CPU 伪共享是如何发生的?又该如何避免?
CPU 如何读写数据的?
先来认识一下 CPU 的架构
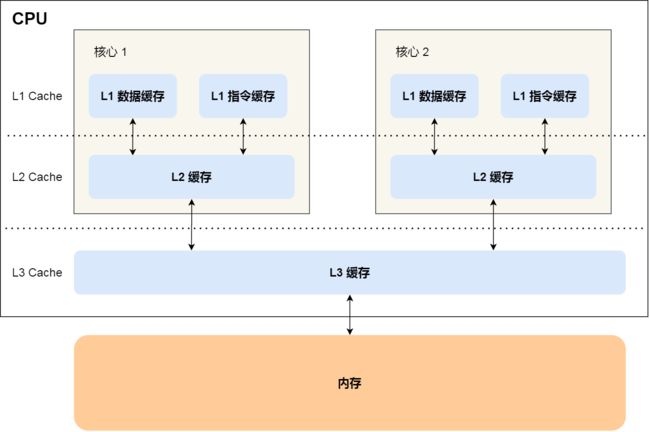
一个 CPU 里通常会有多个 CPU 核心,并且每个 CPU 核心都有自己的 L1 Cache 和 L2 Cache,而 L1 Cache 通常分为(数据缓存)和(指令缓存),L3 Cache 则是多个核心共享的,这就是 CPU 典型的缓存层次。
上面提到的都是 CPU 内部的 Cache,放眼外部的话,还会有内存和硬盘,这些存储设备共同构成了金字塔存储层次。如下图所示:
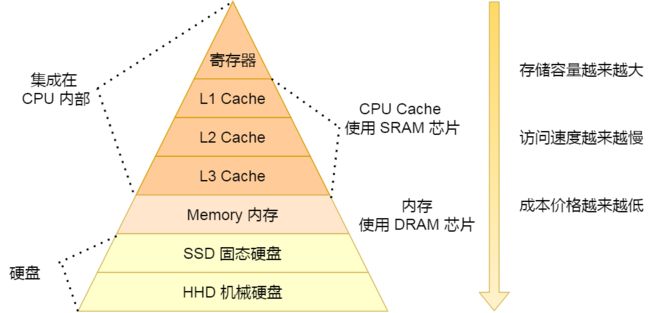
从上图也可以看到,从上往下,存储设备的容量会越大,而访问速度会越慢。
CPU 访问 L1 Cache 速度比访问内存快 100 倍,这就是为什么 CPU 里会有 L1~L3 Cache 的原因,目的就是把 Cache 作为 CPU 与内存之间的缓存层,以减少对内存的访问频率。
CPU 从内存中读取数据到 Cache 的时候,并不是一个字节一个字节读取,而是一块一块的方式来读取数据的,这一块一块的数据被称为 CPU Cache Line(缓存块),所以 CPU Cache Line 是 CPU 从内存读取数据到 Cache 的单位。
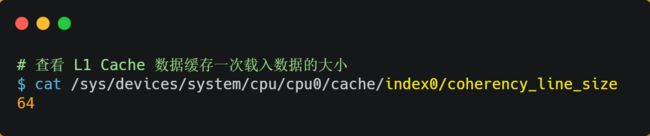
至于 CPU Cache Line 大小,在 Linux 系统可以用下面的方式查看到,你可以看我服务器的 L1 Cache Line 大小是 64 字节,也就意味着 L1 Cache 一次载入数据的大小是 64 字节。
那么对数组的加载, CPU 就会加载数组里面连续的多个数据到 Cache 里,因此我们应该按照物理内存地址分布的顺序去访问元素,这样访问数组元素的时候,Cache 命中率就会很高,于是就能减少从内存读取数据的频率, 从而可提高程序的性能。
但是,在我们不使用数组,而是使用单独的变量的时候,则会有 Cache 伪共享的问题,Cache 伪共享问题上是一个性能杀手,我们应该要规避它。
接下来,就来看看 Cache 伪共享是什么?又如何避免这个问题?
Cache 伪共享
现在假设有一个双核心的 CPU,这两个 CPU 核心并行运行着两个不同的线程,它们同时从内存中读取两个不同的数据,分别是类型为 long 的变量 A 和 B,这个两个数据的地址在物理内存上是连续的,如果 Cahce Line 的大小是 64 字节,并且变量 A 在 Cahce Line 的开头位置,那么这两个数据是位于同一个 Cache Line 中,又因为 CPU Cache Line 是 CPU 从内存读取数据到 Cache 的单位,所以这两个数据会被同时读入到了两个 CPU 核心中各自 Cache 中。
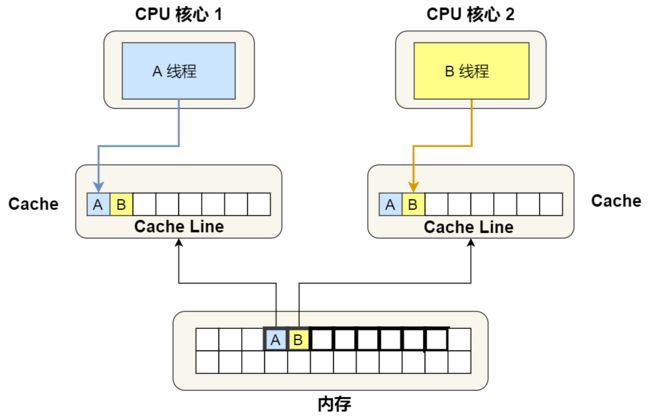
我们来思考一个问题,如果这两个不同核心的线程分别修改不同的数据,比如 1 号 CPU 核心的线程只修改了 变量 A,或 2 号 CPU 核心的线程的线程只修改了变量 B,会发生什么呢?
