基于YOLOv8+PyQt5实现的共享自行车识别检测系统,含数据集+模型+精美GUI界面(可用于违规停放检测告警项目)

系列文章目录
文章目录
- 系列文章目录
- 前言
-
- 欢迎来到我的博客!我很高兴能与大家分享关于基于YOLOv8的共享自行车识别检测,违规停放告警系统的内容。
- 一、系统特点
-
- 7. 带有训练部分标注好的数据集,训练集、验证集
- 二、环境配置
-
- 2.anaconda环境导入pycharm
- 三、数据准备
-
- 1.收集制作图片数据
- 2.labelImg标注工具标注为voc格式或yolo格式标签
- 四、开始训练模型
-
- 1.修改train.py文件
- 2.运行train.py开始训练
- 3.训练好的模型及评估指标
- 五、PyQt5开发系统GUI界面对接YOLOv8算法模型
-
- 1.界面开发关键步骤如下:
- 2.GUI界面a示例代码如下
- 3.GUI界面b示例代码如下:
- 六、YOLOv8+GUI界面检测演示
-
- 1.GUI界面a界面效果(高级)
- 2.GUI界面b界面效果(简易版)
- 七、基于YOLOv8+PyQt5实现的共享自行车识别检测系统源码,含数据集+模型+精美GUI界面(可用于违规停放检测告警项目)
-
- GUI界面a(高级)系统源码
- GUI界面b(基础版)系统源码
- 总结
前言
欢迎来到我的博客!我很高兴能与大家分享关于基于YOLOv8的共享自行车识别检测,违规停放告警系统的内容。
基于YOLOv8共享自行车违规停放检测项目,一般用于智慧城市,智慧交通智能摄像头上。实现该项目主要分三步。第一步,训练检测自行车的模型,使用YOLOv8识别检测出自行车,得到自行车的在画面中的坐标信息(x1,y1,x2,y2);第二步手动设定停放区,可以是不规则多边形,也可以是矩形(后面判断简单些),其中区域也可以使用关键点坐标来表示;第三步,通过区域相交算法或者其他算法来判断目标框是否与划定区域有相交重叠,矩形相交可以看我这篇【深度学习笔记】目标检测之区域入侵判断代码
提示:以下是本篇文章正文内容
一、系统特点
- 采用最新最优秀的目标检测算法YOLOv8
- 系统分别基于PyQt5开发了两种GUI图形界面,供大家学习使用
- 系统可以检测本地图片或者视频,也可以实时检测网络视频流,另外可调整IUO阈值,置信度阈值等参数
- 系统可升级,带有语音提醒功能,告警抓拍上传,发送告警邮件等功能
- 部署简单,适合windows、Linux、Mac系统,安装好requirement.txt中的包即可
- 系统带有本人训练好的YOLOv8模型,可直接调用使用,另外附有训练得的评估指标曲线PR_curve、F1_curve、R_curve、训练日志等,无需自己训练
7. 带有训练部分标注好的数据集,训练集、验证集
二、环境配置
1、在anaconda中安装必要的软件包
2、安装pycharm,在pycharm中运行项目
3、以下内容都是在完成1、2两步的基础上进行,很多博客有介绍,在此不必赘述>requirements.txt如下:
# Usage: pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.2.2
opencv-python>=4.6.0
Pillow>=7.1.2
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.64.0
pandas>=1.1.4
seaborn>=0.11.0
psutil # system utilization
2.anaconda环境导入pycharm
可参考的博客很多,主要针对该工程导入刚安装的python环境(如envs/YOLOv8/python.exe)
三、数据准备
1.收集制作图片数据
可网络爬取,或者自己模拟拍摄制作
本系统训练的数据集部分图片如下所示:

2.labelImg标注工具标注为voc格式或yolo格式标签
voc格式和yolo格式都可以互相转换,标注任意格式都可以
voc格式如下:
标注的类别有:【自行车】
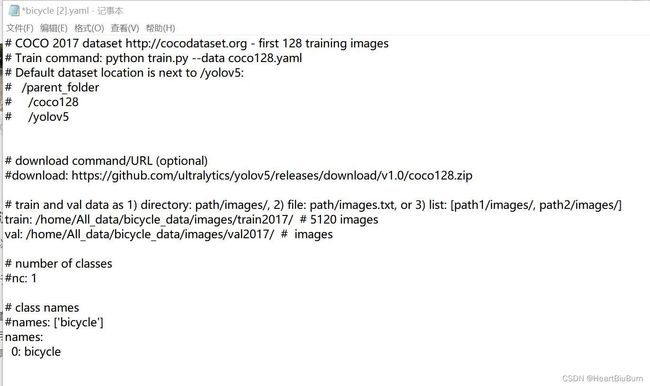
训练模型是yolov8算法中的yaml配置文件bicycle.yaml如下图所示:
红色框为数据集图片与标签保存路径,names为数据类别
可以按照该方式训练其他模型,训练模型的方法基本与YOLOv5一样。
# Ultralytics YOLO , GPL-3.0 license
from copy import copy
import numpy as np
import torch
import torch.nn as nn
from ultralytics.nn.tasks import DetectionModel
from ultralytics.yolo import v8
from ultralytics.yolo.data import build_dataloader
from ultralytics.yolo.data.dataloaders.v5loader import create_dataloader
from ultralytics.yolo.engine.trainer import BaseTrainer
from ultralytics.yolo.utils import DEFAULT_CFG, RANK, colorstr
from ultralytics.yolo.utils.loss import BboxLoss
from ultralytics.yolo.utils.ops import xywh2xyxy
from ultralytics.yolo.utils.plotting import plot_images, plot_labels, plot_results
from ultralytics.yolo.utils.tal import TaskAlignedAssigner, dist2bbox, make_anchors
from ultralytics.yolo.utils.torch_utils import de_parallel
