复活这个失效的文库下载神器,从此告别VIP
写在前面
当你在网上冲浪,想着搜索资源,或者说想要下载一个文档的时候。在点击下载的时候,是不是经常遇到下面的情况(可恶的拦路虎)
道客巴巴

百度文库

这两个主流的资料库都是这样的,大部分内容下载都需要VIP,有一些甚至要VIP才能查看全文。这对于一心只想白嫖的我来说,真的是难以忍受。

可恶,难道就没有什么办法了吗?()。想着想着,一个已经“死了”的百度文库下载神器——文库下载器BY小叶。但是这一个下载器由于作者遭到了许多的指责与谩骂。主要就是有部分人利用这一个来谋取私利,甚至在某宝上面都有售卖。作者因此最后也自己限制了这个工具的使用。
关于文库下载器(by 小叶)
此文库下载器下载器在某一时间段,真的是白嫖党的福音。简洁又好用,关键是全部免费,让你告别VIP,畅享百度文库。打开后是这个样子(下图)

虽然说看着有一点点花哨,但是十分简洁好用的。但是,有一个坏消息,如果打开后还是这个样子的话,那也就没有这篇文章了。现在打开的话,应该是这个样子的

会弹出一个强制更新的提示。点进确定后,看到的将会是作者已经注销的博客,里面留下的声明写满了无奈。

谈谈原理
这些下载器是一般大体上分两种方法实现下载功能,一种是解析文库站的代码,然后破除前端限制,再下载文档内容;一种则是边截图,边 OCR 识别,最后整合到一起。但是这两种方法只能在可以预览全文的情况下下载全部内容。当遇到下面的情况

下载器也无能为力啦。但这种也能满足我们大部分需要了。话不多说,我来说说如何复活这个下载器!
复活篇
文库下载器:click
首先我们要明确我们的目标,这个下载器的问题前面也说了,不是不能下,而是有那个更新的弹窗。我们只要阻止向这个网页跳转就行了。现在我介绍两种方法。
一 断网法
这个方法很直截了当,每次进入前,断掉网络连接即可。这个方法,虽然简单有效,但是每次进入都要进行这样的操作,是不是有点麻烦呢。对于我来说,还是挺麻烦的。那有没有一种一劳永逸的方法呢。答案是肯定的。

