一个迷惑性很高的生产故障-Elasticsearch日志rotate导致节点CPU激增
背景
Elasticsearch CPU很高的场景很常见,优化读写以及扩容即可解决问题。
如果只有一个节点CPU高,那可能的情况就比较多了,节点机器异常?读写不均匀?GC过高?forcemerge?
这里描述一个极具迷惑性的case。
问题
收到用户报障碍,突然有写入被reject,并且有一个节点的CPU突然增高。

分析、验证与结论
1.常用套路,先大致了解集群、索引。
集群层面:6.8.5 版本,18个节点(冷热分离)
索引层面:近3000个索引,大多数小索引(mb、1~10gb级别),template(设置1主分片、1副本分片)
用户行为:写多读少的OLAP场景
2.检查节点(pod)监控、宿主机监控、ES集群监控。没有很明显的异常行为。只能观测到异常节点CPU高、出现reject。用户的读写流量也没有观测到明显变化。
3.集群GC、merge等行为都很正常,并且只有一个节点CPU高(刚好用户索引都是1主1副),开始认为和热点相关。可能是某个索引的读写导致了节点CPU的上升。
4.使用 GET _nodes/hot_threads 查看CPU使用情况,果然抓到了异常节点占用CPU的主要是 write 线程。
5.由于hot_threads只能抓取瞬时的数据,不一定准确。准备进入容器,使用arthas工具抓取perf信息(arthas是阿里的开源工具、已经被我们集成到ES镜像里)。
通过arthas简要的获取热点线程:可以看到主要是write线程在执行bulk请求,然后还有日志打印的堆栈。

