【大数据】Flink 详解(三):核心篇 Ⅱ
本系列包含:
- 【大数据】Flink 详解(一):基础篇
- 【大数据】Flink 详解(二):核心篇 Ⅰ
- 【大数据】Flink 详解(三):核心篇 Ⅱ
- 【大数据】Flink 详解(四):核心篇 Ⅲ
- 【大数据】Flink 详解(五):核心篇 Ⅳ
- 【大数据】Flink 详解(六):源码篇 Ⅰ
Flink 详解(三):核心篇 Ⅱ
- 22、刚才提到 State,那你简单说一下什么是 State?
- 23、Flink 状态包括哪些?
- 24、Flink 广播状态了解吗?
- 25、Flink 状态接口包括哪些?
- 26、Flink 状态如何存储?
- 27、Flink 状态如何持久化?
- 28、Flink 状态过期后如何清理?
22、刚才提到 State,那你简单说一下什么是 State?
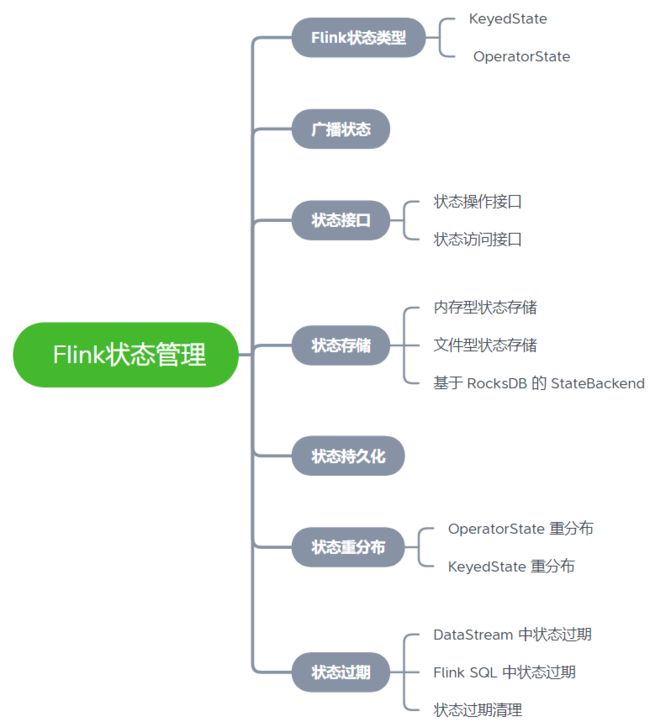
在 Flink 中,状态 被称作 state,是用来保存中间的计算结果或者缓存数据。根据状态是否需要保存中间结果,分为 无状态计算 和 有状态计算。
- 对于流计算而言,事件持续产生,如果每次计算相互独立,不依赖上下游的事件,则相同输入,可以得到相同输出,是无状态计算。
- 如果计算需要依赖于之前或者后续事件,则被称为有状态计算。
有状态计算如 sum 求和,数据累加等。

23、Flink 状态包括哪些?
