Kylin的介绍、使用和原理架构(Kylin3.0和Kylin4.0,Cube,去重原理,性能优化,MDX For Kylin,BI工具集成)
文章目录
-
- 简介
-
- 介绍
- 架构
- Kylin特点
- Kylin4.0升级
- 安装
-
- Kylin3.0安装
- Kylin4.0安装
-
- 依赖环境
- Spark安装和部署
- Kylin 安装和部署
- Kylin 启动环境准备
- Kylin 启动和关闭
- docker安装
- Kylin使用
-
- 创建工程
- 获取数据源
- 创建model
- 构建cube
- 查询
- 每日自动构建cube
- Kylin 使用注意事项
-
- 每日全量维度表及拉链维度表重复Key问题处理
- 只能按照构建 Model 的连接条件来写 SQL
- 只能按照构建 Cube 时选择的维度字段分组统计
- 只能统计构建 Cube 时选择的度量值字段
- Kylin 设置查询下压
- Kylin4.0 查询引擎
-
- 查询引擎 Sparder
- HDFS 存储目录
- 查询参数汇总
- Cube构建原理
-
- 维度和度量
- Cube、Cuboid、Segment
- Cube构建算法
- Cube存储原理
- 去重原理(※)
-
- 去重方法
- 精确去重的原理
- RoaringBitmap
-
- 实现思路
- 小桶的类型
- 与bitmap的性能对比
- 全局字典介绍
- Trie树与AppendTrie树
- Cube构建优化
-
- 衍生维度(derived dimension)
- 聚合组(Aggregation group)
- Cube构建参数调优
-
- 使用适当的 Spark 资源和配置来构建 Cube
- 全局字典构建性能调优
- 快照表构建性能调优
- 查询性能优化
-
- Row Key优化
- 使用 shardby 列来裁剪 parquet 文件
- 减少小的或不均匀的 parquet 文件
- 将多个小文件读取到同一个分区
- 使用堆外内存
- BI工具集成
-
- JDBC
- Zepplin
- MDX For Kylin
-
- 流程介绍
- 安装
-
- 前置条件
- 安装 MDX
- 启动 MDX For Kylin
- 设计数据集
- 在 Excel 中分析
- Kylin5.0介绍
简介
介绍
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
架构
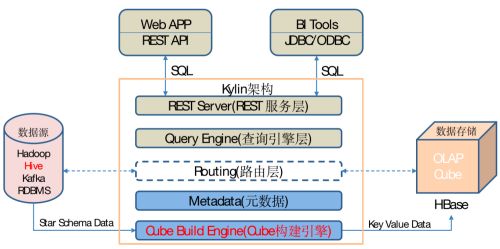
Kylin4.0版本架构:
(1)REST Server
REST Server是一套面向应用程序开发的入口点,旨在实现针对Kylin平台的应用开发工作。 此类应用程序可以提供查询、获取结果、触发cube构建任务、获取元数据以及获取用户权限等等。另外可以通过Restful接口实现SQL查询。
(2)查询引擎(Query Engine)
当cube准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它组件进行交互,从而向用户返回对应的结果。
(3)路由器(Routing)
在最初设计时曾考虑过将Kylin不能执行的查询引导去Hive中继续执行,但在实践后发现Hive与Kylin的速度差异过大,导致用户无法对查询的速度有一致的期望,很可能大多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此体验非常糟糕。最后这个路由功能在发行版中默认关闭。
(4)元数据管理工具(Metadata)
Kylin是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存在Kylin当中的所有元数据进行管理,其中包括最为重要的cube元数据。其它全部组件的正常运作都需以元数据管理工具为基础。 Kylin4.0 的元数据存储在 MySQL 中,原版本是存在hbase中。
(5)任务引擎(Cube Build Engine)
这套引擎的设计目的在于处理所有离线任务,其中包括shell脚本、Java API以及Map Reduce任务等等。任务引擎对Kylin当中的全部任务加以管理与协调,从而确保每一项任务都能得到切实执行并解决其间出现的故障。
kylin4.0 的构建引擎从 MR 替换为 Spark,速度更快。使用户能够快速得到想要的 Cube 数据。构建引擎最终得到的数据存放到 Parquet 文件当中,然后让用户可以更好的使用SparkSQL 查询引擎去读取 Cube 数据。
Kylin特点
Kylin的主要特点包括支持SQL接口、支持超大规模数据集、亚秒级响应、可伸缩性、高吞吐率、BI工具集成等。
- 标准SQL接口:Kylin是以标准的SQL作为对外服务的接口。
- 支持超大数据集:Kylin对于大数据的支撑能力可能是目前所有技术中最为领先的。早在2015年eBay的生产环境中就能支持百亿记录的秒级查询,之后在移动的应用场景中又有了千亿记录秒级查询的案例。
- 亚秒级响应:Kylin拥有优异的查询相应速度,这点得益于预计算,很多复杂的计算,比如连接、聚合,在离线的预计算过程中就已经完成,这大大降低了查询时刻所需的计算量,提高了响应速度。
- 可伸缩性和高吞吐率:单节点Kylin可实现每秒70个查询,还可以搭建Kylin的集群。
- BI工具集成。Kylin可以与现有的BI工具集成,具体包括如下内容:
- ODBC:与Tableau、Excel、PowerBI等工具集成
- JDBC:与Saiku、BIRT等Java工具集成
- RestAPI:与JavaScript、Web网页集成
Kylin开发团队还贡献了Zepplin的插件,也可以使用Zepplin来访问Kylin服务。
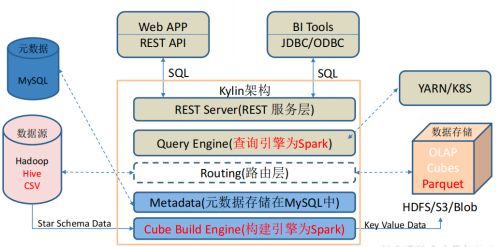
Kylin4.0升级
Apache Kylin4.0 是 Apache Kylin3.x 之后一次重大的版本更新,它采用了全新的 Spark 构建引擎和 Parquet 作为存储,同时使用 Spark 作为查询引擎。
Apache Kylin4.0 的第一个版本 kylin4.0.0-alpha 于 2020 年 7 月份发布,此后相继发布 kylin4.0.0-beta 以及正式版本。
首先介绍一下 Apache Kylin 4.0 的主要优势,Apache Kylin 4 是完全基于 Spark 去做构建和查询的,能够充分地利用 Spark 的并行化、向量化和全局动态代码生成等技术,去提高大数据场景下查询的效率。接下来我们从数据存储,构建引擎,查询引擎三方面来聊一聊Kylin4.0 的升级。
(1)数据存储
Apache Kylin 3.0 是使用 Hbase 作为存储结构的,因此我们可以称为是 Kylin on Hbase。 而 Apache Kylin 4.0 完全砍掉了 Hbase,底层使用 Parquet 存储文件,因此可以称为 Kylin on Parquet。
首先来看一下,Kylin on HBase 和 Kylin on Parquet 的对比。Kylin on HBase 的 Cuboid 的数据是存放在 HBase 的表里,一个 Segment 对应了一张 HBase 表,查询下压的工作由HBase 协理器处理,因为 HBase 不是真正的列存并且对 OLAP 而言吞吐量不高。Kylin 4 将 HBase 替换为 Parquet,也就是把所有的数据按照文件存储,每个 Segment 会存在一个对应的 HDFS 的目录,所有的查询、构建都是直接通过读写文件的方式,不用再经过 HBase。虽然对于小查询的性能会有一定损失,但对于复杂查询带来的提升是更可观的、更值得的。
(2)构建引擎
Kylin Cube 的构建引擎,在 Kylin3.0 中,一般都会使用 MR 作为 Cube 构建引擎去逐层构建 Cube,速度较慢。而在 Kylin4.0 中,将构建引擎换成了特定优化的 Spark 引擎,步骤也减少为了两大步,第一步进行资源探测,收集构建 Cube 所需要的元数据信息。第二步使用 Spark 引擎去计算和构建,有效的提升了 Cube 构建速度。
(3)查询引擎
Kylin3.0 的查询完全依托于 Calcite 引擎和 HBase 的协处理器,这就导致当数据从HBase 读取后,如果想做聚合、排序等,就会局限于 QueryServer 单点的瓶颈,而 Kylin 4 则转换为基于 Spark SQL 的 DataFrame 作为查询引擎,得益于 Spark 的分布式查询机制,Kylin4.0 的查询速度也有了不少的改善。
安装
Kylin3.0安装
(1)Kylin依赖环境
安装Kylin前需先部署好Hadoop、Hive、Zookeeper、HBase,并且需要在/etc/profile中配置以下环境变量HADOOP_HOME,HIVE_HOME,HBASE_HOME,记得source使其生效。
版本:
- Hadoop:3.1.3
- Hive:3.1.2
- Zookeeper:3.5.7
- HBase:2.0.5
(2)Kylin搭建
-
上传Kylin安装包apache-kylin-3.0.2-bin.tar.gz
-
解压apache-kylin-3.0.2-bin.tar.gz到/opt/module
[atguigu@hadoop102 sorfware]$ tar -zxvf apache-kylin-3.0.2-bin.tar.gz -C /opt/module/ [atguigu@hadoop102 module]$ mv /opt/module/apache-kylin-3.0.2-bin /opt/module/kylin
(3)Kylin兼容性问题
修改/opt/module/kylin/bin/find-spark-dependency.sh,排除冲突的jar包
需要增加的内容:! -name ‘*jackson*’ ! -name ‘*metastore*’
注意前后保留空格

