Pytorch_LSTM与GRU
RNN循环网络在序列问题处理中得到了广泛的应用。但使用标准版本的RNN模型时,常遇到梯度消失gradient vanishing和梯度爆炸gradient explosion问题。
RNN的缺点
RNN的梯度消失和梯度爆炸不同于其它网络,全连接网络和卷积网络每一层有不同参数,而RNN 的每个处理单元Cell(处理单个序列元素的操作称为处理单元Cell)共用同一组权重矩阵W。在上一篇介绍RNN网络算法时可以看到,处理单元之间是全连接关系,序列向前传播的过程中将不断乘以权重矩阵W,从而构成了连乘Wn,当W<1时,如果序列很长,则结果趋近0;当w>1时,经过多次迭代,数值将迅速增长。反向传播也有同样问题。
梯度爆炸问题一般通过“梯度裁剪”方法改善,而梯度消失则使得序列前面的数据无法起到应有的作用,造成“长距离依赖”(Long-Term Dependencies)问题,也就是说RNN只能处理短距离的依赖关系。
这类似于卷积神经网络在处理图像问题时加深网络层数,无法改进效果。尽管理论上可以通过调参改进,但难度很大,最后图像处理通过修改网络结构使用残差网络解决了这一问题。同样,RNN也改进了结构,使用LSTM和GRU网络。作为RNN的变种,它们使用率更高。
LSTM长短时记忆网络
LSTM是Long Short Term Memory Networks的缩写,即长短时记忆网络,该方法在1997年被提出,主要用于解决“长距离依赖”问题。不同于RNN用单一的隐藏层描述规律,LSTM新增加了细胞状态Cell state,简称c,并用多个门控参数分别控制读、写、遗忘操作。
门控gate
门控理论源于生物学,指脊髓中的一些细胞像门一样(门开了才能通过),切断和阻止一些痛觉信号进入大脑。在神经网络中通常是使用激活函数控制数据的传输,如激活函数sigmoid常被用于控制信号是否通过,它的取值范围从0-1,0表示阻断,1表示完全通过,0-1之间数据部分通过,从而实现有选择的输入、有选择的输出、有选择的记忆。
算法
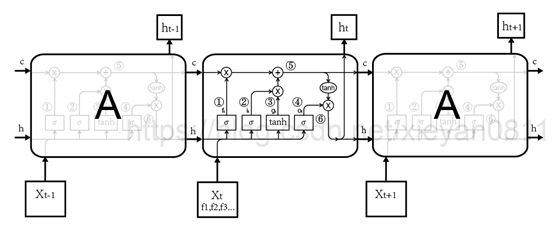
上图描述了LSTM网络对输入Xt(序列中每个元素)处理生成输出ht的前向传播过程。笔者将其分为六步,在图中用圆圈加数字表示。
第一步:计算遗忘门,遗忘门forget gate简称f,用于控制是否遗忘上一层的状态Cell state。该门的输入是前一个隐藏层的状态h(t-1)以及当前的xt,通过一个sigmoid(用σ表示)激活函数,得到当前时间t的遗忘门的值ft ,W和b是该门的参数和偏置。比如:当输入词为“但是”时,认为前面的记忆不再重要,ft值为0,清空之前的记忆(只是举例,不要较真儿)。其公式为:
![]()
第二步:计算输入门,输入门input gate简称i,它用于向Cell state中增加新的内容,该门的输入也是前一个隐藏层的状态h(t-1)以及当前的xt计算it。例如:当输入是“,”时,认为该输入没有携带有贡献的信息,it值为0,忽略该输入。
![]()
第三步:计算输入值,这一步类似于RNN中计算隐藏层参数的算法,输入也是前一个隐藏层的状态h(t-1)以及当前的xt计算gt,它是这一步输入产生的具体影响,此处的激活函数使用tanh。
![]()
第四步:计算输出门,输出门output gate,简称o,在用Cell state值计算输出值ht的过程中用ot控制输出,该门的输入也是前一个隐藏层的状态h(t-1)以及当前的xt。
![]()
第五步:计算当前的细胞状态Cell state,用遗忘门f控制上一步的状态c(t-1),用输入门i控
