Scala的函数式编程与高阶函数,匿名函数,偏函数,函数的闭包、柯里化,抽象控制,懒加载等
Scala的函数式编程
函数式编程
解决问题时,将问题分解成一个一个的步骤,将每个步骤进行封装(函数),通过调用这些封装好的步骤,解决问题。
- 例如:请求->用户名、密码->连接 JDBC->读取数据库
- Scala 语言是一个完全函数式编程语言。万物皆函数。
- 函数的本质:函数可以当做一个值进行传递。
- 在 Scala 中函数式编程和面向对象编程完美融合在一起了。
函数的基本语法和使用
函数基本语法
在Scala中,函数是一等公民,可以被赋值给变量、作为参数传递给其他函数,以及作为返回值返回。
- 函数的基本语法:

- 使用案例:
// 定义一个函数,计算两个整数的和
def add(a: Int, b: Int): Int = {
a + b
}
// 调用函数
val result = add(3, 4)
println(result) // 输出结果为7
函数使用def关键字进行定义,并且需要指定参数列表和返回类型。在函数体中,可以使用return关键字返回一个值,也可以省略return关键字,将最后一行作为返回值。
函数定义
- 函数定义
(1) 函数 1:无参,无返回值
(2) 函数 2:无参,有返回值
(3) 函数 3:有参,无返回值
(4) 函数 4:有参,有返回值
(5) 函数 5:多参,无返回值
(6) 函数 6:多参,有返回值
- 案例实操
下面示例函数的不同形式的定义:
object Test_FunctionDefine {
def main(args: Array[String]): Unit = {
// (1)函数1:无参,无返回值
def f1(): Unit = {
println("1. 无参,无返回值")
}
f1()
println(f1())
println("=========================")
// (2)函数2:无参,有返回值
def f2(): Int = {
println("2. 无参,有返回值")
return 12
}
println(f2())
println("=========================")
// (3)函数3:有参,无返回值
def f3(name: String): Unit = {
println("3:有参,无返回值 " + name)
}
println(f3("alice"))
println("=========================")
// (4)函数4:有参,有返回值
def f4(name: String): String = {
println("4:有参,有返回值 " + name)
return "hi, " + name
}
println(f4("alice"))
println("=========================")
// (5)函数5:多参,无返回值
def f5(name1: String, name2: String): Unit = {
println("5:多参,无返回值")
println(s"${name1}和${name2}都是我的好朋友")
}
f5("alice","bob")
println("=========================")
// (6)函数6:多参,有返回值
def f6(a: Int, b: Int): Int = {
println("6:多参,有返回值")
return a + b
}
println(f6(12, 37))
}
}
函数和方法的区别
- 核心概念
(1) 为完成某一功能的程序语句的集合,称为函数。
(2) 类中的函数称之方法。 - 案例实操
(1) Scala 语言可以在任何的语法结构中声明任何的语法
(2) 函数没有重载和重写的概念;方法可以进行重载和重写
(3) Scala 中函数可以嵌套定义。
object Test_FunctionAndMethod {
def main(args: Array[String]): Unit = {
// 定义函数
def sayHi(name: String): Unit = {
println("hi, " + name)
}
// 调用函数
sayHi("alice")
// 调用对象方法
Test01_FunctionAndMethod.sayHi("bob")
// 获取方法返回值
val result = Test01_FunctionAndMethod.sayHello("cary")
println(result)
}
// 定义对象的方法
def sayHi(name: String): Unit = {
println("Hi, " + name)
}
def sayHello(name: String): String = {
