推荐系统(概要+召回)
推荐系统
一、概要
1.基本概念
- 用户行为:点击、点赞、收藏、转发
- 消费指标:点击率 (click rate)、交互率 (engagement rate)
- 北极星指标:用户规模、消费、发布
- 实验流程:离线实验、AB测试、推全
2.推荐系统的链路
- 召回(retrieval):快速从海量数据中取回几千个用户可能感兴趣的物品。
- 粗排:用小规模的模型的神经网络给召回的物品打分,然后做截断,选出分数最高的几百个物品。
- 精排:用大规模神经网络给粗排选中的几百个物品打分,可以做截断,也可以不做截断。
- 重排:对精排结果做多样性抽样,得到几十个物品,然后用规则调整物品的排序。插入广告,推广内容,根据生态要求调整排序。
3.A/B测试
- 分层实验,同层互斥,不同层正交,这样可以同时开很多实验。
- Holdout 机制用于衡量整个部门的业务指标收益。(保留10%的用户,完全不受实验影响,可以考察整个部门对业务指标的贡献)
- 实验推全、反转实验的基本思想。
- 实验推全:新建一个推全层,与其他层正交。
- 反转实验:在新的推全层上,保留一个小的反转桶,使用旧策略。长期观测新旧策略的diff。

二、召回
1.基于物品的协同过滤(Item Based Collaborative Filtering,缩写 ItemCF)
(1)基本思想
- 如果用户喜欢物品item1,而且与item2相似, 那么用户很可能喜欢item2.
(2)预估用户对候选物品的兴趣
∑ j l i k e ( u s e r , i t e m j ) ∗ s i m ( i t e m j , i t e m ) \sum_{j}like(user,item_j) * sim(item_j,item) j∑like(user,itemj)∗sim(itemj,item)

