9.4.tensorRT高级(4)封装系列-使用pybind11为python开发扩展模块
目录
-
- 前言
- 1. pybind11
- 2. 补充知识
-
- 2.1 pybind11 介绍
- 总结
前言
杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。
本次课程学习 tensorRT 高级-使用pybind11为python开发扩展模块
课程大纲可看下面的思维导图
1. pybind11
这节我们学习如何为 python 写 c++ 的扩展模块,使用 pybind11
1. 这里实现了对 yolov5 的推理封装
2. 封装了一个 c++ 类对应到 python 中
3. python 的底层大都使用 c++ 进行封装,可以利用 c++ 的计算性能和 python 的便利性
我们直接来看代码,首先来看 demo.py,代码如下:
import yolo
import os
import cv2
if not os.path.exists("yolov5s.trtmodel"):
yolo.compileTRT(
max_batch_size=1,
source="yolov5s.onnx",
output="yolov5s.trtmodel",
fp16=False,
device_id=0
)
infer = yolo.Yolo("yolov5s.trtmodel")
if not infer.valid:
print("invalid trtmodel")
exit(0)
image = cv2.imread("rq.jpg")
boxes = infer.commit(image).get()
for box in boxes:
l, t, r, b = map(int, [box.left, box.top, box.right, box.bottom])
cv2.rectangle(image, (l, t), (r, b), (0, 255, 0), 2, 16)
cv2.imwrite("detect.jpg", image)
demo.py 主要演示了如何使用编译好的 yolo 扩展库进行 YOLO 模型的推理,其中 yolo 模块是通过 C++ 编译出来的
我们再来看下对应的 C++ 代码,我们主要是学习使用 pybind11 这个第三方库
#include " ,
obj.left, obj.top, obj.right, obj.bottom, obj.class_label, obj.confidence
);
});
py::class_<shared_future<ObjectDetector::BoxArray>>(m, "SharedFutureObjectBoxArray")
.def("get", &shared_future<ObjectDetector::BoxArray>::get);
py::enum_<Yolo::Type>(m, "YoloType")
.value("V5", Yolo::Type::V5)
.value("V3", Yolo::Type::V3)
.value("X", Yolo::Type::X);
py::enum_<Yolo::NMSMethod>(m, "NMSMethod")
.value("CPU", Yolo::NMSMethod::CPU)
.value("FastGPU", Yolo::NMSMethod::FastGPU);
py::class_<YoloInfer>(m, "Yolo")
.def(py::init<string, Yolo::Type, int, float, float, Yolo::NMSMethod, int, bool>(),
py::arg("engine"),
py::arg("type") = Yolo::Type::V5,
py::arg("device_id") = 0,
py::arg("confidence_threshold") = 0.4f,
py::arg("nms_threshold") = 0.5f,
py::arg("nms_method") = Yolo::NMSMethod::FastGPU,
py::arg("max_objects") = 1024,
py::arg("use_multi_preprocess_stream") = false
)
.def_property_readonly("valid", &YoloInfer::valid, "Infer is valid")
.def("commit", &YoloInfer::commit, py::arg("image"));
m.def(
"compileTRT", compileTRT,
py::arg("max_batch_size"),
py::arg("source"),
py::arg("output"),
py::arg("fp16") = false,
py::arg("device_id") = 0,
py::arg("max_workspace_size") = 1ul << 28
);
}
PYBIND11_MODULE 宏是 pybind11 的核心部分,用于定义 Python 模块和绑定 C++ 类和函数到 Python 中,即用于定义 Python 扩展模块。
在这里,我们定义了一个名为 yolo 的模块,并使用 m 作为模块的引用,以下是这个模块定义中的详细内容:
1. ObjectBox 类绑定
py::class_<ObjectDetector::Box>(m, "ObjectBox")
...
这里我们使用 py::class_ 定义一个 Python 类,名为 ObjectBox。该类在 C++ 中对应的是 ObjectDetector::Box,这个类的定义中利用 .def_property 定义了 Box 的多个属性,而 .def_property_readonly 则表示该属性只可读,同时在该类中还使用了 .def 定义了一个python 类中的魔法方法 __repr__ 用于打印 box 的信息
2. SharedFutureObjectBoxArray 类绑定
py::class_<shared_future<ObjectDetector::BoxArray>>(m, "SharedFutureObjectBoxArray")
.def("get", &shared_future<ObjectDetector::BoxArray>::get);
这里我们为 shared_future
3. 枚举绑定
py::enum_<Yolo::Type>(m, "YoloType")
.value("V5", Yolo::Type::V5)
...
py::enum_<Yolo::NMSMethod>(m, "NMSMethod")
...
