| 4 | 0.9665 | 识别概率(1为满分):probs |
| 5 | 0.0000 | 识别分类的索引 {0: 'start', 1: 'target' …… |
之所以都是小数(连分类索引也是),这是因为它们是并列关系,里面有一个概率必须为小数。
了解了这些,我们就能看懂上面的识别结果了。它说:
| 物体 | 概率 | 坐标 |
|---|---|---|
| 0-start 起点块 | 96% | (45, 130) (97, 181) |
| 3-operate 操作块 | 95% | (39, 266) (110, 307) |
| 1-target 目标块 | 95% | (216, 129) (269, 181) |
| 4-refresh 刷新按钮 | 83% | (35, 318) (65, 347) |
接下来,我们只需要将鼠标移动到操作块的区域,然后拖动的方向和距离是从起点块到终点块。最后,抬起鼠标。操作就完成了。
大家请注意,虽然上面一直拿着一张图举例。但是,这个人工智能模型对其他大小、颜色、形状的验证码也是起作用的。
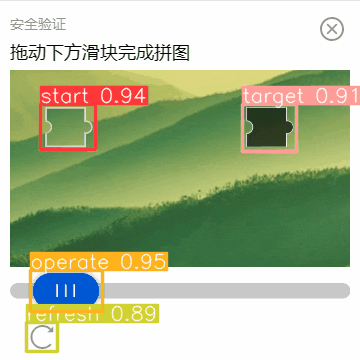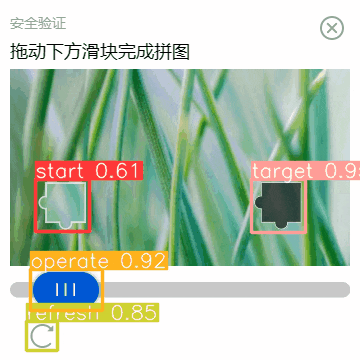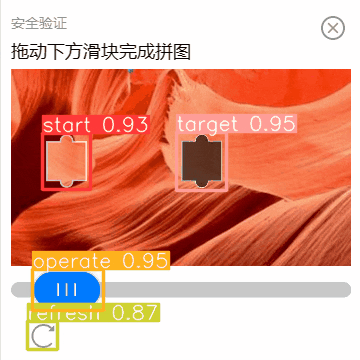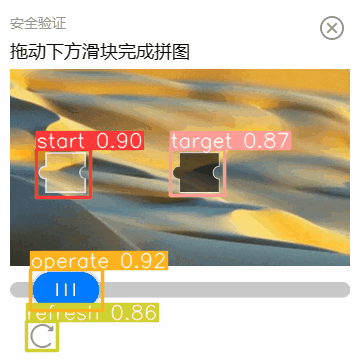
前提是他们得在一个特征体系下。就算方形换成三角形,它也可以正确识别。但是,如果换成将小动物拖到笼子里,那就得再额外训练了。
到目前为止,我们已经有了手(模拟鼠标拖动的pyautogui),也有了大脑(从图片判断目标信息的best.pt)。还差什么呢?
