【AI】机器学习——线性模型(线性回归)
线性模型既能体现出重要的基本思想,又能构造出功能更加强大的非线性模型
文章目录
-
- 3.1 线性模型
-
- 3.1.1 数据
- 3.1.2 目标/应用
- 3.2 线性回归
-
- 3.2.1 回归模型历史
- 3.2.2 回归分析研究内容
-
- 回归分析步骤
- 3.2.3 回归分析分类
- 3.2.4 回归模型
- 3.2.5 损失函数
-
- 梯度下降法
-
- 一元回归模型的梯度下降
- 多元回归模型梯度下降
- 不同特征尺度不同,需归一化
- 牛顿法求方程的解
- 局限性
- 最小二乘法
-
- 直线距离与垂直距离关系
- 一元回归模型LMS
- 多元回归模型LMS
- GD与LMS对比
- 多角度理解LMS
-
- 几何角度
- 线性组合
- 矩阵角度
- 概率角度
- 3.2.6 回归方程衡量标准
-
- 回归方程的拟合优度
- 判定系数
- 3.2.7 显著性检验
-
- 线性关系检验
- 回归系数检验
- 线性关系检验与回归系数检验区别:
- 3.2.8 利用回归直线进行估计和预测
-
- 预测结果的置信度
-
- 标准差
- 置信区间估计
-
- 置信区间宽度影响因素
- 3.2.9 多元线性回归问题
-
- 曲线回归分析过程
- 多重共线性
- 过拟合问题
-
- 岭回归
- LASSO回归
- 岭回归与LASSO回归概率角度
线性模型假设输出变量是若干输入变量的线性组合,并根据这一关系求解线性组合的最优系数
最小二乘法可用于解决单变量线性回归问题,当误差函数服从正态分布时,与最大似然估计等价
多元回归问题也可以用最小二乘法求解,但极易出现过拟合线性
- 岭回归,引入二范数惩罚项
- LASSO回归,引入一范数项
3.1 线性模型
3.1.1 数据
D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n ) } 其中, x i ∈ R n , y i ∈ R ,即训练数据集 D 中有 n 个数据,一个数据有 n 个特征 D=\{(x_1,y_1),(x_2,y_2),\cdots,(x_n,y_n)\}\\ 其中,x_i\in R^n,y_i\in R,即训练数据集D中有n个数据,一个数据有n个特征 D={(x1,y1),(x2,y2),⋯,(xn,yn)}其中,xi∈Rn,yi∈R,即训练数据集D中有n个数据,一个数据有n个特征
3.1.2 目标/应用

- 线性回归——线性拟合
- 线性分类
3.2 线性回归
线性回归假设输出变量是若干输入变量的线性组合,并根据这一关系求解线性组合中的最优系数
- 线性回归模型最易于拟合,其估计结果的统计特性也更容易确定
- 在机器学习中,回归问题隐含了输入变量与输出变量均可连续取指的前提,因而利用线性回归模型可以对任意输入给出输出的估计
3.2.1 回归模型历史
1875年,从事遗传问题研究的英国统计学家弗朗西斯·高尔顿正在寻找子代与父代身高之间的关系。
他发现数据散点图大致呈直线状态(父代身高与子代身高呈正相关关系)
高尔顿将这种现象称为 回归效应 ,即大自然将人类身高的分布约束在相对稳定并不产生两极分化的整体水平,并给出了历史上第一个线性回归的表达式: y = 0.516 x + 33.73 y=0.516x+33.73 y=0.516x+33.73
3.2.2 回归分析研究内容
相关性分析:分析变量之间是否具有相关性
回归分析:寻找存在相关关系的变量间的数学表达式
回归分析步骤
- 确定回归方程中的自变量和因变量
- 确定回归模型(建立方程)
- 对回归方程进行检验
- 利用回归方程进行预测
3.2.3 回归分析分类
- 根据自变量数目,可以分类一元回归(一个特征决定结果),多元回归(多个特征决定结果)
- 根据自变量与因变量之间的表现形式,分为线性与非线性
具体分为四个方向:一元线性回归 、多元线性回归 、一元非线性回归 、多元线性回归
3.2.4 回归模型
训练数据集:
D = { ( x 1 , y 1 ) , ⋯ , ( x i , y i ) , ⋯ , ( x n , y n ) } , i = 1 , 2 , ⋯ , n D=\{(x_1,y_1),\cdots,(x_i,y_i),\cdots,(x_n,y_n)\},i=1,2,\cdots,n D={(x1,y1),⋯,(xi,yi),⋯,(xn,yn)},i=1,2,⋯,n
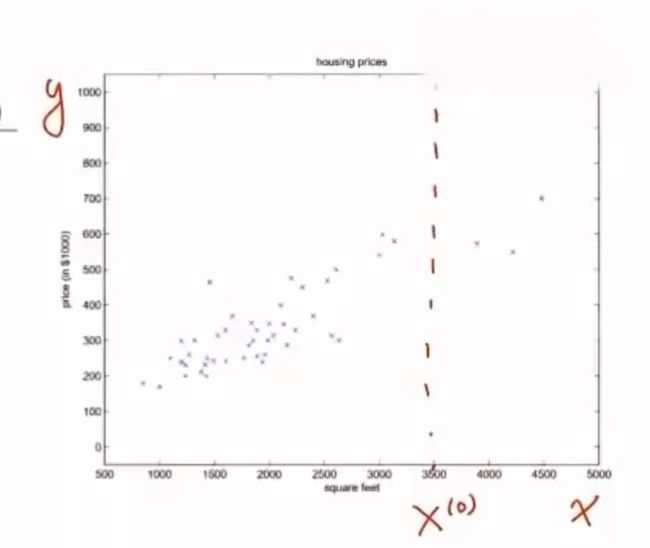
假设有线性函数 y ω ( x ) = ω T x → y y_{\omega}(x)=\omega^Tx\rightarrow y yω(x)=ωTx→y