(4)Kylin启动
-
启动Kylin之前,需先启动Hadoop(hdfs,yarn,jobhistoryserver)、Zookeeper、Hbase
-
启动Kylin
[atguigu@hadoop102 kylin]$ bin/kylin.sh start
启动之后查看各个节点进程:
--------------------- hadoop102 ----------------
3360 JobHistoryServer
31425 HMaster
3282 NodeManager
3026 DataNode
53283 Jps
2886 NameNode
44007 RunJar
2728 QuorumPeerMain
31566 HRegionServer
--------------------- hadoop103 ----------------
5040 HMaster
2864 ResourceManager
9729 Jps
2657 QuorumPeerMain
4946 HRegionServer
2979 NodeManager
2727 DataNode
--------------------- hadoop104 ----------------
4688 HRegionServer
2900 NodeManager
9848 Jps
2636 QuorumPeerMain
2700 DataNode
2815 SecondaryNameNode
在http://hadoop102:7070/kylin查看Web页面
用户名为:ADMIN,密码为:KYLIN
(5)关闭Kylin
[atguigu@hadoop102 kylin]$ bin/kylin.sh stop
Kylin4.0安装
依赖环境
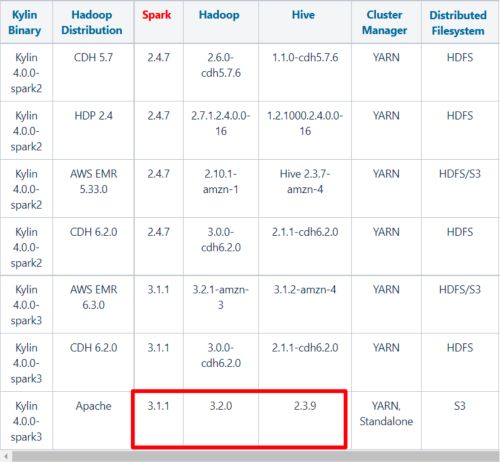
安装 Kylin 前需先部署好 Hadoop、Hive、Zookeeper、Spark,并且需要在/etc/profile 中配置以下环境变量 HADOOP_HOME,HIVE_HOME,ZOOKEEPER_HOME,SPARK_HOME记得 source 使其生效。
注意:目前集群中 hadoop3.1.3 和 hive3.1.2 是可以满足 Kylin4.0 安装和使用的,但是经测试 Spark3.0.0 不能满足 Kylin4.0 对 Spark3 最低版本的要求,因此我们需要先升级 Spark 的版本为 3.1.1
Spark安装和部署
(1)上传 Spark 安装包 spark-3.1.1-bin-hadoop3.2.tgz
(2)解压 spark-3.1.1-bin-hadoop3.2.tgz 到/opt/module
(3)设置 SPARK_HOME,然后source 使其生效
[atguigu@hadoop102 module]$ sudo vim /etc/profile.d/my_env.sh
#SPARK_HOME
export SPARK_HOME=/opt/module/spark-3.1.1
export PATH=$PATH:$SPARK_HOME/bin
[atguigu@hadoop102 module]$ source /etc/profile
(4)修改配置文件 spark_env.sh,让spark 程序能够正常进入 yarn 集群
[atguigu@hadoop102 spark-3.1.1]$ cd conf/
[atguigu@hadoop102 conf]$ mv spark-env.sh.template spark-env.sh
[atguigu@hadoop102 conf]$ vim spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
(5)拷贝 MySQL 连接驱动到 spark 的 jars 目录下,让 Spark 能够正常连接 MySQL
[atguigu@hadoop102 spark-3.1.1]$ cd jars/
[atguigu@hadoop102 jars]$ cp /opt/software/mysql/mysql-connector-java-5.1.48.jar /opt/module/spark-3.1.1/jars/
Kylin 安装和部署
(1)上传 Kylin 安装包 apache-kylin-4.0.1-bin-spark3.tar.gz
(2)解压 apache-kylin-4.0.1-bin-spark3.tar.gz 到/opt/module
[atguigu@hadoop102 sorfware]$ tar -zxvf apache-kylin-4.0.1-bin-spark3.tar.gz -C /opt/module/
[atguigu@hadoop102 module]$ mv /opt/module/apache-kylin-4.0.1-bin-spark3/ /opt/module/kylin-4.0.1/
(3)将 mysql 连接驱动拷贝一份到 Kylin 的 ext 目录下,方便 Kylin 存储元数据
[atguigu@hadoop102 kylin-4.0.1]$ mkdir ext
[atguigu@hadoop102 kylin-4.0.1]$ cp /opt/software/mysql/mysql-connector-java-5.1.48.jar /opt/module/kylin-4.0.1/ext/
(4)修改 Kylin 配置文件 kylin.properties,根据实际情况修改以下参数
[atguigu@hadoop102 conf]$ cd /opt/module/kylin-4.0.1/conf/
[atguigu@hadoop102 conf]$ vim kylin.properties
#### METADATA | ENV ###
# 元数据存储,用的 mysql
kylin.metadata.url=kylin_metadata@jdbc,url=jdbc:mysql://hadoop102:3306/kylin,username=root,password=123456,maxActive=10,maxIdle=10
# hdfs 工作空间
kylin.env.hdfs-working-dir=/kylin
# kylin 在 zk 的工作目录
kylin.env.zookeeper-base-path=/kylin
# 不用 kylin 自带的 zk
kylin.env.zookeeper-is-local=false
# 外部 zk 连接字符串
kylin.env.zookeeper-connect-string=hadoop102:2181,hadoop103:2181,hadoop104:2181
#### SPARK BUILD ENGINE CONFIGS ###
# hadoop conf 目录位置
kylin.env.hadoop-conf-dir=/opt/module/hadoop-3.1.3/etc/hadoop
Kylin 启动环境准备
(1)Yarn 内存设置
Kylin4.0 使用 Spark 作为计算引擎和查询引擎,因此对 spark 任务运行的 yarn 容器内存有所要求,要求 yarn 容器内存不能低于 4G,因此需要将 Yarn 容器内存调为 8G,否则 kylin启动会报错。
注意:yarn 容器内存都调为了 8G,所以三台虚拟机内存一定要大于 8G,否则 Kylin 运行会报错,此处建议学者将三台虚拟机内存设置为 12G,8G,8G。
[atguigu@hadoop102 ~]$ cd /opt/module/hadoop-3.1.3/etc/hadoop/
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>512value>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>8192value>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>8192value>
property>
<property>
<name>yarn.nodemanager.pmem-check-enabledname>
<value>falsevalue>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
修改保存以后,记得分发三台节点。
[atguigu@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
(2)增加 ApplicationMaster 资源比例
容量调度器对每个资源队列中同时运行的 Application Master 占用的资源进行了限制,该限制通过 yarn.scheduler.capacity.maximum-am-resource-percent 参数实现,其默认值是 0.1,表示每个资源队列上 Application Master 最多可使用的资源为该队列总资源的 10%,目的是防止大部分资源都被 Application Master 占用,而导致 Map/Reduce Task 无法执行。
生产环境该参数可使用默认值。但学习环境,集群资源总数很少,如果只分配 10%的资源给 Application Master,则可能出现,同一队列在同一时刻只能运行一个 Job 的情况,因为一个 Application Master 使用的资源就可能已经达到 10%的上限了。故此处可将该值适当调大。因为 Kylin4.0 的查询会生成一个在后台长期运行的 Sparder 任务,占用 Default 队列,因此一定要调大此参数,否则 Kylin4.0 无法正常使用。
- 在 hadoop102 的/opt/module/hadoop-3.1.3/etc/hadoop/capacity-scheduler.xml 文件中修改如下参数值
[atguigu@hadoop102 hadoop]$ vim capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percentname>
<value>0.8value>
- 分发 capacity-scheduler.xml 配置文件,并重启 yarn。
[atguigu@hadoop102 hadoop]$ xsync capacity-scheduler.xml
(3)在 MySQL 里手动创建 kylin 数据库,方便 Kylin 存储元数据
[atguigu@hadoop102 ~]$ mysql -uroot -p123456
mysql> create database kylin;
(4)启动 Zookeeper 集群
[atguigu@hadoop102 ~]$ zk.sh start
(5)启动 Hadoop 集群
[atguigu@hadoop102 ~]$ myhadoop.sh start
Kylin 启动和关闭
(1)启动 kylin
[atguigu@hadoop102 kylin-4.0.1]$ bin/kylin.sh start
启动之后查看各个节点进程:
[atguigu@hadoop102 kylin-4.0.1]$ jpsall
=============== hadoop102 ===============
5408 Bootstrap
3825 NameNode
3974 DataNode
4539 JobHistoryServer
3499 QuorumPeerMain
4350 NodeManager
=============== hadoop103 ===============
3201 ResourceManager
3350 NodeManager
2983 DataNode
2810 QuorumPeerMain
=============== hadoop104 ===============
2819 QuorumPeerMain
3123 SecondaryNameNode
2983 DataNode
3226 NodeManager
在/opt/module/kylin-4.0.1/logs/kylin.log 查看启动日志。
在 http://hadoop102:7070/kylin 查看 Web 页面。
可以使用默认用户登录,用户名为:ADMIN,密码为:KYLIN
(2)关闭Kylin
[atguigu@hadoop102 kylin-4.0.1]$ bin/kylin.sh stop
注意:第一次启动 Kylin,Web 页面会报 404 错误,查看 kylin 后台启动日志,发现错误日志如下:
[atguigu@hadoop102 logs]$ tail -n 1000 kylin.log
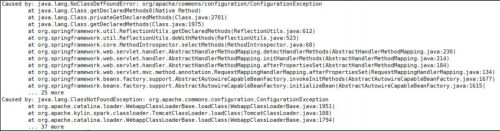
分析原因应该是 Kylin4.0 和 Hadoop 或者 Hive 版本不兼容所致,因此需要手动补充两个 Commons 的 jar 包。上传提前准备好的两个 commons 的 jar 包到 Kylin 的指定目录下,否则 Kylin 启动会报错,目的是为了解决 Kylin 和 Hive 的版本冲突。
[atguigu@hadoop102 sorfware]$ cp commons-configuration-1.3.jar /opt/module/kylin-4.0.1/tomcat/webapps/kylin/WEB-INF/lib/
[atguigu@hadoop102 sorfware]$ cp commons-collections-3.2.2.jar /opt/module/kylin-4.0.1/tomcat/webapps/kylin/WEB-INF/lib/
[atguigu@hadoop102 software]$ ll /opt/module/kylin-4.0.1/tomcat/webapps/kylin/WEB-INF/lib/ | grep commons-co
-rw-rw-r--. 1 atguigu atguigu 232771 5 月 6 2016 commons-codec-1.6.jar
-rw-r--r--. 1 atguigu atguigu 588337 3 月 11 22:48 commons-collections-3.2.2.jar
-rw-rw-r--. 1 atguigu atguigu 71626 9 月 6 2020 commons-compiler-3.0.16.jar
-rw-rw-r--. 1 atguigu atguigu 591748 1 月 17 2019 commons-compress-1.18.jar
-rw-r--r--. 1 atguigu atguigu 232915 3 月 11 22:46 commons-configuration-1.3.j
然后关闭 kylin,重新启动即可。
docker安装
docker pull apachekylin/apache-kylin-standalone:kylin-4.0.1-mondrian
docker run -d \
-m 8G \
-p 7070:7070 \
-p 7080:7080 \
-p 8088:8088 \
-p 50070:50070 \
-p 8032:8032 \
-p 8042:8042 \
-p 2181:2181 \
apachekylin/apache-kylin-standalone:kylin-4.0.1-mondrian
在容器启动时,会自动启动以下服务:
- NameNode, DataNode
- ResourceManager, NodeManager
- Kylin
- MDX for Kylin
并自动运行 $KYLIN_HOME/bin/sample.sh .
容器启动后,我们可以通过 “docker exec -it
- Kylin 页面:http://127.0.0.1:7070/kylin/login
- MDX for Kylin 页面:http://127.0.0.1:7080
- HDFS NameNode 页面:http://127.0.0.1:50070
- YARN ResourceManager 页面:http://127.0.0.1:8088http://127.0.0.1:8088/)
Kylin使用
以gmall数据仓库中的dwd_order_detail作为事实表,dim_user_info、dim_sku_info、dim_base_province作为维度表,构建星型模型,并演示如何使用Kylin进行OLAP分析。
创建工程
(1)点击下图中的"+"。
(2)填写项目名称和描述信息,并点击Submit按钮提交。

获取数据源
(1)点击DataSource
(2)点击下图按钮导入Hive表
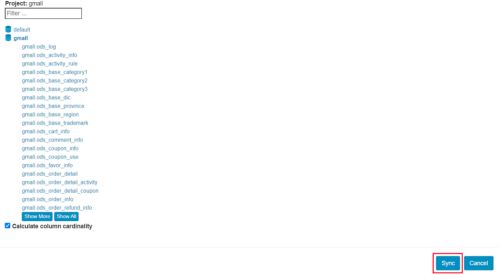
(3)选择以下表格,并点击Sync按钮
dwd_order_detail
dim_sku_info
dim_user_info
dim_base_province
注意事项:
Kylin不能处理Hive表中的复杂数据类型(Array,Map,Struct),即便复杂类型的字段并未参与到计算之中。故在加载Hive数据源时,不能直接加载带有复杂数据类型字段的表。而在dim_sku_info表中存在两个复杂数据类型的字段(平台属性和销售属性),故dim_sku_info不能直接加载,需对其进行以下处理。
(1)在hive客户端创建一个视图,如下。该视图已经将dim_sku_info表中的复杂数据类型的字段去掉,在后续的计算中,不再使用dim_sku_info,而使用dim_sku_info_view。
hive (gmall)> create view dim_sku_info_view
as
select
id,
price,
sku_name,
sku_desc,
weight,
is_sale,
spu_id,
spu_name,
category3_id,
category3_name,
category2_id,
category2_name,
category1_id,
category1_name,
tm_id,
tm_name,
create_time
from dim_sku_info;
(2)在kylin中重新导入dim_sku_info_view视图
创建model
(1)点击Models,点击"+New"按钮,点击"★New Model"按钮。
(2)填写Model信息,点击Next

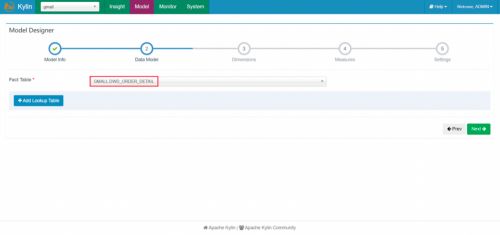
(3)指定事实表
(4)选择维度表,并指定事实表和维度表的关联条件,点击Ok
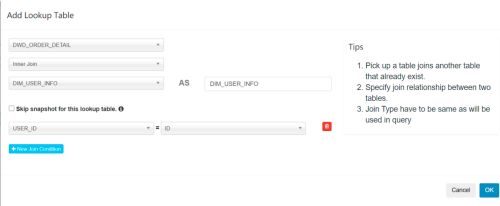
维度表添加完毕之后,点击Next
(5)指定维度字段,并点击Next
(6)指定度量字段,并点击Next
(7)指定事实表分区字段(仅支持时间分区),点击Save按钮,model创建完毕
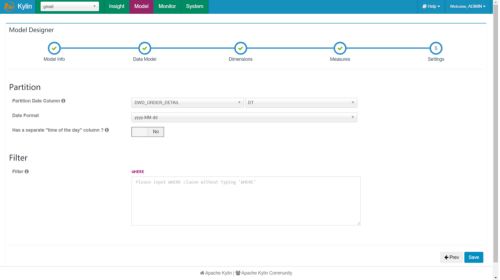
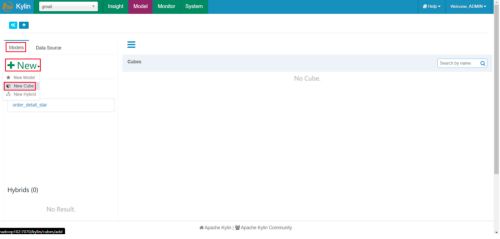
构建cube
(1)点击new, 并点击new cube
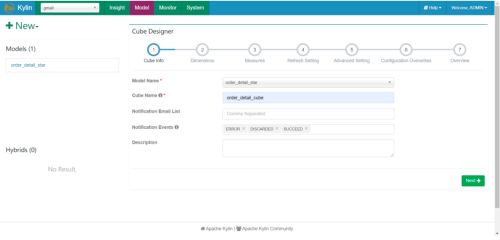
(2)填写cube信息,选择cube所依赖的model,并点击next
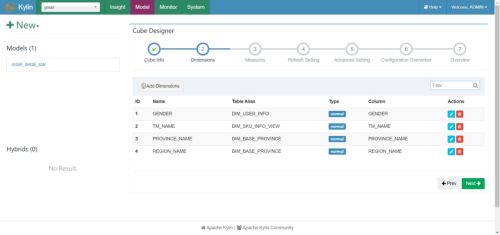
(3)选择所需的维度,如下图所示
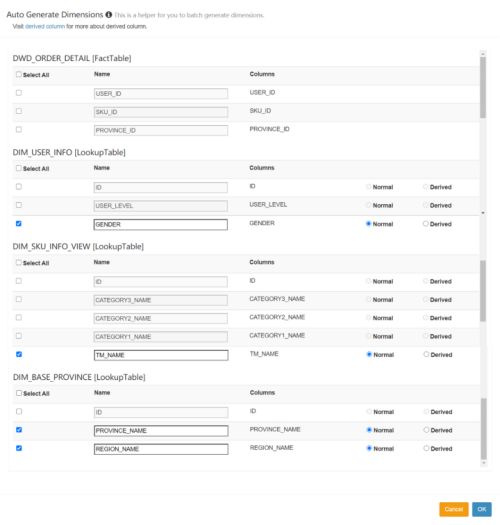
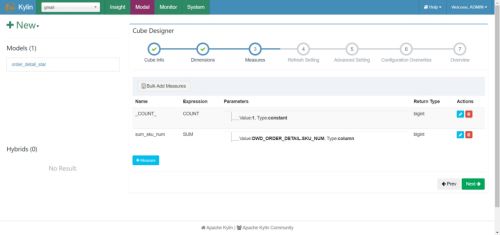
(4)选择所需度量值,如下图所示

