重新梳理DeepFaceLab(DeepFake)最近动态:简要且全面的信息
DeepFaceLab相关文章
一:《简单介绍DeepFaceLab(DeepFake)的使用以及容易被忽略的事项》
二:《继续聊聊DeepFaceLab(DeepFake)不断演进的2.0版本》
三:《如何翻译DeepFaceLab(DeepFake)的交互式合成器》
四:《想要提高DeepFaceLab(DeepFake)质量的注意事项和技巧(一)》
五:《想要提高DeepFaceLab(DeepFake)质量的注意事项和技巧(二)》
六:《友情提示DeepFaceLab(DeepFake)目前与RTX3080和3090的兼容问题》
七:《高效使用DeepFaceLab(DeepFake)提高速度和质量的一些方法》
八:《支持DX12的DeepFaceLab(DeepFake)新版本除了CUDA也可以用A卡啦》
九:《简单尝试DeepFaceLab(DeepFake)的新AMP模型》
十:《非常规的DeepFaceLab(DeepFake)小花招和注意事项》
土:《可以提高DeepFaceLab(DeepFake)合成最终视频速度的方法》
王:《偶然看到DeepFaceLab(DeepFake)在2023年的新动向》—《测试通用遮罩》
文章目录
- (零)基本概念
- (一)版本选择
-
- (1.1)原版DeepFaceLab
- (1.2)ICE版DeepFaceLab
- (二)数据准备
-
- (2.1)源脸数据集(data_src)
-
- (2.1.1)基本
- (2.1.2)进阶1:增强脸部
- (2.1.3)进阶2:角度分布
- (2.1.4)进阶3:XSeg遮罩
- (2.1.5)进阶4:识别点/遮罩确认
- (2.2)目标脸(data_dst)
-
- (2.2.1)基本
- (2.2.2)进阶1:视频帧降噪
- (2.2.3)进阶2:XSeg遮罩
- (2.2.4)进阶3:识别点/遮罩确认
- (三)训练模型
-
- (3.1)新模型vs复用模型
- (3.2)模型属性
-
- (3.2.1)模型类型
- (3.2.2)模型架构
- (3.2.3)模型参数
- (3.3)训练参数
- (3.4)ICE版本新训练参数
- (3.5)训练过程
-
- (3.5.1)命令行窗口
- (3.5.2)预览窗口
- (3.6)阶段阶段
-
- (3.6.1)预训练(可选)
- (3.6.2)泛化/翘曲训练
- (3.6.3)归一化/常规训练
- (3.6.4)增强/GAN 训练(可选)
- (3.7)训练成果
- (四)合成
-
- (4.1)合成参数
- (4.2)覆盖模式+遮罩对比
- (五)合成的图片转视频
- (六)总结
(零)基本概念
DeepFaceLab 简称 DFL,可以将某人的面孔作为来源(source,src),替换目标(destination,dst)视频上另一个人的面孔。
由于发展的时间有点长,之前记录的许多方面有变化,决定重新拉通整理下。
(一)版本选择
(1.1)原版DeepFaceLab
伊佩罗夫的原版DFL(GIthub仓库)发布包最后停留在2021年11月20日。
具体Windows的发布包可通过磁力链接下载。
或者:magnet:?xt=urn:btih:e7ffdcb4ada863de9504f2a741f924dcd56ab84a。
- NVIDIA RTX 2000系列和更旧的显卡:
DeepFaceLab_NVIDIA_up_to_RTX2080Ti_build_11_20_2021.exe - NVIDIA RTX 3000系列和更新的显卡:
DeepFaceLab_NVIDIA_RTX3000_series_build_11_20_2021.exe - 其它显卡:
DeepFaceLab_DirectX12_build_11_20_2021.exe
如果阅读英文困难,也有许多不错的汉化版本,甚至有整合版,界面版,可以自己搜。
(1.2)ICE版DeepFaceLab
下载,变化,简要情况参考这里,具体信息请参考作者的原发布贴。
简单说就是训练得更好更快,并且支持512的遮罩。
仍在开发中,发布的版本有:DF_ICE_1.31c,DF_ICE_1.601。
(二)数据准备
(2.1)源脸数据集(data_src)
由于来源与目标有时容易混淆,所以暂定前提:让你代替志玲姐出现在影视作品中。
那么你的脸,就是来源 = source = src 。
下面基本的步骤是必须要的,进阶部分能做就做。
(2.1.1)基本
最终是形成你的《多角度,多光影,妆容尽量一致,面部少遮挡 的源脸数据集 (aligned faceset)》。
分辨率一般是[512x512],小了细节可能不够,大了模型分辨率跟不上。
根据需要,源脸数据集可以多次补充合并。
最终的数量如果分布均匀大概2000-4000就够了,当然6000-8000也可以。
少了不像,多了相对训练速度会降低。
-
(A)简单的办法可以准备你的一段影片
data_src.mp4,放入工作目录\DFL_Path\workspace中。
接着提取每一帧图片:2) extract images from video data_src.bat。
(A)更好的方法是提前准备各种照片,不限于普通照片,截取自单段视频的图片,效果不错的Stable-Diffusion生成的照片,你的双胞胎姐弟,长得像你的明星???,总之素材多更好。
提取的每一帧图片,或者你准备的图片都放在\DFL_Path\workspace\data_src\目录中。 -
(B)然后从图片中提取脸部数据集:
4) data_src faceset extract.bat。