y ω ( x i ) = ω T x i , i = 1 , 2 , ⋯ , n ω = ( b ω 1 ⋮ ω j ⋮ ω m ) ∈ R m , x i = ( 1 x i ( 1 ) ⋮ x i ( j ) ⋮ x i ( m ) ) ∈ X ∈ R m , j = 1 , 2 , ⋯ , m y_{\omega}(x_i)=\omega^T x_i\quad ,i=1,2,\cdots,n\\ \omega=\left(\begin{aligned}b\\\omega_1\\\vdots\\\omega_j\\\vdots\\\omega_m\end{aligned}\right)\in R^m,x_i= \left(\begin{aligned}1\\x_i^{(1)}\\\vdots\\x_i^{(j)}\\ \vdots\\x_i^{(m)}\end{aligned}\right)\in \mathcal{X}\in R^m\quad ,j=1,2,\cdots,m yω(xi)=ωTxi,i=1,2,⋯,nω= bω1⋮ωj⋮ωm ∈Rm,xi= 1xi(1)⋮xi(j)⋮xi(m) ∈X∈Rm,j=1,2,⋯,m
x i x_i xi 表示第 i i i 个样本, x i ( j ) x_i^{(j)} xi(j) 表示第 i i i 个样本的第 j j j 个特征值, ω j \omega_j ωj 理解为每个特征的相对权重
- 线性回归的作用就是习得一组参数 w i , i = 0 , 1 , ⋯ , n w_i,i=0,1,\cdots,n wi,i=0,1,⋯,n ,使预测输出可以表示为以这组参数为权重的实例属性的线性组合
模型
- 当实例只有一个属性时,输入和输出之间的关系就是二维平面上的一条直线
- 当实例有 n n n 个属性时,输入和输出之间的关系就是 n + 1 n+1 n+1 维空间上的一个超平面,对应一个维度为 n n n 的线性子空间
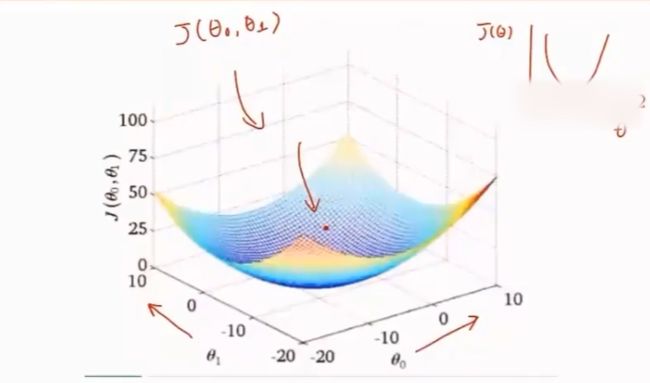
3.2.5 损失函数
J ( ω ) J(\omega) J(ω) 为线性模型的损失函数,通过调整参数 ω \omega ω ,使得 J ( ω ) J(\omega) J(ω) 最小
y ω ( x i ) y_{\omega}(x_i) yω(xi) 与 y i y_i yi 之间有差异,用 y ω ( x i ) − y i y_{\omega}(x_i)-y_i yω(xi)−yi 表示这种差异。模型在训练数据集上的整体误差为 ∑ i = 1 n [ y ω ( x i ) − y i ] = ∑ i = 1 n [ y ^ i − y i ] = Y ^ − Y \sum\limits_{i=1}^n[y_{\omega}(x_i)-y_i]=\sum\limits_{i=1}^n[\hat{y}_i-y_i]=\hat{Y}-Y i=1∑n[yω(xi)−yi]=i=1∑n[y^i−yi]=Y^−Y
一般用最小二乘法优化损失,便于计算,即
J ( ω ) = 1 2 n ∑ i = 1 n ( y ω ( x i ) − y i ) 2 J(\omega)=\frac{1}{2n}\sum\limits_{i=1}^n \left(y_{\omega}(x_i)-y_i\right)^2 J(ω)=2n1i=1∑n(yω(xi)−yi)2
对于参数 ω \omega ω 的不同取值,损失函数有大有小。可通过对损失函数 J ( ω ) J(\omega) J(ω) 最优化,找到损失函数最小的参数值 ω \omega ω
梯度下降法
最优化问题为 min ω J ( ω ) = 1 2 n ∑ i = 1 n ( y ω ( x i ) − y i ) 2 \min\limits_{\omega}J(\omega)=\frac{1}{2n}\sum\limits_{i=1}^n \left(y_{\omega}(x_i)-y_i\right)^2 ωminJ(ω)=2n1i=1∑n(yω(xi)−yi)2


梯度控制方向
-
方向对于梯度下降问题影响较大,步长只决定在梯度方向上移动的距离
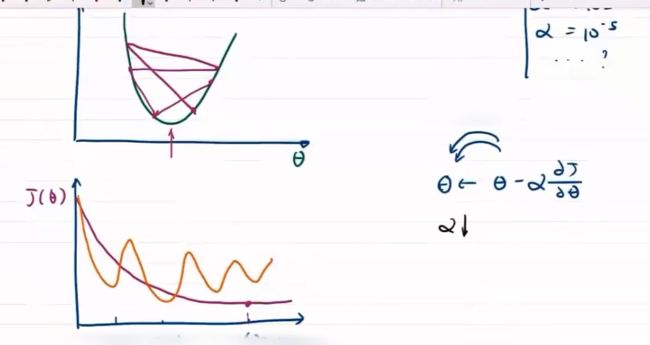
步长大,出现振荡

步长小,收敛慢
一元回归模型的梯度下降
y ω = ω 1 x + ω 0 y_{\omega}=\omega_1x+\omega_0 yω=ω1x+ω0
{ ω 0 [ t ] ← ω 0 [ t − 1 ] − α ∂ J ( ω ) ∂ ω 0 ω 1 [ t ] ← ω 1 [ t − 1 ] − α ∂ J ( ω ) ∂ ω 1 \begin{cases} \omega_0^{[t]}\leftarrow \omega_0^{[t-1]}-\alpha\frac{\partial J(\omega)}{\partial \omega_0}\\ \omega_1^{[t]}\leftarrow \omega_1^{[t-1]}-\alpha\frac{\partial J(\omega)}{\partial \omega_1}\\ \end{cases} {ω0[t]←ω0[t−1]−α∂ω0∂J(ω)ω1[t]←ω1[t−1]−α∂ω1∂J(ω)
