【IR】Vision-Language Tracking
调研:视觉-语言跟踪
- 0x01 Transformer vision-language tracking via proxy token guided cross-modal fusion, PRL2023
-
- Abstract
- Introduction
- Contribution
- 效果
- Conclusion
- 0x02 Divert More Attention to Vision-Language Object Tracking, NeurIPS2022
-
- Abstract
- Introduction
- Contribution
- 统一自适应的vision-language跟踪方法和数据库
- 效果
-
- 消融实验
- 0x03 Vision-Language Intelligence:Tasks, Representation Learning, and Large Models, 2022 综述
-
- 【2014-2018】
- 【2019-2021】
- 【2021- 】
- 0x04 Towards Unified Token Learning for Vision-Language Tracking, TCSVT2023
- 注释
- 关键问题
ChatGPT says:
一些常见的视觉-语言跟踪任务及其应用领域:
1. 视频跟踪(Video Tracking):将视觉-语言技术与视频跟踪相结合,可以实现对视频中目标的跟踪和理解。通过使用视觉特征和语言信息,可以在视频中标记和跟踪感兴趣的物体、行为或者场景。这在监控和安全领域中具有重要意义。
2. 文本跟踪(Text Tracking):对于文本数据,视觉-语言技术可以用于跟踪和理解文本在不同场景和上下文中的变化。例如,在社交媒体分析中,可以使用视觉-语言跟踪来追踪话题、关键词或者事件的演变,从而实现对文本内容的实时监测和分析。
3. 目标跟踪与描述(Object Tracking and Description):视觉-语言技术可以用于将目标的视觉跟踪结果与相应的文字描述关联起来。这可以提供更加细致和丰富的目标理解和描述。例如,在自动驾驶领域,视觉-语言跟踪可以用于将车辆、行人或者交通信号等目标的视觉跟踪结果与语义描述相结合,实现对道路环境的更深入理解和表达。
4. 时空关系跟踪(Temporal-Spatial Relationship Tracking):视觉-语言技术可以用于跟踪和理解物体在时空上的关系变化。例如,在视频中跟踪人与物体之间的相对位置和运动关系,以及对场景中事件的描述和解释。
5. 多模态跟踪(Multimodal Tracking):视觉-语言技术可以跨越多个模态,如图像、音频和文本,进行综合跟踪和理解。这种方法可以实现更全面和多样化的跟踪任务,如多模态情感分析、多模态事件检测等。
0x01 Transformer vision-language tracking via proxy token guided cross-modal fusion, PRL2023
文章链接

Abstract
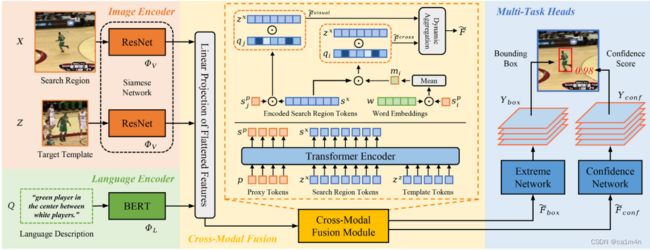
以往的研究主要采用CNN和序列模型对视频和语言进行编码,但是泛化性能(generalization)不佳。为了解决这一问题,本文提出一种基于transformer的VL 跟踪框架:包含图像编码器、语言编码器、跨模态融合模块和特定任务的头部。我们采用残差网络和BERT分别对图像和语言进行嵌入。
更重要的是,我们提出一个基于transformer的代理token引导的跨模态融合模块。代理token作为单词嵌入的代理,并与视觉特征进行交互。通过吸收视觉信息,利用代理token对单词嵌入进行调整,使其关注视觉特征。
最后,通过动态模态聚合(aggregation)方法得到有机融合的特征,并将其输入到特定任务的头部进行跟踪。
Introduction