分析伪共享的问题
现在我们结合保证多核缓存一致的 MESI 协议,来说明这一整个的过程。
最开始变量 A 和 B 都还不在 Cache 里面,假设 1 号核心绑定了线程 A,2 号核心绑定了线程 B,线程 A 只会读写变量 A,线程 B 只会读写变量 B。
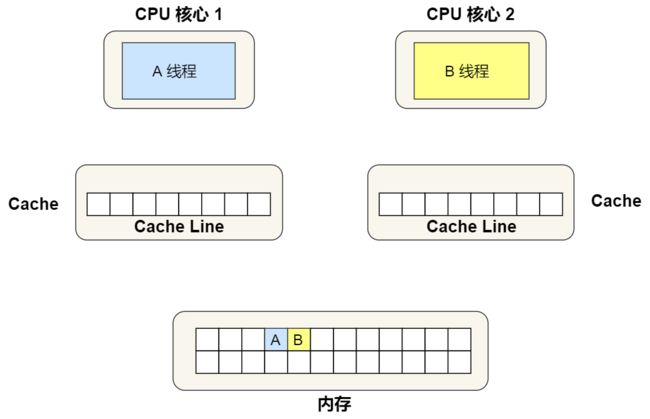
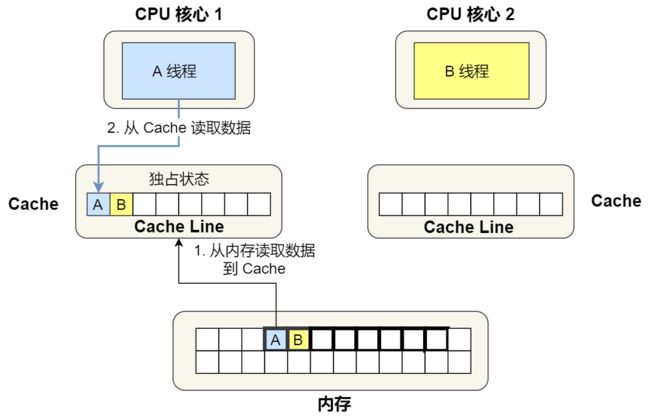
1 号核心读取变量 A,由于 CPU 从内存读取数据到 Cache 的单位是 Cache Line,也正好变量 A 和 变量 B 的数据归属于同一个 Cache Line,所以 A 和 B 的数据都会被加载到 Cache,并将此 Cache Line 标记为「独占」状态。
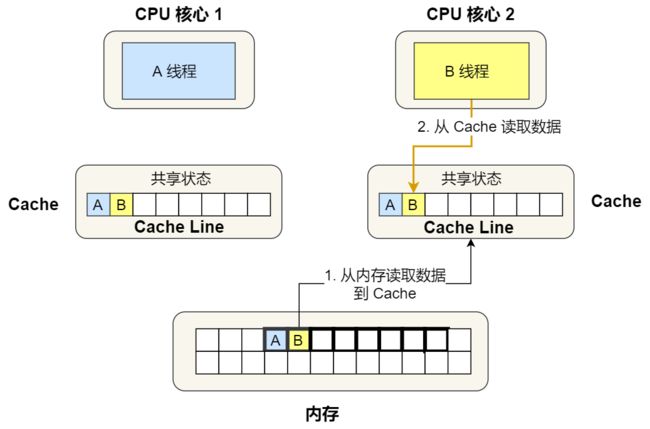
接着,2 号核心开始从内存里读取变量 B,同样的也是读取 Cache Line 大小的数据到 Cache 中,此 Cache Line 中的数据也包含了变量 A 和 变量 B,此时 1 号和 2 号核心的 Cache Line 状态变为「共享」状态。
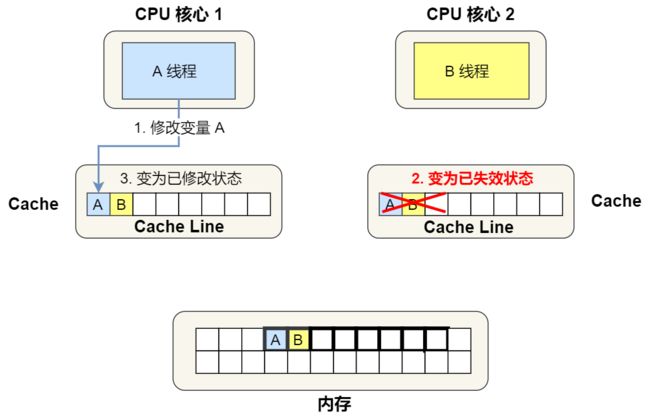
1 号核心需要修改变量 A,发现此 Cache Line 的状态是「共享」状态,所以先需要通过总线发送消息给 2 号核心,通知 2 号核心把 Cache 中对应的 Cache Line 标记为「已失效」状态,然后 1 号核心对应的 Cache Line 状态变成「已修改」状态,并且修改变量 A。
之后,2 号核心需要修改变量 B,此时 2 号核心的 Cache 中对应的 Cache Line 是已失效状态,另外由于 1 号核心的 Cache 也有此相同的数据,且状态为「已修改」状态,所以要先把 1 号核心的 Cache 对应的 Cache Line 写回到内存,然后 2 号核心再从内存读取 Cache Line 大小的数据到 Cache 中,最后把变量 B 修改到 2 号核心的 Cache 中,并将状态标记为「已修改」状态。
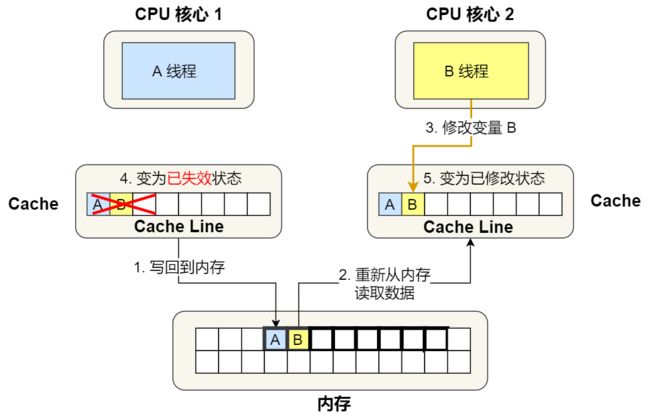
所以,可以发现如果 1 号和 2 号 CPU 核心这样持续交替的分别修改变量 A 和 B,就会重复 ④ 和 ⑤ 这两个步骤,Cache 并没有起到缓存的效果,虽然变量 A 和 B 之间其实并没有任何的关系,但是因为同时归属于一个 Cache Line ,这个 Cache Line 中的任意数据被修改后,都会相互影响,从而出现 ④ 和 ⑤ 这两个步骤。
因此,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
如何避免
举个栗子
public class FalseSharingTest {
public static void main(String[] args) throws InterruptedException {
testPointer(new Pointer());
}