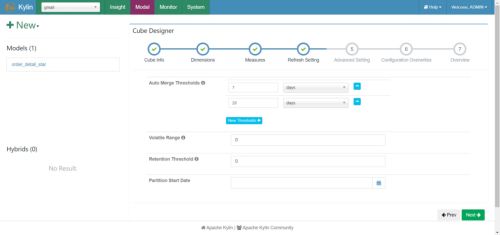
(5)cube自动合并设置,cube需按照日期分区字段每天进行构建,每次构建的结果会保存在Hbase中的一张表内,为提高查询效率,需将每日的cube进行合并,此处可设置合并周期。
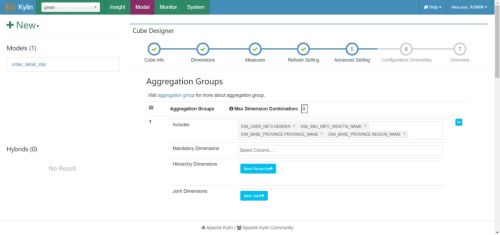
(6)Kylin高级配置(优化相关,暂时跳过,后面构建优化会说)
(7)Kylin相关属性配置覆盖
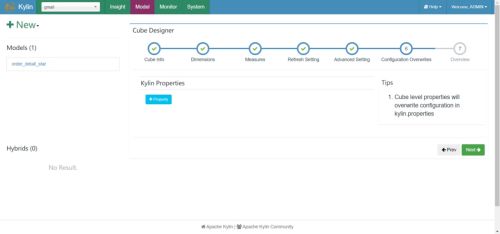
(8)Cube信息总览,点击Save,Cube创建完成
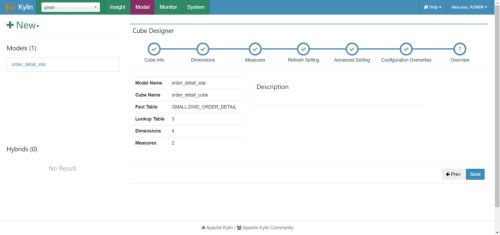
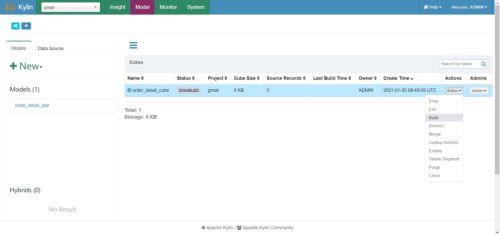
(9)构建Cube(计算),点击对应Cube的action按钮,选择build
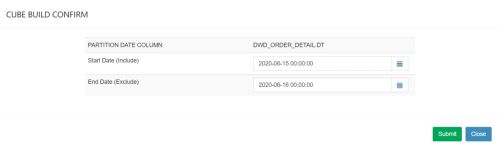
(10)选择要构建的时间区间,点击Submit
(11)点击Monitor查看构建进度
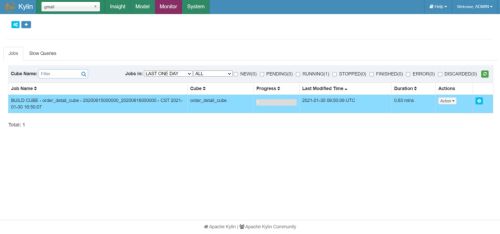
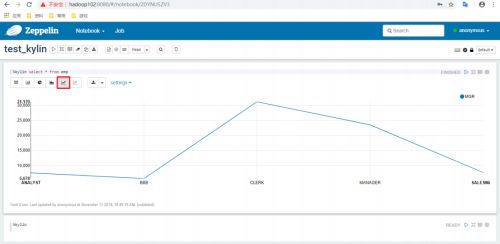
查询
以下展示的例子不一样,知道这样做就行。
(1)进入 Insight 页面
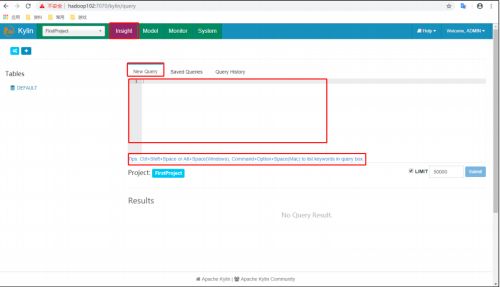
(2)在 New Query 中输入查询语句并 Submit
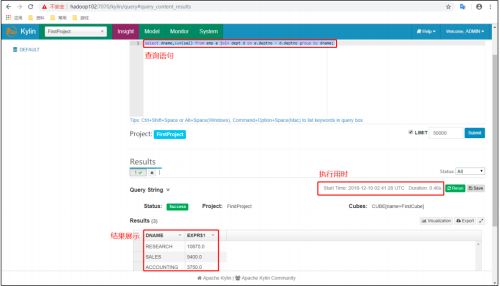
(3)数据图表展示及导出
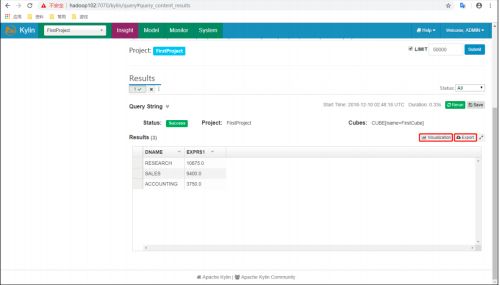
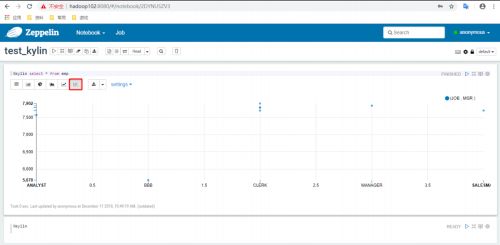
(4)图表展示之条形图
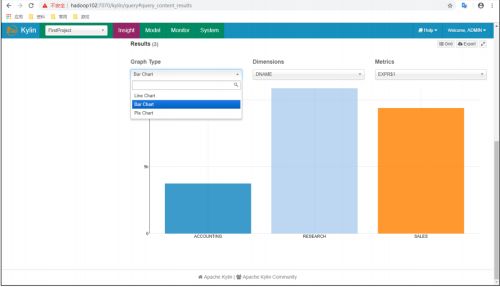
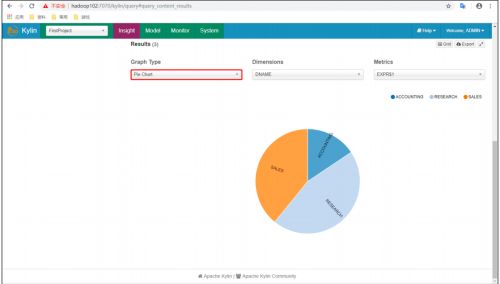
(5)图表展示之饼图
每日自动构建cube
Kylin提供了Restful API,因次我们可以将构建cube的命令写到脚本中,将脚本交给azkaban或者oozie这样的调度工具,以实现定时调度的功能。
脚本如下:
#!/bin/bash
cube_name=order_cube
do_date=`date -d '-1 day' +%F`
#获取00:00时间戳
start_date_unix=`date -d "$do_date 08:00:00" +%s`
start_date=$(($start_date_unix*1000))
#获取24:00的时间戳
stop_date=$(($start_date+86400000))
curl -X PUT -H "Authorization: Basic QURNSU46S1lMSU4=" -H 'Content-Type: application/json' -d '{"startTime":'$start_date', "endTime":'$stop_date', "buildType":"BUILD"}' http://hadoop102:7070/kylin/api/cubes/$cube_name/build
Kylin 使用注意事项
每日全量维度表及拉链维度表重复Key问题处理
按照上述流程,会发现,在cube构建流程中出现以下错误:

错误原因分析:
上述错误原因是model中的维度表dim_user_info为拉链表、dim_sku_info(dim_sku_info_view)为每日全量表,故使用整张表作为维度表,必然会出现订单明细表中同一个user_id或者sku_id对应多条数据的问题,针对上述问题,有以下解决方案。
在hive客户端为拉链表以及每日全量维度表创建视图,在创建视图时对数据加以过滤,保证从视图中查出的数据是一份全量最新的数据即可。
(1)创建维度表视图
--拉链维度表视图
create view dim_user_info_view as select * from dim_user_info where dt='9999-99-99';
--全量维度表视图(注意排除复杂数据类型字段)
create view dim_sku_info_view
as
select
id,
price,
sku_name,
sku_desc,
weight,
is_sale,
spu_id,
spu_name,
category3_id,
category3_name,
category2_id,
category2_name,
category1_id,
category1_name,
tm_id,
tm_name,
create_time
from dim_sku_info
where dt=date_add(current_date,-1);
--当前情形我们先创建一个2020-06-15的视图,由于之前已经创建了dim_sku_info_view,故无需重新创建,修改之前的视图即可。
alter view dim_sku_info_view
as
select
id,
price,
sku_name,
sku_desc,
weight,
is_sale,
spu_id,
spu_name,
category3_id,
category3_name,
category2_id,
category2_name,
category1_id,
category1_name,
tm_id,
tm_name,
create_time
from dim_sku_info
where dt='2020-06-15';
(2)在DataSource中导入新创建的视图,之前的维度表,可选择性删除。
(3)重新创建model、cube。
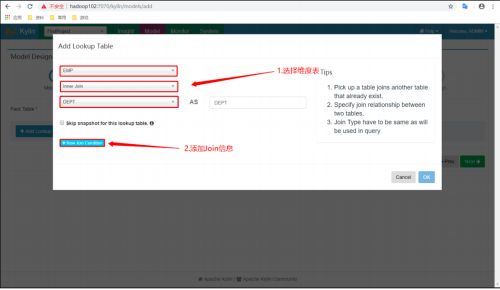
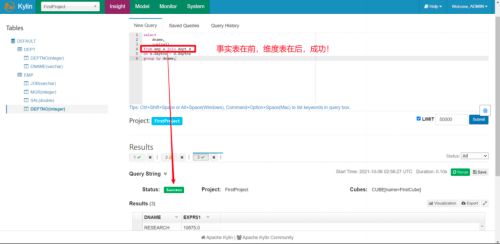
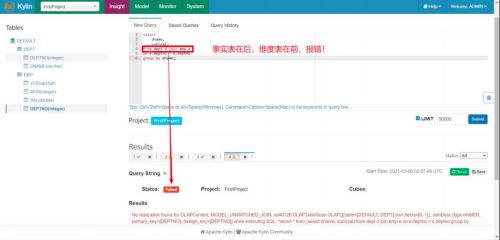
只能按照构建 Model 的连接条件来写 SQL
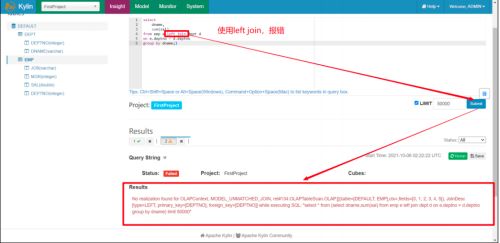
因为在创建 Model 的时候,我们对员工表和部门表选用的是 Inner Join 内连接。
因此我们在使用 Kylin 查询的时候,也只能用 join 内连接,其他连接会报错。
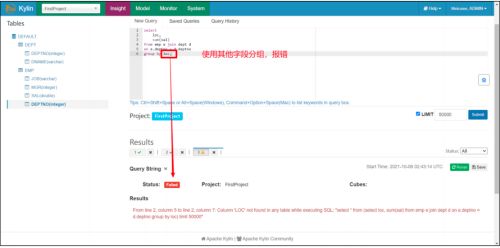
只能按照构建 Cube 时选择的维度字段分组统计
我们在构建 Cube 时,选择了四个维度字段 JOB,MGR,DEPTNO,DNAME。
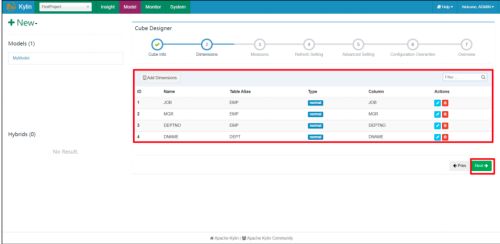
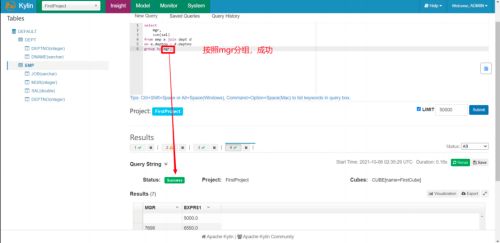
所以我们在使用 Kylin 查询的时候,只能按照这四个为的字段进行 Group By 分组统计,使用其他字段,一定会报错!

只能统计构建 Cube 时选择的度量值字段
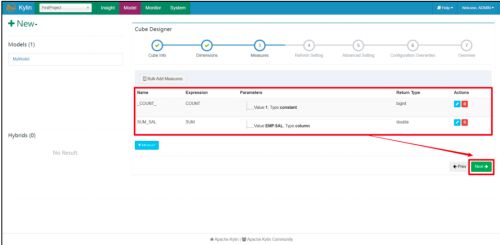
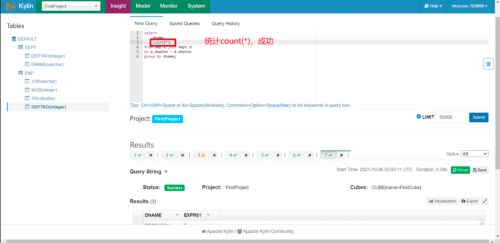
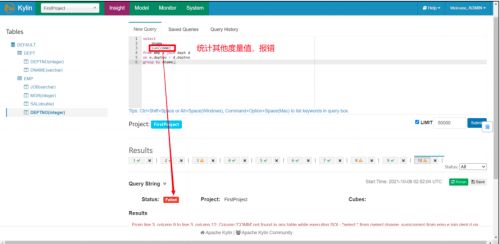
我们构建 Cube 时,只添加了一个 SUM(SAL)的度量值,然后加上默认的 COUNT(*),一共有两个度量值,因此我们只可以利用 Kylin 求这两个度量值,求其他报错。