# BaseTrainer python usage
class DetectionTrainer(BaseTrainer):
def get_dataloader(self, dataset_path, batch_size, mode='train', rank=0):
# TODO: manage splits differently
# calculate stride - check if model is initialized
gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)
return create_dataloader(path=dataset_path,
imgsz=self.args.imgsz,
batch_size=batch_size,
stride=gs,
hyp=vars(self.args),
augment=mode == 'train',
cache=self.args.cache,
pad=0 if mode == 'train' else 0.5,
rect=self.args.rect or mode == 'val',
rank=rank,
workers=self.args.workers,
close_mosaic=self.args.close_mosaic != 0,
prefix=colorstr(f'{mode}: '),
shuffle=mode == 'train',
seed=self.args.seed)[0] if self.args.v5loader else \
build_dataloader(self.args, batch_size, img_path=dataset_path, stride=gs, rank=rank, mode=mode,
rect=mode == 'val', names=self.data['names'])[0]
def preprocess_batch(self, batch):
batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255
return batch
def set_model_attributes(self):
# nl = de_parallel(self.model).model[-1].nl # number of detection layers (to scale hyps)
# self.args.box *= 3 / nl # scale to layers
# self.args.cls *= self.data["nc"] / 80 * 3 / nl # scale to classes and layers
# self.args.cls *= (self.args.imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
self.model.nc = self.data['nc'] # attach number of classes to model
self.model.names = self.data['names'] # attach class names to model
self.model.args = self.args # attach hyperparameters to model
# TODO: self.model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc
def get_model(self, cfg=None, weights=None, verbose=True):
model = DetectionModel(cfg, ch=3, nc=self.data['nc'], verbose=verbose and RANK == -1)
if weights:
model.load(weights)
return model
def get_validator(self):
self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'
return v8.detect.DetectionValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))
def criterion(self, preds, batch):
if not hasattr(self, 'compute_loss'):
self.compute_loss = Loss(de_parallel(self.model))
return self.compute_loss(preds, batch)
def label_loss_items(self, loss_items=None, prefix='train'):
"""
Returns a loss dict with labelled training loss items tensor
"""
# Not needed for classification but necessary for segmentation & detection
keys = [f'{prefix}/{x}' for x in self.loss_names]
if loss_items is not None:
loss_items = [round(float(x), 5) for x in loss_items] # convert tensors to 5 decimal place floats
return dict(zip(keys, loss_items))
else:
return keys
def progress_string(self):
return ('\n' + '%11s' *
(4 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')