没错!那就是眼睛。
2.3 截取屏幕并移动滑块
在上一个步骤中,测试图片是我们设置的固定图片。但在实际场景中,我们更希望程序自己去屏幕上瞅。我要有手动截屏的功夫,还不如我自己去拖动。
我首先想到的是程序截屏,拿着截屏图片让AI去识别目标物体。
在pyautogui中,截屏很简单,调用pyautogui.screenshot()就可以把当前屏幕拿到。它返回的数据是PIL的Image格式,相当于是Image.open('xx.png'),内容是像素的矩阵数组。
如果我在程序页面运行screenshot,它不就把我的IDE截屏了吗?这时截取下来的是代码界面。因此,我把浏览器页面和代码页面左右并列排放在屏幕上。这样就能拿到包含网页的信息了。然后,再去识别就可以了。
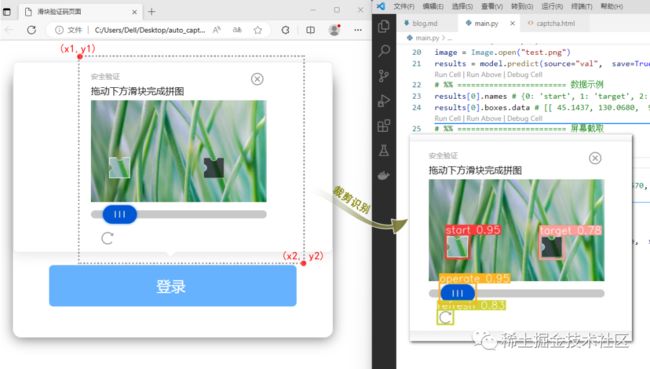
上面的效果实现起来很简单,就是下面这点代码。
import pyautogui
from ultralytics import YOLO
# 截取整个屏幕
screenshot = pyautogui.screenshot()
# 裁剪目标区域
x1,y1,x2,y2 = 140, 110, 570, 510
cropped = screenshot.crop((x1,y1,x2,y2))
# 进行识别
model = YOLO('best.pt')
results = model.predict(source=cropped, save=True)需要解释一下,此处我偷了个懒。正常情况下,所有的操作都得是自动的。大家可能发现,我手动指定了一个(x1, y1)、(x2, y2),这是验证码的区域边框。原因有2点:
第一,我不想将整个屏幕截图全交给AI去识别,这样效率比较低。让程序自动寻找验证码区域,可以做到,其实就是再来一份目标检测。但是,我这个不是商业项目,是技术教程,没必要面面俱到。
第二,针对一款软件而言,它的登录界面的位置相对固定,不会经常变换。对个人用户而言,针对某个场景大体指定一个区域,可以满足日常使用。
如果你要做成商业项目去卖钱,现在的方式是脆弱的。你得让它能自动找到、打开指定的浏览器。其实这些都可以做到。
import pyautogui
# 获取所有窗口的信息
windows = pyautogui.getWindowsWithTitle('Google Chrome')
# 筛选出Chrome浏览器窗口
chrome_window = None
