Python3 网络爬虫.3
在这一次的内容中,我们继续讨论BeautifulSoup的一些操作,我们这次只讨论几个在实践中用处特别大的几个函数。
这次我们将学习通过属性查找标签的方法,标签组的使用。
我们一起回忆一下,基本上,我们见过的每个网站都会使用层叠样式表(css,不懂的可以补一下网页相关知识)。这个css由于其结构的规范化,可以说是网络爬虫的福音。css可以上HTML元素呈现出差异化,使那些具有完全相同修饰的元素呈现出不同的样式。
比如,有一些标签看起来是这样的:
而另一些标签看起来是这样的:
网络爬虫可以通过class属性的值,轻松地区别出两种不同的标签。例如有些网站中一些内容是用红色标记出来的,而一些不重要的细节内容是用绿色字的,那么我们完全可以根据class属性抓取我们想要的内容,而忽略其它的内容。在现在大部分正规的网站中(比如说百度、阿里等),所有元素的处理都是十分符合标准的,每个元素的id是什么,属性是什么。。。这些设置方面都是及其有规律的,当然这样做是有道理的,因为在搭建一个网站的时候,就要为 以后的维护和升级打好基础,一个十分规范的网页代码,在后期维护起来 是特别容易的,可以大大节约人力 物力的,所以现在大部分网站的网页的源码是很规范的,这同时也就为我们编写爬虫提供了很好的便利,我们可以通过利用这些规范,编写爬虫,抓取我们所需要的内容。
这里我们来分析一个有趣的例子:
在豆瓣电影的网页中(网址为:https://movie.douban.com/),我们可以看到很多的关于电影的评价,如下图(这是我当前看到的,在不同时间会有相应的更新):

这个时候呢,我想找出这个网页中所有的电影的名字,然后将它打印出来,那么我该怎么做呢?这里就要用到我们刚刚说到的那个标签属性的知识了。我们首先俩审查一下这个名字元素,只要鼠标放在文章的名字上,然后鼠标右单击,在弹出的菜单中选择检查,这个时候便会跳到这个名字所对应的网页源码的地方了,如下图:
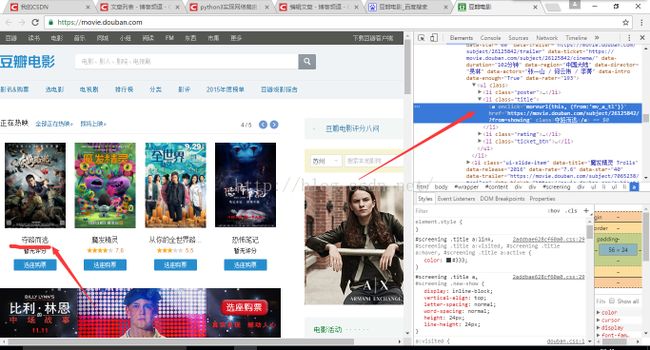
上图是我检查夺路而逃的这个电影名字,然后跳转到了右侧的源码的地方,这里我们会发现,这个名字是放在网页链接中的,也就是用包裹起来的,然后我们看它的上一级是li标签,在这里面是有class属性的,这时候是不是有一种灵光一闪的感觉,这是不是就是我们要找 的class元素呢,可以说这个直觉还是比较准的,当然了,写代码我们是讲究科学的,不能靠直觉,这时候我们便要求证自己的假设是否正确了,那我们就再去看看另外几本电影的名字呗,果然,一查看,这个class属性是一样,那么我们的工作便可以开始了。
下面直接上代码:
- #coding:utf - 8
- from urllib.request import urlopen
- from bs4 import BeautifulSoup
- html = urlopen(”https://movie.douban.com/”)
- bsObj=BeautifulSoup(html,”lxml”) #将html对象转化为BeautifulSoup对象
- liList=bsObj.findAll(”li”,{“class”:“title”}) #找到所有符合此class属性的li标签
- for li in liList:
- name=li.a.get_text() #获取标签中文字
- print(name)
#coding:utf - 8
from urllib.request import urlopen
from bs4 import BeautifulSouphtml = urlopen(“https://movie.douban.com/“)
bsObj=BeautifulSoup(html,”lxml”) #将html对象转化为BeautifulSoup对象
liList=bsObj.findAll(“li”,{“class”:”title”}) #找到所有符合此class属性的li标签