继续抓取2min内的统计信息:可以看到主要是search在使用CPU。和之前获取的信息不符。
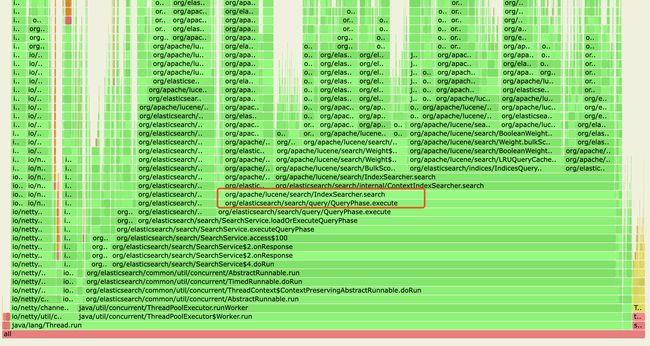
6.分析到底是读还是写影响的CPU。
a.如果是写热点导致,应该会有2个节点CPU高;
b.写入一般很难长时间打高CPU,而一个拉全量/大量数据的大请求很可能拉高CPU,由于index设置1主1副本,刚好可以解释只有一个节点CPU高;
c.考虑到抓取的数据perf结果,2min内的抓取结果比瞬时的可信;
综合来看,大查询导致的CPU高的概率很大。
7.继续走排障流程,查看日志信息
看到异常节点日志里大多都是这类异常。
elasticsearch org.apache.logging.log4j.core.appender.AppenderLoggingException: Error writing to stream /usr/share/elasticsearch/logs/e100024741.log org.apache.logging.log4j.core.appender.AppenderLoggingException: Error writing to stream....
由于节点已经跑了很长时间,log盘写满也是有可能的,而且不太可能瞬间拉高CPU,暂时忽略。
8.进一步验证,将异常节点重启。
果然异常节点CPU下去了,另一个节点CPU起来了,进一步证明了是查询导致的,1主1副的case下,一个节点挂了,另一个承载流量。
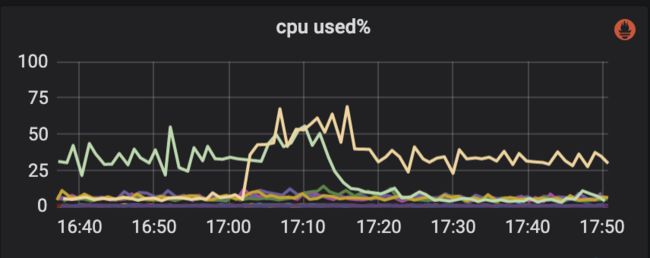
继续观察异常节点的流量:outgoing的流量比较高,又进一步佐证了是查询带来的异常。
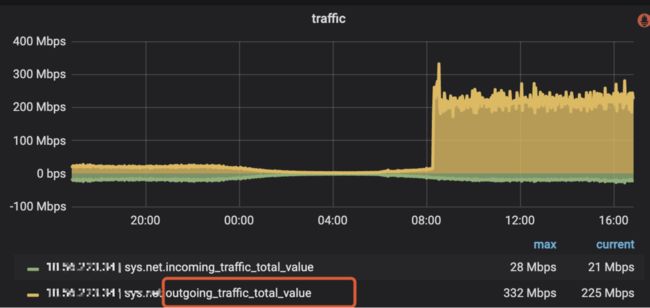
继续查看IO,write/read都相对比较高。
9.考虑到查询无法被阻断、且该节点异常带来的影响并不大,准备等“拉数据的大请求”执行完毕自动恢复。
10.开始关注其他问题。等待一段时间,发现依然没有恢复,且CPU完全没有下降的趋势。考虑到一个大请求不会执行这么长时间,如果多个大请求,至少reject、cpu曲线会有些波动,不会如此稳定。准备继续排查。再次执行多次hot_thread API,依然有很多次都只抓到了write线程占用大量CPU,如果大请求存在,不会一直抓不到search请求。
11.考虑其他思路。找到重启前异常节点和重启异常节点后才异常的节点共有的index(互为主备),在众多index中发现了一个较大的index(800G)。看了下文档数:2147483519,至此,找到了问题的答案。
12.结论:使用了同一template的大量索引(1 primary 1 replica),存在一个index写了大量doc数,超过了lucene的最大限制(integer的最大值),疯狂报错reject,并且记录大量异常日志,日志不断的rotate、清理造成了CPU的大幅上升。
仔细检查异常开始时间节点的日志,可以发现如下异常信息:
[2022-07-22T12:00:36,376][DEBUG][o.e.a.b.TransportShardBulkAction] [e100024741-es-default-1][cp0006014_2022_07][0] failed to execute bulk item (index) index {[cp0006014_2022_07][event_cp][Ir_HJYIBi3-VIQ2V8GIT], source[{"rowkey":"fff5e48f-13d9-4f68-b9c9-8cfc1f0fefa3","column01":"BatchValidateRecevieCouponRealTime","column02":"1","column03":"289358095","column04":"100009826","column05":"nkryj","column06":"32001052810269459246","column08":"fff5e48f-13d9-4f68-b9c9-8cfc1f0fefa3","column09":"[34m~L[34m~A34m~O~Q34m~H[34m~D34m| "column11":"2022-07-22 20:00:29.703","column12":"1","column20":"0","datachangelasttime":1658491229707,"rules":[],"rulesh":[],"scenes":[]}]}
java.lang.IllegalArgumentException: number of documents in the index cannot exceed 2147483519
at org.apache.lucene.index.DocumentsWriterPerThread.reserveOneDoc(DocumentsWriterPerThread.java:226) ~[lucene-core-7.7.2.jar:7.7.2 d4c30fc2856154f2c1fefc589eb7cd070a415b94 - janhoy - 2019-05-28 23:30:25]
at org.apache.lucene.index.DocumentsWriterPerThread.updateDocument(DocumentsWriterPerThread.java:235) ~[lucene-core-7.7.2.jar:7.7.2 d4c30fc2856154f2c1fefc589eb7cd070a415b94 - janhoy - 2019-05-28 23:30:25]
at org.apache.lucene.index.DocumentsWriter.updateDocument(DocumentsWriter.java:494) ~[lucene-core-7.7.2.jar:7.7.2 d4c30fc2856154f2c1fefc589eb7cd070a415b94 - janhoy - 2019-05-28 23:30:25]
at org.apache.lucene.index.IndexWriter.updateDocument(IndexWriter.java:1616) ~[lucene-core-7.7.2.jar:7.7.2 d4c30fc2856154f2c1fefc589eb7cd070a415b94 - janhoy - 2019-05-28 23:30:25]
at org.apache.lucene.index.IndexWriter.addDocument(IndexWriter.java:1235) ~[lucene-core-7.7.2.jar:7.7.2 d4c30fc2856154f2c1fefc589eb7cd070a415b94 - janhoy - 2019-05-28 23:30:25]
at org.elasticsearch.index.engine.InternalEngine.addDocs(InternalEngine.java:1175) ~[elasticsearch-6.8.5.jar:6.8.5]
at org.elasticsearch.index.engine.InternalEngine.indexIntoLucene(InternalEngine.java:1120) ~[elasticsearch-6.8.5.jar:6.8.5]
进一步验证:进入容器清理日志文件,会立刻生成并rotate出多个日志文件。
最终处理:清理掉异常索引立刻恢复正常:
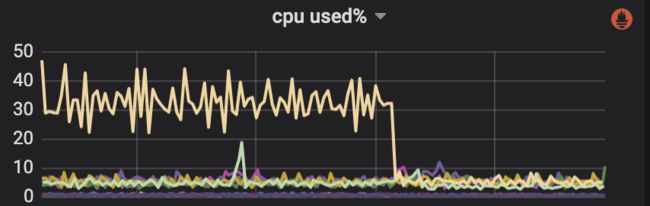
解释前面的坑
1.arthas采集2min内的CPU信息,得到的search结论是正确的,该集群确实存在search大请求。虽然频率不高,但是采集到的概率很大。

2.异常节点的out流量很大。这个逻辑也是正确的,只是并不是导致异常的根本原因。
确实有拉数据的请求存在;节点存在大量索引的分片,无法确认流量来源是否是其他index;该异常情况下用户收到异常ack之后会有重试,影响到流量的统计。

3.重启后另一个节点CPU就开始激增,是因为副本分片成为了主分片,然后开始reject,并疯狂打印日志、进行rotate和清理。
4.为什么只有一个节点CPU高。写入流程是主分片写入成功后,异步转发请求给所有副本(此处只有1),由于主分片写入失败,直接异常,副本也就不会受到影响。
思考
1.经验流大多情况有效,有时却不可取。时刻根据事实排障,避免先入为主。
2.相似的现象以及采集排障数据的巧合进入思维误区,集群业务复杂度增加了排障难度:
大量的日志难以查找(被AppenderLoggingException淹没),且都被判定为和本次异常无关,如 bulk reject 被认为是CPU高的场景下正常的表现,AppenderLoggingException 被认为无法快速消耗CPU,number of documents in the index cannot exceed 2147483519 刚看到时也被认为无法导致CPU增高(仅仅是无法写入);
index太多,无法从单个index层面获取更多信息。(没有明确目标的情况下难以发现那一个异常index)。
3.arthas write线程的堆栈信息中有体现,bulk之后就在打印日志,这两点之间的关联被忽略。
4.优化方向:需要更细粒度的监控和巡检能力,快速发现异常index可大大加快排障进程,不再强依赖OPS的知识体系与推理。