代入线性回归模型损失函数
∂ J ( ω 1 , ω 0 ) ∂ ω 0 = ∂ ∂ ω 0 [ 1 2 n ∑ i = 1 n ( y ω ( x i ) − y i ) 2 ] = 1 n ∑ i = 1 n ( y ω ( x i ) − y i ) ∂ J ( ω 1 , ω 0 ) ∂ ω 1 = ∂ ∂ ω 1 [ 1 2 n ∑ i = 1 n ( y ω ( x i ) − y i ) 2 ] = 1 n ∑ i = 1 n ( y ω ( x i ) − y i ) x ( 1 ) \begin{aligned} \frac{\partial J(\omega_1,\omega_0)}{\partial \omega_0}&=\frac{\partial{}}{\partial{\omega_0}}\left[\frac{1}{2n}\sum\limits_{i=1}^n \left(y_{\omega}(x_i)-y_i\right)^2\right]\\ &=\frac{1}{n}\sum\limits_{i=1}^n \left(y_{\omega}(x_i)-y_i\right)\\ \frac{\partial J(\omega_1,\omega_0)}{\partial \omega_1}&=\frac{\partial{}}{\partial{\omega_1}}\left[\frac{1}{2n}\sum\limits_{i=1}^n \left(y_{\omega}(x_i)-y_i\right)^2\right]\\ &=\frac{1}{n}\sum\limits_{i=1}^n \left(y_{\omega}(x_i)-y_i\right)x^{(1)}\\ \end{aligned} ∂ω0∂J(ω1,ω0)∂ω1∂J(ω1,ω0)=∂ω0∂[2n1i=1∑n(yω(xi)−yi)2]=n1i=1∑n(yω(xi)−yi)=∂ω1∂[2n1i=1∑n(yω(xi)−yi)2]=n1i=1∑n(yω(xi)−yi)x(1)
多元回归模型梯度下降
一般化梯度下降算法
y ω ( x ) = ω T x = ∑ j = 1 m ω j x ( j ) y_{\omega}(x)=\omega^T x=\sum\limits_{j=1}^m\omega_j x^{(j)} yω(x)=ωTx=j=1∑mωjx(j)
最优化损失函数有
ω 0 [ t ] ← ω 0 [ t − 1 ] − α ∂ J ( ω ) ∂ ω 0 = ω 0 [ t − 1 ] − α 1 n ∑ i = 1 n ( y ω ( x i ) − y i ) ω j [ t ] ← ω j [ t − 1 ] − α ∂ J ( ω ) ∂ ω j = ω j [ t − 1 ] − α 1 n ∑ i = 1 n ( y ω ( x i ) − y i ) x ( j ) \omega_0^{[t]}\leftarrow \omega_0^{[t-1]}-\alpha \frac{\partial J(\omega)}{\partial\omega_0}=\omega_0^{[t-1]}-\alpha \frac{1}{n}\sum\limits_{i=1}^n \left(y_{\omega}(x_i)-y_i\right)\\ \omega_j^{[t]}\leftarrow\omega_j^{[t-1]}-\alpha \frac{\partial J(\omega)}{\partial\omega_j}=\omega_j^{[t-1]}-\alpha\frac{1}{n}\sum\limits_{i=1}^n \left(y_{\omega}(x_i)-y_i\right)x^{(j)} ω0[t]←ω0[t−1]−α∂ω0∂J(ω)=ω0[t−1]−αn1i=1∑n(yω(xi)−yi)ωj[t]←ωj[t−1]−α∂ωj∂J(ω)=ωj[t−1]−αn1i=1∑n(yω(xi)−yi)x(j)
不同特征尺度不同,需归一化
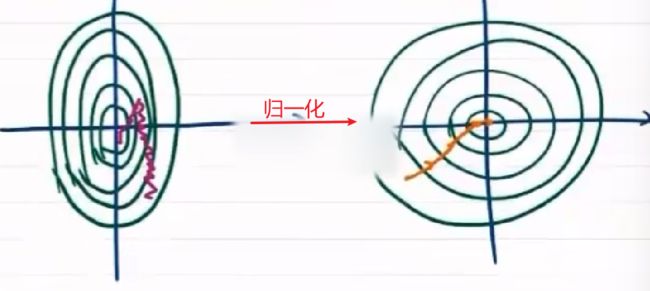
通过归一化,使各特征维度均匀
x ( j ) ← x ( j ) m a x ( x ( j ) ) − m i n ( x ( j ) ) x^{(j)}\leftarrow \frac{x^{(j)}}{max(x^{(j)})-min(x^{(j)})} x(j)←max(x(j))−min(x(j))x(j)
x ( j ) ← x ( j ) − x ‾ m a x ( x ( j ) ) − m i n ( x ( j ) ) x^{(j)}\leftarrow \frac{x^{(j)}-\overline{x}}{max(x^{(j)})-min(x^{(j)})} x(j)←max(x(j))−min(x(j))x(j)−x

牛顿法求方程的解