println("Hello, " + name)
return "Hello"
}
}
Scala 中函数嵌套
object TestFunction {
// (2)方法可以进行重载和重写,程序可以执行
def main(): Unit = {
}
def main(args: Array[String]): Unit = {
// (1)Scala 语言可以在任何的语法结构中声明任何的语法
import java.util.Date
new Date()
// (2)函数没有重载和重写的概念,程序报错
def test(): Unit ={
println("无参,无返回值")
}
test()
def test(name:String):Unit={
println()
}
//(3)Scala 中函数可以嵌套定义
def test2(): Unit ={
println("函数可以嵌套定义")
}
}
}
}
除了常规的函数定义,Scala还支持匿名函数、高阶函数、偏函数等概念,下面将逐一介绍。
匿名函数
匿名函数是一种没有命名的函数,它可以直接作为表达式传递给其他函数或赋值给变量。以下是匿名函数的示例:
// 定义一个函数,接受一个函数和两个整数作为参数,并将结果打印出来
def operate(f: (Int, Int) => Int, a: Int, b: Int): Unit = {
val result = f(a, b)
println(result)
}
// 调用operate函数,并传递一个匿名函数作为参数
operate((a, b) => a + b, 3, 4) // 输出结果为7
上述示例中,匿名函数(a, b) => a + b接受两个整数并返回它们的和。将该匿名函数作为参数传递给operate函数后,可以在operate函数内部调用该匿名函数并得到结果。
高阶函数
高阶函数是指接受一个或多个函数作为参数,并/或返回一个函数的函数。在Scala中,高阶函数的定义和使用非常灵活,以下是高阶函数的语法规则和几种常见类型的示例:
高阶函数常见类型
1. 参数为函数的高阶函数:
def operate(f: (Int, Int) => Int, a: Int, b: Int): Int = {
f(a, b)
}
val add = (a: Int, b: Int) => a + b
val result = operate(add, 3, 4) // 调用operate函数,传入add函数作为参数
println(result) // 输出结果为7
在上述示例中,operate函数接受一个函数f作为参数,并将a和b作为实参调用了f函数。
2. 函数返回值为函数的高阶函数:
def multiplyBy(factor: Int): Int => Int = {
(x: Int) => x * factor
}
val multiplyByTwo = multiplyBy(2) // 调用multiplyBy函数,返回一个新的函数
val result = multiplyByTwo(5) // 调用返回的新函数
println(result) // 输出结果为10
在上述示例中,multiplyBy函数返回了一个新的函数,新函数会将其参数与factor相乘。这里 Int => Int 代表参数为Int类型,返回值也为Int类型的函数,这种是对lambda表达式的简写。
3. 参数和返回值都为函数的高阶函数:
def compose(f: Int => Int, g: Int => Int): Int => Int = {
(x: Int) => f(g(x))
}
val addOne = (x: Int) => x + 1
val multiplyByTwo = (x: Int) => x * 2
val result = compose(addOne, multiplyByTwo)(3) // 调用compose函数,并传入两个函数作为参数
println(result) // 输出结果为7
在上述示例中,compose函数接受两个函数f和g作为参数,并返回一个新的函数,新函数将f应用于g的结果。输出结果为7,函数执行的过程为:定义了两个函数分别为:addOne和multiplyByTwo,调用compose(f, g)函数,将addOne和multiplyByTwo函数作为参数传入,则返回一个新的函数,参数类型为一个Int,函数体为f(g(x)),那么返回的新函数为:addOne( multiplyByTwo ( x: Int ) ),调用compose(addOne, multiplyByTwo)(3)函数,x参数为3,里层函数为 multiplyByTwo(3) => 6,结果返给外层函数addOne(x: Int),最终结果7.
