sql自定义多条件排序规则及优化思路
sql自定义排序规则
一、mysql自定义排序规则
使用field函数
使用格式
select * from 表名 order by field(字段名称,字段值1,字段值2..)
举例:在员工中排序按 领导,正式员工,试用员工,实习生 顺序排序
select * from emp order by field(postName,'领导','正式员工','试用员工','实习生')
如果有多个排序条件规则可以使用逗号分隔
select * from 表名 order by field(字段名称1,字段值1,字段值2..),field(字段名称2,字段值1,字段值2..)
二、oracle自定义排序规则
使用decode函数
使用格式:
select * from 表名 order by decode(字段名称,字段值1,优先级值,字段值2,优先级2...);
场景举例:展示员工信息,排序规则如下:
1、先按部门排序,创新事业部,研发中心,信息化事业部置前,其他部门置后
2、按岗位排序:部门经理,项目经理,Java开发工程师,前端开发工程师,测试开发工程师,运维开发工程师置前,其他岗位置后;
3、最后按入职时间排序;
ORDER BY
decode(DEPART_NAME,'业务创新事业部',1,'研发中心',2,'信息化事业部',3),
decode(POST_NAME, '部门经理',1,'项目经理',2,'java开发工程师',3,'前端开发工程师',4,'测试开发工程师',5,'运维工程师',6),
ENTRY_DATE desc
三、优化
可以发现sql语句存在硬编码,可以通过新建一张参数表,与之关联,修改表数据来修改排序规则
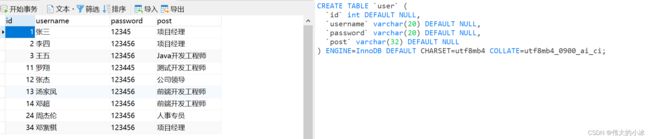
(0)员工表信息
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int NULL DEFAULT NULL,
`username` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`password` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`post` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user
-- ----------------------------
INSERT INTO `user` VALUES (1, '张三', '12345', '项目经理');
INSERT INTO `user` VALUES (2, '李四', '123456', '项目经理');
INSERT INTO `user` VALUES (3, '王五', '123456', 'Java开发工程师');
INSERT INTO `user` VALUES (11, '罗翔', '123445', '测试开发工程师');
INSERT INTO `user` VALUES (12, '张杰', '123456', '公司领导');
INSERT INTO `user` VALUES (13, '汤家凤', '123456', '前端开发工程师');
INSERT INTO `user` VALUES (14, '邓超', '123456', '前端开发工程师');
INSERT INTO `user` VALUES (24, '周杰伦', '123456', '人事专员');
INSERT INTO `user` VALUES (34, '邓紫棋', '123456', '项目经理');
实现过程:
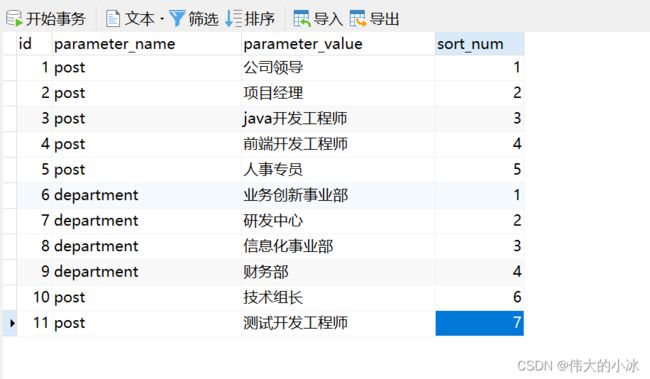
(1) 新建参数表 parameter并插入数据
CREATE TABLE `parameter` (
`id` int NOT NULL AUTO_INCREMENT,
`parameter_name` varchar(64) DEFAULT NULL, -- 参数名称
`parameter_value` varchar(64) DEFAULT NULL, -- 参数值
`sort_num` int DEFAULT NULL,
PRIMARY KEY (`id`)
);
INSERT INTO `parameter` VALUES (1, 'post', '公司领导', 1);
INSERT INTO `parameter` VALUES (2, 'post', '项目经理', 2);
INSERT INTO `parameter` VALUES (3, 'post', 'java开发工程师', 3);
INSERT INTO `parameter` VALUES (4, 'post', '前端开发工程师', 4);
INSERT INTO `parameter` VALUES (5, 'post', '人事专员', 5);
INSERT INTO `parameter` VALUES (6, 'department', '业务创新事业部', 1);
INSERT INTO `parameter` VALUES (7, 'department', '研发中心', 2);
INSERT INTO `parameter` VALUES (8, 'department', '信息化事业部', 3);
INSERT INTO `parameter` VALUES (9, 'department', '财务部', 4);
INSERT INTO `parameter` VALUES (10, 'post', '技术组长', 6);
INSERT INTO `parameter` VALUES (11, 'post', '测试开发工程师', 7);
(2)参数表中存入所有岗位名称信息(数据中有岗位,部门两块信息),其中sort_num为优先级大小
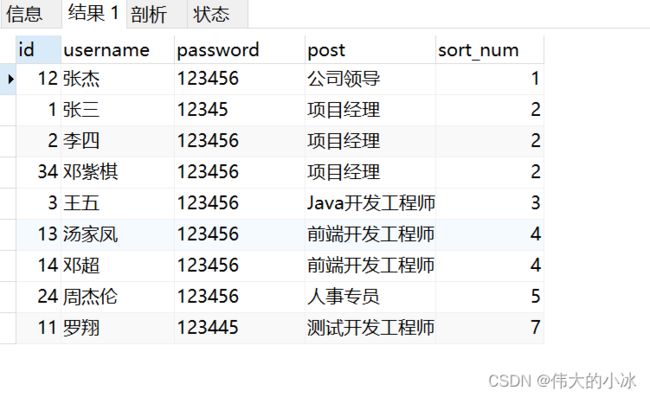
(3)员工表与参数表关联
SELECT
user.* ,p.sort_num
FROM
USER
LEFT JOIN
parameter p
on
p.parameter_value = user.post
ORDER BY
p.sort_num asc
查询出的结果为:
当排序规则发生变化时,可以通过修改表数据进行调整,更灵活更便于维护
note:参数表中parameter_name = 'post’所对应的parameter_value的值为所有的岗位信息,即参数表的岗位信息 >= 员工表中岗位信息
(建的数据库表比较随意,只是为了给大家提供一种优化思路哈)
参照文章:https://blog.csdn.net/hscch/article/details/82348621