(B)或者使用 快速切脸工具,参考这里。不仅快很多,宁可识别不出也不识别出错,适合源脸。
提取的数据集,会放在\DFL_Path\workspace\data_src\aligned\目录中。 -
(C)检查和去掉错误的,以及不是源脸的图片(比如照片中其它人/路人也被识别提取了)。删掉这些错误脸,只留你自己的脸。

-
(D)几千张数据集图片,打包了更方便拷贝和处理:
4.2) data_src util faceset pack.bat。
打包后大堆脸部图片会变成单个\DFL_Path\workspace\data_src\aligned\faceset.pak文件。
(2.1.2)进阶1:增强脸部
脸部数据集来源比较多的话,可能某些模糊某些清楚,某些平滑某些噪点多。
最好是有选择的增强图片,比如图片清晰但噪点多的仅去噪。
图片不太清晰的可以锐化和恢复脸部。如何优化/优化程度都需要自己权衡。
⚠️不要用AI来"脑补"太多的内容,比如:SD-WEBUI,remini,修复后的图片如果五官移位需要重新识别脸部。
⚠️也不要修复得人都不像了,或者脸上油光满面——效果请用自己的眼睛(脑袋)来判断。
-
简单办法用DFL自己的增强命令:
4.2) data_src util faceset enhance.bat,效果不算好。 -
更好的办法是用别的软件优化脸部数据集图片。
1)先保存已识别的面部特征点信息:4.2) data_src util faceset metadata save.bat。
2)用比如 Topaz Photo AI 等软件优化脸部数据集图片。
3)再恢复已识别的面部特征点信息:4.2) data_src util faceset metadata restore.bat。

(2.1.3)进阶2:角度分布
通常来说我们正面的照片较多,太仰视俯视,左右侧面比较少。
所以我们需要人为的找到这些角度的照片,并识别为源脸数据集。
- 以前我们只能通过:
4.2) data_src sort.bat功能,按仰俯排序,左右排序,大概估计角度情况。 - 现在有了 Aligned合并工具,可以按角度二维排序便于添加删除角度。参考这里。很容易看出缺少的角度。
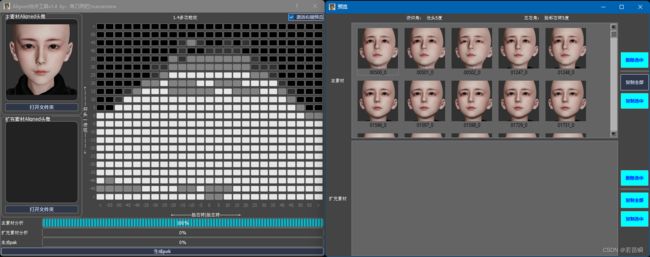
(2.1.4)进阶3:XSeg遮罩
如果你的源脸数据集,每张脸都无遮挡(包括额头),那么可以不用XSeg遮罩(跳过本小节内容)。
有脸就有遮罩。就算没有/不用XSeg遮罩,也有脸部识别的遮罩(范围)。
但是如果源脸数据集中的图片,有比如麦克风,帽子,眼镜,发型,遮挡了部分脸部,就一定要应用遮罩了。
针对性的画遮罩并训练,效果最好,这部分可以搜其他教程一类。
但是懒人可以不自己画遮罩和训练啊,仅用别人成熟的遮罩,效果也不错,参考:这里。
使用:5.XSeg) data_src trained mask - apply.bat 将遮罩写入你的源脸数据集。
例子截图请看下面,目标脸部分章节。
XSeg遮罩在合成时还有个用法,请参考合成部分章节。
(2.1.5)进阶4:识别点/遮罩确认
检查脸部数据集图片,有时会看到某些脸明显不正确,或者脸是其它人,前面说过删掉它们就好了。
但是有些脸图片看上去正确,其实五官识别差得很远(特征点在脸上的位置不对)。
这种情况更容易出现在极限角度的脸上。
对于源脸,识别点错误必须更正(实在更正不了就删掉)。
如果遮罩有错误,可以把有问题的脸留下,单独去除遮罩:5.XSeg) data_src trained mask - remove.bat 。
可以使用 快速切脸工具导出遮罩和特征点,参考这里。
或者用 MVE工具 检查脸特征点和遮罩情况,编辑不正确的特征点,参考这里。新版这里。
例子截图请看下面,目标脸部分章节。
至此,源脸数据集就准备好了。
(2.2)目标脸(data_dst)
由于来源与目标有时容易混淆,所以暂定前提:让你代替志玲姐出现在影视作品中。
那么志玲姐的脸,就是目标 = destination = dst
下面基本的步骤是必须要的,进阶部分能做就做。
(2.2.1)基本
和源只需要脸部数据集不一样,目标需要保留视频+每一帧图片+脸部数据集,才能最后合成:
-
准备志玲姐的一段影片
data_dst.mp4,放入工作目录\DFL_Path\workspace中。
然后生成每一帧图片:3) extract images from video data_dst FULL FPS.bat。
提取的每一帧图片都放在\DFL_Path\workspace\data_dst\目录中。 -
提取每帧图像,建议:
5) data_dst faceset extract + manual fix.bat。
先自动提取,最后手动提取自动找不到的脸。
提取的数据集,会放在\DFL_Path\workspace\data_dst\aligned\目录中。 -
得到了图像生成的目标脸数据集 (aligned faceset)后。
同理检查,删掉错误的脸,删掉不想换(不是志玲姐)的脸。
检查完成后也可以打包。
(2.2.2)进阶1:视频帧降噪
将视频转为每一帧的图片后,提取目标脸部之前,最好根据实际情况降噪。
执行:3.optional) denoise data_dst images.bat,根据目标视频的情况,选择降噪强度(默认7)。
呃,图是用别人的,就当她是志玲姐吧。

(2.2.3)进阶2:XSeg遮罩
如果你的目标脸数据集,每张脸都无遮挡(包括额头),那么可以不用XSeg遮罩(跳过本小节内容)。
和源脸同理,如果目标脸数据集也有被遮挡的部分,最好也应用遮罩。
使用:5.XSeg) data_dst trained mask - apply.bat 将遮罩写入你的目标脸数据集。
面部识别范围有话筒遮挡:

遮罩完美排除多余的部分:

(2.2.4)进阶3:识别点/遮罩确认
和源脸同理,可以进行同样的检查。
问题是目标帧也许很多很多,逐一检查几万张太痛苦了,
而且稍微有错误的影响没有源那么大(视频剪辑cut掉嘛)。所以……
PS:下图不是dst,只是用志玲姐举例:
看上去识别点和遮罩都挺正常的。MVE参考这里。
新版MVE(0.8.2),彩色识别点(Landmark):参考这里。
至此,目标脸视频+视频帧图片+脸数据集就准备好了。
(三)训练模型
训练啥,训练的对象当然是模型(model),输入数据是源和目标。
参考资料:这个网站,以及这个帖子,还有这个帖子。
根据模型类型不同,训练命令为:6) train XX模型类型.bat 这样。
(3.1)新模型vs复用模型
也就是说有了 源脸数据集+目标脸数据集,就可以训练模型了。
我们可以选择:
- 从0开始训练自己模型——慢,但所有参数都可以自己设置。
- 或者复用自己之前的模型/别人的模型or预训练模型——节省时间,参考论坛。
如果不想花钱买,也可以用别人免费共享的模型,比如这里。
(3.2)模型属性
模型属性是新建模型时需要确定的参数,后期不能更改。
如果你复用了模型,则可以直接跳过整个模型部分的参数设置。
(3.2.1)模型类型
之前的各种老模型都被移除了,
原版到目前为止保留三种类型:
-
Quick96:Predefined model; useful for testing. DF-UD, Full Face, Resolution: 96, Batch size: 4
简单尝试快速出结果,因为有训练数据,但分辨率太低,量变引起质变,最终效果不怎么好。 -
SAEHD:Sparse Auto Encoder HD. The standard model and trainer for most deepfakes.
正常都用这个,”别人的模型“大多也是这个类型。 -
AMP:Amplifier. Destination facial expressions are amplified to the source.
用于实时的DFLive效果比较好。 -
Mulan:DF-ICE版本提供的新的独创训练架构-木兰,有多种算法,ICE-V3,V4,V7。
就是速度更快,对高分辨率、新40显卡支持更好,细节学习比对抗网络更强,支持多层遮罩合成(不过我没试过呀)。
具体请看ICE版发布原帖吧。
(3.2.2)模型架构
假设我们选了SAEHD,下一步就需要选择架构。
如果看别人的模型,会经常看到df-ud,df-u,liae-u等等名称,这就是架构和架构的附加参数。
-
DF:Strict face interpretation without morphing. Most accurate and true to source data. Works best when the source and destination have similarly shaped faces and color. Placement of facial features (eyes, mouth, nose, etc.) can differ between source and destination. Works better on frontal shots; possible worse result on profiles. Source faceset must have ample coverage of destination pitch, yaw, and color ranges.
极简描述:更像源脸。 -
LIAE:Lenient face interpretation with some morphing. Adapts more to destination face. Will adapt to faces with dissimilar shape and color. Placement of facial features may be slightly morphed to fit destination face.
Possible better result on extreme angles and missing data. More replication of destination color and lighting conditions.
极简描述:光影更自然。
选择模型架构的同时需要确定架构参数。
模型可以带或不带以下几个选项:
-
U:Increases similarity to source face. Requires more VRAM.
提升生成脸细节一致性。
可能导致训练不稳定或收敛速度慢。可能会破坏图像的全局颜色和对比度的一致性。
架构画面略显普通,缺少灵魂(好严重的指控)。 -
D:Improve performance by effectively doubling the resolution using the same computation cost. Requires longer training and recommended use of a pretrained model. Resolution must be changed by multiples of 32 (other variants: 16).
源于"depth_to_space" 深度换尺寸算法,
提高解码图像分辨率,减少参数量和计算量,提高模型的效率和性能。利用深度维上的信息,增强图像细节和质量。
增加了整体训练时间,可能影响图像的连续性和完整性,图像上下帧不一致,帧闪烁和跳跃。 -
T:Increases similarity to source face.
