转载自石晓文大佬的这篇文章:
https://www.jianshu.com/p/c0384b213320
基于物品的协同过滤ItemCF是推荐领域常用的方法,其关键是评估item之间的相似性。本文将要介绍Neural Attentive Item Similarity Model(简称NASI)来解决ItemCF问题。该模型将注意力机制和神经网络相结合,提升了模型的预测准确性。接下来,我们将从基本的ItemCF问题入手,一步步得出NASI模型。
1、ItemCF问题简介
1.1 标准ItemCF问题
为了预测用户u对于物品i的评分,ItemCF的最基本思想是计算物品i与用户u之前交互过的所有物品的相似性,预测评分计算公式如下:
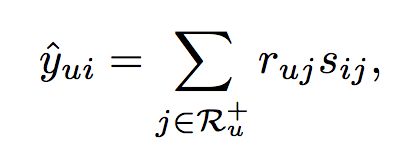
其中,Ru+是用户所有交互过的物品,ruj是用户u对物品j的反馈,sij是物品i和物品j的相似性。其中,ruj可以是显式的评分,如0-5评分,也可以是隐式的反馈,如点击为1,未点击为0。
物品之间的相似性,直观的方法是根据用户-物品交互矩阵,将物品i所在的列作为其向量表示,进一步使用余弦相似度等度量方式计算物品之间的相似性。但是这种方法缺乏针对推荐的优化,类似于一种静态方法,物品的向量不是通过优化得到的。因此性能并不是那么优秀。所以接下来我们将介绍Learning-based Methods,这些方法可以自适应地从数据中学习item相似度,从而提高itemCF的准确性。
1.2 Learning-based Methods for Item-based CF
Learning-based Methods通过优化一个目标函数,来学习item之间的相似性,如SLIM(short for sparse Linear Method)方法中,目标函数设定为:

上面的目标函数中,S代表物品的相似度矩阵。而预测评分的计算仍然基于1.1中的方法。假设物品个数为I,那么模型需要优化的参数有I * I个。上面的式子同时使用L1正则和L2正则,防止了过拟合,增加了模型的稀疏性。但也存在一定的缺点,当物品集数量很大时,参数太多难以优化,同时,模型只能学习同时被打过分的物品之间的两两的相似性。
为了解决这个问题,我们又有了FISM(short for factored item similarity model)方法,其用低维度嵌入向量表示每一个物品。对于每一个物品,都有两个嵌入向量p和q,当物品是预测的物品时,使用p,当物品是交互历史中的物品时,使用q,此时用户评分计算方式如下:
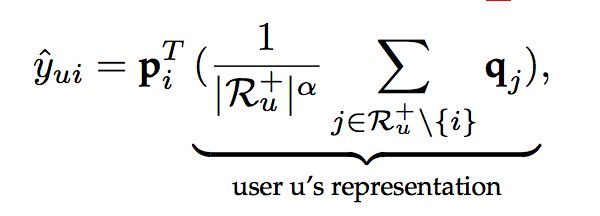
FISM只考虑隐式反馈。对于上面的预测模型,可以通过优化推荐的标准损失(对数损失或者平方损失)来学习物品的嵌入向量表示p和q。
虽然FISM方法取得了不错的性能,但我们认为,当获得用户的表示时,它对用户的所有历史项目的平等处理会限制其表示能力。因此,我们将注意力机制加入其中,用于区分历史item的重要性,提出了NASI模型。
2、NASI模型介绍
这里,我们仍然只考虑隐式反馈,模型设计过程如下:
2.1 第一版
在第一版的设计中,我们认为每个物品有一个固定的注意力权重aj,因此评分预测计算如下:
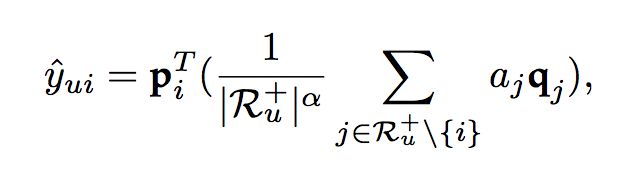
很显然,这是不合理的,我们没有考虑目标物品对于历史物品的影响。于是我们有了第二版设计。
2.2 第二版
在第二版的设计中,我们使用aij来表示历史物品j和目标物品i的权重,评分计算如下:

这样显然也是有缺陷的,当训练集中物品i和物品j没有同时出现过时,aij是无从学习的。于是我们有了第三版设计。
2.3 第三版
第三版设计中,我们使用嵌入向量计算出权重,即:

f通常用一个神经网络来表示,主流的计算方法有以下两种:
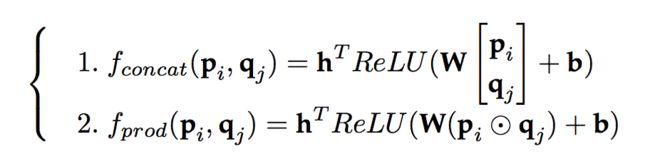
通过f计算出的权重,我们还需要通过softmax进行归一化,因此,评分预测的计算如下:
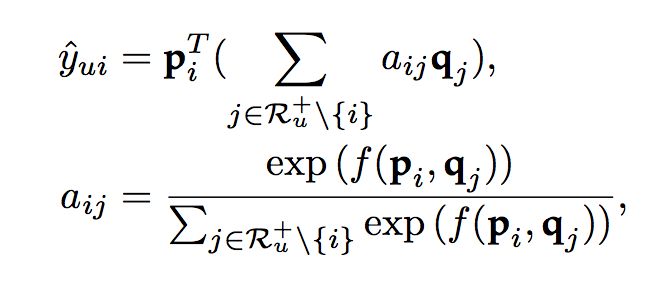
这么做看似是完美了,但是在实际的实验中,却没有取得理想的效果。这个问题主要来自softmax,在传统的注意力机制使用的场景中,如CV、NLP中,注意力机制的长度变化不是很大(这里的长度指图像中的区域个数,句子中单词的个数等等),但是在推荐领域中,用户的历史交互长度可能变化很大。在MovieLens和Pinnterest数据中,用户历史长度的分布如下图所示:

可以看到,对于两个真实数据集,用户的历史长度变化很大,具体而言,用户历史长度的均值和方差分别为(166,37145),(27,572)。在MovieLens数据集中,所有用户的平均长度为166,最大长度为2313。也就是说,最活跃用户的平均注意力权重是1/2313,比平均用户(即,1/166)少大约14倍。如此大的注意权重差异将导致优化模型的item嵌入是个问题。(可以简单的想,同样的物品i和物品j,在活跃用户和非活跃用户中得到的aij差异会非常大)
为了解决用户历史长度不同的问题,我们便有了最终版的NAIS模型。
2.4 最终版
在最终版的模型中,我们对活跃用户的注意力权重进行一定的惩罚,如下:
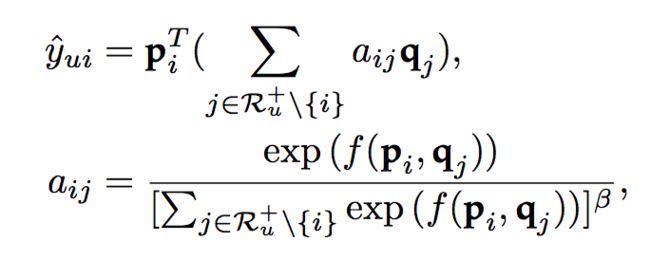
而模型的损失函数使用对数损失+L2正则:

模型的框架图如下:

好了,模型介绍就到这里了,关于模型中的一些细节,大家可以阅读原论文。
3、NASI代码实现
作者给出了Python2版本的代码:https://github.com/AaronHeee/Neural-Attentive-Item-Similarity-Model
这个代码在Python3中是无法运行的,主要是Python3中range函数得到的不是list,需要使用list()函数进行转换,Python3版本的代码地址:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-NAIS-Demo
作者:石晓文的学习日记
链接:https://www.jianshu.com/p/c695808100c7