视觉跟踪的目标是一个视频序列中定位初始化的目标。在大多数情况下,目标是使用在视频序列开始的bounding box来指定的,基于这个bounding box来提取目标对象的视觉表征(visual representation),进行跟踪。
但是存在以下问题:
1、遮挡;
2、外观不可靠(如人脱衣服的外观变化和快速运动等);
3、目前的跟踪器只对RGB帧进行训练,可能无法从大规模的多模态语料库或知识库中学习。
从而,本文提出在自然语言的指导下重新制定跟踪任务。同时,提出了用于自然语言辅助视觉跟踪的大规模基准数据集,如LaSOT和TNL2K。
框架包含4个主要组成模块:图像编码器(ResNet),语言编码器(BERT),跨模态融合模块(Transformer),特定任务头。
将图像和语言特征输入到一个精心设计的基于代理token引导transformer网络的特征融合模块中。代理token作为单词嵌入的代理(避免冗长的word embeddings带来的巨大计算开销),并与视觉特征进行交互。代理token通过吸收视觉信息,对词嵌入进行调制,使其关注视觉特征。此外,我们设计了一个新的置信网络来预测置信分数,将有利于特征聚合(feature aggregation)。
Contribution
- 针对自然语言辅助的视觉跟踪问题,提出了一个新颖的代理token指导的transformer框架(TransVLT)
- 对LTB50长期跟踪数据集中每个视频的语言描述进行了密集标注,语言查询的各种设置表明,不断更新的语言进一步提高了跟踪效果。作者还发现,类别信息对于长期跟踪(long-term tracking)来说是给定句子的重要组成部分。
- 在4个自然语言辅助跟踪数据集上的大量实验都证明了本文提出的跟踪器的强大性能。
效果
性能结果:
 消融实验:
消融实验:

LTB50数据集只有视频的第一帧有标注,经过密集标注的LTB50(Ref-LTB50)数据集的效果如下:
左栏是VOT2020挑战中最佳五款追踪器的结果(作为参考),中间是本文的方法,右栏使用SNLT(开源的vision-language tracker较少): Cate表示有类别信息作为相应的语言描述,First就是第一帧有标注,以此类推占比。
Cate表示有类别信息作为相应的语言描述,First就是第一帧有标注,以此类推占比。
直觉上,标注信息更多,跟踪效果会更好,特别是long-term数据集,但是怎么标注数据集的呢?值得接下来进行学习
Conclusion
本文提出一种针对视觉-语言跟踪的新框架。为了融合两个模块信息,我们设计了一个基于transformer的融合模块,并且使用代理token去指导跨模态注意力。我们针对跟踪和模块聚合,提出了一个新颖的置信估计方法。
为了丰富未来的研究,我们提出一个密集标注的长期目标跟踪数据集。
大量实验表明本文提出的跟踪头表现超过大多数SOTA方法。
总之,我们希望我们的方法能够为未来的研究提供一个强有力的基线,并期望所提出的密集注释数据集能够促进更现实场景的研究。
0x02 Divert More Attention to Vision-Language Object Tracking, NeurIPS2022
文章链接

Code
Abstract
由于大型基础模型的出现,多模态视觉-语言(VL)学习显著地推动了通用智能的发展。然而,跟踪作为一个基本的视觉问题,没有得到显著发展,作者认为原因有两方面:一是缺乏大规模的VL注释视频;二是当前工作的VL交互学习效果不佳。这些麻烦促使我们设计更有效的视觉语言表示来跟踪,同时构建一个带有语言标注的大型数据库来学习模型。
本文首先提出了一种通用的属性标注策略来修饰6种常用的跟踪基准,从而构建了一个包含23000多个视频的大规模vision-language tracking 数据库。
然后引入一个新的框架,通过学习统一自适应(unified-adaptive)的VL表示来改进跟踪。其中的核心是提出的非对称架构搜索和模态混合器(ModaMixer)。为了进一步改善VL表征,引入了一种对比损耗来对齐不同的模式。