这里我们定义了两个 Python 枚举类,名为 YoloType 和 NMSMethod,主要用于 Yolo 类型的指定和 NMS 方法的指定
4. YoloInfer 类绑定
py::class_<YoloInfer>(m, "Yolo")
...
这是最重要的部分。我们为 YoloInfer 类定义了一个 Python 类,名为 Yolo。这个类的定义包含了多个构造函数参数、属性和方法的绑定,比如 engine、type、device_id 等,我们还在这个类中定义了一个 commit 方法用于推理,它关联的是 YoloInfer::commit
5. compileTRT 函数绑定
m.def(
"compileTRT", compileTRT,
py::arg("max_batch_size"),
...
);
最后,我们为 C++ 中的 compileTRT 函数定义了一个 Python 函数。这允许我们在 Python 中利用 TensorRT 编译模型
总的来说,PYBIND11_MODULE(yolo, m) 定义的内容为我们提供了一个完整的 Python 接口,用于 YOLO 模型的推理和相关操作。通过这种方式,我们可以直接在 Python 中使用 C++ 编写的高效 YOLO 模型的推理代码,同时还能使用 Python 的灵活性和易用性。
Makefile 文件也需要发生相应的修改,主要修改如下:
1. 包含 python 的头文件路径
include_paths := src \
src/tensorRT \
$(cuda_home)/include/cuda \
$(cuda_home)/include/tensorRT \
$(cpp_pkg)/opencv4.2/include \
$(cuda_home)/include/protobuf \
/datav/software/anaconda3/include/python3.9
2. 包含 python 的库文件路径
library_paths := $(cuda_home)/lib64 $(syslib) $(cpp_pkg)/opencv4.2/lib /datav/software/anaconda3/lib
3. 添加需要链接的 python 库
link_sys := stdc++ dl protobuf python3.9
4. 编译成动态库
$(workdir)/$(name) : $(cpp_objs) $(cu_objs)
@echo Link $@
@mkdir -p $(dir $@)
@$(cc) -shared $^ -o $@ $(link_flags)
完整的 Makefile 文件内容如下:
cc := g++
name := yolo.so
workdir := workspace
srcdir := src
objdir := objs
stdcpp := c++11
cuda_home := /usr/local/cuda-11.6
syslib := /home/jarvis/anaconda3/envs/yolov8/lib
cpp_pkg := /usr/local/include
trt_home := /opt/TensorRT-8.4.1.5
pro_home := /home/jarvis/lean/protobuf-3.11.4
cuda_arch :=
nvcc := $(cuda_home)/bin/nvcc -ccbin=$(cc)
# 定义cpp的路径查找和依赖项mk文件
cpp_srcs := $(shell find $(srcdir) -name "*.cpp")
cpp_objs := $(cpp_srcs:.cpp=.cpp.o)
cpp_objs := $(cpp_objs:$(srcdir)/%=$(objdir)/%)
cpp_mk := $(cpp_objs:.cpp.o=.cpp.mk)
# 定义cu文件的路径查找和依赖项mk文件
cu_srcs := $(shell find $(srcdir) -name "*.cu")
cu_objs := $(cu_srcs:.cu=.cu.o)
cu_objs := $(cu_objs:$(srcdir)/%=$(objdir)/%)
cu_mk := $(cu_objs:.cu.o=.cu.mk)
# 定义opencv和cuda需要用到的库文件
link_cuda := cudart cudnn
link_trtpro :=
link_tensorRT := nvinfer nvinfer_plugin
link_opencv := opencv_core opencv_imgproc opencv_imgcodecs
link_sys := stdc++ dl protobuf python3.8
link_librarys := $(link_cuda) $(link_tensorRT) $(link_sys) $(link_opencv)