为啥没有任何信息说明呢。
(3.2.3)模型参数
-
模型分辨率:[128] Resolution ( 64-640 ?:help ) :
More resolution requires more VRAM and time to train. Value will be adjusted to multiple of 16 and 32 for -d archi.
更大的分辨率需要更多的显存,也需要更长时间来训练。分辨率决定上限,但不是绝对的分辨率越高就越清晰。
默认的128确实有点小,但是太大我们的显卡又难以承受,需要根据自己显卡来定分辨率。 -
人脸类型:[f] Face type ( h/mf/f/wf/head ?:help ) :
1)head:脑袋,包括头发到脖子,使用3D的标记点,需要XSeg应用到源和目标脸数据集。
2)wf:whole face,整脸,包括额头到下巴以下。
3)f:Full Face,全脸,从眉毛上方到下巴.。
4)mf:Mid Face(旧类型),中脸,覆盖眉毛到下巴,比hf多30%脸颊区域。
5)h:Half Face(旧类型),半脸,覆盖眼睛到嘴巴,较少的脸颊区域。

-
自动编码器维度:[256] AutoEncoder dimensions ( 32-1024 ?:help ) :
All face information will packed to AE dims. If amount of AE dims are not enough, then for example closed eyes will not be recognized. More dims are better, but require more VRAM. You can fine-tune model size to fit your GPU.
根据你的显卡显存大小设置这些参数,用默认也可以。 -
编码器维度:[64] Encoder dimensions ( 16-256 ?:help ) :
More dims help to recognize more facial features and achieve sharper result, but require more VRAM. You can fine-tune model size to fit your GPU. -
解码器维度:[64] Decoder dimensions ( 16-256 ?:help ) :
More dims help to recognize more facial features and achieve sharper result, but require more VRAM. You can fine-tune model size to fit your GPU. -
解码遮罩维度:[22] Decoder mask dimensions ( 16-256 ?:help ) :
Typical mask dimensions = decoder dimensions / 3. If you manually cut out obstacles from the dst mask, you can increase this parameter to achieve better quality.
(3.3)训练参数
训练参数是每次训练前可以修改的。
界面显示保存啥的就略过吧。
-
随机翻转SRC脸:[n] Random flip SRC ( y/n /?:help ) :
Random horizontal flip SRC faceset. Covers more angles, but the face may look less naturally.
不要开启,特别是脸部不对称,比如一边有痣,或者金城武的鼻子。 -
随机翻转DST脸:[y] Random flip DST ( y/n /?:help ) :
Random horizontal flip DST faceset. Makes generalization of src->dst better, if src random flip is not enabled.
通常都开启。 -
批量大小:[4] Batch size ( /?:help ) :
Larger batch size is better for NN’s generalization, but it can cause Out of Memory error. Tune this value for your videocard manually.
.
批量大小是DeepFaceLab中最重要的选项之一,因为它决定了每次迭代可以处理的图像数量。较大的批大小将导致更好的模型泛化和更快的训练(更少的迭代)。非常低的批量大小 (<=4) 会慢得多,并且模型可能难以概括面部特征、颜色等。非常高的批量大小最终可能会导致性能回报降低,创作者之间对“最佳批量大小”存在争议。建议将批大小至少设置为 4,最好在 8-16 范围内。
.
可以随时更改批大小,并且有各种模型选项使用或多或少的系统资源,迫使您更改批大小。此外,如果选择使用预训练模型,则可能需要更改批大小以在硬件上工作。您可以下载在功能更强大的系统上生成的预训练模型,降低批大小,并使用自己的图像进行训练。 -
眼睛和嘴部优先:[n] Eyes and mouth priority ( y/n ?:help ) :
Helps to fix eye problems during training like “alien eyes” and wrong eyes direction. Also makes the detail of the teeth higher.
先开着,后面可以间歇性的开/关交替训练。
打开的时候loss会显得很高,关闭后loss降低很多,但是不用操心这个,我们看的是效果而不是loss数值。 -
侧脸训练权重均衡:[n] Uniform yaw distribution of samples ( y/n ?:help ) :
Helps to fix blurry side faces due to small amount of them in the faceset.
帮助模糊的侧脸训练,因为通常数据集中侧脸较少。 -
遮罩边沿模糊:[n] Blur out mask ( y/n ?:help ) :
Blurs nearby area outside of applied face mask of training samples. The result is the background near the face is smoothed and less noticeable on swapped face. The exact xseg mask in src and dst faceset is required. -
模型优化器放置于GPU:[y] Place models and optimizer on GPU ( y/n ?:help ) :
When you train on one GPU, by default model and optimizer weights are placed on GPU to accelerate the process. You can place they on CPU to free up extra VRAM, thus set bigger dimensions. -
使用信仰优化器:[y] Use AdaBelief optimizer? ( y/n ?:help ) :
Use AdaBelief optimizer. It requires more VRAM, but the accuracy and the generalization of the model is higher. -
使用瘦化神经网络:[n] Use learning rate dropout ( n/y/cpu ?:help ) :
When the face is trained enough, you can enable this option to get extra sharpness and reduce subpixel shake for less amount of iterations. Enabled it beforedisable random warpand beforeGAN.