f ′ ( x 0 ) = f ( x 0 ) Δ x = f ( x 0 ) x 0 − x 1 x 0 − x 1 = f ( x 0 ) f ′ ( x 0 ) x 1 = x 0 − f ( x 0 ) f ′ ( x 0 ) x 2 = x 1 − f ( x 1 ) f ′ ( x 1 ) ⋮ x t = x t − 1 − f ( x t − 1 ) f ′ ( x t − 1 ) f'(x_0)=\frac{f(x_0)}{\Delta x}=\frac{f(x_0)}{x_0-x_1}\\ x_0-x_1=\frac{f(x_0)}{f'(x_0)}\\ x_1=x_0-\frac{f(x_0)}{f'(x_0)}\\ x_2=x_1-\frac{f(x_1)}{f'(x_1)}\\ \vdots\\ x_t=x_{t-1}-\frac{f(x_{t-1})}{f'(x_{t-1})} f′(x0)=Δxf(x0)=x0−x1f(x0)x0−x1=f′(x0)f(x0)x1=x0−f′(x0)f(x0)x2=x1−f′(x1)f(x1)⋮xt=xt−1−f′(xt−1)f(xt−1)
局限性
适用于严格凸函数
可能存在局部最优情况
- 尽量不构造有局部最优的损失函数
- 多采样,给定不同随机值,找到最好的最优点
- 自适应调整步长,跳出局部最优
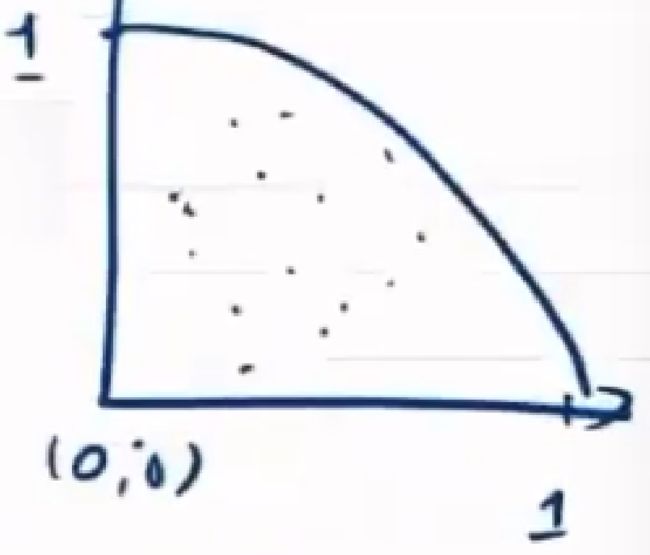
最小二乘法
直线距离与垂直距离关系
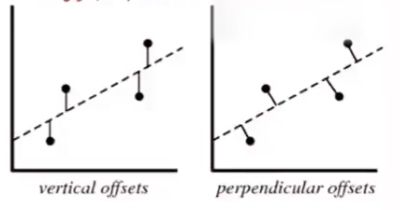
垂直距离 p p p 与竖直距离 v v v ,在斜率为 t a n α = k tan\alpha=k tanα=k 前提下, p = v c o s α p=vcos\alpha p=vcosα
即最小二乘法精确的垂直距离可以用竖直距离代替,即函数值相减
一元回归模型LMS
对于一元回归模型 y ω ( x ) = ω 1 x 1 + ω 0 y_{\omega}(x)=\omega_1x_1+\omega_0 yω(x)=ω1x1+ω0
最小二乘法损失函数 L ( ω 1 , ω 0 ) = 1 2 n ∑ i = 1 n ∥ ω 1 x i ( 1 ) + ω 0 − y i ∥ 2 2 L(\omega_1,\omega_0)=\frac{1}{2n}\sum\limits_{i=1}^n\Vert \omega_1x_i^{(1)}+\omega_0-y_i\Vert^2_2 L(ω1,ω0)=2n1i=1∑n∥ω1xi(1)+ω0−yi∥22
由最优化理论,令 ∂ L ∂ ω 0 = 0 , ∂ L ∂ ω 1 = 0 \frac{\partial L}{\partial \omega_0}=0,\frac{\partial L}{\partial \omega_1}=0 ∂ω0∂L=0,∂ω1∂L=0
∂ L ∂ ω 0 = 1 n ∑ i = 1 n ( ω 1 x i ( 1 ) + ω 0 − y i ) = 0 ⇒ ∑ i = 1 n ω 0 = ∑ i = 1 n ( y i − ω 1 x i ( 1 ) ) ⇒ ω 0 = 1 n ∑ i = 1 n ( y i − ω 1 x i ( 1 ) ) \begin{aligned} \frac{\partial L}{\partial \omega_0}&=\frac{1}{n}\sum\limits_{i=1}^n(\omega_1x_i^{(1)}+\omega_0-y_i)=0\\ &\Rightarrow \sum\limits_{i=1}^n\omega_0=\sum\limits_{i=1}^n(y_i-\omega_1x_i^{(1)})\\ &\Rightarrow \omega_0=\frac{1}{n}\sum\limits_{i=1}^{n}(y_i-\omega_1x_i^{(1)}) \end{aligned} ∂ω0∂L=n1i=1∑n(ω1xi(1)+ω0−yi)=0⇒i=1∑nω0=i=1∑n(yi−ω1xi(1))⇒ω0=n1i=1∑n(yi−ω1xi(1))
∂ L ∂ ω 1 = 1 n ∑ i = 1 n ( ω 1 x i ( 1 ) + ω 0 − y i ) x i ( 1 ) = 0 ⇒ ω 1 ∑ i = 1 n [ x i ( 1 ) ] 2 + ω 0 ∑ i = 1 n x i ( 1 ) − ∑ i = 1 n y i x i ( 1 ) = 0 ⇒ ω 1 ∑ i = 1 n [ x i ( 1 ) ] 2 + 1 n ∑ i = 1 n ( y i − ω 1 x i ( 1 ) ) ∑ i = 1 n x i ( 1 ) − ∑ i = 1 n y i x i ( 1 ) = 0 ⇒ ω 1 { ∑ i = 1 n x i 2 − 1 n ( ∑ i = 1 n x i ) 2 } = ∑ i = 1 n y i ( x i − 1 n ∑ i = 1 n x i ) ⇒ ω 1 = ∑ i = 1 