Cloud Native 演进可行性研究
Paul Fremantle提出Cloud Native的原因是他一直想用一个词表达一种架构,这种架构能描述应用程序和中间件在云环境中的良好运行状态。
Cloud Native是以云和微服务架构为基础构建系统的

从研发流程的角度来讲,自动化的研发环境是Cloud Native的基础。因为使用云作为基础设施,已经具备基础的自动化能力,可以达到自服务的要求,流程中应该尽量减少沟通人员的规模,尽量减少测试及运维对开发的协助。
服务拆分的初衷:
在 Amazon 曾经出现过一个这样的问题,当团队人数快速增长之后,沟通效率越来越低,如何提高沟通效率呢?如何减少会议呢?最好的方式当然是不开会,那么怎么才能不开会却实现高效沟通呢?那就是让各个团队关注不同的模块。拆分服务就是一种方式,让每个团队独立负责一个服务,通过契约化的接口缩小沟通范围,只要接口不发生变化,就不需要过分关注外部的变化。这就是Amazon拆分服务的初衷。
交付速度的提高不能以降低可用性为代价。我们都知道更新是可用性的“天敌”,只要更新就可能发生故障。传统企业提升可用性的一种方法就是少发布、多审核,这显然是和高交付速度背道而驰的。Cloud Native通过一系列工具、方法减少发布导致的可用性问题,而不是减少发布次数。
微服务架构和微服务拆分就不在本文聊了,这种类型的文章太多了,就不浪费篇幅这里说了,我们主要围绕(可用性、可扩展性、一致性、研发流程)四个点来深入扩展
可用性:
- 切换上线
一般上线是一个痛苦的过程,为何痛苦?主要是因为需要根据服务流量的高低峰来确认合适的发布时间点,如果能够随时发布(想发就发)是不是就轻松很多,这个理想是需要背后强大且成熟的发布机制就行依赖的
影子测试:
影子测试是一种常用的在生产环境中通过流量复制、回放和比对的测试方法。

以上是基于日志实现的,还可以使用TCPCopy实现,直接复制生产环境上的请求实现验证,影子测试看上去好像可行且满足大多数需求,但是如果你的服务很多并且中间件很多,那么回放就会比较复杂,这种测试方法需要额外冗余一定的资源,依赖越多就会越复杂
金丝雀发布:
小说《鬼吹灯》里有一个场景,盗墓之前需要先点一根蜡烛,如果蜡烛熄灭,就要停止一切活动,另外一个方法就是放一只鸟进去探测空气质量。实际上,古代的矿井工人也经常利用金丝雀探测瓦斯,以便及时发现危险情况。灰度发布利用了同样的原理,在原有版本可用的情况下,同时部署一个新版本作为“金丝雀”,测试新版本的性能和表现,以保障在整体系统稳定的情况下,尽早发现问题并解决问题。
- 假设生产环境运行的是v1版本,从负载均衡列表中摘掉一个节点,作为“金丝雀”服务器。
- 在“金丝雀”服务器上部署v2版本。
- 进行自动化测试。
- 将v2版本节点添加到负载均衡列表中。
- 如果发生故障,则马上进行回滚。
- 如果没有问题,则逐步升级剩余的其他节点。

- 容错设计
异常是不可避免的一种情况,我们再做任何方案设计时都需要对异常的容错有明确指出,当出现异常的时候我们怎么自动恢复是很重要的
有一个故事,当飞行员学习飞行的时候,要飞到足够的高度,给自己预留足够的操作失误的时间,那么要飞多高呢?飞的高度至少要允许连续出现两次失误,这就是著名的“两次失误高度”。
当你希望系统有更高的可用性的时候,首先要做的就是消除单点,通过负载均衡分配流量,部署多个业务服务,存多份数据。