为了充分证明方法的有效性,我们将所提出的框架集成在三种不同设计的跟踪方法上,即基于CNN的SiamCAR、基于transformer的OSTrack、混合结构的TransT。实验表明,我们的框架可以在六个基准上显著改善所有的baselines。
除了实证结果外,我们还对我们的方法进行了理论分析,以证明其合理性。通过揭示VL representation的潜力,我们希望社区将更多注意力转移到VL跟踪上,并希望为未来的跟踪与多样化的多模态信息提供更多的可能性。
Introduction
多模态视觉-语言学习在近年来随着下游任务(比如visual question answering和imgae/video caption)的涌现,再到SAM和视觉大语言模型的出现,得到不断发展。但是缺乏语言标注的数据库和复杂的模型设计,VL tracking的强大功能还需要更深入的研究。
在LaSOT上,纯视觉和多模态视觉-语言跟踪器的比较:
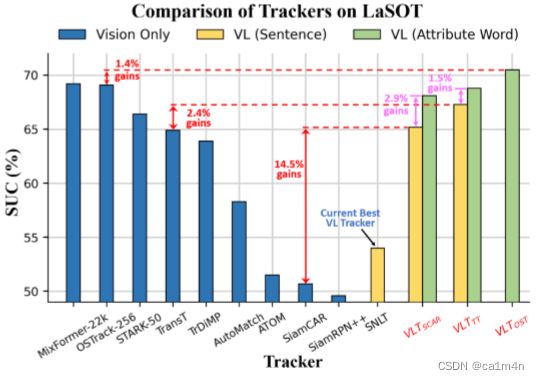
之前的工作将目标的语言描述作为prompt(template),在搜索区域的视觉特征中搜索预定义的对象。尽管简单,但它们的性能和SOTA方法相比仍有很大差距。原因如下:
- 视觉和语言被独立处理和远距离处理,直到最后的匹配模块。虽然这种方式可以很容易将两个模块连接起来,但并不符合人类在因果推理之前通过各种神经元整合多感觉的的学习过程。
- 将模板和搜索分支视为同质输入,之前的方法对这两个分支采用对称的特征学习结构,继承了典型的纯视觉孪生网络跟踪方法。作者认为混合模态可能具有纯视觉模态不同的内在本质,因此需要对不同信号进行更灵活和自适应的设计。
Contribution
- 属性标注策略,用通用属性词标注了6种流行的跟踪数据集,为VL跟踪提供了一个强大的数据库。
- 我们提出了一个概念简单但新颖和有效的模态混合器(ModaMixer)用于统一VL表征学习。
- 我们提出了非对称搜索(ASearch),该策略适应混合VL表征,以提高跟踪鲁棒性。
- 通过使用多个不同架构的多个baselines, 我们的VL跟踪框架通常可以显著提高性能。
统一自适应的vision-language跟踪方法和数据库
 属性标注策略用四个属性词(主类、根类、颜色、目标的初始位置)描述视频中的每个目标。
属性标注策略用四个属性词(主类、根类、颜色、目标的初始位置)描述视频中的每个目标。
统一表征的模态混合器来演示一种紧凑的方法来学习统一的VL表示进行跟踪。
ModaMixer示意图(黑箭头表示推理方向,灰箭头表示训练时外部比损失)
 如上图,首先构建语言表示(细节查看原文)。类似于通道注意力,语言表示中的高级语义可以动态增强视觉特征的特定目标通道,同时抑制类间和类内干扰。
如上图,首先构建语言表示(细节查看原文)。类似于通道注意力,语言表示中的高级语义可以动态增强视觉特征的特定目标通道,同时抑制类间和类内干扰。
再通过线性层将语言特表征 f l f_l fl的通道数和对应的视觉特征 f v f_v fv进行对齐(通道选择器表示为Hadamard乘积算子)。最后,在混合特征 f m f_m fm和视觉特征 f v f_v fv之间进行残差连接这几篇文章都这么做,以避免丢失信息细节。简单来说,ModaMixer被定义为:
f m = B l o c k A S e a r c h ( L i n e a r ( f l ) ⊙ f v ) + B l o c k A S e a r c h ( f v ) f_m=Block_{ASearch}(Linear(f_l) \odot f_v)+Block_{ASearch}(f_v) fm=BlockASearch(Linear(fl)⊙fv)+BlockASearch(fv)
为了进行更深层次的多模态对齐,在训练时将对比损失进一步应用到ModaMixer中(上图的灰色箭头)。
除了融合模块,VL跟踪的另一个关键问题是如何构建基本的建模结构。最简单的策略是从基于视觉的跟踪算法继承一个对称的孪生网络。但是忽略了基于视觉-语言多模态和纯视觉的单模态的本质上的不同,因此本文提出了一种非对称搜索策略(ASearch)来学习与ModaMixer配对的自适应建模结构。
