当大模型不是问题时,如何应对 LLM 的工程化落地挑战?
几个月前,在 Thoughtworks 的内部 AIGC 研讨会里,我们一直达成了一系列一致观点,诸如于:如果没有 “开源模型” 降低企业应用 LLM 的成本,那么 LLM 会很快消亡。所以,我们相信开源 LLM + LoRA 微调会成为企业的一种主流方式。现今,我们可以看到 LLaMA 2、Code LLaMA 2 等模型在不断刷新这种可能性。
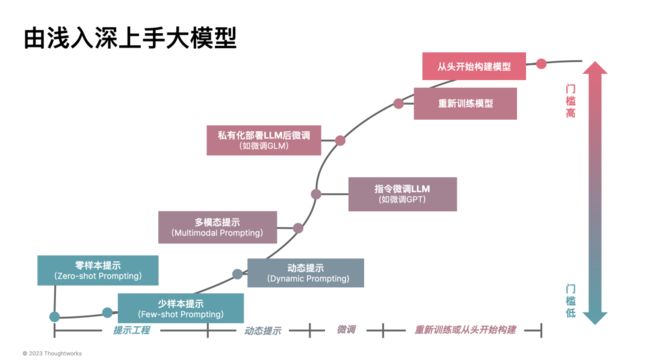
而在模型不是问题之后,作为架构师、开发人员,我们应该致力于:将 LLM 以工程化的方式落地。于是,在过去的几个月里,我们开发了一系列不同领域的 LLM 应用 PoC,尝试从不同的角度思考如何构建好 LLM 应用。诸如于:
语言与生态的角度,探索优化语言间的交互?
技术架构应该如何设计?
Prompt 建模与优化?
有哪些模式构建更好的模型上下文?
语言 API 应该包含那些内容?
其它的一些问题,还包含如何通过小模型、传统 LLM 降低大模型花费?每个问题都是一个比较有意思的问题,也是我们在落地时要考虑的。
语言与生态的角度:LLM Service as a API vs FFI
已经有大量的企业尝试使用 Python + LangChain 去构建知识增强工具的 PoC。从工程的角度意味着,我们需要考虑:
是否使用智能服务都选用 Python,对外提供 API?
在现有的语言、基础设施中,寻找可能的代码方案?
而因为 Python 的动态特性,影响了 IDE 的智能分析,进而影响了开发效率 —— 哪怕是有了 Pydantic 这样的类型库。于是 ,我对于语言的第一个考虑是:与企业现有基础设施相结合。特别是,我现有的各种库、框架使用的都是 JVM 语言编写。
语言的 AI 基础设施

于是乎,我们使用 Java/Kotlin、TypeScript、Rust 语言开发了不同类型、不同场景下的应用,以查看不同语言是否能构建起 LLM 应用。
从现有的体系来看,主流的编程语言都具备深度学习相关的代码库。我们可以以 Python 生态体系下,作为一个参考示例。诸如于:
Java 语言体系里的 Deep Java Library,提供了大量的深度学习相关的库,使得我们可以快速构建基于 LLM 的应用。
Kotlin 语言体系里的 KInference,是专门为推理(inference)进行优化的,主要是针对在服务端、本地(客户端)运行 ONNX 模型推理的。
Rust 语言。在我们构建 CoUnit 里,使用的是 Rust 语言作为开发语言,则需要 ndarray 这样的多维数组库。
但是在大部分场景下,我们并不需要什么 AI 基础设施。作为一个基本的 AI 应用,可能只需要的是计算 Token 长度这样的功能,以便于避免无谓的 LLM 花费。
FFI 作为接口方式

在这时,而 Tiktoken/Tokenizer **便是我们的第一个需要 FFI (Foreign Function Interface,外部函数接口)功能的库,用于计算 Token 长度。FFI 允许不同编程语言之间的代码相互调用和交互,诸如于使用 Python 来调用 Rust 实现的底层库,以实现更快的计算速度。
除此,从应用侧的角度来说,不论是客户端,还是服务端,都需要引入一些小的推理模型。如下是两个比较常用的基于 FFI 库:
Tokenizer/tokeniser。不论是 OpenAI 的 Tiktoken、还是 HuggingFace 的 Tokenizers,选择的方式都是 Rust 作为底层语言。除此,稍有差异的是 JetBrains 的 AI Assistant 使用 Kotlin 实现了 Tokenizer,或者是出于 FFI 性能的考虑。
ONNX Runtime。Onnx 是一个跨平台机器学习推理加速器。通常用于在客户端、服务端引入小模型推理,诸如于引入 SentenceTransformers 在本地进行相似式搜索。从实现上,ONNX 使用的是 C++ 实现的,所以其它语言下使用的也是 FFI 的形式。
唯一对我们影响比较大的点是,在某些语言下,我们可能没有那么多的参考代码、参考架构作为示例,在开发这一类应用时,时间会比较长。
LLM 应用的技术架构
与常规的应用开发相比,LLM 应用并没有什么太大的区别。只是我们需要考虑 LLM 带来的影响,以及在不同的场景下,如何去管理这些架构。
不同业务场景下,AI 应用的三种模式