高阶函数是指接受一个或多个函数作为参数,并/或返回一个函数的函数。Scala提供了多种高阶函数,如map、flatMap、filter等。
scala常见的高阶函数及使用方法
map:对集合中的每个元素应用一个函数,并返回一个新的集合。
val numbers = List(1, 2, 3, 4, 5)
val squaredNumbers = numbers.map(x => x * x)
println(squaredNumbers) // 输出结果为List(1, 4, 9, 16, 25)
flatMap:将集合中的每个元素应用一个函数,并将结果展平为一个新的集合。
val words = List("Hello", "World")
val letters = words.flatMap(word => word.toCharArray)
println(letters) // 输出结果为List(H, e, l, l, o, W, o, r, l, d)
filter:根据给定条件过滤集合中的元素。
val numbers = List(1, 2, 3, 4, 5)
val evenNumbers = numbers.filter(x => x % 2 == 0)
println(evenNumbers) // 输出结果为List(2, 4)
reduce:将集合中的元素逐个进行累积计算。
val numbers = List(1, 2, 3, 4, 5)
val sum = numbers.reduce((a, b) => a + b)
println(sum) // 输出结果为15
fold:将集合中的元素逐个进行累积计算,可以指定一个初始值。
val numbers = List(1, 2, 3, 4, 5)
val sum = numbers.fold(0)((a, b) => a + b)
println(sum) // 输出结果为15
groupBy:根据给定的函数对集合中的元素进行分组。
val numbers = List(1, 2, 3, 4, 5)
val groupedNumbers = numbers.groupBy(x => x % 2)
println(groupedNumbers) // 输出结果为Map(1 -> List(1, 3, 5), 0 -> List(2, 4))
通过使用这些常见的高阶函数,您可以以一种函数式的方式对集合进行处理和转换,简化代码,并提高代码的可读性和可维护性。
偏函数的使用
偏函数中的模式匹配
偏函数也是函数的一种,通过偏函数我们可以方便的对输入参数做更精确的检查。例如:
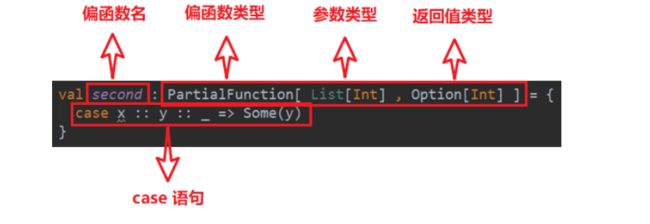
该偏函数的输入类型为List[ Int ],而我们需要的是第一个元素是 0 的集合,这就是通过模式匹配实现的。
偏函数定义:
val second: PartialFunction[List[Int], Option[Int]] = {
case x :: y :: _ => Some(y)
}
偏函数是一种只对部分输入值进行定义的函数。Scala的偏函数使用PartialFunction类表示。以下是一个使用偏函数的示例:
val divide: PartialFunction[Int, Int] = {
case d: Int if d != 0 => 42 / d
}
val result1 = divide(6) // 输出结果为7
val result2 = divide(0) // 抛出MatchError异常
上述示例中的偏函数divide定义了一个对整数进行除法运算的偏函数,只有当除数不为零时才能有效计算。
如果一个方法中没有match 只有case,这个函数可以定义成PartialFunction偏函数。偏函数定义时,不能使用括号传参,默认定义PartialFunction中传入一个值,匹配上了对应的case,返回一个值,只能匹配同种类型。
偏函数示例二
一个case语句就可以理解为是一段匿名函数。
/**
* 一个函数中只有case 没有match ,可以定义成PartailFunction 偏函数
*/
object Lesson_PartialFunction {
def MyTest : PartialFunction[String,String] = {
case "scala" =>{"scala"}
case "hello" =>{"hello"}
case _ => {"no match ..."}
}
def main(args: Array[String]): Unit = {
println(MyTest("scala"))
}
}
/**
* 第二个例子
* map和collect的区别。
*/
def main(args: Array[String]): Unit = {
val list1 = List(1, 3, 5, "seven") map {
MyTest
}//List(1, 3, 5, "seven") map { case i: Int => i + 1 }
list1.foreach(println)
val list = List(1, 3, 5, "seven") collect {
MyTest
}//List(1, 3, 5, "seven") collect { case i: Int => i + 1 }
list.foreach(println)
}
def MyTest: PartialFunction[Any, Int] = {
case i: Int => i + 1
}
偏函数示例三
object Test06_PartialFunction {
def main(args: Array[String]): Unit = {
val list: List[(String, Int)] = List(("a", 12), ("b", 35), ("c", 27), ("a", 13))