for window in windows:
if 'Google Chrome' in window.title:
chrome_window = window
break
# 检查是否找到了Chrome浏览器窗口
if chrome_window is not None:
# 获取Chrome浏览器窗口的位置和大小
chrome_left = chrome_window.left
chrome_top = chrome_window.top
chrome_width = chrome_window.width
chrome_height = chrome_window.height但是,如果细讲这些,我认为就跑题了。
下面,我们开始尝试拖动它。有结果了,对结果进行分析,找到坐标点,然后执行操作就可以了。
# 识别结果
b_datas = results[0].boxes.data
points = {}
names = {0: 'start', 1: 'target', 2: 'fill', 3: 'operate', 4: 'refresh'}
# 将数据按照{"start":[x1,y1,x2,y2]}的格式重组,方便调用
for box in b_datas:
if box[4] > 0.65: # 概率大于65%才记录
name = names[int(box[5])]
points[name] = np.array(box[:4], np.int32)
# 获取起点块、终点块的距离
start_box = points["start"]
target_box = points["target"]
operate_box = points["operate"]
# 找到起点块的中心
centerx_start = (start_box[0] + start_box[2])//2
# 找到终点块的中心
centerx_target = (target_box[0] + target_box[2])//2
drag_distance = centerx_target - centerx_start
# 找到操作块的中心点
centerx_op = (operate_box[0] + operate_box[2])/2 + x1
centery_op = (operate_box[1] + operate_box[3])/2 + y1