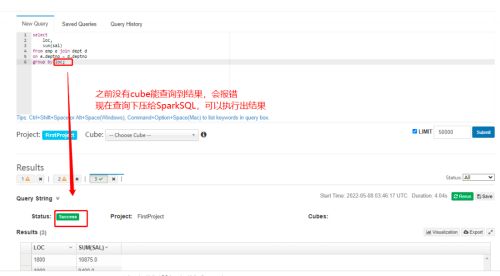
Kylin 设置查询下压
对于没有 cube 能查得结果的 sql,Kylin4.0 支持将这类查询下压至 SparkSql 去查询 Hive 源数据。
(1)设置参数开启
vim /opt/module/kylin-4.0.1/conf/kylin.properties
kylin.query.pushdown.runner-class-name=org.apache.kylin.query.pushdown.PushDownRunnerSparkImpl
(2)页面刷新配置
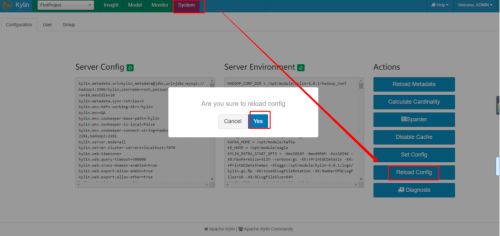
(3)执行没有 cube 对应的查询
Kylin4.0 查询引擎
查询引擎 Sparder
Sparder(SparderContext)是由 Spark application 后端实现的新型分布式查询引擎,它是作为一个 Long-running 的 Spark application 存在的。Sparder 会根据 kylin.query.spark-conf 开头的配置项中配置的 Spark 参数来获取 Yarn 资源,如果配置的资源参数过大,可能会影响构建任务甚至无法成功启动 Sparder,如果 Sparder 没有成功启动,则所有查询任务都会失败,因此请在 Kylin 的 WebUI 中检查 Sparder 状态,不过默认情况下,用于查询的 spark 参数会设置的比较小,在生产环境中,大家可以适当把这些参数调大一些,以提升查询性能。
kylin.query.auto-sparder-context-enabled-enabled 参数用于控制是否在启动 kylin 的同时启动 Sparder,默认值为 false,即默认情况下会在执行第一条 SQL 的时候才启动 Sparder,因此 Kylin 的第一条 SQL 查询速度一般比较慢,因为包含了 Sparder 任务的启动时间。
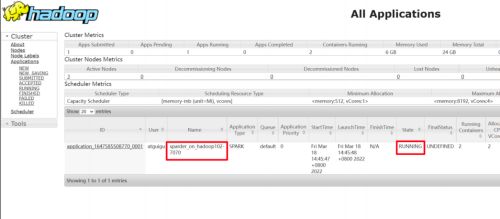
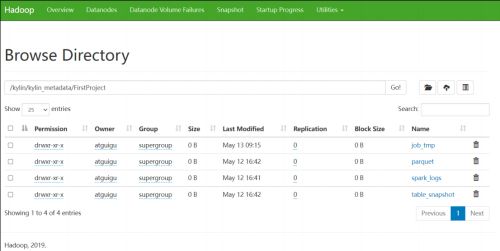
HDFS 存储目录
根目录:/kylin/kylin_metadata
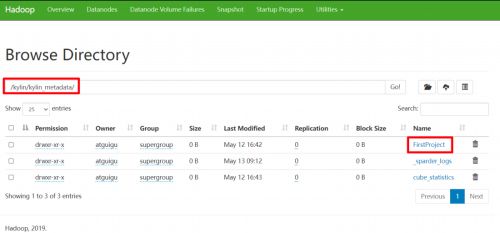
子目录:
- 临时文件存储目录:/project_name/job_tmp
- Cuboid 文件存储目录: /project_name /parquet/cube_name/segment_name_XXX
- 维度表快照存储目录:/project_name /table_snapshot
- Spark 运行日志目录:/project_name/spark_logs
查询参数汇总
Kylin 查询参数全部以 kylin.query.spark-conf 开头,默认情况下,用于查询的 spark 参数会设置的比较小,在生产环境中,大家可以适当把这些参数调大一些,以提升查询性能。
####spark 运行模式####
#kylin.query.spark-conf.spark.master=yarn
####spark driver 核心数####
#kylin.query.spark-conf.spark.driver.cores=1
####spark driver 运行内存####
#kylin.query.spark-conf.spark.driver.memory=4G
####spark driver 运行堆外内存####
#kylin.query.spark-conf.spark.driver.memoryOverhead=1G
####spark executor 核心数####
#kylin.query.spark-conf.spark.executor.cores=1
####spark executor 个数####
#kylin.query.spark-conf.spark.executor.instances=1
####spark executor 运行内存####
#kylin.query.spark-conf.spark.executor.memory=4G
####spark executor 运行堆外内存####
#kylin.query.spark-conf.spark.executor.memoryOverhead=1G
Cube构建原理
维度和度量
维度:即观察数据的角度。比如员工数据,可以从性别角度来分析,也可以更加细化,从入职时间或者地区的维度来观察。维度是一组离散的值,比如说性别中的男和女,或者时间维度上的每一个独立的日期。因此在统计时可以将维度值相同的记录聚合在一起,然后应用聚合函数做累加、平均、最大和最小值等聚合计算。
度量:即被聚合(观察)的统计值,也就是聚合运算的结果。比如说员工数据中不同性别员工的人数,又或者说在同一年入职的员工有多少。
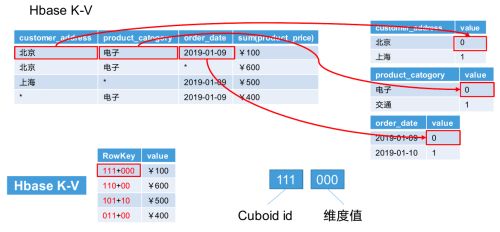
Cube、Cuboid、Segment
有了维度跟度量,一个数据表或者数据模型上的所有字段就可以分类了,它们要么是维度,要么是度量(可以被聚合)。于是就有了根据维度和度量做预计算的Cube理论。
给定一个数据模型,我们可以对其上的所有维度进行聚合,对于N个维度来说,组合的所有可能性共有2^(n)种。对于每一种维度的组合,将度量值做聚合计算,然后将结果保存为一个物化视图,称为Cuboid。所有维度组合的Cuboid作为一个整体,称为Cube。
下面举一个简单的例子说明,假设有一个电商的销售数据集,其中维度包括时间[time]、商品[item]、地区[location]和供应商[supplier],度量为销售额。那么所有维度的组合就有2⁴ = 16种,如下图所示:
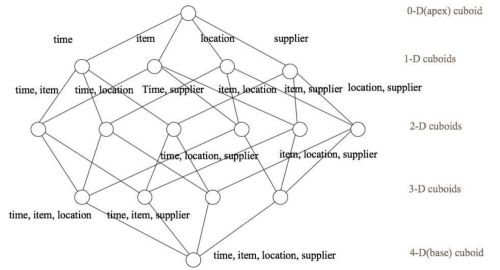
- 一维度(1D)的组合有:[time]、[item]、[location]和[supplier]4种;
- 二维度(2D)的组合有:[time, item]、[time, location]、[time, supplier]、[item, location]、[item, supplier]、[location, supplier]3种;
- 三维度(3D)的组合也有4种;
- 最后还有零维度(0D)和四维度(4D)各有一种,总共16种。
注意:每一种维度组合就是一个Cuboid,16个Cuboid整体就是一个Cube。
Kylin将Cube划分为多个Segment(对应就是HBase中的一个表),每个Segment用起始时间和结束时间来标志。Segment代表一段时间内源数据的预计算结果。一个Segment的起始时间等于它之前那个Segment的结束时间,同理,它的结束时间等于它后面那个Segment的起始时间。同一个Cube下不同的Segment除了背后的源数据不同之外,其他如结构定义、构建过程、优化方法、存储方式等都完全相同。
一个Cube,可以包含多个Cuboid,而Segment是指定时间范围的Cube,可以理解为Cube的分区。对应就是HBase中的一张表,该表中包含了所有的Cuboid。
例如:以下为针对某个Cube的Segment:
| Segment名称 | 分区时间 | HBase表名 |
|---|---|---|
| 201910110000000-201910120000000 | 20191011 | KYLIN_41Z8123 |
| 201910120000000-201910130000000 | 20191012 | KYLIN_5AB2141 |
| 201910130000000-201910140000000 | 20191013 | KYLIN_7C1151 |
| 201910140000000-201910150000000 | 20191014 | KYLIN_811680 |
| 201910150000000-201910160000000 | 20191015 | KYLIN_A11AD1 |
Cube构建算法
(1)逐层构建算法(layer)

我们知道,一个N维的Cube,是由1个N维子立方体、N个(N-1)维子立方体、N*(N-1)/2个(N-2)维子立方体、…、N个1维子立方体和1个0维子立方体构成,总共有 2 N 2^N 2N个子立方体组成,在逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。比如,[Group by A, B]的结果,可以基于[Group by A, B, C]的结果,通过去掉C后聚合得来的;这样可以减少重复计算;当 0维度Cuboid计算出来的时候,整个Cube的计算也就完成了。
每一轮的计算都是一个MapReduce任务,且串行执行;一个N维的Cube,至少需要N次MapReduce Job。
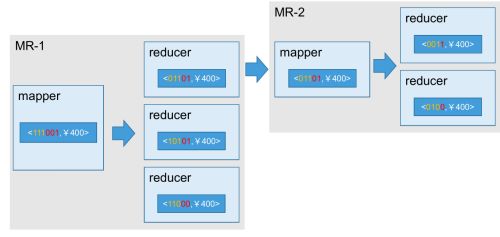
算法优点:
- 此算法充分利用了MapReduce的优点,处理了中间复杂的排序和shuffle工作,故而算法代码清晰简单,易于维护;
- 受益于Hadoop的日趋成熟,此算法非常稳定,即便是集群资源紧张时,也能保证最终能够完成。
算法缺点:
- 当Cube有比较多维度的时候,所需要的MapReduce任务也相应增加;由于Hadoop的任务调度需要耗费额外资源,特别是集群较庞大的时候,反复递交任务造成的额外开销会相当可观;
- 由于Mapper逻辑中并未进行聚合操作,所以每轮MR的shuffle工作量都很大,导致效率低下。
- 对HDFS的读写操作较多:由于每一层计算的输出会用做下一层计算的输入,这些Key-Value需要写到HDFS上;当所有计算都完成后,Kylin还需要额外的一轮任务将这些文件转成HBase的HFile格式,以导入到HBase中去;
总体而言,该算法的效率较低,尤其是当Cube维度数较大的时候。
(2)快速构建算法(inmem)
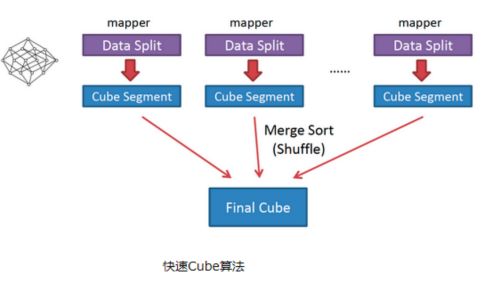
也被称作“逐段”(By Segment) 或“逐块”(By Split) 算法,从1.5.x开始引入该算法,该算法的主要思想是,每个Mapper将其所分配到的数据块,计算成一个完整的小Cube 段(包含所有Cuboid)。每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果。如图所示解释了此流程。
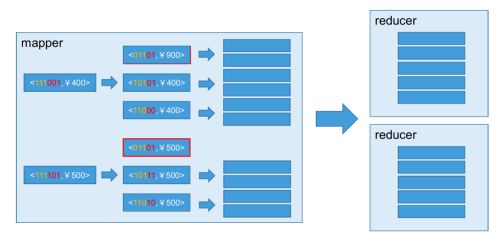
与旧算法相比,快速算法主要有两点不同:
- Mapper会利用内存做预聚合,算出所有组合;Mapper输出的每个Key都是不同的,这样会减少输出到Hadoop MapReduce的数据量,Combiner也不再需要;
- 一轮MapReduce便会完成所有层次的计算,减少Hadoop任务的调配。
Cube存储原理
去重原理(※)
去重方法
在 OLAP 数据分析领域,去重计数(count distinct)是非常常见的需求(这可以作为一个度量),根据去重结果的要求分为近似去重和精确去重(在Kylin中,可以自行选择):
-
Kylin的近似去重计数是基于HLL(HyperLogLog)来实现。
简单来说,每个需要被计数的值都会经过特定Hash函数的计算,将得到的哈希值放入到byte数组中,最后根据特定算法对byte数据的内容进行统计,就可以得到近似的去重结果。
这种方式的好处是,不论数据有多少,byte数组的大小是有理论上限的,通常不会超过128KB,存储压力非常小。也就是说能够满足超大数据集和快速响应的要求。
但最大的问题就是结果是非精确的,这是因为保存的都是经过hash计算的值,而一旦使用hash就一定会有冲突,这就是导致结果不精确的直接原因。此外在实践中发现,hash函数的计算是计算密集型的任务,需要大量的CPU资源。
-
对于精确去重,最常用的处理方法是 bit map 方法。对于整型数据,我们可以将这些整数直接保存到 bit map 中。但除了整型之外,还有其他类型,如 String,为了实现精确的重复数据删除,我们首先需要对这些数据建立一个字典进行统一映射,然后使用 bit map 方法进行统计。
目前业界有很多成熟的bitmap库可用,比如RoaringBitmap,ConciseSet等,其中RoaringBitmap的读写速度最快,存储效率也很高,目前已经在Spark,Drill等开源项目中使用,因此Kylin也选择了RoaringBitmap。经过试验,证明了想法是可行的,通过实现一种新的基于bitmap的去重计算指标,确实能够实现对Int型数据的精确去重计数。在百万量级的数据量下,存储的结果可以控制在几兆,同时查询能够在秒级内完成,且可以支持任意粒度的上卷聚合计算。
精确去重的原理
精确去重指标实现的两个核心难点:
- 支持任意粒度的上卷聚合
- 支持String等非Int类型数据
难点的解决方案:
- 前面提到,为了支持任意粒度的上卷聚合,我们需要保留明细数据,而计算机存储的最小单位是bit,所以采用了Bitmap来存储Kylin的精确去重指标。Kylin在实际工程中采用的是业界中广泛使用, 性难最优的RoaringBitmap库。
- RoaringBitmap仅支持Int类型数据,为了支持String等非Int类型数据,我们需要一个String到Int的映射,而且要求所有Segment中同一个String始终映射到同一个Int。 为什么呢? 假如UUID列的String “A” 在Segment1中映射到Int 1,但是String “A” 却在Segment2中映射到INT 2,那么当UUID列需要跨Segment1和Segment2去重时,显然就会出错。 所以我们引入了全局字典,来保证String等非Int类型数据始终映射到同一个Int值。
无需上卷的精确去重查询优化:
前面提到,为了支持任意粒度的上卷聚合,我们使用Bitmap存储精确去重指标。所以在查询时,我们需要先从HBase端将整个Bitmap传输给Kylin的QueryServer,Kylin的QueryServr再根据Bitmap计算出 去重值。但是在实际的使用场景中,用户的一些甚至多数精确去重查询是不需要上卷聚合的, 比如用户的Cube按照dt列分区,且已经预计算好(A,dt)的Cuboid,那么下面的SQL查询时在HBase端和Kylin的QueryServer端都是无需聚合的:
RoaringBitmap
RoaringBitmap是高效压缩位图,简称RBM。
RBM的历史并不长,它于2016年由S. Chambi、D. Lemire、O. Kaser等人在论文《Better bitmap performance with Roaring bitmaps》与《Consistently faster and smaller compressed bitmaps with Roaring》中提出.
实现思路
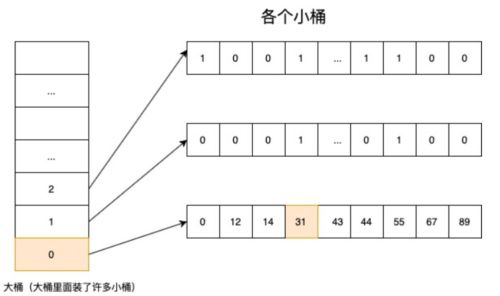
- 将 32bit int(无符号的)类型数据 划分为 2^16 个桶,即最多可能有216=65536个桶,论文内称为container。用container来存放一个数值的低16位;
- 在存储和查询数值时,将数值 k 划分为高 16 位和低 16 位,取高 16 位值找到对应的桶,然后在将低 16 位值存放在相应的 Container 中(存储时如果找不到就会新建一个)
比如要将31这个数放进roarigbitmap中,它的16进制为:0000001F,前16位为0000,后16为001F。
所以先需要根据前16位的值:0,找到它对应的通的编号为0,然后根据后16位的值:31,确定这个值应该放到桶中的哪一个位置,如下图所示。
小桶的类型
在roaringbitmap中共有3种小桶:
- arraycontainer(数组容器)
- bitmapcontainer(位图容器)
- runcontainer(行程步长容器)
(1)arraycontainer
当ArrayContainer(其中每一个元素的类型为 short int 占两个字节,且里面的元素都是按从大到小的顺序排列的)的容量超过4096(即8k)后,会自动转成BitmapContainer(这个所占空间始终都是8k)存储。
4096这个阈值很聪明,低于它时ArrayContainer比较省空间,高于它时BitmapContainer比较省空间。也就是说ArrayContainer存储稀疏数据,BitmapContainer存储稠密数据,可以最大限度地避免内存浪费。
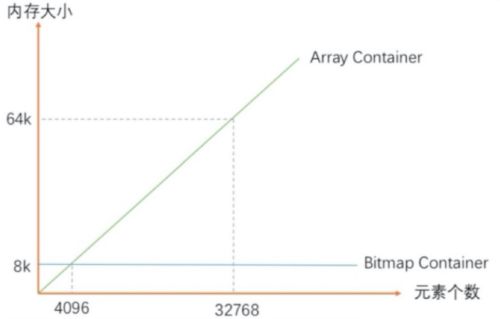
(2)bitmapcontainer
这个容器就是位图,只不过这里位图的位数为216(65536)个,也就是2^16个bit, 所占内存就是8kb。然后每一位用0,1表示这个数不存在或者存在,如下图:

(3)runcontainer
RunContainer中的Run指的是行程长度压缩算法(Run Length Encoding),对连续数据有比较好的压缩效果。
它的原理是,对于连续出现的数字,只记录初始数字和后续数量。即:
- 对于数列11,它会压缩为11,0;
- 对于数列11,12,13,14,15,它会压缩为11,4;
- 对于数列11,12,13,14,15,21,22,它会压缩为11,4,21,1;
不过这种容器不常用,所以在使用的时候需要自行调用相关的转换函数来判断是不是需要将arraycontiner,或bitmapcontainer转换为runcontainer。
这种压缩算法的性能和数据的连续性(紧凑性)关系极为密切,对于连续的100个short,它能从200字节压缩为4字节,但对于完全不连续的100个short,编码完之后反而会从200字节变为400字节。
如果要分析RunContainer的容量,我们可以做下面两种极端的假设:
- 最好情况,即只存在一个数据或只存在一串连续数字,那么只会存储2个short,占用4字节
- 最坏情况,0~65535的范围内填充所有的奇数位(或所有偶数位),需要存储65536个short,128kb
(4)读取性能
增删改查的时间复杂度方面,BitmapContainer只涉及到位运算且可以根据下标直接寻址,显然为O(1)。而ArrayContainer和RunContainer都需要用二分查找在有序数组中定位元素,故为O(logN)。
- ArrayContainer一直线性增长,在达到4096后就完全比不上BitmapContainer了
- BitmapContainer是一条横线,始终占用8kb
- RunContainer比较奇葩,因为和数据的连续性关系太大,因此只能画出一个上下限范围。不管数据量多少,下限始终是4字节;上限在最极端的情况下可以达到128kb。
空间占用(即序列化时写出的字节流长度)方面,BitmapContainer是恒定为8KB的。ArrayContainer的空间占用与基数(c)有关,为(2 + 2c)B;RunContainer的则与它存储的连续序列数(r)有关,为(2 + 4r)B。
与bitmap的性能对比
roaringbitmap除了比bitmap占用内存少之外,其并集和交集操作的速度也要比bitmap的快,原因如下:
-
计算上的优化:
-
对于roaringbitmap本质上是将大块的bitmap分成各个小块,其中每个小块在需要存储数据的时候才会存在。所以当进行交集或并集运算的时候,roaringbitmap只需要去计算存在的一些块而不需要像bitmap那样对整个大的块进行计算。如果块内非常稀疏,那么只需要对这些小整数列表进行集合的 AND、OR 运算,这样的话计算量还能继续减轻。这里既不是用空间换时间,也没有用时间换空间,而是用逻辑的复杂度同时换取了空间和时间。
-
同时在roaringbitmap中32位长的数据,被分割成高 16 位和低 16 位,高 16 位表示块偏移,低16位表示块内位置,单个块可以表达 64k 的位长,也就是 8K 字节。这样可以保证单个块都可以全部放入 L1 Cache,可以显著提升性能。
-
-
程序逻辑上的优化:
- roaringbitmap维护了排好序的一级索引以及有序的arraycontainer,当进行交集操作的时候,只需要根据一级索引中对应的值来获取需要合并的容器,而不需要合并的容器则不需要对其进行操作直接过滤掉。
- 当进行合并的arraycontainer中数据个数相差过大的时候采用基于二分查找的方法对arraycontainer求交集,避免不必要的线性合并花费的时间开销。
- roaingbitmap在做并集的时候同样根据一级索引只对相同的索引的容器进行合并操作,而索引不同的直接添加到新的roaringbitmap上即可,不需要遍历容器。
- roaringbitmap在合并容器的时候会先预测结果,生成对应的容器,避免不必要的容器转换操作。
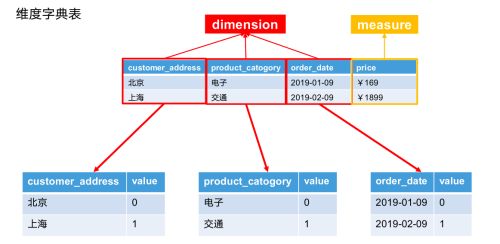
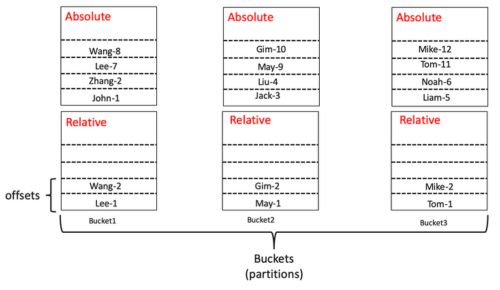
全局字典介绍
在Apache Kylin的现有实现中,Cube的每个Segment都会创建独立的字典,这种方式会导致相同数据在不同Segment字典中被映射成不同的值,这会导致最终的去重结果出错。
为此,在 Cube 的增量构建过程中,为了避免由于对不同时间段分别构造字典而导致最终去重结果出现错误,一个 Cube 中的所有 segments 将使用同一个字典,即全局字典。全局字典的意义是保证所有Value映射到全局唯一且连续的Int ID 。
具体来说,根据字典的资源路径(元数据名+库名+表名+列名)可以从元数据中获取同一个字典实例,后续的数据追加也是基于这个唯一的字典实例创建的builder进行的。
全局字典最重要的意义是支持精确去重指标跨Segment上卷,但在某些应用场景下,用户的确不需要Segment上卷。 比如用户只需要按天进行去重,或者Cube本身就是不分区的(每次全量构建)。 针对这一点,新增了一种SegmentAppendTrieDictBuilder(前面提到的Segment Dictionary ),底层的数据结构依然还是AppendTrieDictionary,只是每次构建时Working目录不是Copy最新的Version目录,而是从空Working目录开始构建,同时字典的元数据也需要重新初始化。由于SegmentAppendTrieDictBuilder是segment粒度的,也不需要分布式锁,所以可以并发构建。使用SegmentAppendTrieDictBuilder后构建和加载时的内存问题也基本不会再有。
原理:
- 每个构建任务都将生成一个新的全局字典;
- 每个新的构建任务的字典会根据版本号保存,旧的全局字典会逐渐删除;
- 一个全局字典包含一个元数据文件和多个字典文件,每个字典文件称为一个 bucket (bucket);
- 每个 bucket 被划分为两个映射(Map
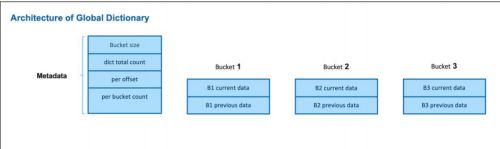
Kylin引入了桶这一概念,可以理解为在处理数据的时候,将数据分到若干个桶(即多个分区)中进行并行处理。 第一次构建字典的时候会对每个桶内的值从1开始编码,在所有桶的编码完成之后再根据每个桶的offset值进行整体字典值的分配。在代码中两次编码是通过两个HashMap进行存储的,其中一个存储桶内相对的字典值,另一个存储所有桶之间绝对的字典值。
下图所示的是编号为1的桶多次构建任务中,桶内字典的传递,每一次构建都会为桶创建一个新的版本(即v1, v2, v3等),加入版本控制的原因后面会有解释。Curr(current)和Prev(Previous)是一个桶内的两个HashMap,分别存储着当前桶内字典的相对(Relative)编码值和之前已经构建的所有字典值的绝对(Absolute)编码值。
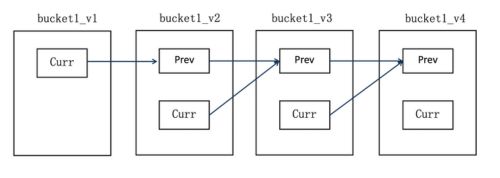
构建步骤:
- 通过 Spark 创建平表并获取需精确去重列的 distinct 值
- 根据确定去重后的字面值数量来确认分片数, 并且根据需求判断是否需要扩容
- 将数据分配(repartition)到多个分片(Partition)中,分别进行编码, 存储到各自的字典文件中
- 为当前构建任务分配版本号
- 保存字典文件和 metadata数据(桶数量和桶的 offset 值)
- 根据条件判断需要删除旧版本
初次构建:
- 计算桶的大小:取需要构建字典的数量处理 单个桶阈值 和 桶数量默认值 的最大值。
- 创建桶并分配数据进行编码
- 生成meta文件记录桶的offsets
以下是相关配置项及其默认值:
kylin.dictionary.globalV2-min-hash-partitions=10
kylin.dictionary.globalV2-threshold-bucket-size=500000
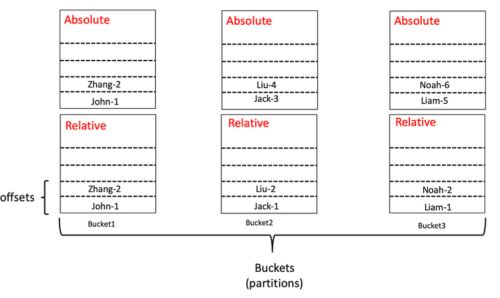
非初次构建:
- 根据字典数量确定桶是否需要扩容
- 已编码的字典值对扩容后的桶进行重新分配
- 读取之前最新版本的字典数据,并分配到各个桶中
- 将新的值分配到桶中
- 前一次构建的字典值不会改变
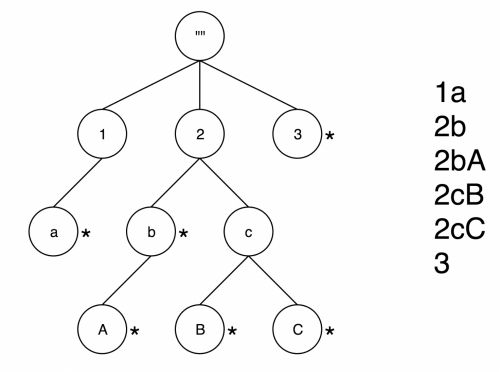
Trie树与AppendTrie树
在全局字典中,映射关系有很多种实现方式,比如基于格式的编码,hash编码等,其中空间和性能效率都比较高,且通用性更强的是基于Trie树的字典编码方式。目前Apache Kylin之前已经实现了TrieDictionary,用于维度值的编码。
Trie树又名前缀树,是是一种有序树,一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,根节点对应空字符串,而每个字符串对应的编码值由对应节点在树中的位置来决定。图1是一棵典型的Trie树示意图,注意并不是每个节点都有对应的字符串值。
在构造Trie树时,将每个值依次加入到树中,可以分为三种情况,如图所示:
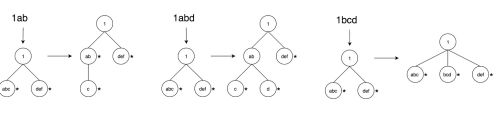
上述的是Trie树在构建过程中的内存模型,当所有数据加入之后,需要将整棵Trie树的数据序列化并持久化。具体的格式如图所示:
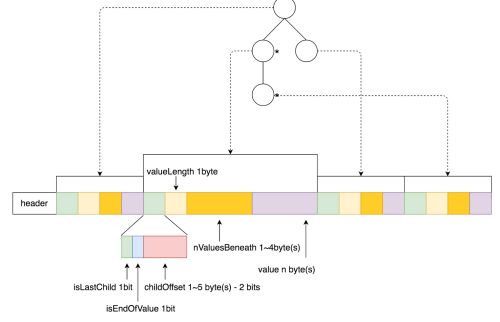
从上图中可以按照,整棵树按照广度优先的顺序依次序列化,其中childOffset和nValuesBeneath的长度是可变的,这是为了根据整棵树的大小尽可能使用更短的数据,降低存储量。此外需要注意到,childOffset的最高两位是标志位,分别标识当前节点是否是最后一个child,以及当前节点是否对应了原始数据的一个值。
当需要从字典中检索某个值的映射id时,直接从序列化后的数据读取即可,不需要反序列化整棵Trie树,这样能在保证检索速度的同时保持较低的内存用量。整个过程如图所示。
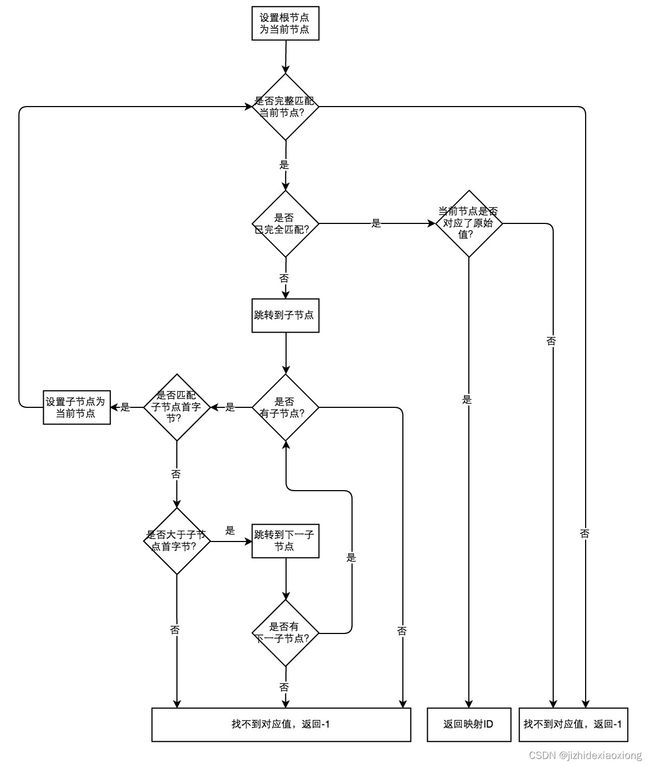
通过上述对Trie树的分析可以看到,Trie树的效率很高,但有一个问题,Trie树的内容是不可变的。也就是说,当一颗Trie树构建完成后,不能再追加新的数据进去,也不能删除现有数据,这是因为每个原始数据对应的映射id是由对应节点在树中的位置决定的,一旦树的结构发生变化,那么会导致部分原始数据的映射id发生变化,从而导致错误的结果。为此,我们需要对Trie树进行改造,使之能够持续追加数据,也就是AppendTrie树。
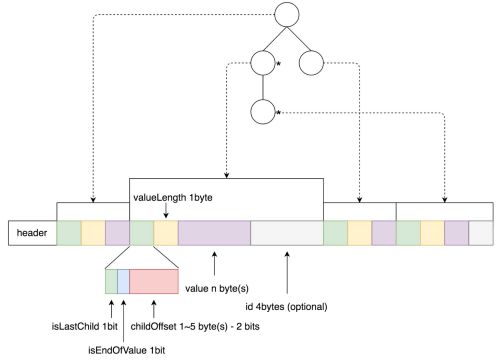
下图是AppendTrie的序列化格式,可以看到和传统Trie树相比,主要区别在于不保留每个节点的子value数,转而将节点对应的映射id保存到序列化数据中,这样虽然增大了存储空间,但使得整棵树是可以追加的,而且同时也导致了AppendTrieDictionary只能根据Value查找Id,不能根据Id查找Value。。
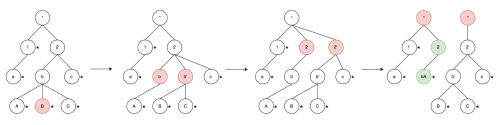
经过改造,AppendTrie树已经满足了我们的需求,能够支持我们实现对所有数据的统一编码,进而支持精确去重计数。但从实际情况来看,当统计的数据量超过千万时,整颗树的内存占用和序列化数据都会变得很大,因此需要考虑分片,将整颗树拆成多颗子树,通过控制每颗子树的大小,来实现整棵树的容量扩展。为了实现这个目标,当一棵树的大小超过设定阈值后,需要通过分裂算法将一棵树分裂成两棵子树,下图展示了整个过程。
在一棵AppendTrie树是由多棵子树构成的基础上,我们很容易想到通过LRU之类的算法来控制所有子树的加载和淘汰行为。为此我们基于guava的LoadingCache实现了特定的数据结构CachedTreeMap。这种map继承于TreeMap,同时value通过LoadingCache管理,可以根据策略加载或换出,从而在保证功能的前提下降低了整体的内存占用。
此外,为了支持字典数据的读写并发,数据持久化采用mvcc的理念,每次构建持久化的结果作为一个版本,版本一旦生成就不可再更改,后续更新必须复制版本数据后进行,并持久化为更新的版本。每次读取时则选择当前最新的版本读取,这样就避免了读写冲突。同时设置了基于版本个数和存活时间的版本淘汰机制,保证不会占用过多存储。
经过上述的改进和优化后,AppendTrie树完全达到了我们的要求,可以对所有类型的数据统一做映射编码,支持的数据量可以到几十亿甚至更多,且保持内存占用量的可控,这就是我们的可追加通用字典AppendTrieDictionary。
分布式环境下数据一致性的保证:
- MVCC: 全局字典最终是持久化在HDFS目录上,为了避免读写冲突,我们采用了MVCC,当读AppendTrieDictionary时,永远只读取最新的Version目录;当写AppendTrieDictionary时,会将最新的Verion目录copy到working目录,修改完成且通过正确性校验后,会将working目录rename为新的Version目录。
- 分布式锁:通过分布式锁,我们保证了在多JobServer的多Segment并发构建下,1个Kylin集群在同一时刻只会有1个线程可以修改AppendTrieDictionary。
参考:
- https://blog.bcmeng.com/post/kylin-distinct-count-global-dict.html
- https://hexiaoqiao.github.io/blog/2016/11/27/exact-count-and-global-dictionary-of-apache-kylin/
Cube构建优化
衍生维度(derived dimension)
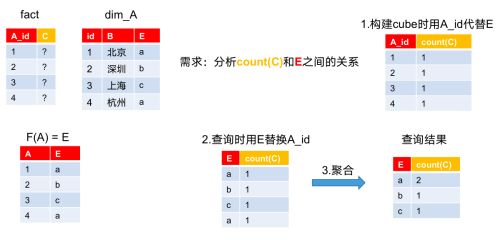