这是ICE版本的修改,我记得原本是通过随机的丢弃学习率,来避免卷积算法遇到的马鞍效应(学习率难以下降)。
训练足够之后开启,先开启这个,再关闭随机扭曲素材和打开对抗网络。 -
随机扭曲素材:[y] Enable random warp of samples ( y/n ?:help ) :
Random warp is required to generalize facial expressions of both faces. When the face is trained enough, you can disable it to get extra sharpness and reduce subpixel shake for less amount of iterations.
前期需要开启,配合小的BS(比如4),快速成型。
后期需要关闭,训练足够之后。 -
随机应用色调/饱和度/亮度:[0.0] Random hue/saturation/light intensity ( 0.0 … 0.3 ?:help ) :
Random hue/saturation/light intensity applied to the src face set only at the input of the neural network. Stabilizes color perturbations during face swapping. Reduces the quality of the color transfer by selecting the closest one in the src faceset. Thus the src faceset must be diverse enough. Typical fine value is 0.05
开点对色彩有好处。 -
对抗网络强度:[0.0] GAN power ( 0.0 … 5.0 ?:help ) :
Forces the neural network to learn small details of the face. Enable it only when the face is trained enough with lr_dropout(on) and random_warp(off), and don’t disable. The higher the value, the higher the chances of artifacts. Typical fine value is 0.1
最后开,用来生成纹理细节。 -
真脸强度:[0.0] ‘True face’ power. ( 0.0000 … 1.0 ?:help ) :
Experimental option. Discriminates result face to be more like src face. Higher value - stronger discrimination. Typical value is 0.01 . Comparison - https://i.imgur.com/czScS9q.png
此项参数只有DF架构的模型才能看到。开得越大,越像源脸(即便很不自然了)。慎重!!!

-
人脸风格学习强度:[0.0] Face style power ( 0.0…100.0 ?:help ) :
Learn the color of the predicted face to be the same as dst inside mask. If you want to use this option with ‘whole_face’ you have to use XSeg trained mask. Warning: Enable it only after 10k iters, when predicted face is clear enough to start learn style. Start from 0.001 value and check history changes. Enabling this option increases the chance of model collapse.
不用开。 -
背景风格学习强度:[0.0] Background style power ( 0.0…100.0 ?:help ) :
Learn the area outside mask of the predicted face to be the same as dst. If you want to use this option with ‘whole_face’ you have to use XSeg trained mask. For whole_face you have to use XSeg trained mask. This can make face more like dst. Enabling this option increases the chance of model collapse. Typical value is 2.0
不用开。 -
对SRC应用颜色转换器:[none] Color transfer for src faceset ( none/rct/lct/mkl/idt/sot ?:help ) :
Change color distribution of src samples close to dst samples. Try all modes to find the best.
自己觉得哪个好就哪个。PS:合成时也有对应的选项。 -
使用梯度剪裁:[n] Enable gradient clipping ( y/n ?:help ) :
Gradient clipping reduces chance of model collapse, sacrificing speed of training.
通过设置梯度阈值,防止模型崩溃,特别是开某些参数的时候(gan,true face, style power)。 -
开启预训练:[n] Enable pretraining mode ( y/n ?:help ) :
Pretrain the model with large amount of various faces. After that, model can be used to train the fakes more quickly. Forces random_warp=N, random_flips=Y, gan_power=0.0, lr_dropout=N, styles=0.0, uniform_yaw=Y
呃,预训练不如直接练。。。
(3.4)ICE版本新训练参数
-
[y] 启用 ICE-RG 优化器 ( y/n /?:帮助 ) :
RG优化器,对训练过程中梯度计算进行优化,有限显存提升模型参数容忍度。
RG optimization is turned on by default. Please set [N] when it is turned off. -
[n] 启用 loss 优化器 ( y/n /?:帮助 ) :
启用优化器,将挑选极限角度进行集中训练,并改善扭曲素材间稳定性,提取脸部特征机率更高,
Optimize the loss value of Src and DST materials to make the overall decline curve of loss smoother,Material with high sniping loss sample -
[3] loss优化器强度 ( 2-8 /?:帮助 ) :
loss优化器强度取值越大,平滑效果越好,占用资源也更高,
Focus on the aiming times of batches,default is 2,How many times are high loss materials trained in a cycle. -
[5e-05] 自定义学习率【Learning rate】 ( 0.0 … 0.1 /?:帮助 ) :
Learning rate: typical fine value 5e-5
用默认的吧,不敢改。 -
[n] 皮肤纹理优先(只支持ICE模型) ( y/n /?:帮助 ) : ?
这个选项对SRC的皮肤纹理优先学习,并在合成中提升皮肤质感!