# 移动到操作块中心点
pyautogui.moveTo(centerx_op, centery_op, duration=1)
pyautogui.mouseDown()
# 拖动鼠标
pyautogui.moveRel(drag_distance, 0, duration=1)
pyautogui.mouseUp()代码很简单,也有注释。
着重说一下,centerx_op、centery_op那里需要加上x1、y1。因为识别结果的坐标是相对裁剪图片而言,而pyautogui移动鼠标,是针对整个屏幕坐标系操作的。
下面是运行的效果。
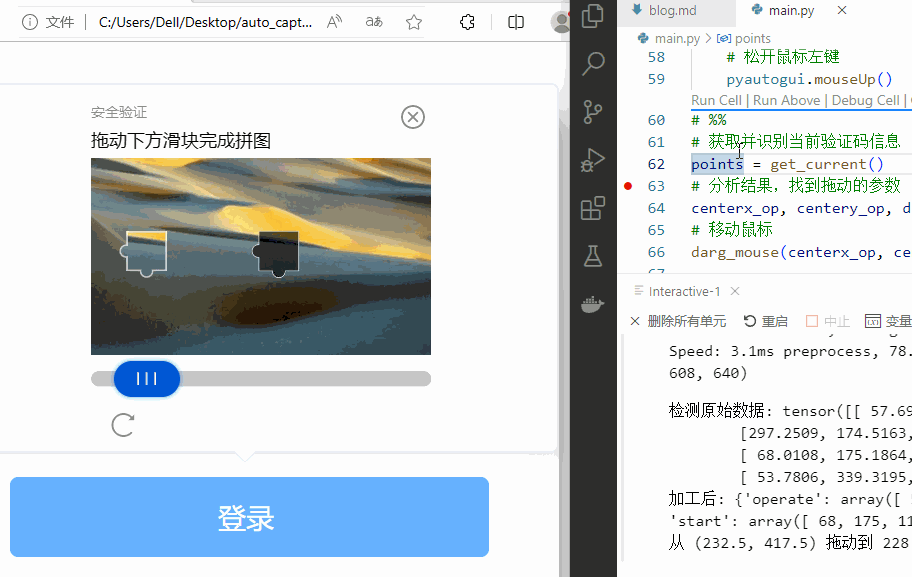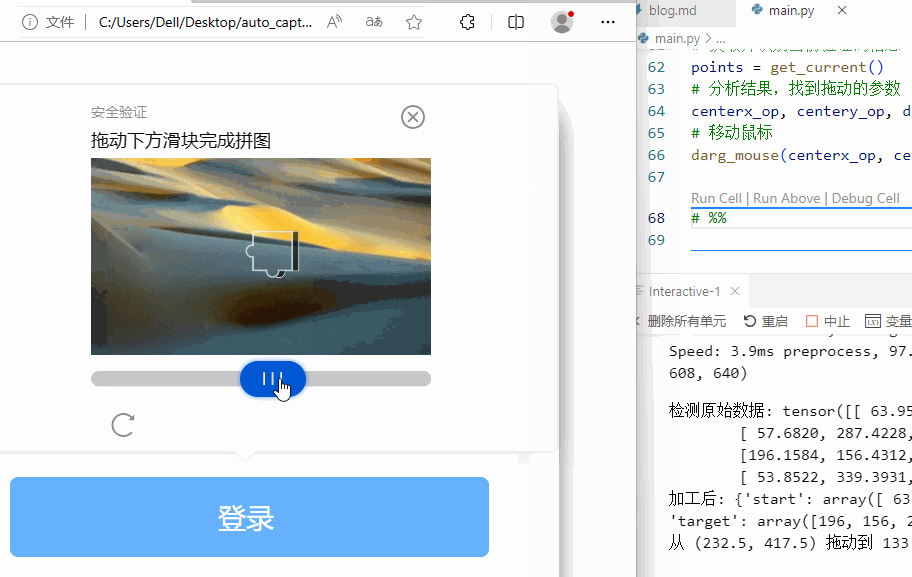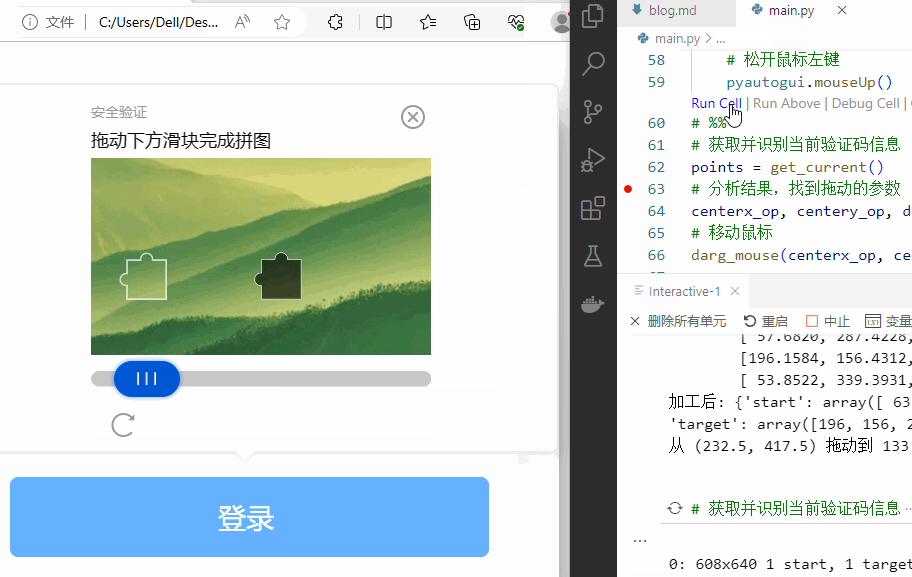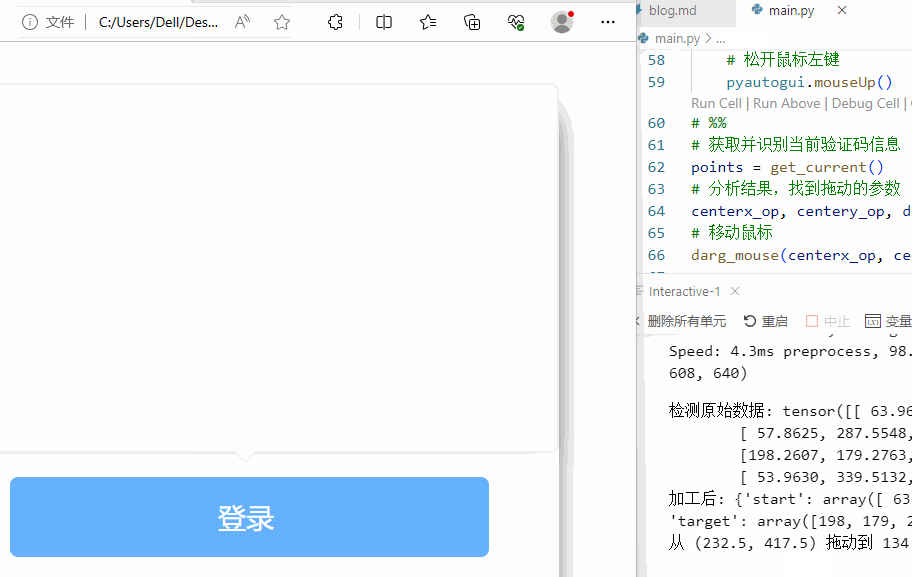
看,可以搞定!
这么复杂的操作都能做到,那么检测输入框,输入文本,点击登录按钮啥的,也不在话下。
2.4 更加健壮的策略
多尝试几次,我便发现了报错。
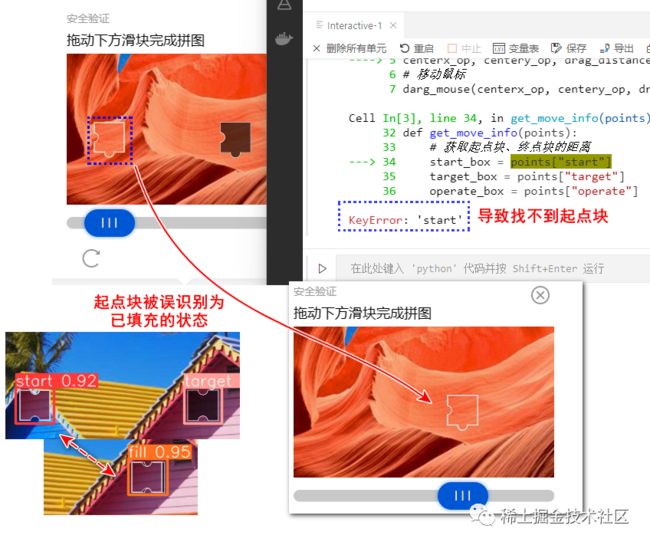
这个报错的原因是没有检测到起点块的信息,我还去取它的数据。之前训练时,我们标记了fill已填充这个状态,这可能会和起点块start弄混。
其实,标记的时候我有考虑过“两者这么类似,它能区分吗?”这导致我寝食难安,犹豫不决。后来我觉得不应该这样为难自己,该为难的应当是算法。另外,这也绝非是强人所难,两者是不一样,start和周围颜色有横断色差,fill和周边像素是融合的。
没想到,现在出现了一个万金油特例,它从空里被挖出来挪到很远的距离后,居然和周围的环境也不违和。
没关系,我们可以处理。这类情况,我们只当没有start,只要将滑块滑动到target的下方就可以了。
代码如下:
……
if "operate" not in points or "target" not in points:
raise ValueError("找不到元素")
# 如果没有起点块,操作块充当起点
if "start" not in points:
start_box = operate_box
else: # 有起点块
start_box = points["start"]
……同时把代码加固了一下,如果找不到必要元素就抛异常,不至于让程序崩溃。
如此一来,它又能正常工作了!