n y i ( x i − 1 n ∑ i = 1 n x i ) ∑ i = 1 n x i 2 − 1 n ( ∑ i = 1 n x i ) 2 \begin{aligned} \frac{\partial L}{\partial \omega_1}&=\frac{1}{n}\sum\limits_{i=1}^n(\omega_1x_i^{(1)}+\omega_0-y_i)x_i^{(1)}=0\\ &\Rightarrow\omega_1\sum\limits_{i=1}^n[x_i^{(1)}]^2+\omega_0\sum\limits_{i=1}^nx_i^{(1)}-\sum\limits_{i=1}^ny_ix_i^{(1)}=0\\ &\Rightarrow \omega_1\sum\limits_{i=1}^n[x_i^{(1)}]^2+\frac{1}{n}\sum\limits_{i=1}^{n}(y_i-\omega_1x_i^{(1)})\sum\limits_{i=1}^nx_i^{(1)}-\sum\limits_{i=1}^ny_ix_i^{(1)}=0\\ &\Rightarrow \omega_1\left\{\sum\limits_{i=1}^nx_i^2-\frac{1}{n}\left(\sum\limits_{i=1}^nx_i\right)^2\right\}=\sum\limits_{i=1}^ny_i(x_i-\frac{1}{n}\sum\limits_{i=1}^nx_i)\\ &\Rightarrow\omega_1=\frac{\sum\limits_{i=1}^ny_i(x_i-\frac{1}{n}\sum\limits_{i=1}^nx_i)}{\sum\limits_{i=1}^nx_i^2-\frac{1}{n}\left(\sum\limits_{i=1}^nx_i\right)^2} \end{aligned} ∂ω1∂L=n1i=1∑n(ω1xi(1)+ω0−yi)xi(1)=0⇒ω1i=1∑n[xi(1)]2+ω0i=1∑nxi(1)−i=1∑nyixi(1)=0⇒ω1i=1∑n[xi(1)]2+n1i=1∑n(yi−ω1xi(1))i=1∑nxi(1)−i=1∑nyixi(1)=0⇒ω1⎩ ⎨ ⎧i=1∑nxi2−n1(i=1∑nxi)2⎭ ⎬ ⎫=i=1∑nyi(xi−n1i=1∑nxi)⇒ω1=i=1∑nxi2−n1(i=1∑nxi)2i=1∑nyi(xi−n1i=1∑nxi)
多元回归模型LMS
损失函数构造
n n n 个数据表示为
{ ω 0 + ω 1 x 1 ( 1 ) + ⋯ + ω n x 1 ( m ) = y ω ( x 1 ) ω 0 + ω 1 x 2 ( 1 ) + ⋯ + ω n x 2 ( m ) = y ω ( x 2 ) ⋮ ω 0 + ω n x 1 ( 1 ) + ⋯ + ω n x n ( m ) = y ω ( x n ) \begin{cases} \omega_0+\omega_1 x_1^{(1)}+\cdots+\omega_n x_1^{(m)}=y_{\omega}(x_1)\\ \omega_0+\omega_1 x_2^{(1)}+\cdots+\omega_n x_2^{(m)}=y_{\omega}(x_2)\\ \vdots\\ \omega_0+\omega_n x_1^{(1)}+\cdots+\omega_n x_n^{(m)}=y_{\omega}(x_n)\\ \end{cases} ⎩ ⎨ ⎧ω0+ω1x1(1)+⋯+ωnx1(m)=yω(x1)ω0+ω1x2(1)+⋯+ωnx2(m)=yω(x2)⋮ω0+ωnx1(1)+⋯+ωnxn(m)=yω(xn)
表示为矩阵形式为
[ 1 x 1 ( 1 ) x 1 ( 2 ) ⋯ x 1 ( m ) 1 x 2 ( 1 ) x 2 ( 2 ) ⋯ x 2 ( m ) ⋮ ⋮ ⋮ ⋱ ⋮ 1 x n ( 1 ) x n ( 2 ) ⋯ x n ( m ) ] ( ω 0 ω 1 ω 2 ⋮ ω m ) = ( y ω ( x 1 ) y ω ( x 2 ) ⋮ y ω ( x n ) ) ⇒ A ω = Y ^ \left[ \begin{matrix} 1&x_1^{(1)}&x_1^{(2)}&\cdots&x_1^{(m)}\\ 1&x_2^{(1)}&x_2^{(2)}&\cdots&x_2^{(m)}\\ \vdots&\vdots&\vdots&\ddots&\vdots\\ 1&x_n^{(1)}&x_n^{(2)}&\cdots&x_n^{(m)}\\ \end{matrix} \right]\left( \begin{matrix} \omega_0\\ \omega_1\\ \omega_2\\ \vdots\\ \omega_m \end{matrix} \right)=\left( \begin{matrix} y_{\omega}(x_1)\\ y_{\omega}(x_2)\\ \vdots\\ y_{\omega}(x_n)\\ \end{matrix} \right)\Rightarrow A\omega = \hat{Y} 11⋮1x1(1)x2(1)⋮xn(1)x1(2)x2(2)⋮xn(2)⋯⋯⋱⋯x1(m)x2(m)⋮xn(m) ω0ω1ω2⋮ωm = yω(x1)yω(x2)⋮yω(xn) ⇒Aω=Y^