(3)相似度计算(余弦相似度)
- 把每个物品表示为一个稀疏向量,向量每个元素对应一个用户
- 相似度sim就是两个向量夹角的余弦
- 喜欢物品 i 1 i_1 i1的用户记作集合 W 1 W_1 W1
- 喜欢物品 i 2 i_2 i2的用户记作集合 W 2 W_2 W2
- 定义交集 V = W 1 ∩ W 2 V = W_1\cap W_2 V=W1∩W2
两个物品相似度(不考虑喜欢的程度 l i k e ( u s e r , i t e m ) like(user,item) like(user,item)
s i m ( i 1 , i 2 ) = ∣ V ∣ ∣ W 1 ∣ ⋅ ∣ W 2 ∣ sim(i_1, i_2)= \frac{\left|V \right|}{\sqrt{\left|W_1 \right| \cdot \left|W_2 \right|}} sim(i1,i2)=∣W1∣⋅∣W2∣∣V∣
考虑喜欢的程度
s i m ( i 1 , i 2 ) = ∑ v ∈ V l i k e ( v , i 1 ) ⋅ l i k e ( v , i 2 ) ∑ u 1 ∈ W 1 l i k e 2 ( u 1 , i 1 ) ⋅ ∑ u 2 ∈ W 2 l i k e 2 ( u 2 , i 2 ) sim(i_1, i_2)= \frac{\sum_{v \in V}like(v,i_1) \cdot like(v,i_2)}{\sqrt{\sum_{u_1 \in W_1}like^2(u_1,i_1)} \cdot \sqrt{\sum_{u_2 \in W_2}like^2(u_2,i_2)}} sim(i1,i2)=∑u1∈W1like2(u1,i1)⋅∑u2∈W2like2(u2,i2)∑v∈Vlike(v,i1)⋅like(v,i2)
(4) 维护两个索引
- ⽤户->物品列表:⽤户最近交互过的 n个物品。
- 物品->物品列表:相似度最⾼的 k个物品
(5)线上做召回
- 利用两个索引,每次取回nk个物品
- 预估用户对每个物品的兴趣分数: ∑ j l i k e ( u s e r , i t e m j ) ∗ s i m ( i t e m j , i t e m ) \sum_j like(user, item_j) * sim(item_j, item) ∑jlike(user,itemj)∗sim(itemj,item)
2.Swing模型
- 额外考虑重合用户是否来自一个小圈子
- ItemCF和Swing的唯一区别在于物品相似度
- 同时喜欢两个物品的用户记作集合V
- 对于V的用户 u 1 和 u 2 u_1和u_2 u1和u2,重合度记作 o v e r l a p ( u 1 , u 2 ) overlap(u_1, u_2) overlap(u1,u2)
- 两个用户重合度大,则可能来自一个小圈子,权重降低
s i m ( i 1 , i 2 ) = ∑ u 1 ∈ V ∑ u 2 ∈ V 1 α + o v e r l a p ( u 1 , u 2 ) sim(i_1, i_2)= \sum_{u_1 \in V} \sum_{u_2 \in V} \frac{1}{\alpha + overlap(u_1,u_2)} sim(i1,i2)=u1∈V∑u2∈V∑α+overlap(u1,u2)1
( α \alpha α是人工设置的参数)
3.基于用户的协同过滤(UserCF)
推荐系统如何找到兴趣相似的网友?
- 点击、点赞、收藏、转发的笔记有很大重合
- 关注的作者有很大的重合
(1)基本思想
- 如果用户user1和user2 相似,而且user2喜欢某物品
- 那么用户user1也很可能 喜欢该物品
(2) 用户相似度计算
- 把每个用户表示为一个稀疏向量,向量每个元素对应一个物品
- 相似度sim就是两个向量夹角的余弦
- 用户 u 1 u_1 u1喜欢的物品记作集合 J 1 J_1 J1
- 用户 u 2 u_2 u2喜欢的物品记作集合 J 2 J_2 J2
- 定义交集 I = J 1 ∩ J 2 I =J_1 \cap J_2 I=J1∩J2
s i m ( u 1 , u 2 ) = ∣ I ∣ ∣ J 1 ∣ ⋅ ∣ J 2 ∣ sim(u_1, u_2) = \frac{\left| I\right|}{\sqrt{\left|J_1 \right| \cdot \left|J_2 \right|}} sim(u1,u2)=∣J1∣⋅∣J2∣∣I∣
降低热门物品权重
- 不论冷门热门权重都是1
s i m ( u 1 , u 2 ) = ∑ l ∈ I l ∣ J 1 ∣ ⋅ ∣ J 2 ∣ sim(u_1, u_2) = \frac{\sum_{l\in I}l}{\sqrt{\left|J_1 \right| \cdot \left|J_2 \right|}} sim(u1,u2)=∣J1∣⋅∣J2∣∑l∈Il
- n l n_l nl喜欢物品l的用户数量,反映物品的热门程度
s i m ( u 1 , u 2 ) = ∑ l ∈ I 1 l o g ( 1 + n l ) ∣ J 1 ∣ ⋅ ∣ J 2 ∣ sim(u_1, u_2) = \frac{\sum_{l\in I}{\frac{1}{log(1 + n_l)}}}{\sqrt{\left|J_1 \right| \cdot \left|J_2 \right|}} sim(u1,u2)=∣J1∣⋅∣J2∣∑l∈Ilog(1+nl)1
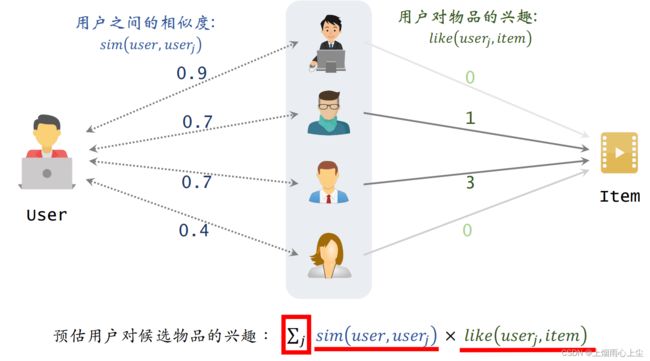