我们采用一种流行的神经结构搜索(NAS)模型,特别是单路径一次性(SPOS)方法来搜索目标的最优结构。
通过ASearch学习到的不对称架构的配置:

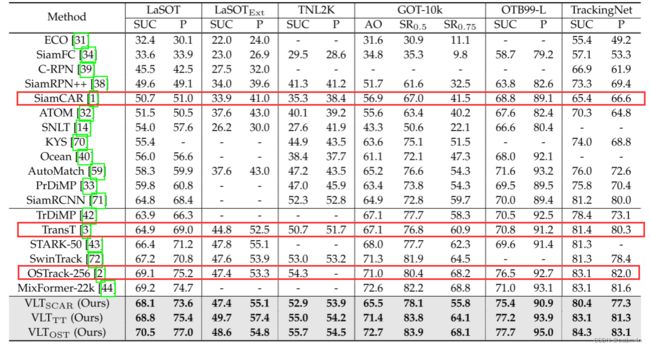
效果
在具有挑战性的LaSOT上,本文提出的基于CNN的孪生网络跟踪器在SUC上从50.7%提升到65.2%,并且超过基于transformer的跟踪器。
SUC(Success Rate):SUC是针对跟踪任务而设计的评价指标,用于衡量跟踪算法在成功跟踪目标的情况下的准确率。SUC通常被定义为目标在跟踪序列中成功跟踪的帧数与总帧数之比。quoted from chatGPT
消融实验
Baseline:基于CNN的SiamCAR[1]

更多实验和可视化结果见原文
0x03 Vision-Language Intelligence:Tasks, Representation Learning, and Large Models, 2022 综述
文章链接 香港科技大学 | IDEA | 中国科学院 | 清华大学 | 微软研究院 | 香港科技大学(广州)
香港科技大学 | IDEA | 中国科学院 | 清华大学 | 微软研究院 | 香港科技大学(广州)
《视觉-语言智能:任务、表征学习和大模型》
这项研究的灵感来自于CV和NLP的remarkable的发展进程,以及从单模态向多模态发展的趋势。从时间上,将VL发展划分为三个阶段:
【2014-2018】
TASK SPECIFIC PROBLEMS
最开始图像-文本任务的模型是为各数据集的特定问题量身定制的(每个模型只能解决一个任务),为了解决特定的任务。
Image Captioning
Seq2Seq在机器翻译方面取得巨大成功,也就是cnn-rnn模型[2]。将文本编码器换成GoogleNet作为图像编码器,提出了img2seq。在解码阶段利用全局CNN特征,但是全局CNN特征有明显的缺点:解码器无法像人类一样聚焦到重要区域,于是引入了注意力机制。再到预训练的detector发展。
总之,早期image captioning方法发展主要有两个方面,即视觉表示和语言编码。视觉表示从图像级的全局特征发展到细粒度和对象级的区域特征,语言编码从LSTM发展到基于注意力的模型。
VQA
VQA的核心是获取图像和语言的联合表示。该领域的大多数工作都是将图像与语言独立编码,然后进行融合,这类似于VLP(Visual-Linguistic Pretraining)的双流法。也有将图像嵌入视为一种语言标记,类似于单流法。
Image Text Matching
ITM的核心是计算图像和文本间的相似度或距离。一个被广泛采用的原型是将图像和文本映射到共享的嵌入空间,然后计算它们的相似性。
【2019-2021】
通过对标记良好的VL数据集进行预训练,学习视觉和语言的联合表征。
VLP方法概貌:

【2021- 】
以CLIP为开始,研究人员寻求在更大的弱标记数据集预先训练VL模型,并通过VL预训练获得强大的零/少样本视觉模型。
0x04 Towards Unified Token Learning for Vision-Language Tracking, TCSVT2023
单独写作一篇了
【VL tracking】Towards Unified Token Learning for Vision-Language Tracking
注释
[1] D. Guo, J. Wang, Y. Cui, Z. Wang, and S. Chen, “SiamCAR: Siamese fully convolutional classification and regression for visual tracking,” in CVPR, 2020.
[2] 一文纵览 Vision-and-Language 领域最新研究与进展, 2019.
关键问题
1、建立多模态间一致性关系(比如融合模块的策略、视频前后帧信息利用)
2、替换特征提取模块
3、数据集,统一标注或弱标注
接下来,去补习BERT和CLIP