那么,为什么一般都要求节点数为n+2个而不是n+1个呢?有一种说法是,当你进行升级的时候,此时要升级一个节点,如果剩下两个节点正常提供服务,那么还可以允许一个节点失效。如果一共只有两个节点,升级一个节点,就只剩一个节点对外提供服务,那么一旦发生意外,就会比较惨。这无形中给了部署人员压力,压力之下更容易出错。
- 降级设计
当高出预期的流量来临时,无法做到快速扩展,也就是加机器起到的效果不理想,我们只能通过流控和降级来解决问题。
降级是指为了保障核心功能,利用目前有限的资源,通过开关手段暂时关闭非核心服务。暂时关闭意味着给用户体验带来一些影响,是有损操作。
- 容量预估
我们需要知道当前系统能够承受多大压力。传统预测方式是在测试环境下进行的,针对场景进行数据模拟,需要开发、测试人员根据线上的场景,评估可能出现的情况。
全链路压测平台在请求入口进行真实流量复制,开源实现可以参考TCPCopy。这样可以简化模拟数据带来的成本,将复制的请求引入压测环境,对压测环境的服务进行压力测试。为了加大压力,可以通过TCPCopy的参数调节,也可以通过MQ等工具“蓄水”。在数据库一侧通过影子表进行隔离,影子表和生产表建立相同的数据结构,通过后缀进行区分,便于隔离删除。如果害怕对生产环境造成影响,那么可以把生产表和影子表放到不同的数据库中。

- 故障演练
我们害怕发生故障,因此制定了很多应对策略,但是这些策略在没有测试的情况下谁也不敢轻易启用,害怕引起更严重的故障。例如,某互联网公司因为网络原因导致大规模故障,中断几个小时,是因为没有灾备吗?当然不太可能。虽然他们做了灾备,但是因为很长时间没有测试过了,所以并不敢切换,灾备成了一个应付领导的噱头。故障演练正是为了解决“不敢切换”的问题。
在这方面,Netflix一直走在前列。早在2010年的一篇博文中,Netflix的工程师John Ciancutti就有一句经典的话:“The best way to avoid failure is to fail constantly”,大意就是,避免失败最好的方式就是不断失败。2012年,Netflix开源了Chaos Monkey,Chaos Monkey是一个在生产环境随机选择并关闭服务的工具。对于这个选择,有人会觉得很疯狂,因为这些演练可能会对最终用户产生影响,但是通过这种频繁的演练,能够使开发人员对服务稳定性有更高的重视,更加关注Design for failure,以确保不会因为故障对最终用户产生更大的影响。可以在Chaos Monkey 上配置执行计划,默认只在工作日的上午9点至下午3点执行。
可扩展性:
数据1:Facebook在2009年每天产生3千万张照片;2013年每天产生3.5亿张照片;2015年每天产生20亿张照片。
数据2:阿里巴巴2009年首个“双11”活动,一天内的销售额为5千万元;2012年“双11”活动一天内的销售额为191亿元;2017年“双11”活动一天内的销售额为1682亿元,而且是11秒内销售额破亿元。
这么庞大且高并发产生的数据,单纯的加机器可以解决问题嘛?
- 横向扩展(scale out)也叫水平扩展,指用更多的节点支撑更大量的请求。例如如果1台机器支撑10 000TPS,那么两台机器是否能支撑20 000TPS?