// 1. map转换,实现key不变,value2倍
val newList = list.map( tuple => (tuple._1, tuple._2 * 2) )
// 2. 用模式匹配对元组元素赋值,实现功能
val newList2 = list.map(
tuple => {
tuple match {
case (word, count) => (word, count * 2)
}
}
)
// 3. 省略lambda表达式的写法,进行简化
val newList3 = list.map {
case (word, count) => (word, count * 2)
}
println(newList)
println(newList2)
println(newList3)
// 偏函数的应用,求绝对值
// 对输入数据分为不同的情形:正、负、0
val positiveAbs: PartialFunction[Int, Int] = {
case x if x > 0 => x
}
val negativeAbs: PartialFunction[Int, Int] = {
case x if x < 0 => -x
}
val zeroAbs: PartialFunction[Int, Int] = {
case 0 => 0
}
// 偏函数的调用,定义一个abs(x: Int)函数,然后返回值也为Int, 使用orElse链式调用不同的偏函数,最终返回结果
/**
orElse是Scala中PartialFunction类的一个方法,用于组合两个偏函数。它返回一个新的偏函数,该偏函数首先尝试应用第一个偏函数,如果第一个偏函数没有定义在输入上,则尝试应用第二个偏函数。
*/
def abs(x: Int): Int = (positiveAbs orElse negativeAbs orElse zeroAbs) (x)
println(abs(-67))
println(abs(35))
println(abs(0))
}
}
偏函数的使用场景
偏函数(Partial Function)是指定义在一个子集上的函数,即函数并不在其所有可能的输入上都有定义,而只在特定的输入值上有定义。在Scala中,可以使用PartialFunction[A, B]来表示偏函数,其中A是输入类型,B是输出类型。
以下是几个常见的偏函数的运用场景:
1. 模式匹配: 偏函数经常与模式匹配一起使用,用于处理特定模式的输入。通过使用case语句定义不同的情况,可以很容易地创建偏函数。例如:
val divideByZero: PartialFunction[Int, Int] = {
case 0 => throw new ArithmeticException("Division by zero")
case x => 10 / x
}
println(divideByZero(5)) // 输出: 2
println(divideByZero(0)) // 抛出ArithmeticException异常
上述例子中,divideByZero是一个偏函数,它对输入进行模式匹配。当输入为0时,抛出除零异常;否则,执行除法运算。
2. 集合操作: 偏函数常用于集合操作,特别是在处理包含可选值或特定条件的元素时。例如,使用collect方法结合偏函数可以过滤和转换集合中的元素:
val names = List("Alice", "Bob", "Charlie", null, "Dave")
val validNames = names.collect { case name: String => name }
println(validNames) // 输出: List(Alice, Bob, Charlie, Dave)
上述示例中,偏函数只接受String类型的输入,通过collect方法过滤掉了空元素,将有效的名称提取出来。
3. 处理异常: 偏函数还可以用于处理异常情况。当无法处理某些特定输入时,可以定义一个偏函数来捕获和处理异常,以便程序继续执行。
val safeDivide: PartialFunction[(Int, Int), Int] = {
case (x, y) if y != 0 => x / y
}
println(safeDivide(10, 2)) // 输出: 5
println(safeDivide(10, 0)) // 抛出MatchError异常
上述示例中,safeDivide是一个偏函数,它只在除数不为零时执行除法操作,否则抛出MatchError异常。
总的来说,偏函数可以在需要对特定输入进行处理或过滤的场景下发挥作用,特别适用于模式匹配、集合操作和异常处理等情况。通过使用偏函数,可以更加准确和灵活地定义和处理特定的输入情况。
偏函数底层源码解读
在Scala中,PartialFunction是一个特质(trait),而不是一个类(class)。它定义了一种能够在部分输入上定义的函数,并提供了一些方法来检查函数是否对给定的输入进行了定义,以及如何将这些函数组合成一个新的偏函数。
Scala中的PartialFunction特质定义如下:
trait PartialFunction[-A, +B] extends (A => B) {
self =>
import PartialFunction._
def isDefinedAt(x: A): Boolean
def orElse[A1 <: A, B1 >: B](that: PartialFunction[A1, B1]): PartialFunction[A1, B1] =new OrElse[A1, B1] (this, that)
override def andThen[C](k: B => C): PartialFunction[A, C] =new AndThen[A, B, C] (this, k)
...