通常来说,根据不同的业务模式,结合 AI 的程度也是不一样的,我们将其总结为三种不同的模式。
基础 LLM 应用。通常只需要使用提示工程来与预训练模型进行交互。
Co-pilot 型应用。使用提示工程与智能体(Agent)进行交互,该智能体预训练模型和外部工具储相结合。通常来说,根据用户意图,结合特别的模式编写 workflow,以自动构建上下文。
自主智能体。使用高级智能体(Agent)自动生成提示来控制预训练模型和外部工具。通常来说,由 LLM 来自动根据用户意图生成 workflow,并自动控制外部工具。
因此,根据我们先前构造的几个 PoC,我们将其总结为四个架构设计的基本原则。
LLM 优先的软件架构原则

在这里我们思考的四个架构原则,其实是受限于 LLM 能力所产生的:
用户意图导向设计。设计全新的人机交互体验,构建领域特定的 AI 角色,以更好地理解用户的意图。诸如于,我们可以基于 DSL 来逐步引导用户输出更多的上下文。
上下文工程。构建适合于获取业务上下文的应用架构,以生成更精准的 prompt,并探索高响应速度的工程化方式。
原子能力映射。分析 LLM 所擅长的原子能力,将其与应用所欠缺的能力进行结合,进行能力映射。
语言接口。探索和寻找合适的新一代 API ,以便于 LLM 对服务能力的理解、调度与编排。
而从实践的情况而言,引导用户、完善上下文是我们工程化落地的最大难点。
Prompt 建模与优化
Prompt 的模型与 Prompt 策略本身是息息相关的,通常来说,它与我们解析复杂问题的方式是相关的。
上下文相关的 Prompt 建模
在开发的时候编写 prompt 是一件痛苦的事情,在我们构建了不同的思维链模板之后,我们需要提供更好的示例。为此,我们会对 prompt 进行建模,以更好的管理和测试 prompt。以 LangChain 源码中的 prompt 作为示例:
Human: What is 2+2?
AI: 4
Human: What is 2+3?
AI: 5
Human: What is 4+4?对应的 Python 代码如下:
examples = [
{"input": "2+2", "output": "4"},
{"input": "2+3", "output": "5"},
]为此,根据我们的 Prompt 模式,需要不同的 PromptTemplate 模式,如 LangChain 里便构建了一系列复杂的 Prompt 策略模式,如: FewShotPromptWithTemplates、 FunctionExplainerPromptTemplate 等。
Prompt 模板持续优化
而在我们的 PoC 项目中,不只一种类型的 example。因此需要考虑:如何去持续对它们进行建模?如下是我们使用 Kotlin 构建的项目的一个 QA 模板示例:
@Serializable
data class QAUpdateExample(
override val question: String,
override val answer: String,
val nextAction: String = "",
val finalOutput: String = "",
) : PromptExample {
}也是随着我们迭代的过程中,不断优化出来。而由于 prompt 中需要结合一下上下文信息,通过变量的方式,所以我们还需要诸如于 Apache Velocity 这样的模板引擎,将 prompt 中的变量采用真实的数据来替换。
上下文构建的模式:RAG 与领域特定模式
毫无疑问,在现有的 LLM (大语言模型)应用里,与智能客服、知识问答相关的场景是最多的。在这些场景之下,开发人员一直在探索更好的 RAG(Retrieval-augmented generation,检查增强生成)模式,来使 LLM 回答得更加准确。
然而,事实上,在大部分的场景之下,我们可以构建专有的模式,它们的质量往往更好。但是,通用性不多,依赖于专家来构建,因此显得性价比不足。
领域特定的语言抽象
毫无疑问,代码生成相关的工具是第二大热门的 LLM 工具。与知识场景不同的是,你不一定需要 RAG 来帮你完成上下文的构建。在这个场景下,每个问题都很 “具体”,可以在 IDE、编辑器里拿到足够多的上下文。
不论是 GitHub Copilot、JetBrains AI Assistant,还是我们开源的 AutoDev,都只是在根据用户的行为,得到的结果,来生成对应的 prompt。如 Copilot 会根据最近的 20 个文件,计算与当前代码相差的 code chunk,生成 prompt。而在 AutoDev 里,我们觉得应该将规范编写入代码生成的 prompt,以生成规范化的代码。
也因此,我们相信在特定领域里,根据领域的上下文设计 DSL,设计 prompt 策略,再结合 RAG 才是最合理的方式。
检索增强生成与 Prompt 策略
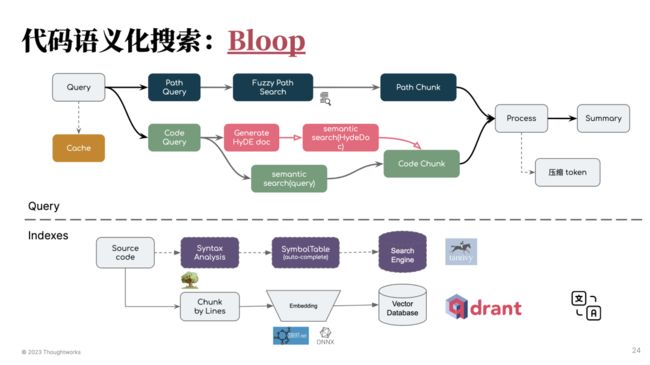
在内部的培训材料里,我将 RAG 视为 prompt 策略的一种。基础的 RAG 模式需要结合向量数据库、构建知识索引。在基础 RAG 模式之下,构建出来的 prompt 并不会达到令人满意的结果。
用户都是小白,并不会以我们预期的方式来操作系统。他们的输入是模糊的,我们的挑战便是:如何将一个模糊的问题具象化?
在 CoUnit 里,我们需要将用户的意图转为 DSL,其中包含中文、英文、HyDE 文档(假设性文档嵌入),以此进行语义化搜索,来获得可能的结果。
在 CoUnit 这一类的场景之下,本身就是查询扩展(Query Expansion)的一种模型,在这类场景之下,还有 Query2Doc 等一系列不同的模式。而随着,我们的有效历史聊天的存储,相关的结果也会越来越准确。
在 LLM 不包含我们知识的情况下,而内部又有大量的相似知识,我们又需要考虑结合 Lost in the Middle 来思考:如何在 prompt 中高效地分布我们的 chunk?即在头尾中分配最相关的结果,以让 LLM 能抓住重点。
与半年前的 LLM 一样,RAG 相关的内容在未来几个月里仍然将激烈的演进,我们依旧需要持续的学习。
转换不确定性的语言 API
在与 LLM 进行交互时,需要由自然语言作为 API。总体上可以分为两大类场景:
LLM + Workflow。由 LLM 分析用户的意图,来选择合适的工具、API。
LLM DSL 生成。由 LLM 分析用户的意图,结合特定上下文,输出 DSL,让应用解析,并作为程序的输入。
语言非常的奇妙,而结合 LLM 的本质则是将不确实性转为确定的函数调用参数、DSL 等。
函数调用:基于用户意图选择合适扩展工具