- 横向扩展通常是为了提升吞吐量,响应时间一般要求不受吞吐量影响即可
- 纵向扩展(scale up)也叫垂直扩展,扩展一个点的能力支撑更大的请求,它通常通过提升硬件实现,例如把磁盘升级为SSD。
- 纵向扩展提升单机能力
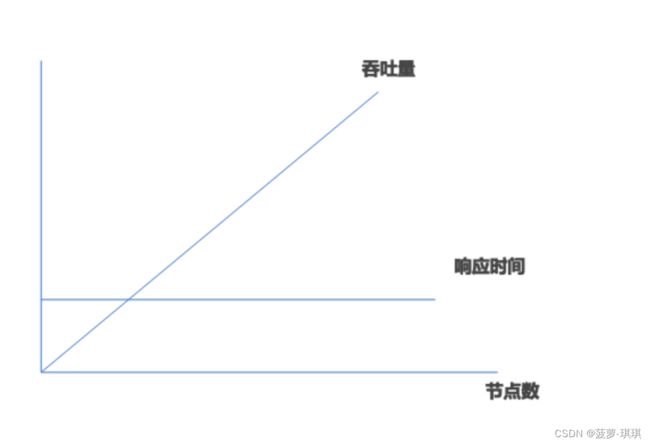
AKF扩展立方体
AKF是eBay前副总裁Martin Abbott在The Art of Scalability一书中提出的经典理论,他把系统在架构上的扩展性按照三个维度进行说明
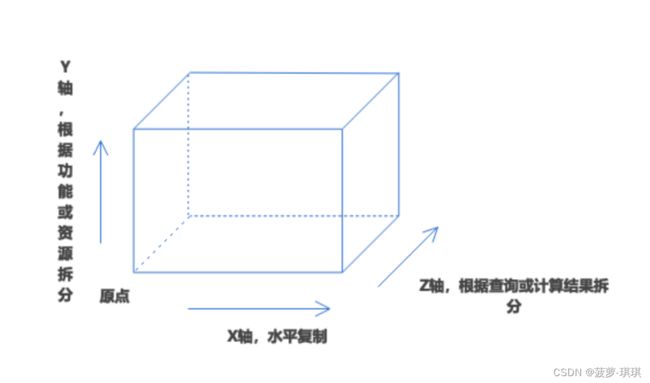
| 描述 | 场景 | 优势 | 挑战 | |
| X轴 | 复制实例,通过负载均衡分摊整体流量压力 | 产品初期 | 架构简单,实施维护简单 | 无状态服务可以快速扩展,但是有状态服务就无法完成 |
| Y轴 | 单体架构到微服务架构转变 | 业务复杂,关联性不强,开发团队庞大,代码规模大 | 故障隔离性好,快速部署,团队沟通成本低 | 部署集成依赖很高,运维成本高 |
| Z轴 | 分布式、分片架构思想 | 存在高并发性能压力,X轴和Y轴无法解决的问题 | 数据可以突破极限 | 架构复杂,数据维护复杂 |
X轴扩展
应用层 ~ 数据层的主从集群架构
Y轴扩展
数据层的分库分表
Z轴扩展
如果采用分库、垂直分表还是不能解决问题,那么就只能通过Z轴扩展的方式进行分片了。什么时候开始考虑分片呢?由于采用分片会导致架构的复杂度大幅上升,因此如果能避免应该尽量避免。
分片的目标:数据量尽可能分布均匀。因为数据量会对数据库造成压力,影响性能指标。在100条数据里搜索一条数据和在一亿条数据里搜索一条数据完全不一样。
- 区间分片法:
将表中具有标示性的字段简单的按区间划分,将不同数据对应到不同区间表中
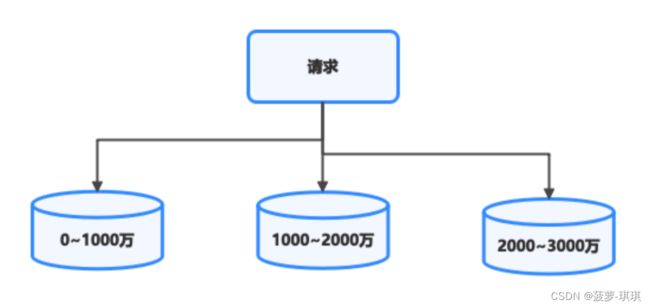
区间法的优点是利于排序,在这几种分区算法中,只有区间法配合分区算法更容易排序。
区间法缺点是容易导致热点问题并且需要维护元数据信息
- 轮流法
根据关键字对分片总量求余以实现均匀分布,此时可以通过对Key计算Hash值缓解热点,公式变为n=Hash(K)mod N。
采用轮流法进行扩容的时候,最好成倍扩容,这样迁移的数据量少。例如,从两个节点扩容为四个节点需要迁移一半的数据。我们举例说明一下,如果现在有两个库,采用轮流法分库,现在由两个库扩展为三个库,发生移动的数据量为三分之二。但是如果是从两个分片变为四个分片,只有一半的数据发生了移动,迁移的数据量更少,并且达成了扩容的效果。
轮流法有点是简单、不需要维护元数据信息。
轮流法缺点是进行数据扩缩容的时候需要迁移的数据量会很大,这也是为什么出现一致性hash的原因。
- 一致性hash法
这里就不详细说这个算法的实现了,可以自行百度
一致性:
假设现在有11支军队攻打一个城堡,他们可以根据当时的情况判断是进攻还是撤退。如果各支军队行动不统一可能会导致失败,那么怎么保证他们一起进攻,或一起撤退呢?很显然,他们可以通过传令兵进行通信,最简单的方式是让所有人投票,通过少数服从多数的方式确定最终的方案。但是这11支部队中可能存在间谍,如果有5位判断进攻,4位判断撤退,假设两位间谍也投撤退票,最终做出错误的决定——全部撤退,但是结果是11支军队的行为是一致的,这完全可以接受。
- 分布式事务
- CAP
- BASE
- NWR模型
- 租约机制
Quorum(NWR模型)
在分布式场景中,扩展性、可靠性可以通过复制数据副本实现。如果多个服务分别向三个节点写数据,为了保证强一致,就必须要求三个节点全部写成功才返回。这样在读的时候可以读任意节点,就不会有不一致的情况了。但是,同步写三个节点的性能较低,如果换一个思路,一致性并不一定要在写数据的时候完成,可以在读的阶段决策,只要每次能读到最新的版本就可以了。这就是Quorum机制的核心思想。
简单来说,Quorum机制就是要满足公式W+R>N,式中N代表备份个数,W代表要写入至少W份才认为成功,R表示至少读取R个备份。这个公式把选择权交给了业务用户,让用户来做出最终决策。

ServerLess
举个例子,开发一个应用,开发者需要关心缓存、MQ、Web容器。而在Serverless环境下,开发者只需要关注代码层面的东西,也就是写完代码直接提交到 Serverless 服务上,并设置相关的策略,Serverless就会帮开发者考虑好一切,包括基础设施、扩展性、性能等。如果你想用 MQ,则只需调用函数,无须关注MQ是否能承受压力,至于什么时候需要扩展,成本如何控制等问题,Serverless会为你做好一切。
优势:
- 成本低。只有运行的时候才启动服务,按调用次数收费,花费更少。
- 开发速度更快。开发人员需要关注的范围更小,开发速度大幅提升。质量属性高。
- 由于云厂商的基础设施及公共基础服务都有SLA要求,Serverless经过大规模验证过,质量属性相对较高。
- 简化运维。相关的运维工作全转移到云厂商一侧
劣势:
- 成功案例太少。目前的情况也只适合简单的应用开发,缺乏大型成功案例的推动。
- 很难满足个性化。跟PaaS平台一样,开发者的个性化需求绝对不想被绑定。
- 缺乏行业标准。在 AWS 上能运行,是否意味着被厂商绑架了,有没有一套标准可以适用所有的云。初次访问性能差。
- 这种有请求才启动服务的方式,在启动服务的这段时间,一定会降低响应时间,影响用户体验。缺乏开发调试工具。
- 在开发验证的过程中,需要不断地把代码上传到服务端运行调试。

应用场景:
- 发送消息。例如邮件、短信、推送消息,这种业务对实时性要求没有那么高,访问量波动很大,采用Serverless能节省很多成本
- 文件处理。例如异步生成图片的缩略图,定时对文件进行合并压缩等
- 例如物联网场景,一些设备可能几分钟上报一次数据,基于事件驱动,然后对数据进行统计分析,非常典型的Serverless场景
ServiceMesh
网格服务,这边也不展开讲了,随着Cloud Native热度上升后,ServiceMesh 也随之发展起来