}
其中,-A表示输入类型,+B表示输出类型,=>表示函数类型。因此,PartialFunction[A, B]是一个从类型为A的输入到类型为B的输出的部分函数。
PartialFunction特质有三个核心方法:isDefinedAt和apply,orElse 方法。isDefinedAt方法用于检查函数是否对给定的输入进行了定义。如果函数在该输入上有定义,则返回true,否则返回false。apply方法用于在函数定义的输入范围内对输入进行计算,并返回相应的输出值。
orElse 方法接受一个类型为 PartialFunction[A1, B1] 的参数,并返回一个新的 PartialFunction[A1, B1]。
orElse 方法用于组合两个偏函数,它会先检查当前偏函数是否能够处理给定的输入 x,如果能够处理,则直接调用当前偏函数的 apply 方法;如果不能处理,则将输入传递给参数中的另一个偏函数,然后调用其 apply 方法。
这种组合方法使得我们可以链式地连接多个偏函数,形成一个更复杂的偏函数链。
因此,通过使用PartialFunction特质,我们可以定义一种只在部分输入上有定义的函数,并使用isDefinedAt和apply方法对这些函数进行管理和操作。同时,由于PartialFunction是一个特质,我们还可以将其作为其他类的组成部分来使用,以便实现更复杂的功能。
函数的柯里化、抽象控制和惰性加载
柯里化(Currying)
- 柯里化(Currying):柯里化是将接受多个参数的函数转换为接受一个参数的函数序列的过程。这可以提供更高的灵活性和复用性。
def add(a: Int)(b: Int): Int = a + b
val addTwo = add(2) _ // 创建一个新函数,固定a为2
val result = addTwo(3) // 输出结果为5
抽象控制
- 抽象控制:抽象控制是指接受函数作为参数,并在需要的时候调用该函数。它提供了一种灵活的控制流程。
def executeFunction(callback: => Unit): Unit = {
println("执行前")
callback
println("执行后")
}
executeFunction {
println("回调函数被执行")
}
上述示例中的executeFunction函数接受一个没有参数和返回值的函数,并在适当的时机调用该函数。
抽象控制例子二
object Test_ControlAbstraction {
def main(args: Array[String]): Unit = {
// 1. 传值参数
def f0(a: Int): Unit = {
println("a: " + a)
println("a: " + a)
}
f0(23)
def f1(): Int = {
println("f1调用")
12
}
f0(f1())
println("========================")
// 2. 传名参数,传递的不再是具体的值,而是代码块
def f2(a: =>Int): Unit = {
println("a: " + a)
println("a: " + a)
}
f2(23)
f2(f1())
f2({
println("这是一个代码块")
29
})
}
}
函数的懒加载机制
- 惰性加载:惰性加载是指推迟表达式的求值,直到它被实际使用时才计算。这有助于提高程序效率和资源利用率。
lazy val expensiveCalculation: Int = {
// 执行昂贵的计算
42
}
println(expensiveCalculation) // 在此处才进行计算和输出结果
在上述示例中,expensiveCalculation变量在声明时并不会立即计算,而是在第一次访问时才进行计算。
柯里化和闭包示例
/*
* 在scala中,函数是一个对象,方法调用的时候,会在内存中开辟两个空间,
* 一个是栈内存,方法调用会压栈,同时会将方法对应的函数实例保存到堆内存一份,
* 对内存的数据是共享的。栈内存是独享的,随着方法调用完毕,栈内存会释放,
* 但是堆内存的变量仍然还在,这样就实现了函数的闭包。
*/
object Test_ClosureAndCurrying {
def main(args: Array[String]): Unit = {