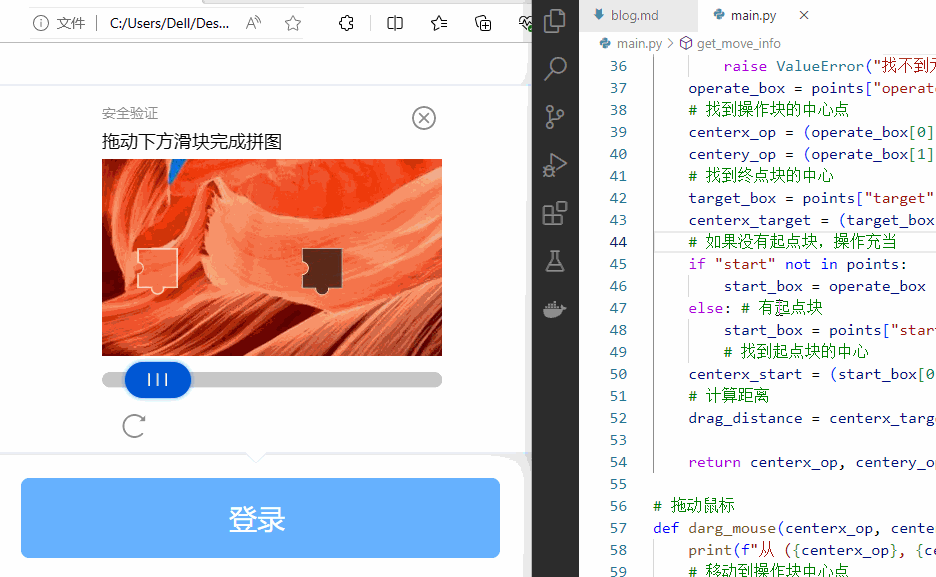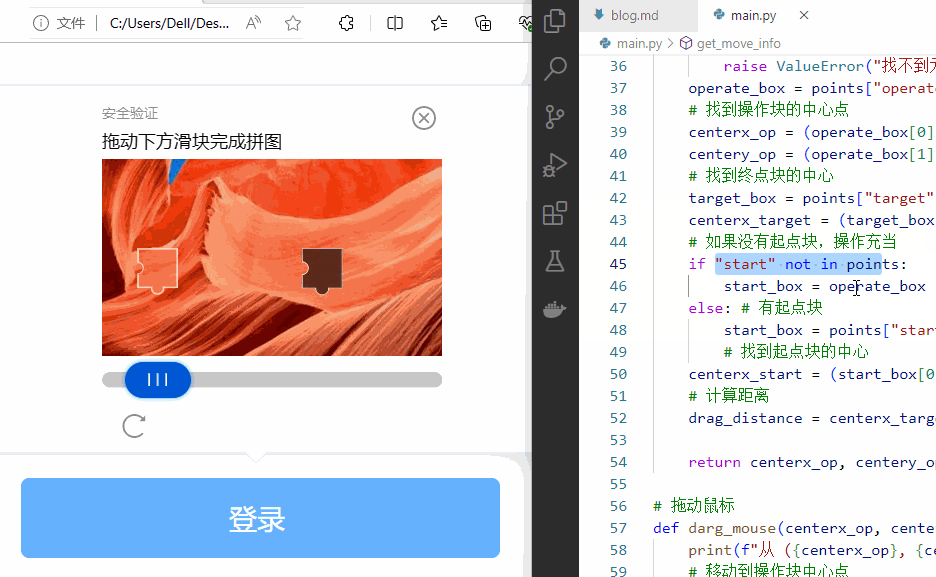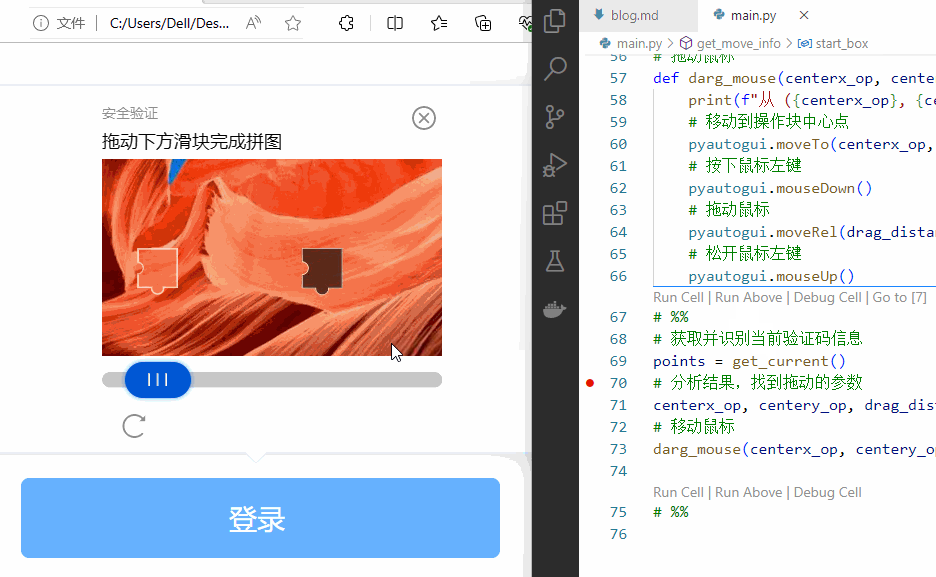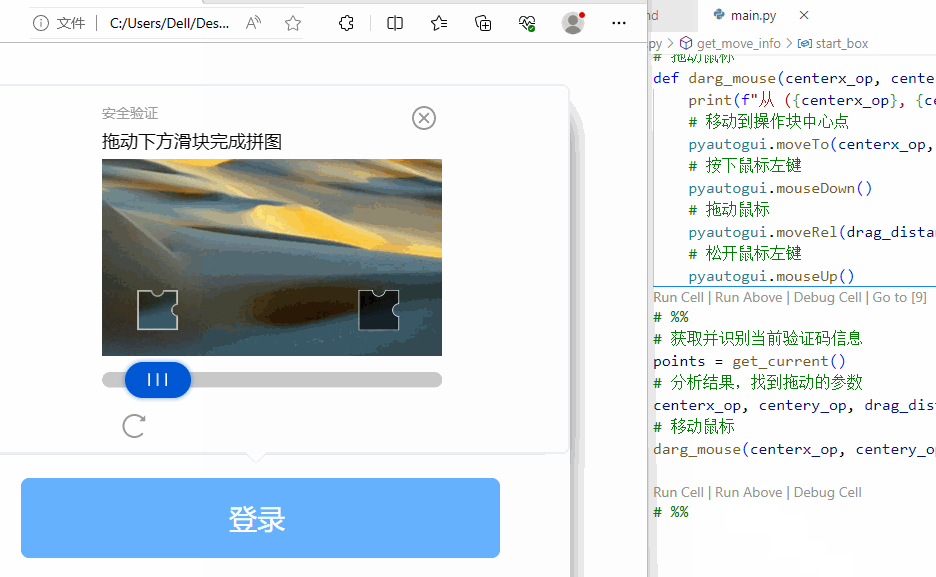
这只是举了一个提高健壮性的例子。实际在使用时,还会遇到更多的异常。都需要挨个处理。
三、小结
我还有很多想法,比如滑到了目的地,先不抬起鼠标,再截屏识别一次,看看是否真的填充上了。如果没有,则左右移动几个像素,再尝试。这样可以确保向人工操作去看齐。
虽然我们用机器极力模仿人工,但是实际上,机器操作和人工操作是有很大区别的。
机器的操作是规整的,这一点人工基本做不到。
