The Power of Scale for Parameter-Efficient Prompt Tuning及prefix tuning与prompt tuning的区别
1.本文贡献
(1)提出prompt tuning,并在大型语言模型领域展示其与model tuning(fine tuning)的竞争力;
(2)减少了许多设计选择,显示质量和鲁棒性随着规模的增加而提高。
(3)在域转移问题上,显示prompt tuning优于model tuning。
(4)提出“prompt ensembling”,并展示其有效性。
2.Prompt tuning
在GPT-3中,提示标记P={p1,p2,…,pn}的表示是模型embedding table的一部分,由冻结θ参数化(模型嵌入表原来不适合于GPT3,后经过预训练后,词语的嵌入表示适合与GPT3,也就相当于被模型的参数参数化了,而提示又是离散的,且是嵌入表中的词,所以说是被模型的参数参数化了)。与GPT-3相比,Prompt tuning有其自己的参数,而不是像GPT-3那样参数被模型的参数Θ参数化。
prompt design涉及从一个固定的冻结的嵌入的词表中寻找prompt token,而prompt tuning被认为使用一个固定的特殊token的提示,这些提示的token可以被更新。所以新形式的条件生成就变为;,最大化其概率,通过反向传播,使用梯度下降的方法更新即可。
本文使用的是T5模型。输入n个tokens形成一个n*e的xe矩阵,我们的soft prompts被表示为一个p*e的Pe矩阵,p为提示的长度。提示和输入连接起来变成(p+n)*e的矩阵[Pe;xe]。
2.1 三种初始化提示表示的方法
(1)使用随机初始化
(2)使用模型词表中的嵌入进行初始化
(3)对于分类任务,枚举输出类别的嵌入进行初始化
由于想要模型产生输出里的token,所以使用valid target token的嵌入来初始化,使得模型将其输出限制到合法的输出类别中。(后边经过实验验证发现,用类别相关的token进行初始化,最终学到的提示向量,使用余弦距离找其最近的向量,可以发现初始化的token在所学的提示向量附近。所以说使用target token进行初始化,最终不会产生奇怪的不合法的输出)。
2.2 T5模型相关实验
T5模型的预训练任务是span corruption,最终的输出会带有sentinel token(哨兵标记),输入是"Thank you
进行了T5模型的三个实验:
(1)"Span Courruption": 我们使用预先训练过的T5现成模型作为我们的冻结模型,并测试其为下游任务输出预期文本的能力。
(2)"Span Corruption+ Sentinel":我们使用相同的模型,但在所有下游目标之前都有一个哨兵,以便更接近训练前看到的目标。
(3)"LM Adaptation":继续使用T5的自监督训练,并且进行少量的额外步骤,在额外步骤中,使用LM目标,来尽力的在输出的目标中消除哨兵标记(本人理解:使用LM的目标函数作为损失函数来尽力消除哨兵标记这种非自然倾向)。
通过LM Adaptation,我们希望“快速”将T5转换为更类似于GPT-3的模型,该模型始终输出真实文本,并且作为“少数镜头学习者”能够很好地响应提示。与从头开始的前期培训相比,这一后期转变的成功程度尚不明显,据我们所知,之前也没有对其进行过调查。因此,我们对不同长度的自适应进行了实验,最多可达100K步。
3.结果部分
冻结模型建立在预先培训的各种尺寸(Small、Base、Large、XL、XXL)的T5之上。
"默认"配置是用绿色“×”绘制的,它使用了经过额外100K步训练的LM-adapted版本的T5,使用类标签进行初始化,并使用100个标记的提示长度。
在SuperGLUE基准测试(Wang等人,2019a)上衡量绩效,该测试包括八项具有挑战性的英语语言理解任务。