(3)预估用户user对候选物品item的兴趣
∑ j s i m ( u s e r , u s e r j ) ∗ l i k e ( u s e r j , i t e m ) \sum_{j}sim(user,user_j) * like(user_j,item) j∑sim(user,userj)∗like(userj,item)
4.离散特征处理
(1)建立字典:把类别映射成序号
例:
中国 ->1
美国->2
印度->3
(2)向量化:把序号映射成向量
- One-hot编码:把序号映射成高维洗漱向量
例:
两百个国家,每个国家映射出200维的向量,序号对应位置元素是1,其他位置对应元素为0
类别太大时不用One-hot编码
- Embedding:把序号映射成低维稠密向量
- 参数以矩阵形式保存
- 输入是序号
- 输出是向量, 如:美国对应参数矩阵第二列
例:
每个国家映射成八维 稠密向量
参数数量=向量维度 ∗ * ∗类别数量
5.矩阵补充
(1)矩阵补充
- 把物品ID、⽤户ID做 embedding,映射成向量
- 两个向量的內积 < a u , b i >
- 让 < a u , b i >
- 矩阵补充模型有很多缺点,效果不好
- 仅⽤ID embedding,没利⽤物品(类⽬、关键词、地理位置、作者信息)、⽤户属性(性别、年龄、地理定位、感兴趣的类⽬)
- 负样本的选取⽅式(曝光之后,没有点击、交互)不对
- 做训练的⽅法不好
- 内积不如余弦相似度
- 平方损失不如交叉熵损失

(2) 线上召回
- 把⽤户向量 a 作为 query,查找使得 < a u , b i >
- 暴⼒枚举速度太慢。实践中⽤近似最近邻查找。
- Milvus、Faiss、HnswLib 等向量数据库⽀持近似 最近邻查找
6.双塔模型
(1) 模型结构
- 用户塔、物品塔个输出一个向量
- 两个向量的余弦相似度作为兴趣的预估值
(2) 三种训练方式
- Pointwise: 每次用一个用户、一个物品(可正可负)
- Pairwise:每次用一个用户,一个正样本,一个负样本
- Listwise:每次用一个用户,一个正样本,多个负样本
(3)正负样本
- 正样本: 曝光⽽且有点击。
- 简单负样本:
- 全体物品。
- batch内负样本。
- 困难负样本:被召回,但是被排序淘汰。
- 错误:曝光、但是未点击的物品做召回的 负样本
(4) 双塔模型的召回
- 离线存储:把物品向量b存入向量数据库
- 1.完成训练后,用物品塔计算每个物品的特征向量b。
- 2.把几亿个物品向量b存入向量数据库
- 3.向量数据库建索引,以便加速最近临查找
- 线上召回:查找用户最感兴趣的k个物品
- 1.给定⽤户ID和画像,线上⽤神经⽹络算⽤户向量 a。
- 2.最近邻查找:
- 把向量 a 作为 query,调⽤向量数据库做最近邻查找。
- 返回余弦相似度最⼤的 k 个物品,作为召回结果
(5)模型更新
- 全量更新:今天凌晨,⽤昨天全天的数据训练模型。
- 在昨天模型参数的基础上做训练。(不是随机初始化)
- ⽤昨天的数据,训练 1 epoch,即每天数据只⽤⼀遍。
- 发布新的⽤户塔神经⽹络和物品向量,供线上召回使⽤。
- 全量更新对数据流、系统的要求⽐较低。
- 增量更新:做 online learning 更新模型参数。
- ⽤户兴趣会随时发⽣变化。
- 实时收集线上数据,做流式处理,⽣成 TFRecord ⽂件。
- 对模型做 online learning,增量更新 ID Embedding 参数。 (不更新神经⽹络其他部分的参数。)
- 发布⽤户 ID Embedding,供⽤户塔在线上计算⽤户向 量
- 实际的系统
- 全量更新 & 增量更新 相结合。
- 每隔 ⼏⼗分钟,发布最新的⽤户 ID Embedding,供⽤户 塔在线上计算⽤户向量
(6)自监督学习
- 双塔模型存在的问题
- 推荐系统头部效应严重:
- 少部分物品占据大部分点击
- 大部分物品的点击次数不高
- 高点击物品的表征学得好,长尾物品的表征学得不好
- 自监督学习:做data augmentation,更好地学习长尾物品的向量表征
- 推荐系统头部效应严重:
- 双塔模型