如果你仔细观察的话,我们上面的程序控制鼠标移动,它的路径是直线,这一点很难骗人。
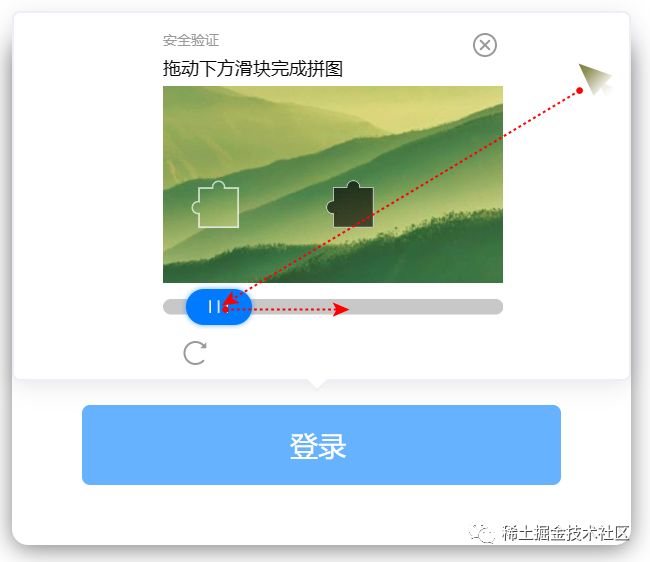
你说,我绕个圈不就行了。可以!但是,让程序实现绕圈是这样的。
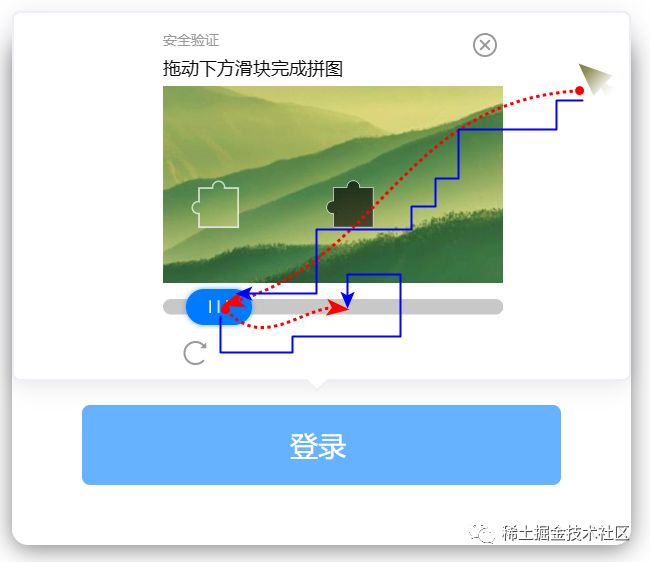
对人类来说,不管是上面的直线、曲线还是折线,我们都很难做到机器那么规整。
换一个角度,人工的方式,机器想要模拟,成本也很高。
下面是我拿着鼠标移动的路线,尽管我极力保持直线,但放大了看,在关键点(点击鼠标)上,还是存在极不规则的路径。
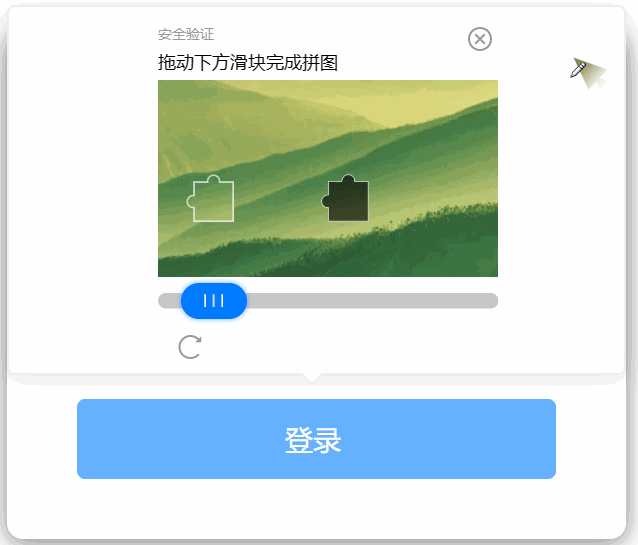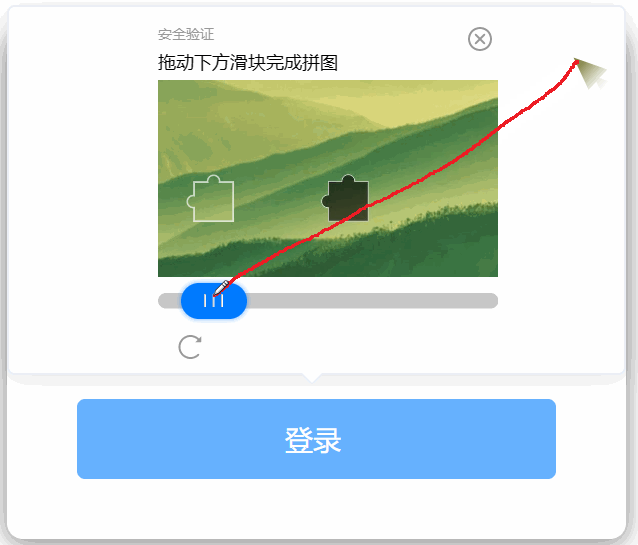