每一个提示都是在单个的SuperGLUEtask任务上进行训练,没有多任务的设置,也没有跨任务的训练数据混合。
考虑两个baselines:
(1)"Model Tuning":使用T5模型对每个任务进行微调
(2)"Model Tuning(Multi-task)":在T5模型中微调多个任务,使用任务名字作为前缀。
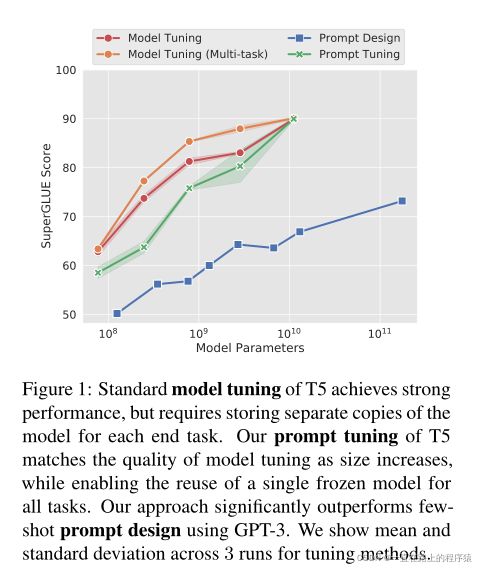
上图可以看到,随着规模的增加,prompt tuning与model tuning,具有了可比的效果。同时可以看到prompt tuning击败了GPT3的prompt design。
实验一、探索前缀长度
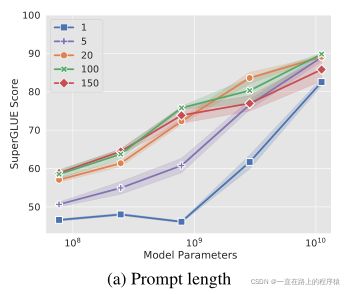
对于大多数model size来说,将提示长度增加到超过一个长度对于实现良好性能至关重要。值得注意的是,XXL模型仍然通过一个标记提示给出了强有力的结果,这表明模型越大,实现目标行为所需的条件信号就越少(也就是说需要的提示信息越少)。在所有模型中,增加超过20个token只会产生边际收益(超过20个token会导致性能产生下降,超过20个token之后,同样的模型大小,超过20个前缀长度的模型性能会在某个点低于使用20个token前缀长度的模型)。
实验二、探索前缀初始化
(1)对于随机初始化,从[−0. 5,0. 5]范围内均匀采样。
(2)当从样本词汇中初始化时,我们将T5的句子块词汇(Kudo and Richardson,2018)中最“常见”的根据训练前语料库中的可能性排序的5000个标记限制在范围内,从这5000词中选择进行初始化
(3)对于类别标签初始化,获取在下游任务中每个类的字符串表示嵌入(verbalizer将标签映射到的标签词空间中的那些标签词的嵌入表示),并使用它们初始化提示符中的一个标记。

实验三、预训练目标

从图标中可以看出之前的假设是正确的,即T5模型默认的"Span Corruption"的目标不适合训练冻结的、以后根据提示进行调整的语言模型。预先训练读写哨兵标记的模型很难直接应用于没有哨兵的文本读写任务。即使在下游任务的目标中加入了哨兵标记,Span Corruption+Sentinel,却发现性能只有一点点的改进。
在非最优的“Span Corruption”设置中,我们观察到不同模型大小的不稳定性,小模型的表现优于较大的基础模型、大模型和XL模型。通过检查,发现对于许多任务,这些中型模型从未学会输出合法的类别标签,因此得分为0%。最常见的两种错误模式是从输入中复制子span和预测空字符串。这种较差的性能并不是由于prompt tuning中的随机变化造成的,因为作者观察到对于每一个大小的模型,3次运行之间的prompt差异较小。
实验四、与类似方法的比较
(1)prefix tuning:学习一系列在每一个transformer层以及输入层预先设置好的前缀。与此相反,prompt tuning使用加在embedding input前的单个提示表示。后者除了需要更少的参数外,还允许transformer根据输入示例的上下文更新中间层任务表示。而prefix tuning却不行,因为他的每一层都有prefix参数所以在每一层都会更新任务的表示。同时prefix tuning需要前缀的重新参数化来稳定学习,这会在训练期间添加大量参数。而prompt tuning则不需要重新参数化。
(2)WARP:把提示参数添加到输入层。该方法运用MLM运作,依赖[mask]标签和一个可以学习的输出层,输出层将[mask]标签映射给class logits。Prompt tuning不需要对输入做任何的改变,其性能与fine tuning的性能接近。
(3)P-tuning:可学习的连续提示使用人类设计的模式(模板)在整个嵌入输入中交错。Prompt-tuning不需要如此复杂,只需要在输入前添加提示即可。
…..