def add(a: Int, b: Int): Int = {
a + b
}
// 1. 考虑固定一个加数的场景
def addByFour(b: Int): Int = {
4 + b
}
// 2. 扩展固定加数改变的情况
def addByFive(b: Int): Int = {
5 + b
}
// 3. 将固定加数作为另一个参数传入,但是是作为”第一层参数“传入
def addByFour1(): Int=>Int = {
val a = 4
def addB(b: Int): Int = {
a + b
}
addB
}
def addByA(a: Int): Int=>Int = {
def addB(b: Int): Int = {
a + b
}
addB
}
println(addByA(35)(24))
val addByFour2 = addByA(4)
val addByFive2 = addByA(5)
println(addByFour2(13))
println(addByFive2(25))
// 4. lambda表达式简写
def addByA1(a: Int): Int=>Int = {
(b: Int) => {
a + b
}
}
def addByA2(a: Int): Int=>Int = {
b => a + b
}
def addByA3(a: Int): Int=>Int = a + _
val addByFour3 = addByA3(4)
val addByFive3 = addByA3(5)
println(addByFour3(13))
println(addByFive3(25))
// 5. 柯里化
def addCurrying(a: Int)(b: Int): Int = {
a + b
}
println(addCurrying(35)(24))
}
}
总结:
Scala是一门强大的函数式编程语言,提供丰富的函数概念。本文首先介绍了函数的基本语法和使用方法,并列举了一些示例。然后,讨论了匿名函数的特点以及如何使用它们。接下来,我们介绍了高阶函数及其常见用法。然后,我们介绍了偏函数的概念和使用方法。最后,我们涵盖了柯里化、抽象控制和惰性加载等进阶主题。
函数的闭包
函数闭包是指一个函数以及其在创建时所能访问的自由变量(即不是参数也不是局部变量)的组合。闭包允许函数捕获并访问其周围上下文中定义的变量,即使这些变量在函数执行时不再存在。
在Scala中,闭包是一种非常强大且常见的特性,它可以用于创建具有灵活状态的函数。以下是一个示例来说明函数闭包的概念:
def multiplier(factor: Int): Int => Int = {
(x: Int) => x * factor
}
val multiplyByTwo = multiplier(2) // 使用multiplier函数创建一个闭包
val result1 = multiplyByTwo(5) // 调用闭包
println(result1) // 输出结果为10
val multiplyByThree = multiplier(3) // 使用multiplier函数创建另一个闭包
val result2 = multiplyByThree(5) // 调用另一个闭包
println(result2) // 输出结果为15
在上述示例中,multiplier函数接受一个整数参数factor,并返回一个闭包,闭包是一个匿名函数(x: Int) => x * factor。在闭包中,factor是一个自由变量,它被捕获并保存在闭包中,即使在闭包被调用时,factor的定义已经超出了其作用域。因此,每次调用闭包时,它都可以访问和使用正确的factor值,实现了状态的保留。
闭包在许多场景下非常有用,例如:
- 创建高阶函数时,可以使用闭包将函数作为参数传递,并携带额外的上下文信息。
- 在函数式编程中,闭包可以用于构建递归函数,其中函数自身作为参数传递给递归调用。
- 在异步编程中,使用闭包可以捕获异步操作完成后的结果,并进行后续处理。
需要注意的是,在使用闭包时,需要谨慎处理自由变量的生命周期,确保不会发生对已经超出作用域的变量的意外引用。另外,闭包可能会引起内存泄漏,因此需要适度使用,避免额外的资源占用。