二 host重定向
在具体说这个方法之前,我想先给大家科普一下,关于host重定向的一些知识作为准备。
①什么是host重定向?
Host重定向是一种网络服务器技术,它可以将一个域名或主机名重定向到另一个域名或主机名。
②host重定向的作用?
网站跳转:如果一个网站更改了其域名或主机名,它可以使用Host重定向将旧的域名或主机名重定向到新的域名或主机名,以确保访问者可以访问到正确的网站。
负载均衡:当一个服务器无法处理大量的请求时,可以使用Host重定向将请求重定向到其他服务器上,以均衡服务器的负载。
安全性:可以使用Host重定向防止黑客攻击,例如防止DNS欺骗攻击等。
SEO:Host重定向可以帮助网站提高搜索引擎优化(SEO)排名。当一个网站更改其域名或主机名时,如果没有正确设置重定向,搜索引擎可能会将网站的排名降低。通过正确设置Host重定向,可以确保搜索引擎将旧的网址与新的网址关联起来,从而维护网站的排名。
③为什么可以使用hosts文档屏蔽网站?
使用hosts文档屏蔽网站的原理是通过修改计算机的hosts文件来阻止计算机访问特定的网站。hosts文件是一个文本文件,其中包含计算机上所有已知的域名和IP地址的映射关系。当用户输入一个网址时,计算机会首先查找hosts文件中是否有该网址对应的IP地址,如果找到了,则直接使用该IP地址访问网站,否则就通过DNS服务器查找该网址对应的IP地址。
因此,如果将特定网站的域名或IP地址添加到hosts文件中,并将其指向一个不存在的IP地址(0.0.0.0)或者本地地址,那么当用户尝试访问这些网站时,计算机会尝试使用hosts文件中的IP地址来访问网站,但由于该IP地址不存在,访问请求会失败,从而实现了屏蔽网站的目的。
④关于hosts文件的tips
使用hosts文件屏蔽网站只能防止从本机访问该网站,而不能防止其他计算机或设备访问该网站。此外,使用hosts文件屏蔽网站可能会影响某些应用程序的正常工作,因此需要谨慎使用。
此外,hosts文件还可以用于过滤广告和追踪器。通过将广告和追踪器的域名添加到hosts文件中,并将其指向一个不存在的IP地址或者本地地址,可以阻止它们在计算机上加载和运行,从而提高浏览器的速度和安全性。
总之,使用hosts文档屏蔽网站可以有效地保护计算机和用户的安全,并提高浏览器的速度和安全性。
前面提到了关于不存在的IP(0.0.0.0),这里也做一下介绍
⑤关于0.0.0.0保留IP
0.0.0.0是一个保留的IP地址,它通常被用作默认路由器地址或表示“任何地址”的通配符地址。在hosts文件中,将一个网站的IP地址指向0.0.0.0,意味着将该网站的访问请求转发到一个不存在的IP地址,从而使得该网站无法访问。
虽然0.0.0.0在实际网络中并不代表一个具体的主机或设备,但它确实是一个有效的IP地址,且被广泛应用在网络中。在某些情况下,0.0.0.0也可以表示一个本地主机或设备的IP地址,例如在某些路由器或防火墙的配置中。
需要注意的是,将一个网站的IP地址指向0.0.0.0并不能完全屏蔽该网站,因为某些浏览器或应用程序可能会尝试使用该网站的域名进行访问。因此,如果想要完全屏蔽一个网站,最好将其域名和IP地址都添加到hosts文件中,并将其指向一个不存在的IP地址或者本地地址。
好了,补充知识点讲完了。现在我们正式开始操作复活这个文库下载器。
操作
将一个网站的域名和IP地址添加到hosts文件中,可以按照以下步骤进行操作:
1. 打开文本编辑器(例如记事本)。
2. 打开hosts文件。hosts文件通常位于C:\Windows\System32\drivers\etc\目录下,可以使用管理员权限打开文本编辑器,再使用“打开”菜单选择该文件。
3. 在hosts文件的末尾添加一行,格式为“IP地址 域名”,例如:192.168.1.100 www.example.com。如果你想屏蔽整个域名,可以使用通配符,例如:0.0.0.0 *.example.com。
对于这个文库下载器,按如图操作即可。
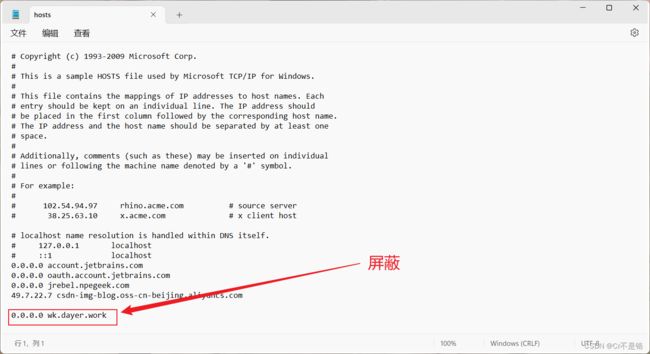
4. 保存hosts文件,关闭文本编辑器。
5. 刷新DNS缓存。打开命令提示符窗口,输入“ipconfig /flushdns”命令,以刷新DNS缓存,使得修改后的hosts文件生效。
需要注意的是,对于Windows操作系统,修改hosts文件需要使用管理员权限,否则无法保存修改后的文件。此外,如果你想取消对一个网站的屏蔽,只需要将该网站的域名和IP地址从hosts文件中删除即可。
补充:
小叶文库下载器,可以免费下载包括百度文库,智库等一系列里面的资源(非常实用)。但是,对于道客巴巴却无能为力。但是不必过于担心,我这里提供一个Python源码,专门针对道客巴巴进行资源获取。
from selenium import webdriver
import os
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from lxml import etree
chromeOptions = webdriver.ChromeOptions()
path=os.getcwd()+'\data'
options = Options()
#判断文件夹是否存在,不存在创建文件夹
is_exists = os.path.exists(path)
if not is_exists:
os.mkdir(path)
#指定浏览器下载文件夹
prefs = {"download.default_directory": path}
options.add_experimental_option("prefs", prefs)
browser = webdriver.Chrome(chrome_options=options)
#指定网页链接
url='https://www.doc88.com/p-41899289232878.html'
# browser.get('https://www.doc88.com/p-5969904068700.html') #论文
browser.get(url)
#网页源代码
text=browser.page_source
html=etree.HTML(text)
page_num=html.xpath("//li[@class='text']/text()")[0]
#获取总页码数
page_num=int(page_num.replace('/ ',''))
print(f'共{page_num}页')
print(EC.visibility_of_element_located((By.XPATH, "//div[@id='continueButton']")))
# #等待网页加载
time.sleep(10)
#等待按钮
element=WebDriverWait(browser, 20).until(EC.visibility_of_element_located((By.XPATH, "//div[@id='continueButton']")))
element.click()
# browser.find_element_by_xpath("//div[@id='continueButton']").click()
js = "return action=document.body.scrollHeight"
# 初始化现在滚动条所在高度为0
height = 0
# 当前窗口总高度
new_height = browser.execute_script(js)
k=0
while k<=page_num:
for i in range(height, new_height, 3000):
k+=1
browser.execute_script('window.scrollTo(0, {})'.format(i))
time.sleep(1)
a = f"downloadPages({k}, {k})"
# 中间需要手动点一下运行下载多个文件
browser.execute_script("""function downloadPages(from, to) {
for (i = from; i <= to; i++) {
const pageCanvas = document.getElementById('page_' + i);
if (pageCanvas === null) break;
pageNo_ = i >= 10 ? ''+i:'0'+i;
const pageNo = pageNo_;
pageCanvas.toBlob(
blob => {
const anchor = document.createElement('a');
anchor.download = 'page_' + pageNo + '.png';
anchor.href = URL.createObjectURL(blob);
anchor.click();
URL.revokeObjectURL(anchor.href);
}
//, 'image/jpeg' // (*)
//, 0.9 // (*)
);
}
};
""" + a)希望本文对你有所帮助!