简单来说,就是类似于如下的 prompt 方式:
你的任务是回答关于代码库的问题。你应该使用一组工具来收集信息,以帮助你回答问题。以下工具可供使用:从实践上来说,通常可以分为这三种模型。
Tooling 模式。即上述的方式,并提供一堆可能可选择的工具。在开发应用时,往往需要结合上下文,生成动态的工具列表,以让 LLM 选择合适的工具。
Function Calling 模式。由 LLM 在聊天时,检测何时应该调用一个函数,传递输入给函数,并调用这个函数。
意图识别小模型。即类似于 OpenAI 相似的方式进行微调,以在特定的场景下,实现类似的功能。
而除了上述的场景之后,还可以由 LLM 生成 DSL,如 JSON 等方式,由程序来处理这个函数实现类似的功能。
数据驱动:DSL 模式与引导用户
通常来说,我们会采用 DSL 作为用户与 LLM 的中间语言。即方便于 LLM 理解,也方便于人类理解,还适合程序解析。当然了,也有一些 DSL 并不需要解析,诸如于:
----------------------------------------------
| Navigation(10x) |
----------------------------------------------
| Empty(2x) | ChatHeader(8x) | Empty(2x) |
----------------------------------------------
| MessageList(10x) |
----------------------------------------------
| MessageInput(10x) |
----------------------------------------------
| Footer(10x) |
----------------------------------------------它可以用为中间的呈现模式,以便于 LLM 进一步生成代码。
除此,如何基于 DSL 模型引导用户,就是一件非常有意思的事。
总结与下一步
在这一篇文章里,我们总结了过去几个月里,构建 LLM 应用的一些经验。而从这些经验里,我们发现了越来越多可复用的模式。
我们将探索如何更好地沉淀下这些模式 ,以用于支撑更快速的 LLM 应用开发。