private static void testPointer(Pointer pointer) throws InterruptedException {
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
pointer.x++;
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
pointer.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(System.currentTimeMillis() - start);
System.out.println(pointer);
}
}
class Pointer {
volatile long x;
volatile long y;
}上面这个例子,我们声明了一个Pointer的类,它包含了x和y两个变量(必须声明为volatile,保证可见性),一个线程对x进行自增1亿次,一个线程对y进行自增1亿次。
可以看到,x和y完全没有任何关系,但是更新x的时候会把其它包含x的缓存行失效,同时y也就失效了,运行这段程序输出的时间为3890ms。
伪共享的原理我们知道了,一个缓存行是64字节,一个long类型是8个字节,所以避免伪共享也很简单,大概有以下三种方式:
(1)在两个long类型的变量之间再加7个long类型
我们把上面的pointer改成下面这个结构
class Pointer {
volatile long x;
long p1, p2, p3, p4, p5, p6, p7;
volatile long y;
}再次运行程序,会发现输出时间神奇的缩短为695ms
(2)重新创建自己的long类型,而不是java自带的long修改Pointer如下
class Pointer {
MyLong x = new MyLong();
MyLong y = new MyLong();
}
class MyLong {
volatile long value;
long p1, p2, p3, p4, p5, p6, p7;
}同时把pointer.x++改为pointer.x.value++;等,再次运行程序发现时间是724ms,这样本质上还是填充。所以,避免 Cache 伪共享实际上是用空间换时间的思想,浪费一部分 Cache 空间,从而换来性能的提升。
(3)使用@sun.misc.Contended注解(java8)
修改MyLong如下:
@sun.misc.Contended
class MyLong {
volatile long value;
}默认使用这个注解是无效的,需要在JVM启动参数加上-XX:-RestrictContended才会生效,再次运行程序发现时间是718ms。注意,以上三种方式中的前两种是通过加字段的形式实现的,加的字段又没有地方使用,可能会被jvm优化掉,所以建议使用第三种方式。
Java 并发框架 Disruptor 使用「字节填充 + 继承」的方式,来避免伪共享的问题。感兴趣的同学可以自己去学习了解一下。