(3.5)训练过程
(3.5.1)命令行窗口
这部分和之前没有什么变化。
用ICE版本为例,选了GPU/模型后,简单的显示/设置了参数,就开始训练了。
由于没有开启LOSS平滑,所以命令行显示的内容和原版一致,默认25分钟保存一次模型。
[当前时间][i:迭代次数][单次迭代时长ms]-[src loss][dst loss]
注意:3秒内按下回车按键,将重新设置模型训练参数! 训练器:RG 优化开启,AMP关闭
装载类型:me-model: 100%|██████████████████████████| 5/5 [00:01<00:00, 3.86it/s]
从 X:\DFL_Path\workspace\data_src\aligned 装载 2400 个训练样本
角度排序: 100%|█████████████████████████████| 128/128 [00:00<00:00, 8530.97it/s]
从 X:\DFL_Path\workspace\data_dst\aligned 装载 24000 个训练样本
角度排序: 100%|██████████████████████████████| 128/128 [00:00<00:00, 682.50it/s]
____________________ 模型摘要 _____________________
模型名称:: LG256_SAEHD
当前迭代: 1234567
____________________ 模型参数 _____________________
模型架构: liae-ud
人脸类型: f
模型分辨率: 256
自动编码器维度 ae_dims: 256
编码器维度 e_dims: 64
解码器维度 d_dims: 64
解码器掩码维度 d_mask_dims: 22
BS大小: 20
学习率lr: 5e-05
瘦化神经网络 lr_dropout: 开启
遮罩约束训练范围: 开启
均衡侧脸训练权重: 开启
眼睛和嘴部优先: 开启
素材增强-翻转dst: 开启
素材增强-随机色调、饱和度、亮度: 0.05
RG优化器: 开启
模型优化器放置于GPU: 开启
梯度剪裁: 开启
版本: V3
_____________________________________________________
设备序号: 0
设备名称: NVIDIA GeForce RTX 3060
显存大小: 9.37GB
_____________________________________________________
ICE 1.31 version by kingboy! QQ group:366893641
开始训练,输入 "回车" 将保存模型,结束模型训练。
[21:11:43][i:1234589][1128ms]-[0.7113][0.9651]
……
(3.5.2)预览窗口
用ICE1.31c版本为例,和原版差异不大。
当然,ICE版增强了一些功能,可以看上面的提示。
上方显示loss变化情况,整体是下降的,中间有变化是因为改变了参数再进行训练。
和命令行的loss变化情况是相对应的。
下面5列分别显示:源脸图,学习到的源,目标脸图,学习到的目标,合成图。
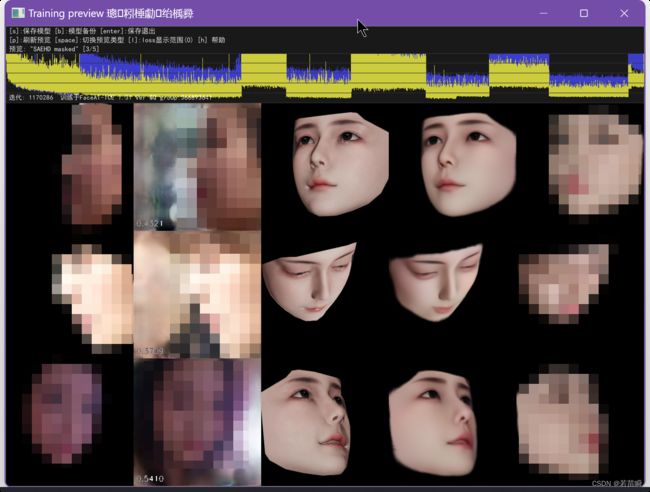
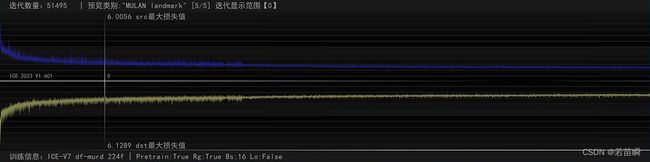
PS:新的ICE版本显示loss方式改进了。
src和dst的loss分别显示,更加清晰了(但抗锯齿又不太清晰)。
(3.6)阶段阶段
不同的训练阶段,通过开关某些参数可以加快训练,得到更好的成果。参考这个帖子。
PS:此图来自zhatv.cn论坛,版权归原作者所有。
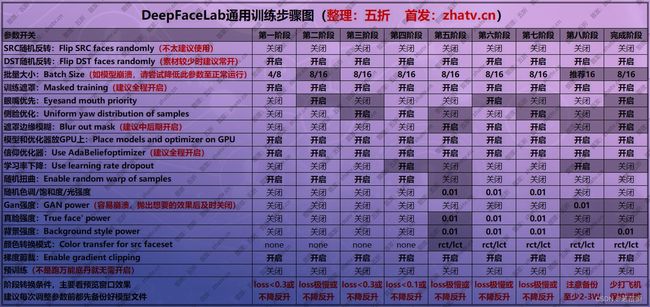
确实是个有用的参考。
我倒是觉得不需要那么复杂,主要看阶段和素材,以及实际训练情况。
按阶段来,并不是每步都需要,参考英文手册如下:
(3.6.1)预训练(可选)
- 第 1 步 - 预训练或导入预训练模型
(3.6.2)泛化/翘曲训练
- 第 2 步 - Random Warp
启用 样本Random Warp
启用 Masked training(仅WF/Head)
禁用 “真实面强”(仅DF模型)
禁用 GAN
禁用 预训练模式。