# 定义头文件路径,请注意斜杠后边不能有空格
# 只需要写路径,不需要写-I
include_paths := src \
src/tensorRT \
$(cuda_home)/include \
$(trt_home)/include \
$(cpp_pkg)/opencv4 \
$(pro_home)/include\
/home/jarvis/anaconda3/envs/yolov8/include/python3.8
# 定义库文件路径,只需要写路径,不需要写-L
library_paths := $(cuda_home)/lib64 $(syslib) $(cpp_pkg)/opencv4.2/lib /usr/local/lib ${trt_home}/lib ${pro_home}/lib
# 把library path给拼接为一个字符串,例如a b c => a:b:c
# 然后使得LD_LIBRARY_PATH=a:b:c
empty :=
library_path_export := $(subst $(empty) $(empty),:,$(library_paths))
# 把库路径和头文件路径拼接起来成一个,批量自动加-I、-L、-l
run_paths := $(foreach item,$(library_paths),-Wl,-rpath=$(item))
include_paths := $(foreach item,$(include_paths),-I$(item))
library_paths := $(foreach item,$(library_paths),-L$(item))
link_librarys := $(foreach item,$(link_librarys),-l$(item))
# 如果是其他显卡,请修改-gencode=arch=compute_75,code=sm_75为对应显卡的能力
# 显卡对应的号码参考这里:https://developer.nvidia.com/zh-cn/cuda-gpus#compute
# 如果是 jetson nano,提示找不到-m64指令,请删掉 -m64选项。不影响结果
cpp_compile_flags := -std=$(stdcpp) -w -g -O0 -m64 -fPIC -fopenmp -pthread
cu_compile_flags := -std=$(stdcpp) -w -g -O0 -m64 $(cuda_arch) -Xcompiler "$(cpp_compile_flags)"
link_flags := -pthread -fopenmp -Wl,-rpath='$$ORIGIN'
cpp_compile_flags += $(include_paths)
cu_compile_flags += $(include_paths)
link_flags += $(library_paths) $(link_librarys) $(run_paths)
# 如果头文件修改了,这里的指令可以让他自动编译依赖的cpp或者cu文件
ifneq ($(MAKECMDGOALS), clean)
-include $(cpp_mk) $(cu_mk)
endif
$(name) : $(workdir)/$(name)
all : $(name)
run : $(name)
@cd $(workdir) && python demo.py $(run_args)
$(workdir)/$(name) : $(cpp_objs) $(cu_objs)
@echo Link $@
@mkdir -p $(dir $@)
@$(cc) -shared $^ -o $@ $(link_flags)
$(objdir)/%.cpp.o : $(srcdir)/%.cpp
@echo Compile CXX $<
@mkdir -p $(dir $@)
@$(cc) -c $< -o $@ $(cpp_compile_flags)
$(objdir)/%.cu.o : $(srcdir)/%.cu
@echo Compile CUDA $<
@mkdir -p $(dir $@)
@$(nvcc) -c $< -o $@ $(cu_compile_flags)
# 编译cpp依赖项,生成mk文件
$(objdir)/%.cpp.mk : $(srcdir)/%.cpp
@echo Compile depends C++ $<
@mkdir -p $(dir $@)
@$(cc) -M $< -MF $@ -MT $(@:.cpp.mk=.cpp.o) $(cpp_compile_flags)
# 编译cu文件的依赖项,生成cumk文件
$(objdir)/%.cu.mk : $(srcdir)/%.cu
