kylin的Cube构建原理及优化
Kylin的Cube构建原理
cube的构建主要有两种算法:逐层构建算法、快速构建算法,无论是采用哪种算法,首先是从Hive表中拉取数据,根据配置的星型模型,把hive中涉及的表关联起来,并拉取所有的字段形成一个中间层的宽表,如图

然后根据落地中间表的数据生成cube
逐层构建算法:
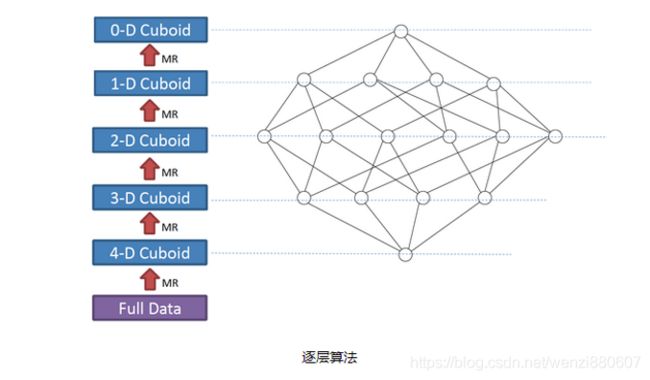
一个N维的Cube,是由1个N维的立方体、N个(N-1)维子立方体、N*(N-1)/2个(N-2)维子立方体、.....、N个1维子立方体和1个0维子立方体构成,总共由2^N个子立方体组成,逐层算法中,就是按照维度数逐层减少来串行计算的,第一层直接从宽表的数据计算而来,之后每个层级的计算是基于上一层级的结果计算的,比如说,A、B、C三个维度的结果是基于A、B、C、D四个维度的结果上直接汇总得来的,这样可以减少重复计算,直到0维度Cuboid计算出来的时候,整个Cube的计算也就完成了,每一轮计算都是一个MR任务,串行执行,1个N维的Cube,至少需要N次MR job
算法的优点:
1、充分利用了MR的优点,处理了中间复杂的排序和shuffle工作,逐层算法代码清晰简单,容易维护
2、基于hadoop日益成熟,此算法非常稳定,即便是集群资源紧张,也能保证最终能够完成CUBE的构建
算法缺点:总体而言,效率低,尤其是维度数较大的时候
1、当维度增加,所需的MR任务也相应增加,hadoop的任务调度需求耗费额外资源,而且反复提交任务造成的额外开销会相当巨大
2、Mapper逻辑中并未进行聚合操作,所以每轮MR的shuffle工作量都很大,导致效率低下
3、对HDFS的读写操作较多,因为每一层的计算的输出会用作下一层计算的输入,导致这些Key-Value需要落盘到HDFS上,当所有计算都完成后,还需额外的一轮任务将这些文件转成Hbase的Hfile格式,并导入到Hbase中
快速构建算法:

快速构建算法也叫做“逐段”或“逐块”算法,主要思想是:每个mapper将其分配到的数据块,计算成一个完整的小Cube段(包含所有Cuboid),每个Mapper将计算完成的Cube段输出给Reducer做合并,生成大Cube也就是最终结果
优点:
1、Mapper会利用内存做预聚合,算出所有组合;Mapper输出的每个Key都是不同的,这样会减少输出到Hadoop MR的数据量,Combiner也不再需要;
2、一轮MR即可完成所有层次的计算,减少hadoop任务的调配
Cube构建优化
构建维度数量较多的Cube时,要注意Cube的剪枝优化(即减少Cuboid的生成)
1、使用衍生维度
衍生维度用于在有效维度内将有效维度表上的非主键维度排除掉,并使用维度表的主键(事实表上的外键)来替代他们,Kylin会在底层记录维度表主键与维度表其他维度之间的映射关系,以便在查询时能够动态的将维度表的主键“翻译”成这些非主键维度,并进行实时聚合。

2、使用聚合组
聚合组是一种强大的剪枝工具,聚合组假设一个cube的所有维度均可以根据业务需求划分成若干组,由于同一组内的维度更可能同时被同一个查询用到,因此会表现出更加紧密的内在关联。
具体实现方式有如下几种:
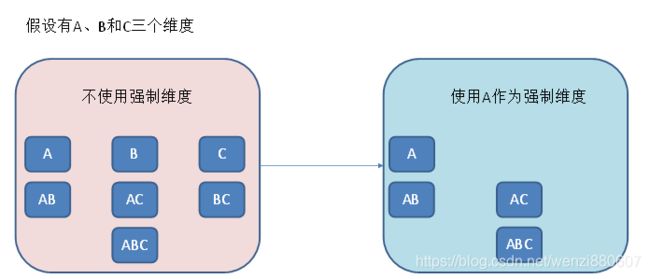
1)、强制维度,如果一个维度被定义为强制维度,那么这个分组产生的所有Cuboid中每一个cuboid都会包含该维度,每个分组中都可以由0个、1个、或多个强制维度。如果根据这个分组的业务逻辑,则相关的查询一定会在过滤条件或分组条件中,因此可以在改分组中把该维度设置为强制维度。
2)、层级维度
每个层级包含两个或更多个维度。假设一个层级中包含D1,D2…Dn这n个维度,那么在该分组产生的任何Cuboid中, 这n个维度只会以(),(D1),(D1,D2)…(D1,D2…Dn)这n+1种形式中的一种出现。每个分组中可以有0个、1个或多个层级,不同的层级之间不应当有共享的维度。如果根据这个分组的业务逻辑,则多个维度直接存在层级关系,因此可以在该分组中把这些维度设置为层级维度

3)、联合维度
每个联合维度中包含两个或更多个维度,如果某些列形成一个联合,那么在该分组产生的任何Cuboid中,这些联合维度要么一起出现,要么都不出现。每个分组中可以由0个或多个联合,但是不同的联合之间不应当由共享的维度(否则他们可以合并成一个联合)。如果根据这个分组的业务逻辑,多个维度在查询中总是同时出现,则可以在该分组中把这些维度设置为联合维度
row key优化
kylin会把所有的维度按照顺序组合成一个完整的Rowkey,并且按照这个rowkey升序排列cuboid中所有的行。设计良好的rowkey将更有效的完成数据的查询过滤和定位,减少IO次数,提高查询速度,维度在rowkey中的次序,对查询性能由显著的影响
原则:
1)、被用作where条件的过滤的维度放在前边
2)、基数大的维度放在基数小的维度前边
并发粒度的优化