(可选)随机翻转 SRC、随机翻转 DST、色彩转换模式、随机 HSL
(可选)在扭曲阶段添加或删除面集图像并更改遮罩
(可选)根据需要启用梯度剪切 - 第 3 步 - 眼睛和嘴巴优先(可选)
启用 眼睛和嘴巴优先 - 第 4 步 - Uniform Yaw(可选)
禁用 眼睛和嘴巴优先
启用 Uniform yaw distribution of samples - 第 5 步 - Learning Rate Dropout(可选)
启用 Learning Rate Dropout
禁用 Uniform yaw distribution of samples (可选)
(3.6.3)归一化/常规训练
- 第 6 步- 常规训练
禁用 Random Warp
禁用 Uniform Yaw
禁用 眼睛和嘴巴优先
禁用 Learning Rate Dropout - 第 7 步 - 风格和颜色(可选)
启用 模糊遮罩、"真实面部 "功能(仅限 DF)、面部风格功能、背景风格功能 - 第 8 步 - 眼睛和嘴巴优先(可选)
启用 眼睛和嘴巴优先 - 第 9 步:Uniform Yaw(可选)
禁用 眼睛和嘴巴优先
启用 Uniform yaw distribution of samples - 第 10 步:LRD(可选)
启用 Learning Rate Dropout
禁用 眼睛和嘴巴优先
禁用 Uniform yaw distribution of samples(可选)
(3.6.4)增强/GAN 训练(可选)
- 第 11 步 - GAN
禁用 眼睛和嘴巴优先
禁用 Uniform yaw distribution of samples
设置 GAN power
设置 GAN patch size
设置 GAN dimensions
(3.7)训练成果
训练好的“单个模型”,就是是 “1个人的src对应1或N个人的dst” 的学习成果。
这时只需要模型和dst,就可以合成视频了。
由于模型具有泛化能力,如果你用别人的“某人”模型,其实是可以直接尝试合成一个没训练的dst的。
模型文件大概是这样的一组文件,当然无论训练好了没有,都是同样的文件名。
放置在\DFL_Path\workspace\model\目录中

(四)合成
这部分没什么变化。
确保 模型+目标视频帧图片+目标脸部数据集 位置正确。
执行:7) merge XX模型类型.bat。
合成阶段最好还是用交互式合成界面的。
详细的可以参考这贴。
合成快捷键可继续参考《如何翻译DeepFaceLab(DeepFake)的交互式合成器》
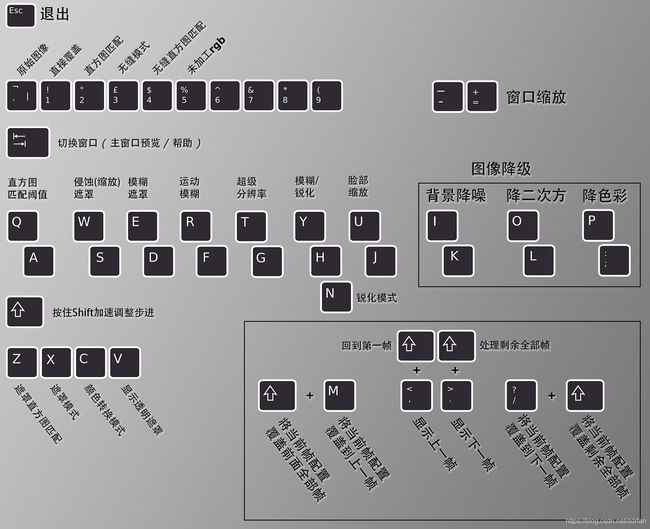
对了,上面的界面只是帮助界面。
需要按一下Tab进入真正的合成预览界面,
这时候快捷键才能生效。
然后,通常只需要:
- 用
W/S调整侵蚀遮罩(5-30)。 - 用
E/D调整模糊(50-100)。 - 用
C选择一种颜色转换(看着自然就行)。
根据情况不同,也许还需要:
- 用
X选一种遮罩方式(默认是学习到的src+dst遮罩,就算之前从未写入遮罩,合成时也可放入通用Xseg遮罩文件并选用它) - 用
U/J调整src的脸部大小,去适应dst的脸盘子大小(看着自然就好)。 - 用
T/G调整超分辨率(模型分辨率小,而dst画面分辨率高+脸部占比太大)。
当调整这些参数的时候,命令行窗口总是会显示:进度/当前帧,以及当前帧参数设置情况。

总之调整到自然之后,用Shift+/将当前帧的设置用于后面所有帧。
如果你设置的不是第一帧,则可能还需要用Shift+M将当前帧的设置用于前面所有帧。
最后,可以选择按>一帧帧的合成(适合第一次合成,不同场景需要调整不同参数)。
也可以从第一帧开始按Shift+>合成所有帧。
命令行进度条走完,所有视频帧就都合成完毕了。
(4.1)合成参数
下面是按键功能和几个重要参数的含义。粗体是默认的设置,高亮是常用的设置(不见得吧)。
其实可以尝试各种不同的参数,预览图像效果,比单纯文字解释更清晰。
按键功能:
- [`,1-6] Overlay Mode:见图像的 覆盖方式>>>
- [Z] Masked Hist-Match:遮罩或非遮罩的直方图匹配
- [Q,A] His-Match Threshold:直方图匹配阈值
- [W,S] Erode Mask Modifier:扩大或缩小遮罩区域.