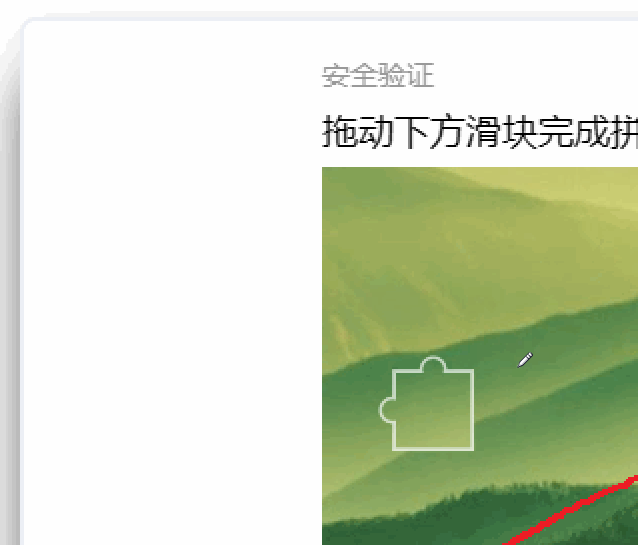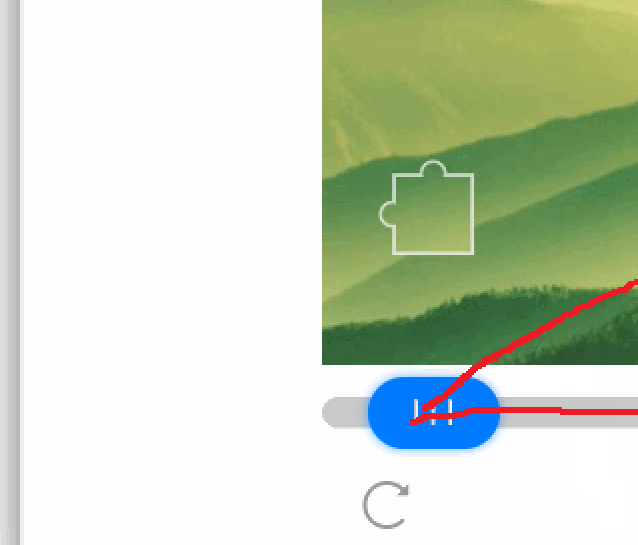
机器想要搞出我这么个路径,它会很累的,因为这就像是笔迹鉴定一样。
这就是为什么,有的验证码让你点一个小圈,就能判断出你是不是机器人。所以啊,想要防机器自动操作,也不是很难。
我想这就是开源软件和商业软件的区别。开源软件仅仅是走通了,说明可行、能用。但是如果你想拿去卖钱,就得下功夫去完善,得让它好用、易用。
AI+RPA我已经在使用了,但仅限于解决自己生活中遇到的问题。我在学习高数时,遇到不会做的题目,有时想搜都不知道该敲些什么字符。那么,通过AI进行识别,然后对接大语言模型,可以直接给出解题思路。
总之,科技发展地很快。有时候换个思路,会有意想不到的收获。它会将很多你认为的不可能,变为可能。
欢迎大家在我的实现思路上去验证、改进、完善。很希望能帮到你,或者仅仅是对你有所启发。
最后献上本项目的GitHub地址:https://github.com/hlwgy/juejin_rpa
如果文章对你有帮助的话欢迎
「关注+点赞+收藏」
❤️ 谢谢支持
以上便是本次分享的全部内容,希望对你有所帮助^_^
喜欢的话别忘了 分享、点赞、收藏 三连哦~。
![]()
从零搭建全栈可视化大屏制作平台V6.Dooring
从零设计可视化大屏搭建引擎
Dooring可视化搭建平台数据源设计剖析
可视化搭建的一些思考和实践
基于Koa + React + TS从零开发全栈文档编辑器(进阶实战
点个在看你最好看