优化问题变为 S = ∥ A ω − Y ∥ 2 2 S=\Vert A\omega-Y\Vert_2^2 S=∥Aω−Y∥22 ,即求 S S S 的最小化 ω ^ = a r g min ω ∥ A ω − Y ∥ 2 2 \hat{\omega}=arg\min\limits_{\omega}\Vert A\omega-Y\Vert_2^2 ω^=argωmin∥Aω−Y∥22
LMS最优化
∥ A ω − Y ∥ 2 2 = ( A ω − Y ) T ( A ω − Y ) = ( ω T A T − Y T ) ( A ω − Y ) = ω T A T A ω − ω T A T Y − Y T A ω + Y T Y = ( ω T A T Y ) 1 × m × m × n × n × 1 为标量 ω T A T A ω − 2 ω T A T Y + Y T Y \begin{aligned} \Vert A\omega-Y\Vert_2^2&=(A\omega-Y)^T(A\omega-Y)=(\omega^TA^T-Y^T)(A\omega-Y)\\ &=\omega^TA^TA\omega-\omega^TA^TY-Y^TA\omega+Y^TY\\ &\xlongequal{(\omega^TA^TY)_{1\times m\times m\times n\times n\times 1}为标量}\omega^TA^TA\omega-2\omega^TA^TY+Y^TY \end{aligned} ∥Aω−Y∥22=(Aω−Y)T(Aω−Y)=(ωTAT−YT)(Aω−Y)=ωTATAω−ωTATY−YTAω+YTY(ωTATY)1×m×m×n×n×1为标量ωTATAω−2ωTATY+YTY
令 ∂ S ∂ ω = 0 \frac{\partial S}{\partial \omega}=0 ∂ω∂S=0 ,有
∂ ( ω T A T A ω − 2 ω T A T Y + Y T Y ) ∂ ω = ∂ ( ω T A T A ω ) ∂ ω − 2 A T Y \frac{\partial (\omega^TA^TA\omega-2\omega^TA^TY+Y^TY)}{\partial \omega}=\frac{\partial(\omega^TA^TA\omega)}{\partial \omega}-2A^TY ∂ω∂(ωTATAω−2ωTATY+YTY)=∂ω∂(ωTATAω)−2ATY
引理: d ( u T v ) d x \frac{d(u^Tv)}{dx} dxd(uTv)
d ( u T v ) d x = d u T d x v + d v T d x u d ( x T B x ) d x = d x T d x B x + d ( x T B T ) d x x = B x + B T x = ( B + B T ) x ∴ ∂ ( ω T A T A ω ) ∂ ω = ( A T A + A T A ) ω = 2 A T A ω \frac{d(u^Tv)}{dx}=\frac{du^T}{dx}v+\frac{dv^T}{dx}u\\ \frac{d(x^TBx)}{dx}=\frac{dx^T}{dx}Bx+\frac{d(x^TB^T)}{dx}x=Bx+B^Tx=(B+B^T)x\\ \therefore \frac{\partial(\omega^TA^TA\omega)}{\partial \omega}=(A^TA+A^TA)\omega=2A^TA\omega dxd(uTv)=dxduTv+dxdvTudxd(xTBx)=dxdxTBx+dxd(xTBT)x=Bx+BTx=(B+BT)x∴∂ω∂(ωTATAω)=(ATA+ATA)ω=2ATAω
对于最优化问题
∂ S ∂ ω = 2 A T A ω − 2 A T Y = 0 ⇒ A T A ω = A T Y ω ^ = ( A T A ) − 1 A T Y \frac{\partial S}{\partial \omega}=2A^TA\omega-2A^TY=0\Rightarrow A^TA\omega=A^TY\\ \hat{\omega}=(A^TA)^{-1}A^TY ∂ω∂S=2ATAω−2ATY=0⇒ATAω=ATYω^=(ATA)−1ATY
GD与LMS对比
LMS计算量来源于计算求逆的计算量
梯度下降存在局部收敛问题,收敛速度满,步长的选取
最优实践,普通线性模型,数据量不超过百万级,可以不用梯度下降
