LeetCode 无重复字符的最长子串 打败100%的人
前言
LeetCode上的“无重复字符的最长子串”问题要求我们找到给定字符串中不包含重复字符的最长子串的长度。这个问题是一个典型的滑动窗口技巧的应用,需要有效地处理字符出现的情况来找到解决方案。
.
在本解决方案中,我们将探讨两种不同的算法实现来解决这个问题。首先,我们将使用基本方法来解决问题,然后进一步优化以获得更好的时间复杂度。
个人主页:尘觉主页
个人简介:大家好,我是尘觉,希望我的文章可以帮助到大家,您的满意是我的动力
在csdn获奖荣誉: csdn城市之星2名
Java全栈群星计划top前5
端午大礼包获得者
阿里云专家博主
亚马逊DyamoDB结营
欢迎大家:这里是CSDN,我总结知识的地方,欢迎来到我的博客,感谢大家的观看
如果文章有什么需要改进的地方还请大佬不吝赐教 先在次感谢啦
文章目录
- LeetCode 无重复字符的最长子串 打败100%的人
-
- 无重复字符的最长子串
-
- 力扣官方题解
-
- 方法一:滑动窗口
- 思路和算法
- 优秀思路
-
- 自己思路
-
- 重点
- 总结
- 再优化一下
-
- 总结
- 总结
-
- 基本实现:
- 优化实现:
LeetCode 无重复字符的最长子串 打败100%的人
无重复字符的最长子串

力扣官方题解
方法一:滑动窗口
思路和算法
我们先用一个例子考虑如何在较优的时间复杂度内通过本题。
我们不妨以示例一中的字符串 abcabcbb为例,找出从每一个字符开始的,不包含重复字符的最长子串,那么其中最长的那个字符串即为答案。对于示例一中的字符串,我们列举出这些结果,其中括号中表示选中的字符以及最长的字符串:

发现了什么?如果我们依次递增地枚举子串的起始位置,那么子串的结束位置也是递增的!这里的原因在于,假设我们选择字符串中的第 k 个字符作为起始位置,
并且得到了不包含重复字符的最长子串的结束位置为 rk 。那么当我们选择第 k+1k+1 个字符作为起始位置时,首先从 k+1到 rk的字符显然是不重复的,并且由于少了原本的第 k 个字符,我们可以尝试继续增大 rk ,直到右侧出现了重复字符为止。
这样一来,我们就可以使用「滑动窗口」来解决这个问题了:
-
我们使用两个指针表示字符串中的某个子串(或窗口)的左右边界,其中左指针代表着上文中「枚举子串的起始位置」,而右指针即为上文中的 rk ;
-
在每一步的操作中,我们会将左指针向右移动一格,表示 我们开始枚举下一个字符作为起始位置,然后我们可以不断地向右移动右指针,但需要保证这两个指针对应的子串中没有重复的字符。在移动结束后,这个子串就对应着 以左指针开始的,不包含重复字符的最长子串。我们记录下这个子串的长度;
-
在枚举结束后,我们找到的最长的子串的长度即为答案。
判断重复字符
在上面的流程中,我们还需要使用一种数据结构来判断 是否有重复的字符,常用的数据结构为哈希集合
在左指针向右移动的时候,我们从哈希集合中移除一个字符,在右指针向右移动的时候,我们往哈希集合中添加一个字符。
public int lengthOfLongestSubstring(String s) {
// 哈希集合,记录每个字符是否出现过
Set<Character> occ = new HashSet<Character>();
int n = s.length();
// 右指针,初始值为 -1,相当于我们在字符串的左边界的左侧,还没有开始移动
int rk = -1, ans = 0;
for (int i = 0; i < n; ++i) {
if (i != 0) {
// 左指针向右移动一格,移除一个字符
occ.remove(s.charAt(i - 1));
}
while (rk + 1 < n && !occ.contains(s.charAt(rk + 1))) {
// 不断地移动右指针
occ.add(s.charAt(rk + 1));
++rk;
}
// 第 i 到 rk 个字符是一个极长的无重复字符子串
ans = Math.max(ans, rk - i + 1);
}
return ans;
}
优秀思路
这个打败100%
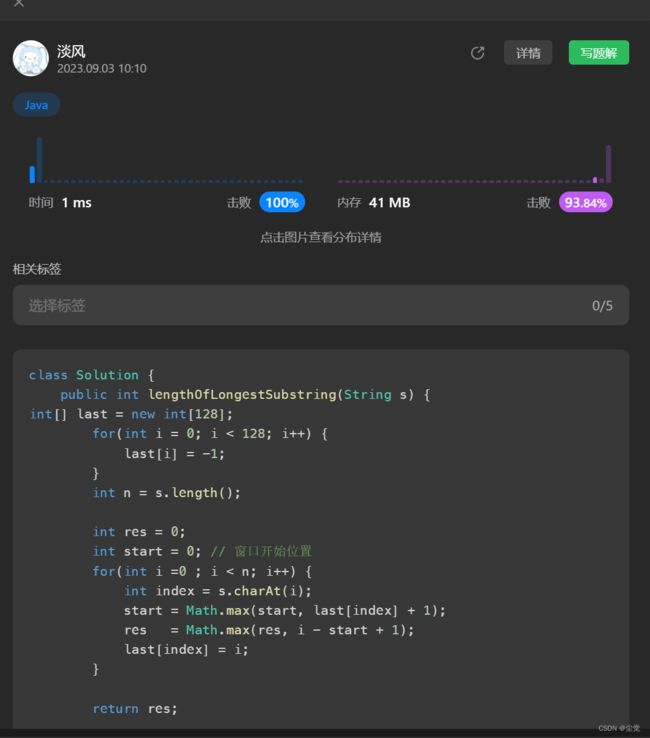
自己思路
首先因为字母表最大ASCLL为128所以我们就初始化128个空间并且假设全部没有出现为0,但是在数组中我们是0开头的所以什么设置为-1
其次我们设置 长度0 最大个数0 开始位置0
重点
我们开始循环 aabcd
i 代表我们是到那个字符了
首先我们读取每个字符的ASCLL值 赋值到index
然后我们开始计算 起始位置 如果这个字符出现过我们就更新起始实位置 last[index]上一次出现的位置 +1是 代表字符串内字符不能重复,所以要从上一次出现位置的下一个位置开始