(1) 按照由 用户管理 还是 Flink 管理,状态可以分为 原始状态 和 托管状态。
- 原始状态(
Raw State):由用户自行进行管理。 - 托管状态(
Managed State):由 Flink 自行进行管理的 State。
两者区别:
- 从 状态管理方式 来说,Managed State 由 Flink Runtime 管理,自动存储,自动恢复,在内存管理上有优化;而 Raw State 需要用户自己管理,需要自己序列化,Flink 不知道 State 中存入的数据是什么结构,只有用户自己知道,需要最终序列化为可存储的数据结构。
- 从 状态数据结构 来说,Managed State 支持已知的数据结构,如
Value、List、Map等。而 Raw State 只支持字节数组,所有状态都要转换为二进制字节数组才可以。 - 从 推荐使用场景 来说,Managed State 大多数情况下均可使用,而 Raw State 是当 Managed State 不够用时,比如需要自定义 Operator 时,才会使用 Raw State。在实际生产过程中,只推荐使用 Managed State。
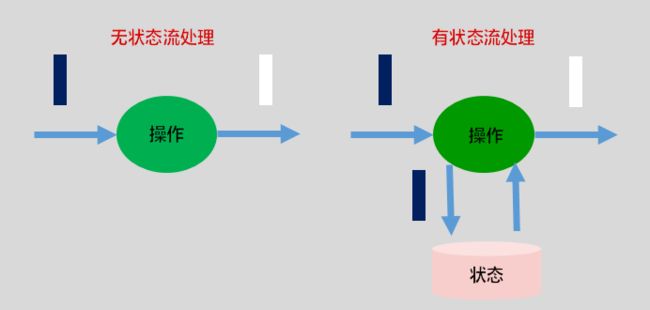
(2)State 按照 是否有 key 划分为 KeyedState 和 OperatorState 两种。
KeyedState 特点
- 只能用在 KeyedStream 上的算子中,状态跟特定的 key 绑定。
- KeyedStream 流上的每一个 key 对应一个 state 对象。若一个 operator 实例处理多个 key,访问相应的多个 state,可对应多个 state。
- KeyedState 保存在 StateBackend 中。
- 通过 RuntimeContext 访问,实现
Rich Function接口。 - 支持多种数据结构:ValueState、
ListState、ReducingState、AggregatingState、MapState。
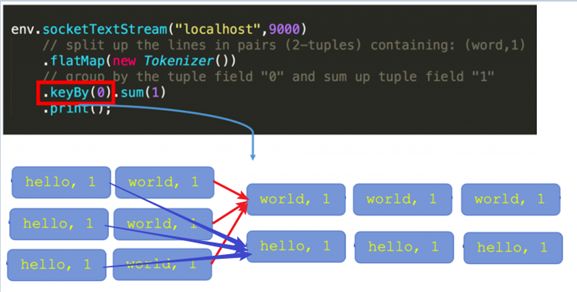
OperatorState 特点
- 可以用于所有算子,但整个算子只对应一个 state。
- 并发改变时有多种重新分配的方式可选:(1)均匀分配(2)合并后每个得到全量。
- 实现
CheckpointedFunction或者ListCheckpointed接口。 - 目前只支持
ListState数据结构。
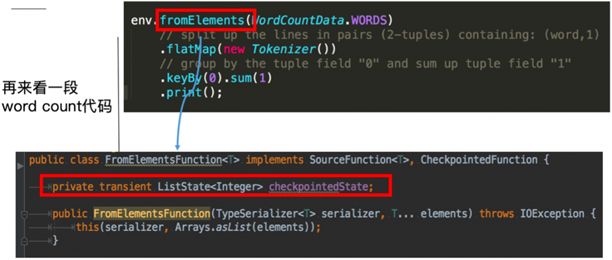
这里的 fromElements 会调用 FromElementsFunction 的类,其中就使用了类型为 ListState 的 operator state。
24、Flink 广播状态了解吗?
Flink 中,广播状态叫作 BroadcastState。 在广播状态模式中使用。所谓广播状态模式, 就是来自一个流的数据需要被广播到所有下游任务,在算子本地存储,在处理另一个流的时候依赖于广播的数据。下面以一个示例来说明广播状态模式。
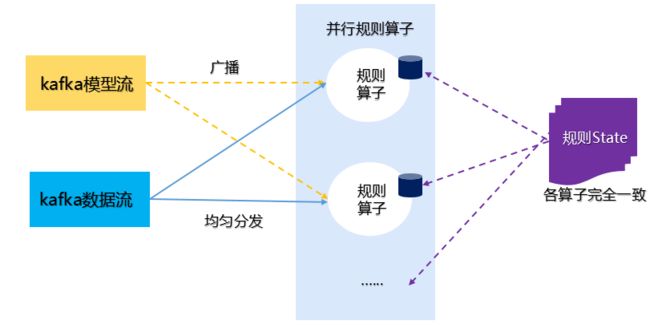
上图这个示例包含两个流,一个为 Kafka 模型流,该模型是通过机器学习或者深度学习训练得到的模型,将该模型通过广播,发送给下游所有规则算子,规则算子将规则缓存到 Flink 的本地内存中,另一个为 Kafka 数据流,用来接收测试集,该测试集依赖于模型流中的模型,通过模型完成测试集的推理任务。
广播状态必须是 MapState 类型,广播状态模式需要使用 广播函数 进行处理,广播函数提供了处理广播数据流和普通数据流的接口。
25、Flink 状态接口包括哪些?