多角度理解LMS
几何角度

线性组合
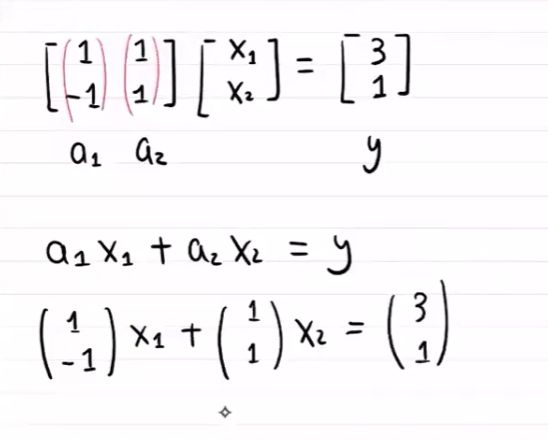

矩阵角度
对于数据集 D = { ( 0 , 2 ) , ( 1 , 2 ) , ( 2 , 3 ) } D=\{(0,2),(1,2),(2,3)\} D={(0,2),(1,2),(2,3)}
线性回归模型为
( 0 , 2 ) → a ⋅ 0 + b = 2 ( 1 , 2 ) → a ⋅ 1 + b = 2 ( 2 , 3 ) → a ⋅ 2 + b = 3 (0,2)\rightarrow a\cdot 0+b=2\\ (1,2)\rightarrow a\cdot 1+b=2\\ (2,3)\rightarrow a\cdot 2+b=3 (0,2)→a⋅0+b=2(1,2)→a⋅1+b=2(2,3)→a⋅2+b=3
即有
[ 0 1 1 1 2 1 ] [ a b ] = [ 2 2 3 ] [ α 1 , α 2 ] ω = y ^ { y ^ = A ω e = y − y ^ = y − A ω \left[ \begin{matrix} 0&1\\1&1\\2&1 \end{matrix} \right]\left[\begin{matrix}a\\b\end{matrix}\right]=\left[\begin{matrix}2\\2\\3\end{matrix}\right]\\\\ [\alpha_1,\alpha_2]\omega=\hat{y}\\\\ \begin{cases} \hat{y}=A\omega\\ e=y-\hat{y}=y-A\omega \end{cases} 012111 [ab]= 223 [α1,α2]ω=y^{y^=Aωe=y−y^=y−Aω

由几何可知
{ e ⋅ α 1 = 0 e ⋅ α 2 = 0 ⇒ { α 1 T ⋅ e = 0 α 2 T ⋅ e = 0 ⇒ A T e = 0 \begin{cases} e\cdot\alpha_1=0\\ e\cdot\alpha_2=0 \end{cases}\Rightarrow \begin{cases} \alpha_1^T\cdot e=0\\ \alpha_2^T\cdot e=0 \end{cases}\Rightarrow A^Te=0 {e⋅α1=0e⋅α2=0⇒{α1T⋅e=0α2T⋅e=0⇒ATe=0
故有
A T ( y − y ^ ) = A T ( y − A ω ) = A T y − A T A ω = 0 ω = ( A T A ) − 1 A T y A^T(y-\hat{y})=A^T(y-A\omega)=A^Ty-A^TA\omega=0\\ \omega=(A^TA)^{-1}A^Ty AT(y−y^)=AT(y−Aω)=ATy−ATAω=0ω=(ATA)−1ATy
概率角度
设误差 x i x_i xi 服从 ( μ , σ 2 ) (\mu,\sigma^2) (μ,σ2) 的正态分布
f ω ( x 1 , x 2 , ⋯ , x n ) = f ( x 1 , x 2 , ⋯ , x n ∣ ω ) = x 1 , ⋯ , x n 之间独立同分布 f ( x 1 ∣ ω ) f ( x 2 ∣ ω ) ⋯ f ( x n ∣ ω ) = ∏ i = 1 n 1 2 π σ e − ( x i − μ ) 2 2 σ 2 l n f ω ( x 1 , x 2 , ⋯ , x n ) = − n l n 2 π σ − ∑ i = 1 n ( x i − μ ) 2 2 σ 2 \begin{aligned} f_{\omega}(x_1,x_2,\cdots,x_n)&=f(x_1,x_2,\cdots,x_n\vert \omega)\\ &\xlongequal{x1,\cdots,x_n之间独立同分布}f(x_1\vert \omega)f(x_2\vert \omega)\cdots f(x_n\vert \omega)\\ &=\prod\limits_{i=1}^n\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x_i-\mu)^2}{2\sigma^2}}\\ lnf_{\omega}(x_1,x_2,\cdots,x_n)&=-nln\sqrt{2\pi}\sigma-\sum\limits_{i=1}^n\frac{(x_i-\mu)^2}{2\sigma^2} \end{aligned} fω(x1,x2,⋯,xn)lnfω(x1,x2,⋯,xn)=f(x1,x2,⋯,xn∣ω)x1,⋯,xn之间独立同分布f(x1∣ω)f(x2∣ω)⋯f(xn∣ω)=i=1∏n2πσ1e−2σ2(xi−μ)2=−nln2πσ−i=1∑n2σ2(xi−μ)2
从 概率论 的角度解释,线性回归得到的是统计意义上的拟合结果,在单变量的情形下,可能一个样本点都没有落在求得的直线上