def plot_training_samples(self, batch, ni):
plot_images(images=batch['img'],
batch_idx=batch['batch_idx'],
cls=batch['cls'].squeeze(-1),
bboxes=batch['bboxes'],
paths=batch['im_file'],
fname=self.save_dir / f'train_batch{ni}.jpg')
def plot_metrics(self):
plot_results(file=self.csv) # save results.png
def plot_training_labels(self):
boxes = np.concatenate([lb['bboxes'] for lb in self.train_loader.dataset.labels], 0)
cls = np.concatenate([lb['cls'] for lb in self.train_loader.dataset.labels], 0)
plot_labels(boxes, cls.squeeze(), names=self.data['names'], save_dir=self.save_dir)
# Criterion class for computing training losses
class Loss:
def __init__(self, model): # model must be de-paralleled
device = next(model.parameters()).device # get model device
h = model.args # hyperparameters
m = model.model[-1] # Detect() module
self.bce = nn.BCEWithLogitsLoss(reduction='none')
self.hyp = h
self.stride = m.stride # model strides
self.nc = m.nc # number of classes
self.no = m.no
self.reg_max = m.reg_max
self.device = device
self.use_dfl = m.reg_max > 1
roll_out_thr = h.min_memory if h.min_memory > 1 else 64 if h.min_memory else 0 # 64 is default
self.assigner = TaskAlignedAssigner(topk=10,
num_classes=self.nc,
alpha=0.5,
beta=6.0,
roll_out_thr=roll_out_thr)
self.bbox_loss = BboxLoss(m.reg_max - 1, use_dfl=self.use_dfl).to(device)
self.proj = torch.arange(m.reg_max, dtype=torch.float, device=device)
def preprocess(self, targets, batch_size, scale_tensor):
if targets.shape[0] == 0:
out = torch.zeros(batch_size, 0, 5, device=self.device)
else:
i = targets[:, 0] # image index
_, counts = i.unique(return_counts=True)
out = torch.zeros(batch_size, counts.max(), 5, device=self.device)
for j in range(batch_size):
matches = i == j
n = matches.sum()
if n:
out[j, :n] = targets[matches, 1:]
out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))
return out
def bbox_decode(self, anchor_points, pred_dist):
if self.use_dfl:
b, a, c = pred_dist.shape # batch, anchors, channels
pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)
return dist2bbox(pred_dist, anchor_points, xywh=False)
def __call__(self, preds, batch):
loss = torch.zeros(3, device=self.device) # box, cls, dfl
feats = preds[1] if isinstance(preds, tuple) else preds
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
(self.reg_max * 4, self.nc), 1)
pred_scores = pred_scores.permute(0, 2, 1).contiguous()
pred_distri = pred_distri.permute(0, 2, 1).contiguous()
dtype = pred_scores.dtype
batch_size = pred_scores.shape[0]
imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
# targets
targets = torch.cat((batch['batch_idx'].view(-1, 1), batch['cls'].view(-1, 1), batch['bboxes']), 1)
targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)
# pboxes
pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
_, target_bboxes, target_scores, fg_mask, _ = self.assigner(
pred_scores.detach().sigmoid(), (pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor, gt_labels, gt_bboxes, mask_gt)
target_bboxes /= stride_tensor
target_scores_sum = max(target_scores.sum(), 1)
# cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
# bbox loss
if fg_mask.sum():
loss[0], loss[2] = self.bbox_loss(pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores,
target_scores_sum, fg_mask)
loss[0] *= self.hyp.box # box gain
loss[1] *= self.hyp.cls # cls gain
loss[2] *= self.hyp.dfl # dfl gain
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
def train(cfg=DEFAULT_CFG, use_python=False):
model = cfg.model or './yolov8s.pt'
data = cfg.data or './data/bicycle.yaml' # or yolo.ClassificationDataset("mnist")
device = cfg.device if cfg.device is not None else ''
args = dict(model=model, data=data, device=[0,1,2,3])
#args = dict(model=model, data=data, device=device)
if use_python:
from ultralytics import YOLO
YOLO(model).train(**args)
else:
trainer = DetectionTrainer(overrides=args)
trainer.train()
if __name__ == '__main__':
train()
四、开始训练模型
放置好标注好的数据集(图片和标签文件),在yaml文件中配置对存放路径,以及数据集类别信息。
1.修改train.py文件
找到ultralytics-main/ultralytics/yolo/v8/detect文件夹,打开train.py,如下图所示:
2.运行train.py开始训练
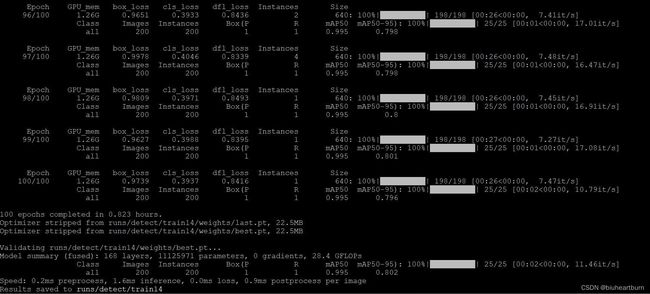
注意: YOLOv8训练过程与YOLOv5、YOLOv7有一点不同,在训练模型时,起始设定训练100个epoch,当训练到60epoch时,精度基本稳定,评估指标不在提升,则训练会提前结束,保存当前最好的模型。
3.训练好的模型及评估指标
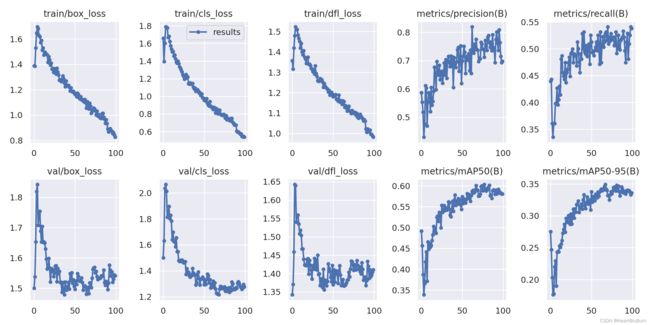
训练结束后,保存模型的文件夹包含:weights、args.yaml、confusion_matrix.png、confusion_matrix_normalized.png、F1_curve.png、labels.jpg、labels_correlogram.jpg、P_curve.png、PR_curve.png、R_curve.png、results.csv、results.png等等。
这些评估指标曲线和表可以用于论文或者报告中,也可以通过曲线评比模型训练好坏,掌握数据分布情况等。









五、PyQt5开发系统GUI界面对接YOLOv8算法模型
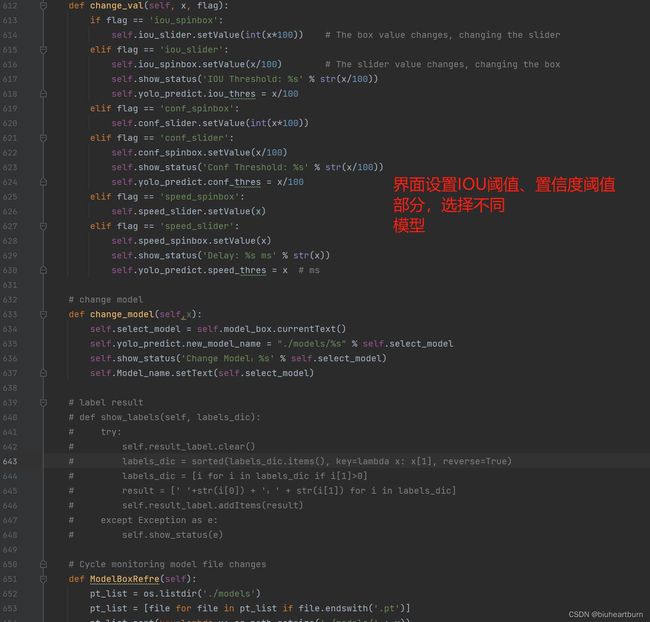
1.界面开发关键步骤如下:
- 安装PyQt5:首先,确保你已经安装了Python和PyQt5库。你可以使用pip命令在终端中安装PyQt5:pip install pyqt5
- 设计GUI界面:使用Qt Designer工具来设计GUI界面。Qt Designer是一个可视化界面设计工具,可以帮助你创建GUI界面并生成.ui文件。你可以在终端中运行designer命令来启动Qt Designer。
- 创建主窗口类:在Python代码中创建一个主窗口类,继承自QtWidgets.QMainWindow。在类中,你可以定义界面的布局、按钮、标签等控件,并连接它们的信号和槽函数。
- 加载.ui文件:使用QtUiTools模块中的QUiLoader类来加载之前设计好的.ui文件。这将把.ui文件中的控件转换为Python对象。
- 实现目标检测算法:在Python代码中实现YOLOv8目标检测算法。你可以使用OpenCV库加载图像或视频,并将其传递给YOLOv8模型进行目标检测。根据检测结果,你可以在GUI界面上绘制边界框或显示检测结果。
- 连接信号和槽函数:在主窗口类中,使用QtCore.QObject.connect()函数将控件的信号连接到槽函数。例如,你可以将一个按钮的点击信号连接到一个槽函数,以触发目标检测算法的执行。
- 运行应用程序:在Python代码的主函数中,创建一个QApplication对象,并实例化主窗口类。最后,调用QApplication对象的exec_()方法来运行应用程序。