在 Flink 中使用状态,包含两种状态接口:
- 状态操作接口:使用状态对象本身存储、写入、更新数据。
- 状态访问接口:从
StateBackend获取状态对象本身。
1、状态操作接口
Flink 中的状态操作接口面向两类用户,即 应用开发者 和 Flink 框架本身。 所以 Flink 设计了两套接口。
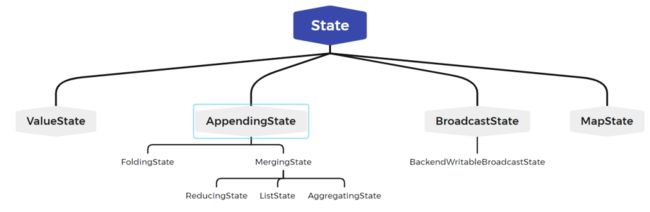
(1)面向开发者 State 接口
面向开发的 State 接口只提供了对 State 中数据的增删改基本操作接口,用户无法访问状态的其他运行时所需要的信息。接口体系如下图:
(2)面向内部 State 接口
内部 State 接口是给 Flink 框架使用,提供更多的 State 方法,可以根据需要灵活扩展。除了对 State 中数据的访问之外,还提供内部运行时信息,如 State 中数据的序列化器,命名空间(namespace)、命名空间的序列化器、命名空间合并的接口。内部 State 接口命名方式为 InternalxxxState。
2、状态访问接口
有了状态之后,开发者自定义 UDF(UserDefineFunction,用户自定义函数)时,应该如何访问状态?
状态会被保存在 StateBackend 中,但 StateBackend 又包含不同的类型。所以 Flink 中抽象了两个状态访问接口:OperatorStateStore 和 KeyedStateStore,用户在编写 UDF 时,就无须考虑到底是使用哪种 StateBackend 类型接口。
(1)OperatorStateStore 接口原理

OperatorState 数据以 Map 形式保存在内存中,并没有使用 RocksDBStateBackend 和 HeapKeyedStateBackend。
(2)KeyedStateStore 接口原理
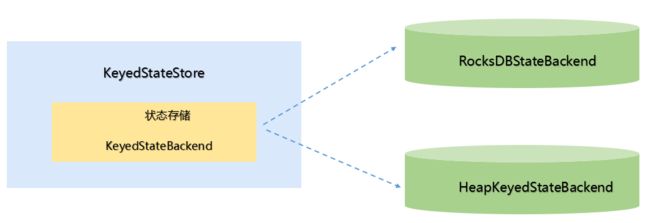
KeyedStateStore 数据使用 RocksDBStateBackend 或者 HeapKeyedStateBackend 来存储,KeyedStateStore 中创建、获取状态都交给了具体的 StateBackend 来处理,KeyedStateStore 本身更像是一个代理。
26、Flink 状态如何存储?