- 自监督学习

目的
-
物品 i 的两个向量表征 b i ′ b_i^{'} bi′ 和 b i ′ ′ b_i^{''} bi′′ 有较⾼的相似度。
-
物品 i和 j 的向量表征 b i ′ b_i^{'} bi′ 和 b j ′ ′ b_j^{''} bj′′有较低的相似度
-
鼓励 c o s ( b i ′ , b i ′ ′ ) cos(b_i^{'} ,b_i^{''}) cos(bi′,bi′′)尽量大, c o s ( b i ′ , b j ′ ′ ) cos(b_i^{'} ,b_j^{''}) cos(bi′,bj′′)尽量大。
特征变换
-
Random Mask
- 随机选⼀些离散特征(⽐如类⽬),把它们遮住
- 例:
- 某物品的类⽬特征是 u = {数码,摄影} 。
- Mask 后的类⽬特征是 u ′ u^{'} u′= {default }(默认的缺失值)
-
Dropout(仅对多值离散特征⽣效)
- ⼀个物品可以有多个类⽬,那么类⽬是⼀个多值离散特征。
- Dropout:随机丢弃特征中 50% 的值。
- 例:
- 某物品的类⽬特征是 u = {美妆,摄影} 。
- Dropout 后的类⽬特征是 u ′ u^{'} u′= {美妆} 。
-
互补特征(complementary)
-
假设物品⼀共有 4 种特征: ID,类⽬,关键词,城市
-
随机分成两组: {ID,关键词} 和 {类⽬,城市}
-
{ID, default,关键词,default}->物品特征
-
{default,类目,default,城市}->物品特征
-
鼓励两个物品特征向量相似
-
Mask一组关联特征(随机遮住一组关联特征)
- 离线计算特征两两之间的关联,⽤互信息(mutual information)衡量
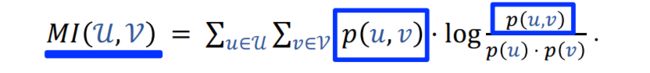
-
设⼀共有 k 种特征。离线计算特征两两之间 MI, 得到 k×k 的矩阵。
-
随机选⼀个特征作为种⼦,找到种⼦最相关的 k/2 种特征。
-
Mask 种⼦及其相关的 k/2 种特征,保留其余的 k/2 种特征
-
好处:⽐ random mask、dropout、互补特征等⽅法 效果更好。
坏处:⽅法复杂,实现的难度⼤,不容易维护
训练模型

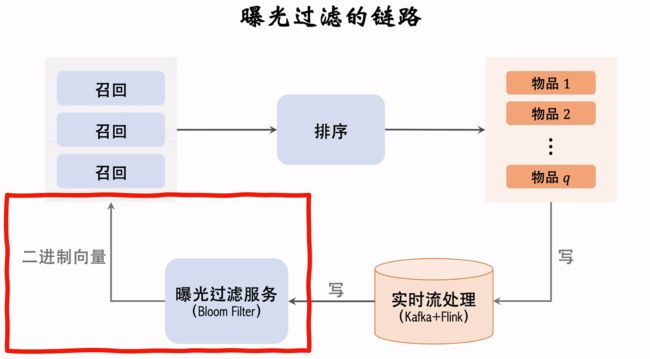
7.曝光过滤&Bloom Filter
(1)曝光过滤问题
- 如果用户看过某个作品,则不再把该作品曝光给用户
- 对于每个用户,记录已经曝光给他的物品
- 对于每个召回的物品,判断他是否已经给该用户曝光过,排除掉曾经曝光过的物品
- 一位用户看过n个物品,本次召回r个物品,如果暴力对比,需要O(nr)的时间
(2)Bloom Filter