@echo Compile depends CUDA $<
@mkdir -p $(dir $@)
@$(nvcc) -M $< -MF $@ -MT $(@:.cu.mk=.cu.o) $(cu_compile_flags)
# 定义清理指令
clean :
@rm -rf $(objdir) $(workdir)/$(name) $(workdir)/*.trtmodel $(workdir)/*.onnx
# 防止符号被当做文件
.PHONY : clean run $(name)
# 导出依赖库路径,使得能够运行起来
export LD_LIBRARY_PATH:=$(library_path_export)
OK!我们先来执行 make run

错误信息如下:
relocation R_X86_64_TPOFF32 against symbol ... can not be used when making a shared object; recompile with -fPIC
问题出在 libprotobuf.a 是静态库,并且它不是使用 -fPIC 选项编译的,这导致在创建动态库时不能链接到对应的 protobuf 动态库。
后来博主发现我们编译使用的 protobuf 一直都是静态库,因此我们需要重新编译 protobuf 使其生成动态库。
动态库的编译也相对简单,只要在静态库的基础上加上动态库编译的选项即可,如下所示:
cmake . -Dprotobuf_BUILD_TESTS=OFF -Dprotobuf_BUILD_SHARED_LIBS=ON
具体可参考:Ubuntu20.04软件安装大全、protobuf库在Linux下编译
编译完成后我们再重新指定下 Makefile 中 protobuf 的路径,并重新执行下 make run 运行效果如下:
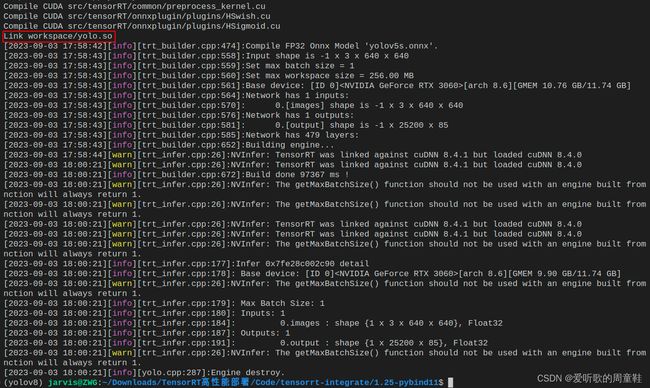
编译有点耗时,可以看到 yolo.so 成功编译了,我们接下来执行下 demo.py,在这里需要说明下我们是通过 make run 来执行 demo.py 的,Makefile 中的 run 指令会 cd 到 workspace 下面然后去执行 python demo.py,如下所示:
run : $(name)
@cd $(workdir) && python demo.py $(run_args)
我们为什么不自己手动 cd workspace 然后 python demo.py 呢?这是因为 Makefile 中我们对环境变量进行了设置,而如果直接在命令行中执行 demo.py 而没有设置这些环境变量,程序可能无法找到必要的共享库或其他依赖项,从而导致不必要的错误。
你可以自己 export 导入必要的环境变量,我们通过 Makefile 执行 demo.py 效果如下:
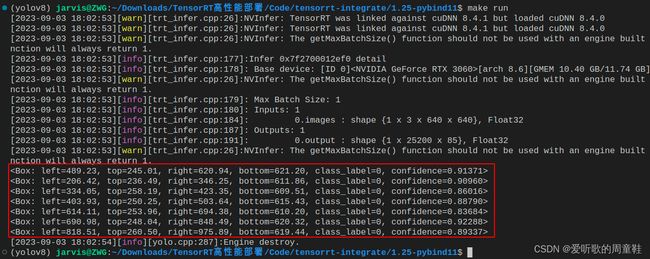
推理的效果图如下:

OK!以上就是用 C++ 为 Python 写扩展库的一个演示
在你认为使用 Python 效率不够高的时候,或者有些功能用 C++ 写更方便的时候,你都应该去考虑用 C++ 写一个库交给 Python 去调用,使得其性能足够高,你的工作效率也足够的高,而不是使用 Python 版本的 tensorRT 或者 Python 版本的 CUDA,这个还不如直接上 C++ 写 CUDA,上 C++ 上写 tensorRT,它性能比在 Python 上更高,可操作性也更强,也更便利(来自杜老师的建议)
2. 补充知识
2.1 pybind11 介绍
pybind11 是一个用于为 Python 创建绑定的 C++11 库。它提供了一个简单的接口,使得 C++ 类和函数可以在 Python 中使用,而无需向 SWIG 或 Boost.Python 那样的中间层
GitHub地址:https://github.com/pybind/pybind11
下面是 pybind11 的一些主要特点:
1. 易于使用:使用 pybind11 可以轻松地在 Python 和 C++ 之间创建绑定
2. 头文件:pybind11 是一个只有头文件的库,这意味着没有必要预先编译任何东西。你只需包含头文件并开始编写绑定代码
3. 类型转换:pybind11 能够自动处理许多 C++ 和 Python 之间的类型转换
4. 扩展性:可以为 C++ 类和函数创建 Python 扩展,甚至支持继承、重载和其他 C++ 特性
5. 性能:与其他绑定生成器相比,pybind11 的性能非常好
6. 与现代 C++ 兼容:pybind11 使用 C++11 标准,这使得它与现代 C++ 代码非常兼容
总结
本次课程我们学习了利用 pybind11 为 Python 写 C++ 的扩展模块。它使得我们可以直接在 Python 中使用 C++ 编写的高性能推理代码,同时还能利用 Python 的灵活和便利性,非常有利于我们平时的开发。