正则表达式
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a到z之间的字母)和特殊字符(称为“元字符”),是计算机科学的一个概念。
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。许多程序设计语言都支持利用正则表达式进行字符串操作。
测试地址:
https://c.runoob.com/front-end/854/1.匹配单个字符
.字符(英文句号)可以匹配任何一个单个的字符。
.字符可以匹配任何单个的字符、字母、数字甚至是.字符本身。
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xIs
na1.xls
na2.xls
sa1.xls正则表达式
sales.匹配结果
sales1
sales2
sales3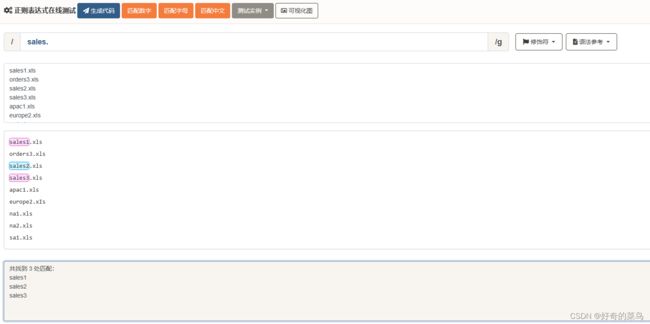
2.转义字符匹配
.字符在正则表达式里有着特殊的含义。如果模式里需要一个.,就要想办法来告诉正则表达式你需要的是.字符本身而不是它在正则表达式里的特殊含义。为此,你必须在.的前面加上一个\(反斜杠)字符来对它进行转义。
原始字符串:
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xIs正则表达式:
sales.\.xls匹配结果
sales1.xls
sales2.xls
sales3.xls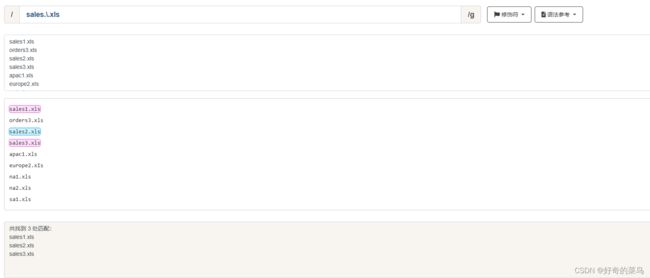
3、匹配多个字符中的某一个
在正则表达式里,我们可以使用元字符[和]来定义一个字符集合。在使用[和]定义的字符集合里,这两个元字符之间的所有字符都是该集合的组成部分,字符集合的匹配结果是能够与该集合里的任意一个成员相匹配的文本。
原始字符串:
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
na1.xls
na2.xls
sa1.xls
ca1.xls正则表达式:
[ns]a.\.xls匹配结果:
na1.xls
na2.xls
sa1.xls
4、使用连字符
在使用正则表达式的时候,会频繁地用到一些字符区间(0~9、A~Z,等等)。为了简化字符区间的定义,正则表达式提供了一个特殊的元字符——字符区间可以用-(连字符)来定义。
(连字符)是一个特殊的元字符,作为元字符它只能用在[和]之间。在字符集合以外的地方,-只是一个普通字符,只能与-本身相匹配。因此,在正则表达式里,-字符不需要被转义。
在定义一个字符区间的时候,一定要避免让这个区间的尾字符小于它的首字符(例如[3-1])。这种区间是没有意义的,而且往往会让整个模式失效。
原始字符创:
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
na1.xls
na2.xls
sa1.xls
ca1.xls正则表达式:
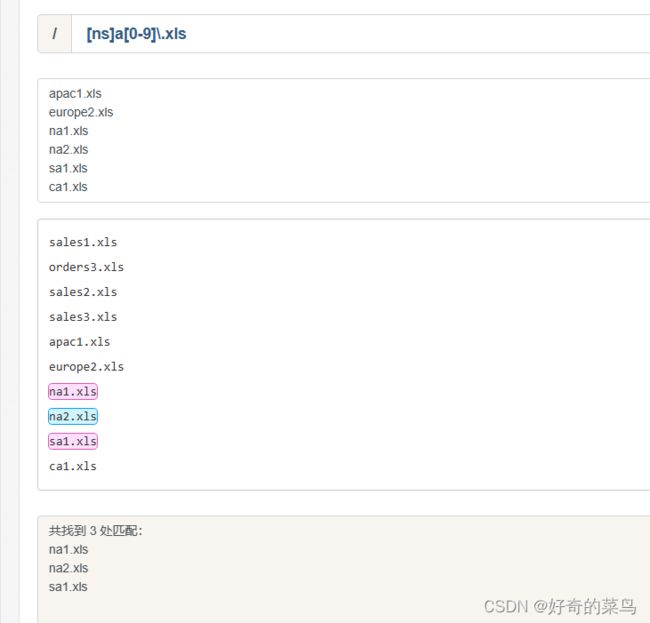
[ns]a[0123456789]\.xls
[ns]a[0-9]\.xls匹配结果:
na1.xls
na2.xls
sa1.xls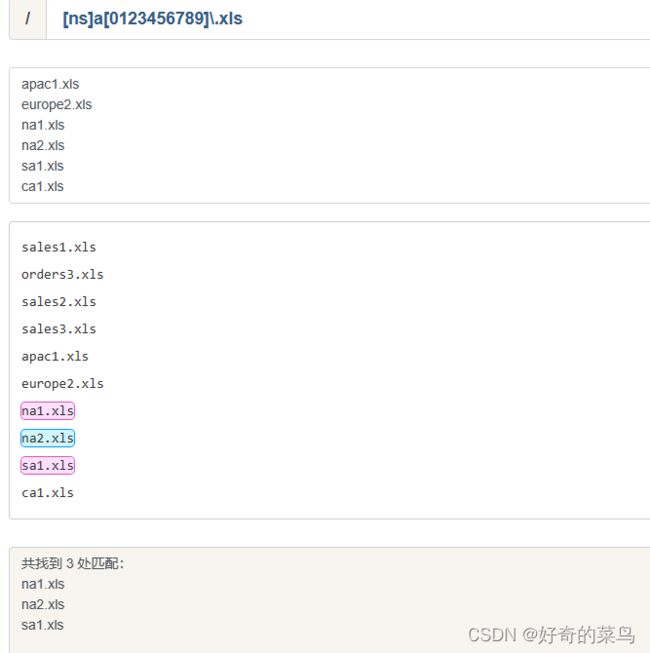
5、取非匹配
用元字符^来表明你想对一个字符集合进行取非匹配——这与逻辑非运算很相似。
原字符串:
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
sam.xml
na1.xls
na2.xls
sa1.xls
ca1.xls正则表达式:
[ns]a[^0-9]\.xml结果:
sam.xml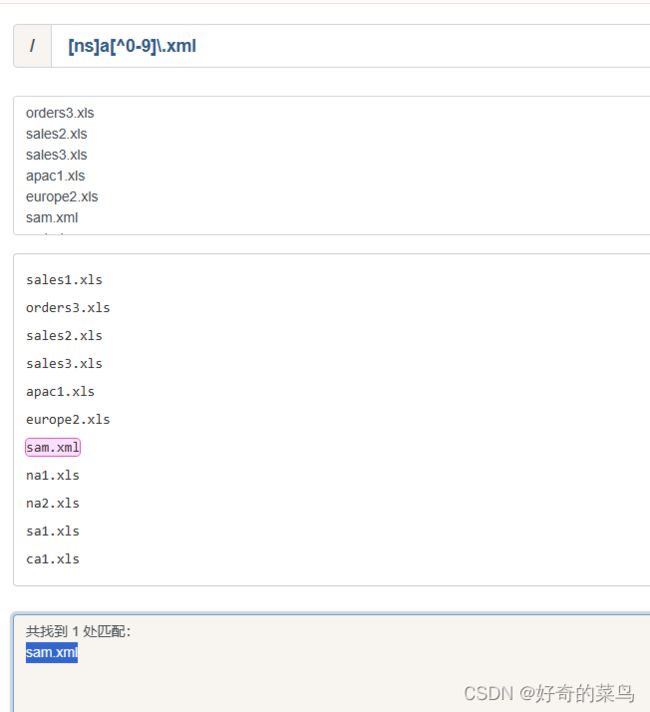
6、空白字符