衍生维度用于在有效维度内将维度表上的非主键维度排除掉,并使用维度表的主键(其实是事实表上相应的外键)来替代它们。Kylin会在底层记录维度表主键与维度表其他维度之间的映射关系,以便在查询时能够动态地将维度表的主键“翻译”成这些非主键维度,并进行实时聚合。
虽然衍生维度具有非常大的吸引力,但这也并不是说所有维度表上的维度都得变成衍生维度,如果从维度表主键到某个维度表维度所需要的聚合工作量非常大,则不建议使用衍生维度。
聚合组(Aggregation group)
聚合组(Aggregation Group)是一种强大的剪枝工具。聚合组假设一个Cube的所有维度均可以根据业务需求划分成若干组(当然也可以是一个组),由于同一个组内的维度更可能同时被同一个查询用到,因此会表现出更加紧密的内在关联。每个分组的维度集合均是Cube所有维度的一个子集,不同的分组各自拥有一套维度集合,它们可能与其他分组有相同的维度,也可能没有相同的维度。每个分组各自独立地根据自身的规则贡献出一批需要被物化的Cuboid,所有分组贡献的Cuboid的并集就成为了当前Cube中所有需要物化的Cuboid的集合。不同的分组有可能会贡献出相同的Cuboid,构建引擎会察觉到这点,并且保证每一个Cuboid无论在多少个分组中出现,它都只会被物化一次。
对于每个分组内部的维度,用户可以使用如下三种可选的方式定义,它们之间的关系,具体如下。
(1)强制维度(Mandatory),如果一个维度被定义为强制维度,那么这个分组产生的所有Cuboid中每一个Cuboid都会包含该维度。每个分组中都可以有0个、1个或多个强制维度。如果根据这个分组的业务逻辑,则相关的查询一定会在过滤条件或分组条件中,因此可以在该分组中把该维度设置为强制维度。
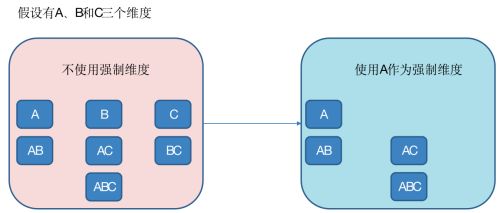
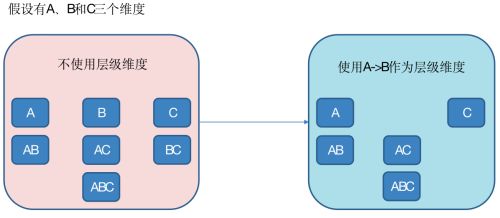
(2)层级维度(Hierarchy),每个层级包含两个或更多个维度,相当于最左前缀。假设一个层级中包含D1,D2…Dn这n个维度,那么在该分组产生的任何Cuboid中, 这n个维度只会以(),(D1),(D1,D2)…(D1,D2…Dn)这n+1种形式中的一种出现。每个分组中可以有0个、1个或多个层级,不同的层级之间不应当有共享的维度。如果根据这个分组的业务逻辑,则多个维度直接存在层级关系,因此可以在该分组中把这些维度设置为层级维度。
(3)联合维度(Joint),每个联合中包含两个或更多个维度,如果某些列形成一个联合,那么在该分组产生的任何Cuboid中,这些联合维度要么一起出现,要么都不出现。每个分组中可以有0个或多个联合,但是不同的联合之间不应当有共享的维度(否则它们可以合并成一个联合)。如果根据这个分组的业务逻辑,多个维度在查询中总是同时出现,则可以在该分组中把这些维度设置为联合维度。
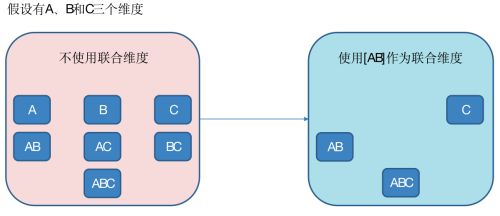
联合维度和强制维度的区别在于,联合维度可以出现也可以不出现,但出现一定得同时出现。
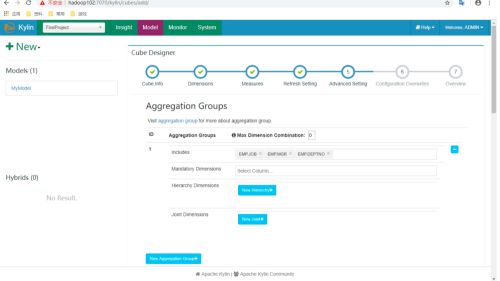
这些操作可以在Cube Designer的Advanced Setting中的Aggregation Groups区域完成,如下图所示。
聚合组的设计非常灵活,甚至可以用来描述一些极端的设计。
- 假设我们的业务需求非常单一,只需要某些特定的Cuboid,那么可以创建多个聚合组,每个聚合组代表一个Cuboid。具体的方法是在聚合组中先包含某个Cuboid所需的所有维度,然后把这些维度都设置为强制维度。这样当前的聚合组就只能产生我们想要的那一个Cuboid了。
- 再比如,有的时候我们的Cube中有一些基数非常大的维度,如果不做特殊处理,它就会和其他的维度进行各种组合,从而产生一大堆包含它的Cuboid。包含高基数维度的Cuboid在行数和体积上往往非常庞大,这会导致整个Cube的膨胀率变大。如果根据业务需求知道这个高基数的维度只会与若干个维度(而不是所有维度)同时被查询到,那么就可以通过聚合组对这个高基数维度做一定的“隔离”。我们把这个高基数的维度放入一个单独的聚合组,再把所有可能会与这个高基数维度一起被查询到的其他维度也放进来。这样,这个高基数的维度就被“隔离”在一个聚合组中了,所有不会与它一起被查询到的维度都没有和它一起出现在任何一个分组中,因此也就不会有多余的Cuboid产生。这点也大大减少了包含该高基数维度的Cuboid的数量,可以有效地控制Cube的膨胀率。
Cube构建参数调优
在 Kylin 4 中,Cube 构建作业中有两个步骤:
- 第一步检测构建为 Cube 数据的源文件;
- 第二步是构建快照表(如果需要),生成全局字典(如果需要),并将 Cube 数据构建为 Parquet文件。
在第二步中,所有计算都是具有相对较重的负载的操作,因此除了使用衍生维度和聚合组来减少 Cube 的数量,使用正确的 Spark 资源和配置来构建 Cube 也非常重要。
使用适当的 Spark 资源和配置来构建 Cube
Kylin 构建参数全部以 kylin.engine.spark-conf 开头,以下表格中的参数省略开头。
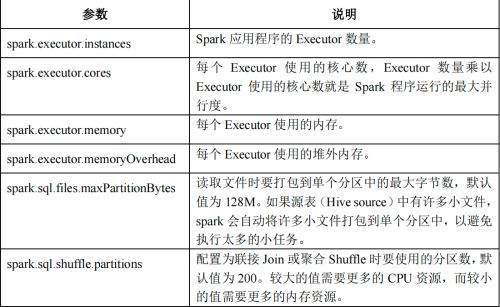
(1)Kylin 根据 Cube 情况自动设置 Spark 参数
Kylin 4 将使用以下分配规则来自动设置 Spark 资源和配置,所有 Spark 资源和配置都是根据源文件中最大文件的大小以及 Cube 是否具有准确的去重计数度量来设置的,这就是为什么我们需要在第一步中检测要构建多少个源文件的原因。
-
Executor 内存规则
如 果 ${ 最 大 文 件 大 小 }>=100G and ${ 存 在 准 确 去 重 度 量 值 }, 设 置’spark.executor.memory’为 20G;
如果${最大文件大小}>=100G or (如果${最大文件大小}>=10G and ${存在准确去重度量值}), 设置 ‘spark.executor.memory’ 为 16G;
如果${最大文件大小}>=10G or (如果${最大文件大小}>=1G and ${存在准确去重度量值}), 设置 ‘spark.executor.memory’ 为 10G;
如果${最大文件大小}>=1G or ${存在准确去重度量值}, 设置 ‘spark.executor.memory’ 为 4G;
否则设置’spark.executor.memory’ 为 1G。
-
Executor 核心数规则
如果${最大文件大小}>=1G or ${存在准确去重度量值},设置 ‘spark.executor.cores’ 为 5;
否则 设置 ‘spark.executor.cores’ to 1。
-
Executor 堆外内存规则
如 果 ${ 最 大 文 件 大 小 }>=100G and ${ 存在准确去重度量值 }, 设 置’spark.executor.memoryOverhead’ 为 6G, 所以这种情况下,每个 Executor 的内存为 20G + 6G = 26G;
如果${最大文件大小}>=100G or (如果${最大文件大小}>=10G and ${存在准确去重度量值}), 设置 'spark.executor.memoryOverhead’为 4G;
如果${最大文件大小}>=10G or (如果${最大文件大小}>=1G and ${存在准确去重度量值}), 设置’spark.executor.memoryOverhead’ 为 2G;
如 果 ${ 最 大 文 件 大 小 }>=1G or ${ 存 在 准 确 去 重 度 量 值 }, 设 置’spark.executor.memoryOverhead’ 为 1G;
否则设置 ‘spark.executor.memoryOverhead’ 为 512M。
-
Executor 实例数量规则
①读取参数’kylin.engine.base-executor-instance’的值作为基本 Executor 数量,默认值为 5 。
② 根据 Cuboid 个数来计算所需的 Executor 个数 , 配置文件中 读 取 参 数’kylin.engine.executor-instance-strategy’的值,默认为’100,2,500,3,1000,4’,即 Cuboid 个数为 0-100 时,因数为 1;100-500 时,因数为 2;500-1000 时,因数为 3;1000 以上时,因数为 4。然后用这个因数乘以第一步的基本 Executor 数量就是 Executor 的预估总数量。
③从 Yarn 资源池中的得到可用的总核心数和总内存数,然后用总核心数和总内存数除以 kylin 任务所需的核心数和内存数,两者求个最小值,就是 Executor 的可用总数量。
④最后在 Executor 的预估总数量和 Executor 的可用总数量之间取最小值作为 Executor的实际最终总数量。
-
Shuffle 分区数量规则
设置’spark.sql.shuffle.partitions’为’max(2, ${最大文件大小 MB} / 32)'。
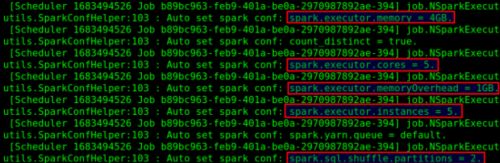
在应用上述所有分配规则后,可以在“kylin.log”文件中找到一些日志消息:
(2)根据实际情况手动设置 Spark 参数
根据 Kylin 自动调整的配置值,如果仍存在一些 Cube 构建性能问题,可以适当更改这些配置的值以进行尝试,例如:
-
如果从 spark ui 观察到某些任务中存在严重的 GC 现象,或者发现大量 executor丢失或获取失败错误,可以更改这两个配置的值,以增加每个 executor 的内存:
spark.executor.memory=
spark.executor.memoryOverhead=
一般调整策略是将参数的值调整为 2 倍。如果问题解决了,您可以适当地调整以避免浪费资源。在增加每个 Executor 的内存后,如果仍有严重的内存问题,可以考虑调整’spark.executor.cores’为 1,此调整可以使单个任务是每个 Executor 的独家任务,并且执行效率相对较低,但它可以通过这种方式来避免构建失败。
-
如果从 spark ui 观察到,有大量任务需要为多轮计划(每轮都用掉了所有内核),可以更改这两个配置的值,以增加 spark 应用程序的内核数:
spark.executor.cores=
spark.executor.instances=
-
如果有一些 Executor 丢失或获取数据错误,并且仅仅因为 Shuffle 期间的减速器数量太小,或者数据倾斜,可以尝试增加’spark.sql.shuffle.partitions’的值。
spark.sql.shuffle.partitions=
全局字典构建性能调优
如果 cube 定义了精确去重(即 count(distinct)语法)的度量值,Kylin4.0 将基于 Spark 为这些度量值分布式地构建全局字段的值(之前版本是单点构建)。这部分的优化主要是调整一个参数。
kylin.dictionary.globalV2-threshold-bucket-size (默认值 500000)
如果 CPU 资源充足,减少此配置的值可以减少单个分区中的数据量,从而加快构建全局字典。
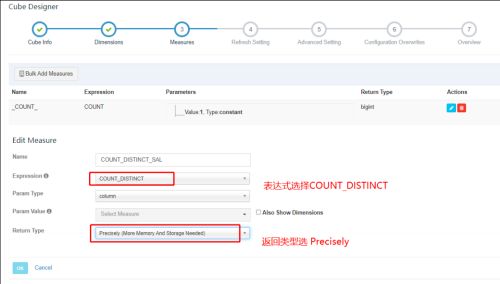
使用全局字典:
在 已 有 的 Model 中 , 创 建 一 个 新 的 Cube 用 于 测 试 全 局 字 典 , 设 置 度 量 为COUNT_DISTINCT,返回类型选择 Precisely:
如果构建失败,可能是 yarn 资源限制,构建时单个容器申请的 cpu 核数超过 yarn 单个容器默认最大 4 核,修改 hadoop 的 yarn-site.xml,分发配置文件,重启 yarn。
<property>
<name>yarn.scheduler.maximum-allocation-vcoresname>
<value>8value>
property>
查看全局字典:
在 HDFS 的 Kylin 元数据目录下,对应工程目录会生成一个 dict 目录:
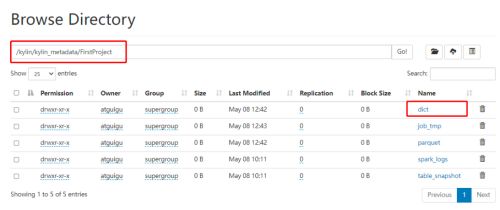
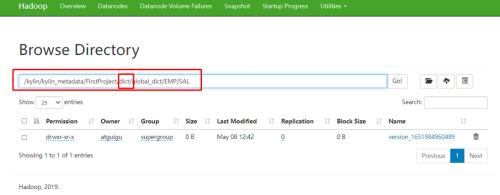
快照表构建性能调优
Snapshot Table - 快照表:每一张快照表对应一个 Hive 维度表,为了实时记录 Hive 维度表的数据变化,Kylin 的 cube 每次构建都会对 hive 维度表创建一个新的快照,以下是快照表的调优参数。
构建 Snapshot table 时,主要调整 2 个参数来调优:
| 参数名 | 默认值 | 说明 |
|---|---|---|
| kylin.snapshot.parallel-build-enabled | true | 使用并行构建,保持开启 |
| kylin.snapshot.shard-size-mb | 128MB | 如果 CPU 资源充足,可以减少值来增加并行度,建议并行度在 Spark 应用CPU 核数的 3 倍以内。并行度=原表数据量/该参数 |
查询性能优化
在 Kylin4.0 中,查询引擎(SparderContext)也使用 spark 作为计算引擎,它是真正的分布式查询引擎,特别是在复杂查询方面,性能会优于 Calcite。然而,仍然有许多关键性能点需要优化。除了上面提到的设置适当的计算资源之外,它还包括减少小的或不均匀的文件,设置适当的分区,以及尽可能多地修剪 parquet 文件。Kylin4.0 和 Spark 提供了一些优化策略来提高查询性能。
Row Key优化
Kylin会把所有的维度按照顺序组合成一个完整的Rowkey,并且按照这个Rowkey升序排列Cuboid中所有的行。
设计良好的Rowkey将更有效地完成数据的查询过滤和定位,减少IO次数,提高查询速度,维度在rowkey中的次序,对查询性能有显著的影响。
Row key的设计原则如下:
(1)被用作过滤的维度放在前边