for li in liList:
name=li.a.get_text() #获取标签中文字
print(name)
程序运行的结果为:
奇异博士
深海浩劫
比利·林恩的中…
航海王之黄金城…
外公芳龄38
捉迷藏
驴得水
聊斋新编之画皮…
湄公河行动
机械师2:复活…
蜡笔小新:梦境…
邻家大贱谍
夺路而逃
魔发精灵
从你的全世界路…
恐怖笔记
育婴室
脱单宝典
但丁密码
减法人生
从结果可以看出,我们成功了,我们已经成功将网页中所有的电影的名字找出来并打印了出来。
下面我们来 分析一下代码:
首先我们来认识一下BeautifulSoup中我认为最有用处和用到最多的两个函数:find()和findAll()
函数原型:
findAll(tag,attributes,recursive,text,limit,keywords);
find(tag,attributes,recursive,text,keywords);
参数:
tag:标签参数tag前面我们已经看到过很多次了,你可以传一个标签的名称或者多个标签名称组成的python列表作为标签参数。
例如此代码是返回HTML文档中所有标题标签的列表:.findAll({“h1”,”h2”,”h3”,”h4”,”h5”,”h6”})
attributes:属性参数attributes是用一个python字典封装一个标签的若干个属性和对应的属性值。
例如此代码会返回HTML文档里红色和绿色两种颜色的span标签:.findAll(“span”,{“class”:{“green”,”red”}})
recursive:递归参数recursive是一个布尔变量。你想抓取HTML文档标签结构里多少层的信息?如果recursive设为True,findAll函数就会根据你的要求去查找标签参数中的所有子标签,以及子标签的子标签。如果recursive设置为False,findAll函数就只查找文档的一级标签。findAll函数默认是支持递归查找的(recursive默认值是True),一般情况下这个参数不需要设置,除非你真正想要了解自己需要哪些信息,而且抓取速度非常重要,那时你可以设置递归参数。
text:文本参数text有点不同,它是用标签的文本内容去匹配,而不是用标签的属性。假如我们想查找前面网页中包含“the prince”内容的标
签数量,我们可以用这个代码:
nameList=bsObj.findAll(text=”the prince”)
print (len(nameList))
limit:范围限制参数limit,显然只用于findAll方法。find其实等价于findAll的limit等于时的情形。如果你只对网页中获取的前n项结果感兴趣,就可以设置它。但是需要注意,这个参数设置之后,获得的前几项结果按照网页上的 顺序排序的,未必是你想要的那前几项。
keyword:这个参数可以让你选择那些具有特定属性的标签。
例如:allText=bsObj.findAll(id=”text”),这个代码可以让你获得所有id为text的标签的内容。
终于把这么多枯燥的参数说明抄完了,对于这种定义式的东西,我是不敢自己随意说的,当然要找本正规的书参考了。
这些参数其实用处都很大,只是我们平时在使用的时候用到最多的就是前两个,那么我们就可以省去很多记忆的东西了,以后需要的时候查资料就好了。
那么我们回到上面的程序中,程序中我们 findAll(“li”,{“class”:”title”})语句,便把我们在网页中带有class为title的li标签 全部拿到手了,然后,在每个li标签中,我们拿到链接,也就是用了li.a,因为li是一个对象,可以对其进行取出属性a的操作的,然后通过get_text()方法,拿到a中的内容。
关于get_text()方法,大家只要知道它可以帮助我们拿到存在于标签中的内容就好了,这里的内容是指<…>内容,即尖括号包起来的内容。