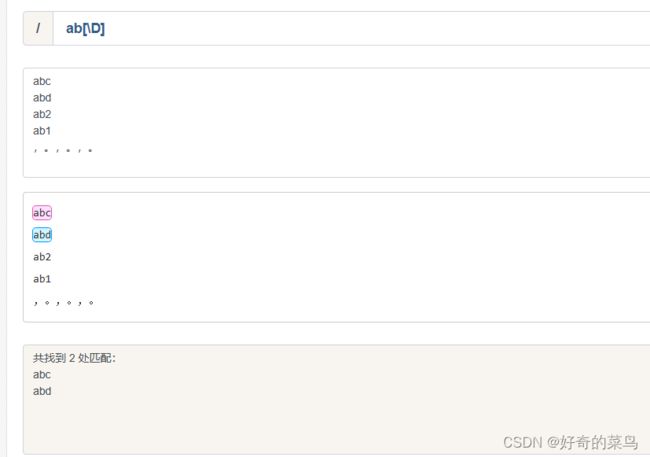
7、匹配数字和非数字

#字符串
abc
abd
ab2
ab1
,。,。,。
#正则表达式
ab[\d]
#结果
ab2
ab1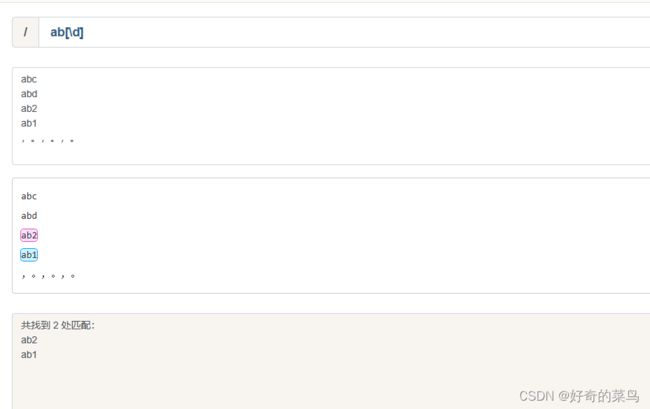
8、匹配字母和数字

#字符串
11213
A1C2E3
48075
48237
M1B4F2
90046
H1H2H2
#正则表达式
\w\d\w\d\w\d
#结果
A1C2E3
M1B4F2
H1H2H2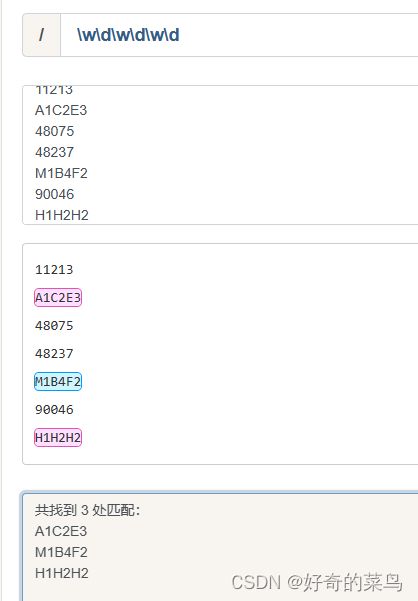
9、匹配空白字符和十六进制、八进制数

在正则表达式里,十六进制(逢16进1)数值要用前缀\x来给出。比如说,\x0A对应于ASCII字符10(换行符),其效果等价于\n。
在正则表达式里,八进制(逢8进1)数值要用前缀\0来给出,数值本身可以是两位或三位数字。比如说,\011对应于ASCII字符9(制表符),其效果等价于\t。
10、POSIX字符类


这里使用的模式以[[开头、以]]结束(两对方括号)。这是使用POSIX字符类所必须的。POSIX字符类必须括在[:和:]之间,我们使用的POSIX字符类是[:xdigit:](不是:xdigit:)。外层的[和]字符用来定义一个字符集合,内层的[和]字符是POSIX字符类本身的组成部分。