实验五、domain shift
输入的分布在训练和测试集不同,就可以称之为domain shift。

在大多数域外数据集上,Prompt tuning优于Model tuning,具有显著的优势。在领域转移较大的情况下(Biomedical in BioASQor to Textbooks in TextbookQA),Prompt的收益更大。
作为对域转移鲁棒性的第二个测试,探索了GLUE中两个释义检测任务之间的转换。
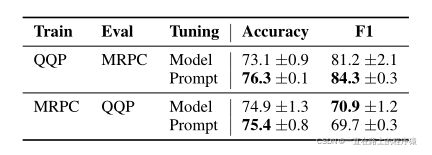
QQP到MRPC,使用Prompt tuning精度提高了3个点,F1提高了3个点;MRPC到QQP,精度提高了1个点,F1下降了1个点。相比来看,Model容易对训练数据过拟合,导致其性能低于prompt tuning
实验六、Prompt Ensembling
对同一数据进行不同初始化训练的神经模型集合被观察到可提高任务性能(Hansen和Salamon,1990),并可用于估计模型不确定性。
随着模型的增大,存储N个神经网络的副本变得不太显示。但是有了prompt tuning,可以在相同的任务上训练N个prompt存储起来(相当于对一个任务创建N个独立的模型)。
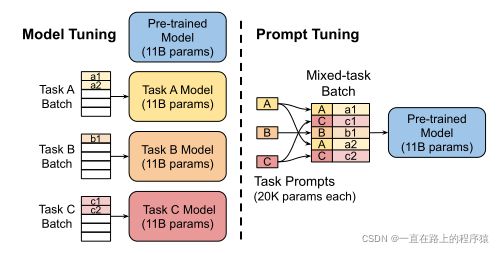
为每一个SuperGLUE任务使用T5-XXL训练了5个提示,使用简单多数投票来计算集合的预测。实验效果如下图所示:

实验七、Interpretability
为了测试我们学习的soft prompt的可解释性,从冻结模型的词汇表中计算每个提示标记的最近邻,使用词汇嵌入向量和提示标记表示之间的余弦距离作为相似性度量。
观察结果,对于给定的学习提示标记,前5个最近邻形成紧密的语义簇。例如,我们看到词汇上相似的集群,比{Technology/Technology/Technologies/Technology/Technologies},以及更加多样化但仍然密切相关的集群,如{entirely/completely/totally/altogether/100%}。这些集群的性质表明,提示实际上是在学习“类词”表征。我们发现,从嵌入空间中提取的随机向量不显示这种语义聚类(意思是随机向量的前五个最近邻不会形成语义簇)。
当使用“class label”策略初始化提示时,经常发现类标签会通过训练保持不变。具体地说,如果提示token被初始化为给定的标签,则该标签通常在调优后位于学习令牌的最近邻居中。当使用“Random Uniform”或“Sampled Vocab”方法初始化时,也可以在Prompt的最近邻中找到类标签;然而,它们倾向于作为多个Prompt token的邻居出现。这表明模型正在学习将预期的输出类存储在提示中作为参考,而初始化提示到输出类会使这更容易、更集中。
当测试较长的Prompt(例如长度为100)时,我们通常会发现几个具有相同近邻的提示标记。这表明提示中存在容量过剩,或者提示表示中缺少顺序结构,使得模型难以将信息定位到特定位置。