在 Flink 中,状态存储 被叫做 StateBackend,它具备两种能力:
- 在计算过程中提供访问 State 能力,开发者在编写业务逻辑中能够使用 StateBackend 的接口读写数据。
- 能够将 State 持久化到外部存储,提供容错能力。
Flink 状态提供三种存储方式:
- 内存型:
MemoryStateBackend,适用于验证、测试、不推荐生产使用。 - 文件型:
FSStateBackend,适用于长周期大规模的数据。 - RocksDB:
RocksDBStateBackend,适用于长周期大规模的数据。
上面提到的 StateBackend 是 面向用户 的,在 Flink 内部 3 种 State 的关系如下图:
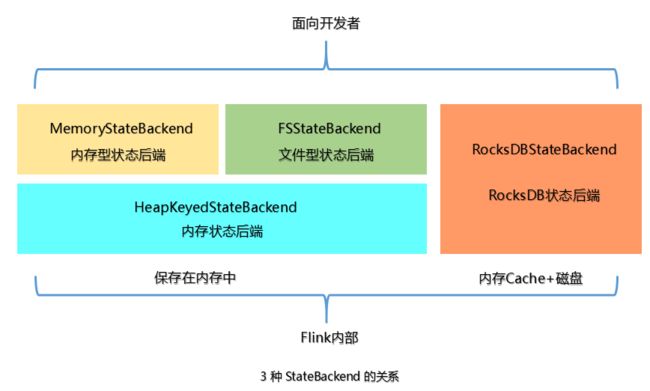
在运行时,MemoryStateBackend 和 FSStateBackend 本地的 State 都保存在 TaskManager 的内存中,所以其底层都依赖于 HeapKeyedStateBackend。HeapKeyedStateBackend 面向 Flink 引擎内部,使用者无须感知。
1、内存型 StateBackend
MemoryStateBackend,运行时所需的 State 数据全部保存在 TaskManager JVM 堆上内存中,KV 类型的 State、窗口算子的 State 使用 HashTable 来保存数据、触发器等。执行检查点的时候,会把 State 的快照数据保存到 JobManager 进程的内存中。
MemoryStateBackend 可以使用异步的方式进行快照(也可以同步,推荐异步),避免阻塞算子处理数据。
基于内存的 StateBackend 在生产环境下不建议使用,可以在本地开发调试测试 。注意点如下 :
- State 存储在 JobManager 的内存中,受限于 JobManager 的内存大小。
- 每个 State 默认 5 M B 5MB 5MB,可通过
MemoryStateBackend构造函数调整。 - 每个 Stale 不能超过 Akka Frame 大小。
2、文件型 StateBackend
FSStateBackend,运行时所需的 State 数据全部保存在 TaskManager 的内存中, 执行检查点的时候,会把 State 的快照数据保存到配置的文件系统中。
可以是分布式或者本地文件系统,路径如:
- HDFS路径:“hdfs://namenode:40010/flink/checkpoints”
- 本地路径:“file:///data/flink/checkpoints”
FSStateBackend 适用于处理大状态、长窗口、或者大键值状态的有状态处理任务。注意点如下 :
- State 数据首先被存在 TaskManager 的内存中。
- State 大小不能超过 TM 内存。
- TM 异步将 State 数据写入外部存储。
MemoryStateBackend 和 FSStateBackend 都依赖于 HeapKeyedStateBackend,HeapKeyedStateBackend 使用 State 存储数据。
3、RocksDBStateBackend
RocksDBStateBackend 跟内存型和文件型都不同 。
RocksDBStateBackend 使用嵌入式的本地数据库 RocksDB 将流计算数据状态存储在本地磁盘中,不会受限于 TaskManager 的内存大小,在执行检查点的时候,再将整个 RocksDB 中保存的 State 数据全量或者增量持久化到配置的文件系统中,在 JobManager 内存中会存储少量的检查点元数据。RocksDB 克服了 State 受内存限制的问题,同时又能够持久化到远端文件系统中,比较适合在生产中使用。
缺点:RocksDBStateBackend 相比基于内存的 StateBackend,访问 State 的成本高很多,可能导致数据流的吞吐量剧烈下降,甚至可能降低为原来的 1 / 10 1/10 1/10。
适用场景
- 最适合用于处理大状态、长窗口,或大键值状态的有状态处理任务。
RocksDBStateBackend非常适合用于高可用方案。RocksDBStateBackend是目前唯一支持增量检查点的后端。增量检查点非常适用于超大状态的场景。
注意点
- 总 State 大小仅限于磁盘大小,不受内存限制。
RocksDBStateBackend也需要配置外部文件系统,集中保存 State。- RocksDB 的 JNI API 基于 byte 数组,单 Key 和单 Value 的大小不能超过 8 8 8 字节。
- 对于使用具有合并操作状态的应用程序,如 ListState ,随着时间可能会累积到超过 2 31 2^{31} 231 字节大小,这将会导致在接下来的查询中失败。
27、Flink 状态如何持久化?
