Pytorch中的DataLoader
dataloader基本信息(定义及参数)
dataloader的定义
官方给出的定义是:
 即:数据加载器。组合数据集和采样器,并在数据集上提供单进程或多进程迭代器。
即:数据加载器。组合数据集和采样器,并在数据集上提供单进程或多进程迭代器。
换句话说,通常在训练时我们会将数据集分成若干小的、随机的批(batch),这个操作当然可以手动操作,但是pytorch里面为我们提供了API让我们方便地从dataset中获得batch,DataLoader就是来解决这个问题的。
它的本质是一个可迭代对象,即经过DataLoader的返回值为一个可迭代的对象,一般的操作是:1、创建一个 dataset 对象;2、创建一个DataLoader对象;3、遍历这个DataLoader对象,将data, label加载到模型中进行训练。
dataloader的基本参数解释
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, \
batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, \
drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None)dataset:官方文档给出的解释是 “ 从中加载数据的数据集 ” 。
batch_size(int,可选):每个批次要加载的样本数(默认值:1)。
shuffle(bool,可选):设置为“True”可在每个epoch重新排列数据(默认值:“False”)。一个epoch表示数据集的数据全部使用一遍。
sampler(sampler,可选):定义从数据集中提取样本的策略。如果指定,“shuffle”必须为False。batch_sampler 类似,表示一次返回一个batch的索引。
num_workers(int,可选):用于数据加载的子进程数,0 表示将在主进程中加载数据。(默认值:0)。换句话说,num_workers = 0 表示在主进程中加载数据而不使用任何额外的子进程;若大于0,表示开启多个进程。进程越多,处理数据的速度越快,但会使电脑性能下降,占用更多的内存。
collate_fn(可调用,可选):表示合并样本列表以形成小批量的Tensor对象。
pin_memory(bool,可选):表示要将load进来的数据是否要拷贝到pin_memory区中,其表示生成的Tensor数据是属于内存中的锁页内存区,这样将Tensor数据转义到GPU中速度就会快一些,默认为False。如果为“True”,数据加载程序将在返回张量之前将张量复制到CUDA固定内存中。通常情况下,数据在内存中要么以锁页的方式存在,要么保存在虚拟内存(磁盘)中,pin_memory设置为True后,数据直接保存在锁页内存中,后续直接传入CUDA;否则需要先从虚拟内存中传入锁页内存中,再传入CUDA,这样就比较耗时了。
drop_last(bool,可选):当整个数据长度不能够整除batch_size,选择是否要丢弃最后一个不完整的batch,默认为False。设置为“True”时可以删除最后一个不完整的批次(batch)。
使用dataloader
我们以torchvision内置的数据集cifar10为例,来说明dataloader的运行机制,cifar10数据集的网页链接:https://www.cs.toronto.edu/~kriz/cifar.html,下载链接为:https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
数据集展示:
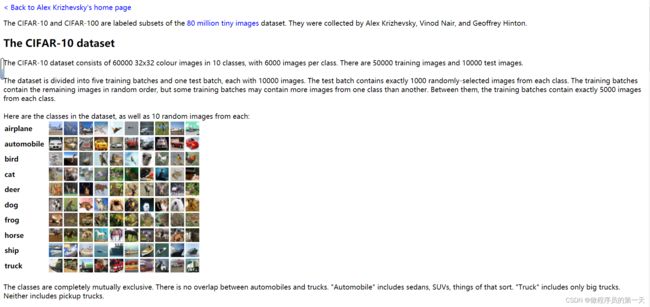
创建一个dataset对象
import torchvision.datasets
from torch.utils.data import DataLoader
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())运行上述代码,则会在项目根目录下创建一个名为 dataset 的文件夹,并且由于 download=True 的存在会自动下载数据集存放于该文件夹内。
test_data的内容为图像信息与标签信息的组合。执行下述代码,我们发现返回的图像 img 信息为3通道32✖32尺寸的图片,标签归属为 3 。
img, target = test_data[0]
print(img.shape) # torch.Size([3, 32, 32])
print(target) # 3创建一个DataLoader对象
import torchvision.datasets
from torch.utils.data import DataLoader
test_data = torchvision.datasets.CIFAR10("./dataset", train=False,
transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=4,
shuffle=True, num_workers=0,
drop_last=True, pin_memory=True)遍历这个DataLoader可迭代对象
step = 0
for data in test_loader:
imgs, targets = data
print(imgs.shape)
print(targets)
step = step + 1运行结果为:
torch.Size([4, 3, 32, 32])
tensor([2, 9, 5, 0])
torch.Size([4, 3, 32, 32])
tensor([0, 1, 0, 6])
torch.Size([4, 3, 32, 32])
tensor([4, 7, 9, 5])
torch.Size([4, 3, 32, 32])
tensor([2, 3, 4, 6])
torch.Size([4, 3, 32, 32])
tensor([4, 2, 5, 5])
……我们取出第一组来解释,即:torch.Size([4, 3, 32, 32]),tensor([2, 9, 5, 0])。
对于torch.Size([4, 3, 32, 32]),则表示取出样本图像的信息,4表示第一批次(batch)取了4张图片,对应batch_size=4;3表示每张图片是3通道的,后面两个32表示每张图片的尺寸为32✖32。
对于tensor([2, 9, 5, 0]),则表示这四张图片的标签张量,其中2、9、5、0分别代表取出的第1、2、3、4张图片的标签。
注意:由于在本次小实验中并没有设置sampler的值,而sampler的默认值为随机选取,因此才会出现test_data[0](第一张图片)的图像标签是3,而在遍历DataLoader对象时第一个图像标签却是2。
参考自:
https://blog.csdn.net/anshiquanshu/article/details/112868740
pytorch 中的DataLoader_datalodar_Nancyhan88的博客-CSDN博客