- 通过按照以上步骤,你可以开发一个基于PyQt5的YOLOv8目标检测算法GUI界面。这样,用户可以通过界面加载图像或视频,并实时进行目标检测,从而更方便地使用该算法。
2.GUI界面a示例代码如下
3.GUI界面b示例代码如下:
from PyQt5.Qt import *
from PyQt5.QtCore import QThread,pyqtSignal
import sys
from jiemian import Ui_Form
from tkinter import filedialog
import tkinter as tk
import cv2
import torch
import glob
import ultralytics
from ultralytics import YOLO
class Window(QWidget,Ui_Form):
def __init__(self):
super().__init__()
self.setupUi(self)
self.setAttribute(Qt.WA_StyledBackground, True)
self.pushButton_3.clicked.connect(self.get_model)
#self.pushButton.clicked.connect(self.get_img)
self.pushButton_2.clicked.connect(self.get_video)
self.pushButton_4.clicked.connect(self.dectect)
self.dec_thread = detection_thread()
self.img_path = ''
self.video_path = ''
self.model_path = ''
def dectect(self):
self.dec_thread.img_path = self.img_path
self.dec_thread.video_path = self.video_path
self.dec_thread.model_path = self.model_path
self.dec_thread.img.connect(self.show_img)
self.dec_thread.start()
def show_img(self, img):
image = self.resize_img(img, self.label.width(), self.label.height())
ori_img = QImage(image[:], image.shape[1], image.shape[0], image.shape[1] * 3, QImage.Format_RGB888)
ori_pixmap_img = QPixmap.fromImage(ori_img)
self.label.setPixmap(ori_pixmap_img)
self.label.setAlignment(Qt.AlignCenter)
def resize_img(self, img, label_w, label_h):
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
if img.shape[0] > label_h or img.shape[1] > label_w:
size = min(label_h / img.shape[0], label_w / img.shape[1])
else:
size = 1
img = cv2.resize(img, dsize=(int(img.shape[1] * size), int(img.shape[0] * size)), interpolation=cv2.INTER_AREA)
return img
def get_video(self):
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename()
if path:
self.video_path = path
self.dec_thread.trans = True
def get_img(self):
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename()
if path:
self.img_path = path
self.dec_thread.trans = False
def get_model(self):
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename()
if path:
self.model_path = path
六、YOLOv8+GUI界面检测演示
1.GUI界面a界面效果(高级)
运行main.py自动弹出界面

运行main_b.py自动弹出界面


七、基于YOLOv8+PyQt5实现的共享自行车识别检测系统源码,含数据集+模型+精美GUI界面(可用于违规停放检测告警项目)
GUI界面a(高级)系统源码
下载地址:https://download.csdn.net/download/DeepLearning_/88298396
包含:GUI界面+YOLOv8源码+训练好模型+部分数据集+各种评估指标及训练日志+部署操作说明文档
GUI界面b(基础版)系统源码
下载地址:https://download.csdn.net/download/DeepLearning_/88298429
包含:GUI界面+YOLOv8源码+训练好模型+部分数据集+各种评估指标及训练日志+部署操作说明文档
总结
在本博客中,我们介绍了基于YOLOv8+PyQt5实现的共享自行车识别检测系统,含数据集+模型+精美GUI界面(可用于违规停放检测告警项目)。通过结合计算机视觉和深度学习技术,我们开发了一个实时共享自行车违规停放识别检测系统,并及时发出警报,说出需求,可私信博主可升级。通过结合先进的目标检测算法和强大的GUI开发库,我们可以创建一个功能强大的系统,为智慧城市出力。并附上了项目开发的源代码和部署文档,欢迎大家提问交流,互相学习!