Langchain使用介绍之-文档加载
Lanchain提供了加载多种文档的能力,Lanchain初了能加载txt,csv等格式文档外,还支持加载网页,音频,pdf等。本篇博客将介绍如何通过Langchain完成PDF文档,音频文档,网页文档的加载。
加载PDF文档
通过使用Langchain提供的PyPDFLoader,可以非常容易的加载一个已有的pdf文档,需要注意一点:使用PyPDFLoader需要安装pip3 install pypdf。
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader(
'./chat-with-data/data/cs229_lectures/MachineLearning-Lecture01.pdf')
result = loader.load()
print(type(result))
print(len(result))
print(result[0])
page = result[0]
print(page.page_content)
print(page.metadata)加载完成后,打印加载的信息,可以看到结果信息类型是一个List,List的长度是22,这个pdf的页数也是22。所以,存放PDF文档内容是按页来存储的。每一个List中的值,包含page_content和metadata信息。
 可以单独获取每一页的page_content和metadata信息,结果如下所示:
可以单独获取每一页的page_content和metadata信息,结果如下所示:
 当然,上面只是介绍了如何加载PDF文档,实际langchain还支持加载html,csv,txt,json,markdown等格式的文档。更多信息可参考官网。
当然,上面只是介绍了如何加载PDF文档,实际langchain还支持加载html,csv,txt,json,markdown等格式的文档。更多信息可参考官网。
加载Youtube的音频信息
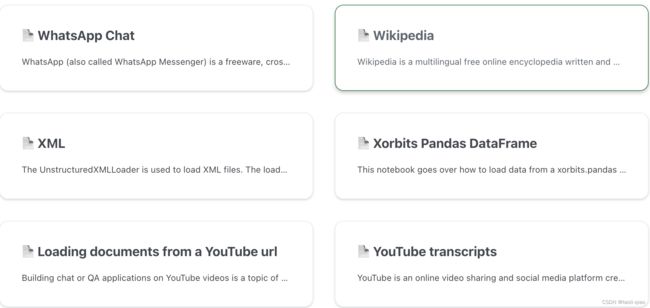
除了支持加载上面提到的,不同格式的本地文档外,Langchain也支持与很多第三方工具集成。如下图所示,langchain支持加载WhatsApp chat中的信息,加载Wikipedia的信息,也支持通过YouTube的url加载文档信息。除了截图显示的上方内容外,实际支持的第三方工具的集成还有很多,具体可查看官网。
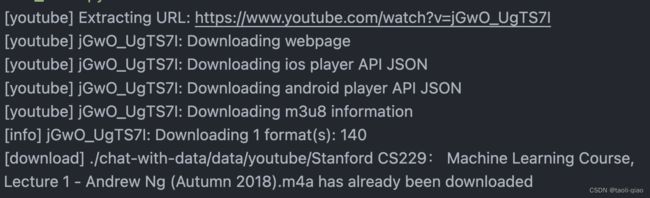
下面来看看如何通过youtube的url加载音频文件。对于给定的 YouTube 视频链接 (URL),使用 LangChain 加载器将视频的音频下载到本地,然后使用 OpenAIWhisperPaser 解析器,将音频转化为文本。
from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader
from langchain.document_loaders.generic import GenericLoader
from langchain.document_loaders.parsers import OpenAIWhisperParser
url = "https://www.youtube.com/watch?v=jGwO_UgTS7I"
save_dir = "./chat-with-data/data/youtube"
loader = GenericLoader(
YoutubeAudioLoader([url], save_dir),
OpenAIWhisperParser())
result = loader.load()
print(result)
print(type(result))
print(len(result))
print(result[0])执行上面的代码,会看到从url中下载audio文件到本地存储目录,然后通过OpenAIWhisperParser() 将音频文件转换成文字。
查看result的类型,会看到result的长度是1,类型是List,List中值的类型是
page_content包含该文档的内容。meta_data为文档相关的描述性数据。
加载Web Page
除了通过url加载youtube的audio文件外,也支持通过url加载web page中的内容,这里加载的是一个markdown格式的文档。
from langchain.document_loaders import WebBaseLoader
import json
url = "https://github.com/basecamp/handbook/blob/master/README.md"
header = {'User-Agent': 'python-requests/3.9.6',
'Accept-Encoding': 'gzip,deflate,br',
'Accept': '*/*',
'Connection': 'keep-alive'}
loader = WebBaseLoader(web_path=url, header_template=header)
result = loader.load()
print(type(result))
print(len(result))
# print(result[0])
# print(result[0].page_content)
print(result[0].metadata)
convert_to_json = json.loads(result[0].page_content)
print(convert_to_json)
print(convert_to_json['payload']['blob']['richText'])加载后生成的result类型也是List,List的长度是1,result[0]中的数据类型也是‘langchain.schema.document.Document',包含page_content和metadata信息,对于markdown格式的内容,可以看到page_content中除了真正的文档内容,还有很多其他信息。

查看page_content的详细类型,会看到“richText"字段后面才是真正的文档内容信息

所以,对于有些load过来的内容,可以通过json进行内容格式转换,获取真正的文档内容信息。
print(convert_to_json['payload']['blob']['richText'])获取到的信息就是真正的markdown文本内容信息。
以上,就是对Langchain提供的集中loader的介绍,更多敢于langchain提供的加载文档的能力,可查看官网具体的例子。