pytorch代码实现之空间通道重组卷积SCConv
空间通道重组卷积SCConv
空间通道重组卷积SCConv,全称Spatial and Channel Reconstruction Convolution,CPR2023年提出,可以即插即用,能够在减少参数的同时提升性能的模块。其核心思想是希望能够实现减少特征冗余从而提高算法的效率。一般压缩模型的方法分为三种,分别是network pruning, weight quantization, low-rank factorization以及knowledge distillation,虽然这些方法能够达到减少参数的效果,但是往往都会导致模型性能的衰减。另一种方法就是在构建模型时利用特殊的模块或操作减少模型参数,获得轻量级的网络模型,这种方法能够在保证性能的同时达到参数减少的效果。
原文地址:SCConv: Spatial and Channel Reconstruction Convolution for Feature Redundancy
作者提出的SCConv包含两部分,分别是Spatial Reconstruction Unit (SRU)和Channel Reconstruction Unit (CRU),下面是SSConv的总体结构。

可以看出,SCConv模块设计,对于输入的特征图先利用1x1的卷积改变为适合的通道数,之后便分别是SRU和CRU两个模块对于特征图进行处理,最后在通过1x1的卷积将特征通道数恢复并进行残差操作。
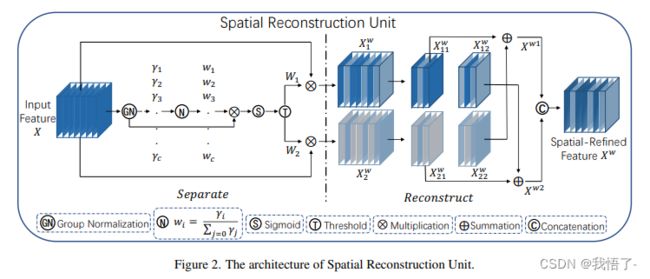
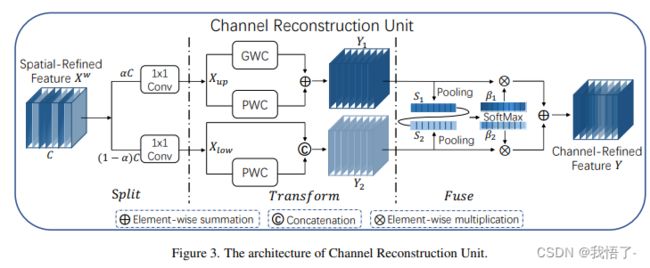
代码实现如下:
import torch
import torch.nn.functional as F
import torch.nn as nn
class GroupBatchnorm2d(nn.Module):
def __init__(self, c_num:int,
group_num:int = 16,
eps:float = 1e-10
):
super(GroupBatchnorm2d,self).__init__()
assert c_num >= group_num
self.group_num = group_num
self.gamma = nn.Parameter( torch.randn(c_num, 1, 1) )
self.beta = nn.Parameter( torch.zeros(c_num, 1, 1) )
self.eps = eps
def forward(self, x):
N, C, H, W = x.size()
x = x.view( N, self.group_num, -1 )
mean = x.mean( dim = 2, keepdim = True )
std = x.std ( dim = 2, keepdim = True )
x = (x - mean) / (std+self.eps)
x = x.view(N, C, H, W)
return x * self.gamma + self.beta
class SRU(nn.Module):
def __init__(self,
oup_channels:int,
group_num:int = 16,
gate_treshold:float = 0.5
):
super().__init__()
self.gn = GroupBatchnorm2d( oup_channels, group_num = group_num )
self.gate_treshold = gate_treshold
self.sigomid = nn.Sigmoid()
def forward(self,x):
gn_x = self.gn(x)
w_gamma = self.gn.gamma/sum(self.gn.gamma)
reweigts = self.sigomid( gn_x * w_gamma )
# Gate
info_mask = reweigts>=self.gate_treshold
noninfo_mask= reweigts<self.gate_treshold
x_1 = info_mask * x
x_2 = noninfo_mask * x
x = self.reconstruct(x_1,x_2)
return x
def reconstruct(self,x_1,x_2):
x_11,x_12 = torch.split(x_1, x_1.size(1)//2, dim=1)
x_21,x_22 = torch.split(x_2, x_2.size(1)//2, dim=1)
return torch.cat([ x_11+x_22, x_12+x_21 ],dim=1)
class CRU(nn.Module):
'''
alpha: 0<alpha<1
'''
def __init__(self,
op_channel:int,
alpha:float = 1/2,
squeeze_radio:int = 2 ,
group_size:int = 2,
group_kernel_size:int = 3,
):
super().__init__()
self.up_channel = up_channel = int(alpha*op_channel)
self.low_channel = low_channel = op_channel-up_channel
self.squeeze1 = nn.Conv2d(up_channel,up_channel//squeeze_radio,kernel_size=1,bias=False)
self.squeeze2 = nn.Conv2d(low_channel,low_channel//squeeze_radio,kernel_size=1,bias=False)
#up
self.GWC = nn.Conv2d(up_channel//squeeze_radio, op_channel,kernel_size=group_kernel_size, stride=1,padding=group_kernel_size//2, groups = group_size)
self.PWC1 = nn.Conv2d(up_channel//squeeze_radio, op_channel,kernel_size=1, bias=False)
#low
self.PWC2 = nn.Conv2d(low_channel//squeeze_radio, op_channel-low_channel//squeeze_radio,kernel_size=1, bias=False)
self.advavg = nn.AdaptiveAvgPool2d(1)
def forward(self,x):
# Split
up,low = torch.split(x,[self.up_channel,self.low_channel],dim=1)
up,low = self.squeeze1(up),self.squeeze2(low)
# Transform
Y1 = self.GWC(up) + self.PWC1(up)
Y2 = torch.cat( [self.PWC2(low), low], dim= 1 )
# Fuse
out = torch.cat( [Y1,Y2], dim= 1 )
out = F.softmax( self.advavg(out), dim=1 ) * out
out1,out2 = torch.split(out,out.size(1)//2,dim=1)
return out1+out2
class ScConv(nn.Module):
def __init__(self,
op_channel:int,
group_num:int = 16,
gate_treshold:float = 0.5,
alpha:float = 1/2,
squeeze_radio:int = 2 ,
group_size:int = 2,
group_kernel_size:int = 3,
):
super().__init__()
self.SRU = SRU( op_channel,
group_num = group_num,
gate_treshold = gate_treshold )
self.CRU = CRU( op_channel,
alpha = alpha,
squeeze_radio = squeeze_radio ,
group_size = group_size ,
group_kernel_size = group_kernel_size )
def forward(self,x):
x = self.SRU(x)
x = self.CRU(x)
return x
if __name__ == '__main__':
x = torch.randn(1,32,16,16)
model = ScConv(32)
print(model(x).shape)