制当前输入g,从而计算当前状态ct(遗忘了部分以往信息,加入了部分新信息)。
![]()
第六步:通过当前细胞状态c和输出门o计算隐藏层h,最后两步将通过各个门的数据组织起来。
![]()
标准的RNN模型比较粗糙,只调节一组参数,而LSTM把问题细化成几个子问题,需要反复迭代计算多组W参数,运算量比普通的RNN大很多。LSTM的核心原理是保持信息的完整性,它假设每一个状态都是由上一状态叠加一个变化得来的(类似于残差网络),即两组信息做加法,它不同于RNN的逐层做乘法,由此改进了梯度爆炸/梯度消失的问题。它对于较长的序列效果更好。
用法
Pytorch提供的LSTM调用方法与RNN类似,只要把上篇例程中的“RNN”改成“LSTM”即可,不需要其它调整。
与RNN不同的是,在调用前向传递函数forward时,传入和传出的参数都可包含h和c两组值,其格式为:
![]()
其中input是输入,output是输出,第二个参数(h0,c0)为Tuple类型,h0和c0分别是两个隐藏层的初始值;同样LSTM也将计算后隐藏层的值(hn,cn)作为返回值。h和c的维度是(num_layers, batch_size, hidden_size)。
GRU门控循环单元
GRU是门控循环单元Gated Recurrent Unit的缩写,该方法在2014年被提出,是LSTM网络的变体,它比LSTM网络结构更简单,逻辑更加清晰,速度更快,且效果也很好。GRU模型只有两个门:更新门和重置门。它的网络结构与RNN更为相似,在每一步接收序列中的数据输入,上一个隐藏层的输出,并输出隐藏层。
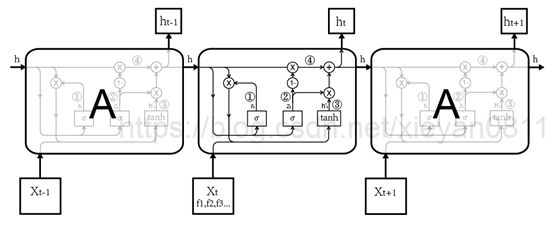
上图描述了对GRU处理输入Xt生成输出ht的前向传播过程。笔者将其分为四步,在图中用圆圈加数字表示。
第一步:计算更新门,更新门update gate简称为z,它的功能类似于LSTM中的遗忘门,用于控制以往信息和新输入数据的在当前状态中的比例,该门的输入也是前一个隐藏层的状态ht-1以及当前的输入xt,省略了偏置参数b。
![]()
第二步:计算重置门,重置门reset gate常简称为r,它的功能类似于LSTM中的输入门,该门的输入也是前一个隐藏层的状态ht-1以及当前的输入xt。
![]()
第三步:计算输入值,输入值由前一个隐藏层的状态ht-1,当前的xt以及重置门rt计算得来。可视为当前输入对状态的影响。
![]()
第四步:计算当前状态,当前状态由两部分组成,前一部分是以往信息的影响,后一部分是当前输入的影响,参数zt是更新门的值,它经过激活函数sigmoid,取值在0-1之间,也就是说,前后两部分的权重之和为1,通过更新门均衡二者的占比。
![]()
与LSTM相比,状态层State cell被省略,由隐藏层h实现它的功能,并省略了输出门o,去掉了各层的偏置参数b,在多个步骤进行了简化,占用资源更少。
Pytorch的具体调用方法和RNN类似,此处不再赘述。
优化RNN网络
深度学习工具一般都提供API直接调用RNN模型,像Keras工具只使用一条语句即建立一个LSTM模型,在建模过程中除了调用API程序员需要做哪些工作呢?
循环神经的网络每一个处理单元都通过一个或者多个全连接网络与下一个单元相连,类似于CNN的多层网络,因此序列越长,计算越复杂,设计网络时需要考虑模型复杂度,估计训练时间,涉及:迭代次数、序列长度,如何切分序列,隐藏层数,隐藏层元素个数,学习率,是否将隐藏层状态传入下一次迭代,超参数、以及参数初值等因素。
比如:RNN的误差往往不是平滑收敛的,尤其是序列较长时,学习率很难固定下来,建议使用Adam优化器自动调节学习参数。