创建 cube 时,可以指定维度列的排序,当保存 cube 数据时,每个 cuboid 的第一个维度列将用于执行排序操作。其目的是在使用排序列进行查询时,通过 parquet 文件的最小最大索引尽可能地过滤不需要的数据。
在 cube 构建配置的高级配置中,rowkey 的顺序就是排序顺序:
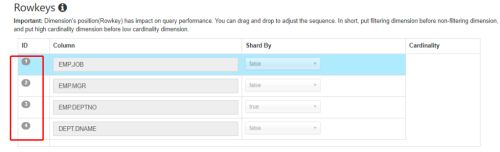
页面中可以左键点击 ID 进行拖拽,调整顺序

(2)基数大的维度放在基数小的维度前边

使用 shardby 列来裁剪 parquet 文件
Kylin4.0 底层存储使用的是 Parquet 文件,并且 Parquet 文件在存储的时候是会按照某一列进行分片的。这个分片的列在 Kylin 里面,我们称为是 shardBy 列,Kylin 默认按照 shardBy列进行分片,分片能够使查询引擎跳过不必要的文件,提高查询性能。我们在创建 Cube 时可以指定某一列作为 shardBy 列,最好选择高基列(基数高的列),并且会在多个 cuboid 中出现的列作为 shardBy 列。
如下图所示,我们按照时间(月)过滤,生成对应的 Segment,然后按照维度 A 作为shardBy 列进行分片,每个 Segment 里面都会有相应的分片。如果我们在查询的时候按照时间和维度 A 进行过滤,Kylin 就会直接选择对应 Segment 的对应分片,大大的提升的查询效率。
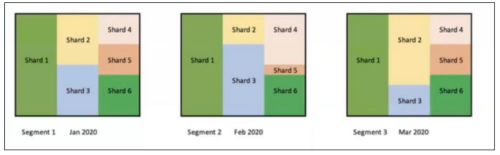
在 Kylin4.0 中,parquet 文件存储的目录结构如下:

查询时,查询引擎可以通过日期分区列过滤出 segment-level 目录,并通过 cuboid 过滤出cuboid-level 目录。但是在 cuboid-level 目录中仍有许多 parquet 文件,可以使用 shard by 列进一步裁剪parquet文件。目前在SQL查询中只支持以下过滤操作来裁剪parquet文件:Equality、In、InSet、IsNull。
(1)修改 cube 配置
这里拿已有的 cube 来做演示,先对已有 cube 清空数据。
对其 disable 禁用:
(2)指定 shardby 列
进行编辑:
点击高级配置:
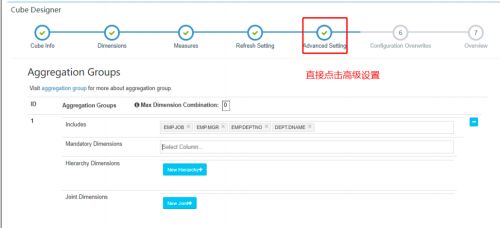
选择需要的列,将 shardby 改成 true。
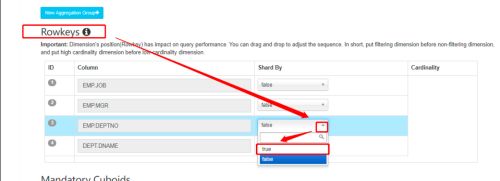
当构建 cube 数据时,它会根据这个 shard 按列对 parquet 文件进行重分区。如果没有指定一个 shardby 的列,则对所有列进行重分区。
减少小的或不均匀的 parquet 文件
在查询时读取太多小文件或几个太大的文件会导致性能低下,为了避免这个问题,Kylin4.0 在将 cube 数据作为 parquet 文件构建时,会按照一定策略对 parquet 文件进行重分区,以减少小的或不均匀的 parquet 文件。
(1)相关配置
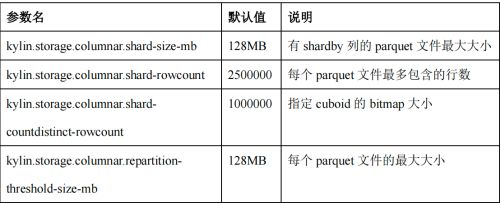
(2)重分区的检查策略
- 如果这个 cuboid 有 shardBy 的列;
- parquet 文件的平均大小 < 参数’kylin.storage.columnar.repartition-threshold-size-mb’ 值 ,且 parquet 文件数量大于 1;这种情况是为了避免小文件太多;
- parquet 文件的数量 < (parquet 文件的总行数/ ‘kylin.storage.columnar.shard-rowcount’ * 0.75),如果这个 cuboid 有精确去重的度量值(即 count(distinct)),使用’kylin.storage.columnar.shard-countdistinct-rowcount’ 来代替 ‘kylin.storage.columnar.shard-rowcount’;这种情况是为了避免不均匀的文件;
如果满足上述条件之一,它将进行重分区,分区的数量是这样计算的:
${fileLengthRepartitionNum} = Math.ceil(${parquet 文件大小 MB} / ${kylin.storage.columnar.shard-size-mb})
${rowCountRepartitionNum} = Math.ceil(${parquet 文件总行数} / ${kylin.storage.columnar.shard-rowcount})
分区数量=Math.ceil(( ${fileLengthRepartitionNum} + ${ rowCountRepartitionNum } ) / 2)
(3)合理调整参数的方式
-
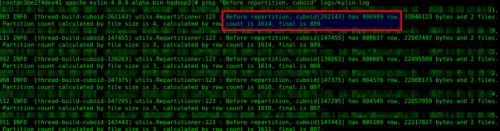
查看重分区的信息,可以通过下面命令去 log 中查找:
grep "Before repartition, cuboid" logs/kylin.log比如官方案例:可以看到分区数有 809 个。
-
增 大 ‘kylin.storage.columnar.shard-rowcount’ 或 'kylin.storage.columnar.shard-countdistinctrowcount’的值,重新构建,查看日志:


可以看到:分区数变成了 3 个,构建的时间也从 58 分钟降低到 24 分钟。
-
查询性能得到提高。
原先查询要 1.7 秒,扫描 58 个文件:
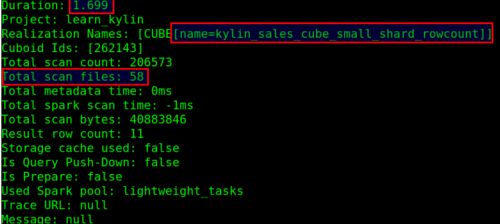
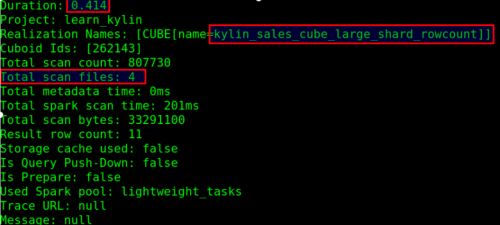
调整参数后,查询只要 0.4 秒,扫描 4 个文件:
将多个小文件读取到同一个分区
当已经构建的 segments 中有很多小文件时,可以 修改参数’spark.sql.files.maxPartitionBytes’ (默认值为 128MB)为合适的值,这样可以让 spark 引擎将一些小文件读取到单个分区中,从而避免需要太多的小任务。
如 果 有 足 够 的 资 源 , 可 以 减 少 该参数 的 值 来 增 加 并 行 度 , 但 需 要 同 时 减 少’spark.hadoop.parquet.block.size’(默认值为 128MB)的值,因为 parquet 文件的最小分割单元是RowGroup,这个 blocksize 参数表示 parquet 的 RowGroup 的最大大小。
使用堆外内存
Spark 可以直接操作堆外内存,减少不必要的内存开销,减少频繁的 GC,提高处理性能。相关配置:

BI工具集成
可以与Kylin结合使用的可视化工具很多,例如:
- ODBC:与Tableau、Excel、PowerBI等工具集成
- JDBC:与Saiku、BIRT等Java工具集成
- RestAPI:与JavaScript、Web网页集成
- Kylin开发团队还贡献了Zepplin的插件,也可以使用Zepplin来访问Kylin服务。
JDBC
(1)新建项目并导入依赖
<dependencies>
<dependency>
<groupId>org.apache.kylingroupId>
<artifactId>kylin-jdbcartifactId>
<version>4.0.1version>
dependency>
dependencies>
(2)编码
package com.atguigu;
import java.sql.*;
public class KylinTest {
public static void main(String[] args) throws Exception{
//Kylin_JDBC 驱动
String KYLIN_DRIVER = "org.apache.kylin.jdbc.Driver";
//Kylin_URL
String KYLIN_URL =
"jdbc:kylin://hadoop102:7070/FirstProject";
//Kylin 的用户名
String KYLIN_USER = "ADMIN";
//Kylin 的密码
String KYLIN_PASSWD = "KYLIN";
//添加驱动信息
Class.forName(KYLIN_DRIVER);
//获取连接
Connection connection =
DriverManager.getConnection(KYLIN_URL, KYLIN_USER, KYLIN_PASSWD);
//预编译 SQL
PreparedStatement ps = connection.prepareStatement("select dname,sum(sal) from emp e join dept d on e.deptno = d.deptno group by dname");
//执行查询
ResultSet resultSet = ps.executeQuery();
//遍历打印
while (resultSet.next()) {
System.out.println(resultSet.getString(1)+":"+resultSet.getDouble
(2));
}
} }
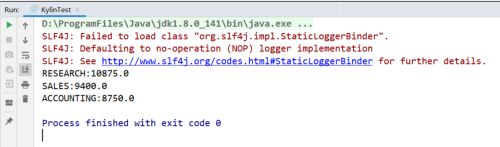
(3)结果展示
Zepplin
(1)Zepplin安装与启动
-
将zeppelin-0.8.0-bin-all.tgz上传至Linux
-
解压zeppelin-0.8.0-bin-all.tgz之/opt/module
[atguigu@hadoop102 sorfware]$ tar -zxvf zeppelin-0.8.0-bin-all.tgz -C /opt/module/ -
修改名称
[atguigu@hadoop102 module]$ mv zeppelin-0.8.0-bin-all/ zeppelin -
启动
[atguigu@hadoop102 zeppelin]$ bin/zeppelin-daemon.sh start
可登录网页查看,web默认端口号为8080
http://hadoop102:8080
(2)配置Zepplin支持Kylin
- 点击右上角anonymous选择Interpreter