首先,Flink 的状态最终都要持久化到第三方存储中,确保集群故障或者作业挂掉后能够恢复。RocksDBStateBackend 持久化策略有两种:
- 全量持久化策略,RocksFullSnapshotStrategy
- 增量持久化策略,RocksIncementalSnapshotStrategy
1、全量持久化策略
每次将全量的 State 写入到状态存储中(HDFS)。内存型、文件型、RocksDB 类型的 StataBackend 都支持全量持久化策略。
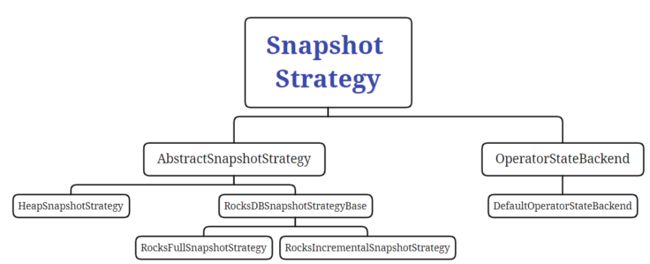
在执行持久化策略的时候,使用异步机制,每个算子启动 1 1 1 个独立的线程,将自身的状态写入分布式存储可靠存储中。在做持久化的过程中,状态可能会被持续修改,基于内存的状态后端使用 CopyOnWriteStateTable 来保证线程安全,RocksDBStateBackend 则使用 RocksDB 的快照机制,使用快照来保证线程安全。
2、增量持久化策略
增量持久化就是每次持久化增量的 State,只有 RocksDBStateBackend 支持增量持久化。
Flink 增量式的检查点以 RocksDB 为基础, RocksDB 是一个基于 LSM-Tree 的 KV 存储。新的数据保存在内存中, 称为 memtable。如果 Key 相同,后到的数据将覆盖之前的数据,一旦 memtable 写满了,RocksDB 就会将数据压缩并写入磁盘。memtable 的数据持久化到磁盘后,就变成了不可变的 sstable。
因为 sstable 是不可变的,Flink 对比前一个检查点创建和删除的 RocksDB sstable 文件就可以计算出状态有哪些发生改变。
为了确保 sstable 是不可变的,Flink 会在 RocksDB 触发刷新操作,强制将 memtable 刷新到磁盘上。在 Flink 执行检查点时,会将新的 sstable 持久化到 HDFS 中,同时保留引用。这个过程中 Flink 并不会持久化本地所有的 sstable,因为本地的一部分历史 sstable 在之前的检查点中已经持久化到存储中了,只需增加对 sstable 文件的引用次数就可以。
RocksDB 会在后台合并 sstable 并删除其中重复的数据。然后在 RocksDB 删除原来的 sstable,替换成新合成的 sstable。新的 sstable 包含了被删除的 sstable 中的信息,通过合并历史的 sstable 会合并成一个新的 sstable,并删除这些历史 sstable。可以减少检查点的历史文件,避免大量小文件的产生。
28、Flink 状态过期后如何清理?
1、DataStream 中状态过期
可以对 DataStream 中的每一个状态设置清理策略 StateTtlConfig,可以设置的内容如下:
- 过期时间:超过多长时间未访问,视为 State 过期,类似于缓存。
- 过期时间更新策略:创建和写时更新、读取和写时更新。
- State 可见性:未清理可用,超时则不可用。
2、Flink SQL 中状态过期
Flink SQL 一般在流 Join、聚合类场景使用 State,如果 State 不定时清理,则导致 State 过多,内存溢出。清理策略配置如下:
StreamQueryConfig qConfig = ...
//设置过期时间为 min = 12小时 ,max = 24小时
qConfig.withIdleStateRetentionTime(Time.hours(12),Time.hours(24));