如aabcd 第一个a 出现过一次 所以在 last[index] 的位置为 0 因为出现过一次了所以我们就从 第二个a 开始 就是 last[index]+1 以此类推
再是 我们比较 最大子串和 当前位置 i - 开始位置看谁最长 注意这个加1是代表次数 因为我们是从0开始 但是计数是从1开始 所以要+1
最后 我们记录这个字符在这个字符串中的位置 注意这个是字符串的位置是从0开始的
总结
要注意 计数 和在字符串 的位置 一个是从0 开始 一个是从 1开始 这就是为什么需要i - start + 1需要+1的原因
public int lengthOfLongestSubstring(String s) {
// 记录字符上一次出现的位置
int[] last = new int[128];
for(int i = 0; i < 128; i++) {
last[i] = -1;
}
int n = s.length();
int res = 0;
int start = 0; // 窗口开始位置
for(int i =0 ; i < n; i++) {
int index = s.charAt(i);
start = Math.max(start, last[index] + 1);
res = Math.max(res, i - start + 1);
last[index] = i;
}
return res;
}
再优化一下
大体逻辑是差不多的这里注意说一下区别
这里没有赋值是利用了java在初始化数组的时候是默认分配0
last[index] = i+1; 代表着这个字符出现的位置 比如 aabcd 第一个a 它的位置是 i+1=1次 到第二个a的时候就是 i=1
所以 start = Math.max(start, last[index])直接是从1开始 然后重新记录a的位置是 i+1=2 以此类推
注意这个是从 1开始的 不是0 包括后面 res也是从1开始 不是0
总结
要注意区分 统计 和 数组位置 以及 从1开始的位置
// 记录字符上一次出现的位置
int[] last = new int[128];
// for(int i = 0; i < 128; i++) {
// last[i] = -1;
// }
int n = s.length();
int res = 0;
int start = 0; // 窗口开始位置
for(int i = 0; i < n; i++) {
int index = s.charAt(i);
start = Math.max(start, last[index]);
res = Math.max(res, i + 1 - start );
last[index] = i+1;
}
return res;
总结
基本实现:
-
初始化大小为128的数组last(表示ASCII字符)来跟踪每个字符上次出现的索引位置。将last中的所有元素初始化为-1,表示尚未见过任何字符。
-
从左到右遍历输入字符串s。
-
对于s中索引为i的字符,计算其ASCII值并将其存储在index变量中。
-
更新start变量,使其成为当前值和last[index] + 1中的较大者。这一步确保start表示当前不包含重复字符的子串的起始位置。
-
更新res变量,使其成为当前值和i + 1 - start中的较大者。这一计算找到了当前不包含重复字符的子串的长度,并与先前的最大长度进行比较。
-
更新last[index]为i + 1,记录字符在字符串中的最近位置。
-
重复步骤3-6,直到处理完整个字符串。
-
最终的res值将表示输入字符串s中不包含重复字符的最长子串的长度。
优化实现:
-
优化版本的解决方案消除了不必要的last数组初始化,并相应地调整了计算。还利用了Java默认使用零初始化数组的特性。
-
通过进行这些优化,代码变得更加简洁,并且在内存使用和代码简洁性方面都得到了改善。
-
这两种实现都提供了正确的答案,但优化版本在内存使用和代码简洁性方面都具有更高的效率。
这些实现为解决LeetCode上的“无重复字符的最长子串”问题提供了清晰而高效的方法,展示了滑动窗口技巧和字符出现情况跟踪的应用。
热门专栏推荐
想学习vue的可以看看这个
java基础合集
数据库合集
redis合集
nginx合集
linux合集
手写机制
微服务组件
spring
springMVC
mybits
等等等还有许多优秀的合集在主页等着大家的光顾感谢大家的支持
欢迎大家加入我的社区 尘觉社区
文章到这里就结束了,如果有什么疑问的地方请指出,诸佬们一起来评论区一起讨论
希望能和诸佬们一起努力,今后我们一起观看感谢您的阅读
如果帮助到您不妨3连支持一下,创造不易您们的支持是我的动力