-
搜索Kylin插件并修改相应的配置
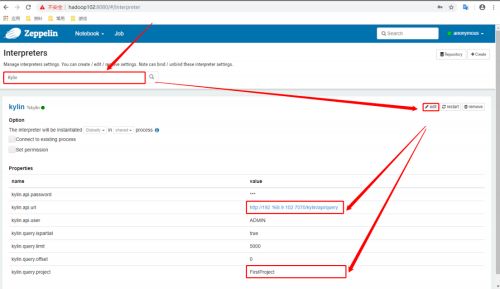
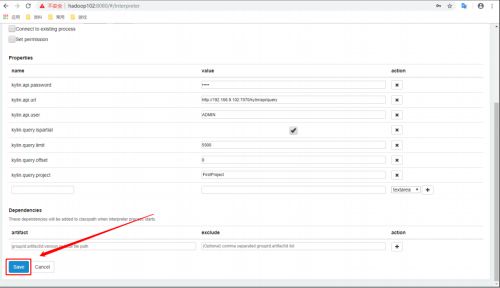
-
修改完成点击Save完成
(3)案例实操
需求:查询员工详细信息,并使用各种图表进行展示
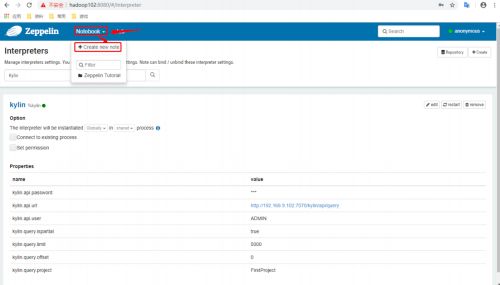
-
点击Notebook创建新的note
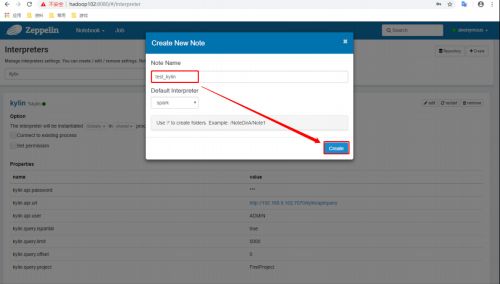
-
填写Note Name点击Create
-
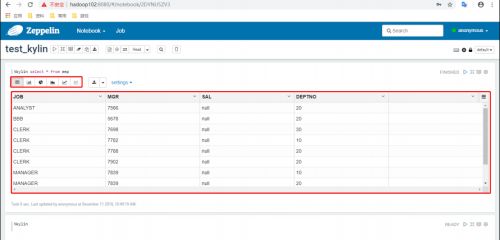
执行查询

-
结果展示
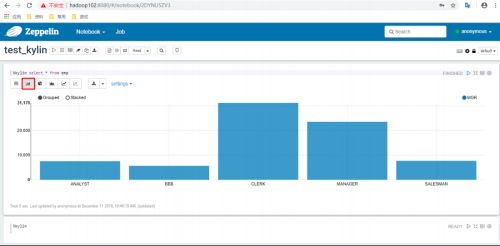
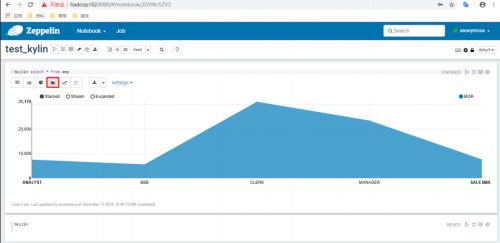
-
其他图表格式

MDX For Kylin
MDX for Kylin 是基于 Mondrian 二次开发的、由 Kyligence 贡献的、使用 Apache Kylin 作为数据源的 MDX 查询引擎 。MDX for Kylin 的使用体验比较接近 Microsoft SSAS,可以集成多种数据分析工具,包括 Microsoft Excel、Tableau 等,可以为大数据分析场景下提供更极致的体验。
MDX for Kylin 是在决策支持和业务分析中使用的分析数据引擎。MDX for Kylin 助力消除数据孤岛,统一数据口径,提高数据业务转化效率,提升运营决策能力。
MDX for Kylin 相对其它开源 MDX 查询引擎,具有以下优势:
- 更好支持 BI (Excel/Tableau/Power BI 等) 产品,适配 XMLA 协议;
- 针对 BI 的 MDX Query 进行了特定优化重写;
- 适配 Kylin 查询,通过 Kylin 的预计算能力加速 MDX 查询;
- 通过简洁易懂的操作界面,提供了统一的指标定义和管理能力。
流程介绍
使用时,客户端发送 MDX 查询给 MDX for Kylin,MDX for Kylin 再解析 MDX 查询翻译为 SQL 并且发送给 Kylin ,然后 Kylin 通过预计算的 Cuboid 回答 SQL 查询并把结果交还给 MDX for Kylin,MDX for Kylin 会再做一些衍生指标的计算,最终将多维数据结果返回给客户端。
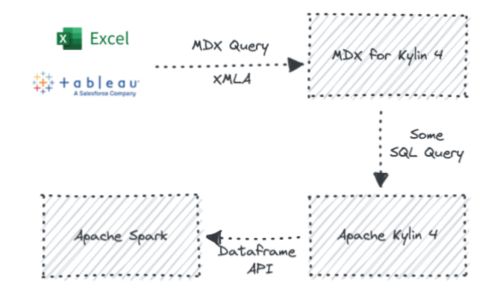
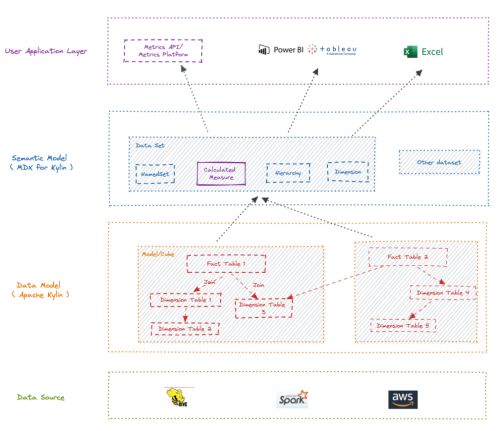
总的来说,支持 MDX 接口能够增强 Kylin 的语义层能力,为用户带来统一的数据分析和管理体验,更好地发挥数据的价值。下图就是将从下而上,展示从原始数据加工业务指标的过程。
安装
MDX for Kylin 需要对接一个 Kylin 实例或集群,现在 MDX for Kylin 能对接 Kylin 版本为 4.0.2 及以上。本课程使用的 4.0.1,需要替换 jar 包解决兼容性。
(1)启动 kylin
(2)上传 kylin-server-base-4.0.1.jar 包,覆盖原有 jar 包
cp /opt/software/kylin-server-base-4.0.1.jar /opt/module/kylin-4.0.1/tomcat/webapps/kylin/WEB-INF/lib
(3)重启 kylin
bin/kylin.sh restart
前置条件
(1)推荐的硬件配置
双路 Intel 至强处理器,6 核(或 8 核)CPU,主频 2.3GHz 或以上。
32GB ECC DDR3 以上。
至少 1 个 1TB 的 SAS 硬盘(3.5 寸),7200RPM,RAID1。
至少两个 1GbE 的以太网电口。
(2)推荐的 Linux 版本
- Red Hat Enterprise 7.x
- CentOS 6.4+ 或 7.x
- Suse Linux 11
- Ubuntu 16
(3)需要的依赖
JAVA 环境:JDK8 或以上
(4)推荐的元数据库版本
MySQL 5.7.x 及以上
(5)推荐的元数据库驱动 jar 版本
mysql-connector-java-8.0.16, 请下载到
(6)推荐的客户端配置
CPU:2.5 GHz Intel Core i7
操作系统:macOS / windows 7 或 10
内存:8G 或以上
浏览器及版本:谷歌 Chrome 67.0.3396 及以上
安装 MDX
(1)MySQL创建数据库
create database mdx default character set utf8mb4 collate utf8mb4_unicode_ci;
注意:将 character_set_database 设定为 utf8mb4 或 utf8, 将 collation_server 设定为utf8mb4_unicode_ci 或 utf8_unicode_ci,
(2)上传并解压 mdx 安装包
tar -zxvf mdx-for-kylin-1.0.0-beta.tar.gz -C /opt/module
(3)加密元数据库访问密码
bin/mdx.sh encrypt '123456'
注意:如果输入的密码包含特殊字符, 需要用单引号包裹, 如果密码里面有单引号, 那么可以用双引号包裹。
记录加密后的密文:698d2c7907fc9b6dbe7f8a8c4cb0297a
(4)修改配置文件
修改 conf 目录下 insight.properties 配置。
vim conf/insight.properties
insight.kylin.host: hadoop102
insight.kylin.port: 7070
insight.database.type: mysql
insight.database.ip: hadoop102
insight.database.port: 3306
insight.database.name: mdx
insight.database.username: root
insight.database.password: 698d2c7907fc9b6dbe7f8a8c4cb0297a
insight.mdx.cluster.nodes: hadoop102:7080
注意:password 是前面加密后的密文。
启动 MDX For Kylin
(1)首次启动会需要几分钟的时间来更新元数据
bin/mdx.sh start
注意:在首次启动时,由于未并未填写与 Kylin 通信的账户信息,所以同步任务会失败。详情如下图,此时可正常登陆 MDX for Kylin 并填写同步信息,填写后即可正常同步。
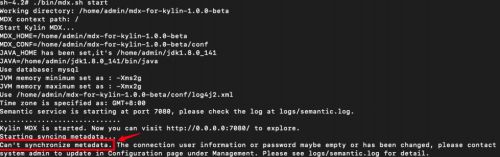
安装成功后,通过 http://hadoop102:7080/login/ 登陆 MDX for Kylin,密码和 Kylin 一样,默认是 ADMIN/KYLIN。
由于 MDX for Kylin 需要与 Kylin 进行通信,所以首次启动时,登陆系统后,系统会提示填写连接使用的用户名和密码。
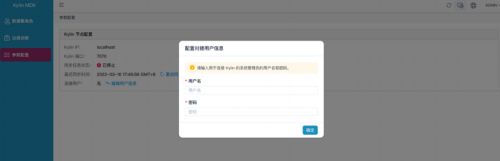
输入 ADMIN/KYLIN。
(2)停止 MDX for Kylin
bin/mdx.sh stop
设计数据集
(1)打开 mdx 的 Web UI,创建数据集:http://hadoop102:7080
(2)命名数据集
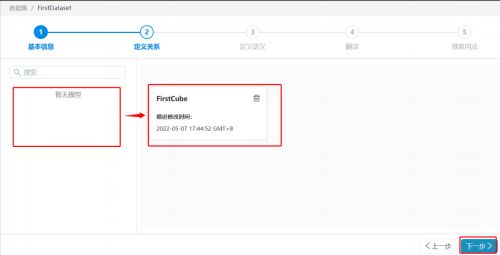
(3)拖拽模型到右侧画布
(4)修改维度和度量(名称、属性)

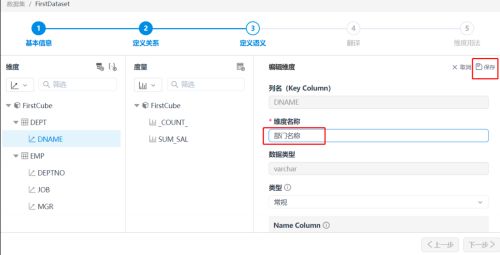
更多修改维度和度量属性的操作,可以查阅:
https://kylin.apache.org/cn/docs/tutorial/quick_start_for_mdx.html
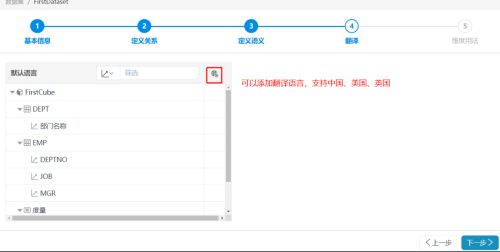
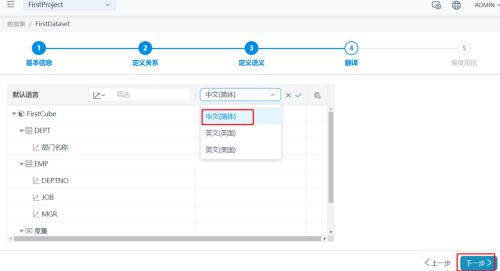
(5)定义翻译
(6)确定保存
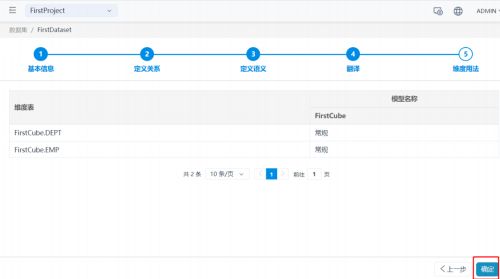
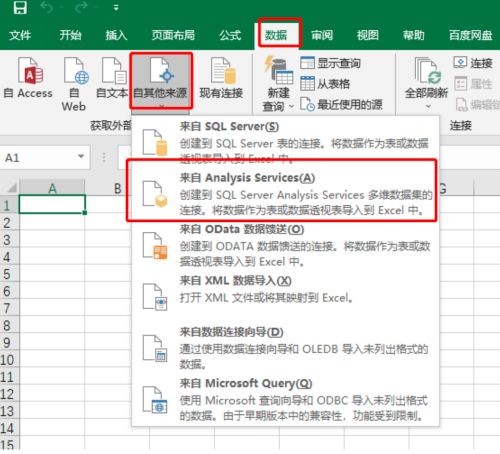
在 Excel 中分析
(1)打开 Excel,设置获取数据
(2)配置 MDX 地址
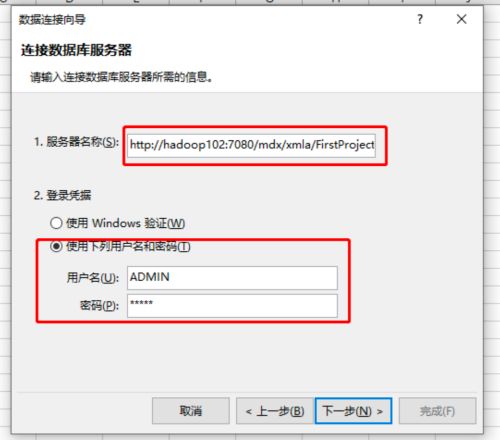
名称的格式为: http://{host}:{port}/mdx/xmla/{project}
- host 和 port 为 mdx 的主机和端口 7080。
- project 为 kylin 中对应的 project 名称。
用户名密码是 mdx 的登陆用户名和密码 ADMIN/KYLIN。
(3)选择数据库和表
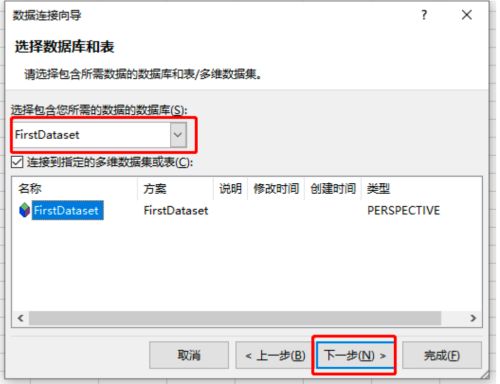
(4)保存文件并完成
(5)使用透视表分析

Kylin5.0介绍
Roadmap of Kylin 5.0(CN) | Welcome to Kylin 5 (apache.org)