- [E,D] Blur Mask Modifier:羽化(模糊)遮罩边缘
- [R,F] Motion Blur Power:运动模糊强度(小心场景切换).
- [U,J] Output Face Scale:脸部大小调节.
- [X,] Mask mode:见遮罩模式>>>
- [C] Color Transfer Mode:见色彩转换模式.>>>
- [V] Show Alpha Mask:显示透明遮罩(图像确认遮罩设置情况).
- [N] Sharpen Mode:锐化模式.
- [Y,H] Blur/Sharpen Amount:模糊/锐化强度.
- [T,G] Super Resolution Power:超分辨率强度
- [I,K] Image Denoise Power:画面降噪强度
- [O,L] Bicubic Degrade Power:双三次减弱强度.
- [P,;] Color Degrade Power:色彩减弱强度.
覆盖方式(Overlay Mode):
- [`] Original: 显示原始的dst视频帧图像.
- [1] Overlay: 直接覆盖(叠加).
- [2] Hist-Match: 使用直方图匹配进行叠加.
- [3] Seamless: 使用 OpenCV Poisson 无缝克隆技术混合人脸.
- [4] Seamless Hist-Match: 结合 Seamless 和 Hist-Match.
- [5] Raw-RGB: 覆盖整个学习的面部区域(正方形)无遮罩.
- [6] Raw-Predicted: 只输出预测(学习)的人脸, 像人脸数据集一样的方形图像.
遮罩模式(Mask_Mode):
- dst: 默认生成的目标遮罩
- learned-prd: 在训练中基于源学习的遮罩
- learned-dst: 在训练中基于目标学习的遮罩
- learned-prd*learned-dst: 使用最小面积的组合已学习的遮罩组合
- learned-prd+learned-dst: 使用最大面积的组合已学习的遮罩组合
- XSeg-prd: 基于源的 XSeg 遮罩(需要 XSeg 模型)
- XSeg-dst: 基于目标的 XSeg 遮罩(需要 XSeg 模型)
- XSeg-prd*XSeg-dst: 使用最小面积的 XSeg 遮罩组合(需要 XSeg 模型)
- learned-prdlearned-dstXSeg-prd*XSeg-dst: 使用最小面积的遮罩组合(需要 XSeg 模型)
- full: 遮罩扩展到脸部边界(正方形),类似于无遮罩。
颜色转换模式(Color Transfer Mode):
- none:无色彩转换
- rct:Reinhard色彩转换(遮罩)
- lct:线性色彩转换
- mkl:Monge-Kantorovitch 线性 色彩转换
- mkl-m:MKL带遮罩
- idt:Iterative Distribution Transfer(迭代分布转换)
- idt-m:IDT带遮罩
- sot-m:Sliced Optimal Transport 带遮罩
- mix-m:RCT/LCT/SOT混合屏蔽(可能是)
(4.2)覆盖模式+遮罩对比
下面用个例子对比看看(其它参数比如侵蚀/羽化/色彩转换有调节)。
-
Mode:
original: 显示原始的dst视频帧图像(志玲姐).

-
Mode:
overlay: 直接覆盖(叠加)
Mask:full:无遮罩,整个正方形区域都用(经常有人问为什么有个方形的框,因为没遮罩,就没范围)

-
Mode:
overlay: 直接覆盖(叠加)
Mask:learned-prd*learned-dst: 使用最小面积的组合已学习的遮罩组合(手指反而被脸部遮挡)

-
Mode:
overlay: 直接覆盖(叠加)
Mask:XSeg-prd*XSeg-dst:使用最小面积的 XSeg 遮罩组合(需要 XSeg 模型)(手指遮挡脸部正常)

(五)合成的图片转视频
这部分没什么变化。
确保 合成后视频帧图片+ 目标视频(data_dst.mp4) 位置正确。
执行:8) merged to mp4.bat。建议输入个超高的码率,便于后期用视频软件处理。
需要原始的目标视频,是因为要它的音频和码率。。。
⚠️千万不要用8) merged to mp4 lossless.bat。视频质量会出奇的低,各种色块,不知道是什么bug。
除非你参考《可以提高DeepFaceLab(DeepFake)合成最终视频速度的方法》里面的内容修改了lossless的源代码。
既然改了代码,就强烈建议用N卡的nvenc方式,真的快很多倍啊。
合成完毕,输出的视频叫result.mp4。
恭喜你,现在志玲姐的影视片段,由你来主演了。
后面就是PR,AE,Vegas的事儿了。
(六)总结
-
所有的辅助软件都在开始(人脸数据集素材)阶段起作用。
-
素材准备最最重要。完全正确的脸部识别+遮罩,将大幅增加合成的自然度,还可以降低训练时间。
-
记得复用模型,换dst可直接训练,甚至0训练直接合成。
-
单个模型是单个src的模型,复用模型但换src是需要更多训练的。
如果是liae模型就删除xx_SAEHD_inter_AB.npy文件再训练新src。