对上述现象的解释是:回归结果可以完美匹配理想样本点的分布,但训练中使用的真实样本点是理想样本点和噪声叠加的结果,因而与回归模型之间产生了偏差,每个样本点上噪声的取值等于 y i = ω T x i + ε i y_i=\omega^Tx_i+\varepsilon_i yi=ωTxi+εi
设 ε i = y i − ω T x i \varepsilon_i=y_i-\omega^Tx_i εi=yi−ωTxi 服从 ( 0 , σ 2 ) (0,\sigma^2) (0,σ2) 的正态分布,即
P ( ε i ) = 1 2 π σ e − ε i 2 2 σ 2 P(\varepsilon_i)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{\varepsilon_i^2}{2\sigma^2}} P(εi)=2πσ1e−2σ2εi2

假定样本点的噪声满足参数为 ( 0 , σ 2 ) (0,\sigma^2) (0,σ2) 的正态分布,这意味着噪声等于0的概率密度最大。
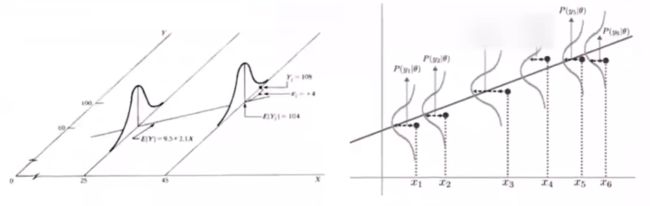
在这种情况下,对参数 w w w 的推导就可以用 最大似然估计 进行,即在已知样本数据及其分布的条件下,找到使样本数据以最大概率出现的参数假设 w w w
P ( y i ∣ x i , ω ) = 1 2 π σ e − ( y i − ω T x i ) 2 2 σ 2 P(y_i\vert x_i,\omega)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y_i-\omega^Tx_i)^2}{2\sigma^2}} P(yi∣xi,ω)=2πσ1e−2σ2(yi−ωTxi)2
在假设每个样本独立同分布的前提下,似然概率写作
L ( ω ) = L ( ω ∣ X , Y ) = P ( x 1 , x 2 , ⋯ , x n ∣ w ) = ∏ i n 1 2 π σ e − ( y i − w T x i ) 2 2 σ 2 L(\omega)=L(\omega\vert X,Y)=P(x_1,x_2,\cdots,x_n\vert w)=\prod\limits_{i}^n\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y_i-w^Tx_i)^2}{2\sigma^2}} L(ω)=L(ω∣X,Y)=P(x1,x2,⋯,xn∣w)=i∏n2πσ1e−2σ2(yi−wTxi)2
最大似然估计的任务就是让上述表达式的取值最大化。为便于计算,对似然概率取对数
l n L ( ω ) = ln P ( x 1 , x 2 , ⋯ , x n ∣ w ) = − ∑ i n [ ln 2 π σ + ( y i − w T x i ) 2 2 σ 2 ] lnL(\omega)=\ln P(x_1,x_2,\cdots,x_n\vert w)=-\sum\limits_{i}^n\left[\ln \sqrt{2\pi}\sigma+\frac{(y_i-w^Tx_i)^2}{2\sigma^2}\right] lnL(ω)=lnP(x1,x2,⋯,xn∣w)=−i∑n[ln2πσ+2σ2(yi−wTxi)2]
令 ∂ l n L ( ω ) ∂ ω = 0 \frac{\partial lnL(\omega)}{\partial \omega}=0 ∂ω∂lnL(ω)=0 ,有
∂ ∂ ω ∑ i = 1 n ( y i − w T x i ) 2 = 0 \frac{\partial}{\partial\omega}\sum\limits_{i=1}^n(y_i-w^Tx_i)^2=0 ∂ω∂i=1∑n(yi−wTxi)2=0
即似然概率的最大化等效为 ∑ k = 1 n ( w T x k − y k ) 2 \sum\limits_{k=1}^n(w^Tx_k-y_k)^2 k=1∑n(wTxk−yk)2 的最小化
3.2.6 回归方程衡量标准
回归方程的拟合优度
回归直线与各观测点的近似程度称为回归直线对数据的拟合优度
总平方和 SST :反映因变量的 n n n 个观察值与均值的总偏差
∑ i = 1 n ( y i − y ‾ ) 2 \sum\limits_{i=1}^n(y_i-\overline{y})^2 i=1∑n(yi−y)2
回归平方和 SSR :由于 x x x 与 y y y 的线性关系引起的 y y y 的变化部分(回归直线可解释部分造成的误差)
∑ i = 1 n ( y ^ i − y ‾ ) 2 \sum\limits_{i=1}^n(\hat{y}_i-\overline{y})^2 i=1∑n(y^i−y)2
残差平方和 SSE :由于 x x x 与 y y y 的线性关系外的关系引起的 y y y 的变化部分(回归直线不可解释部分造成的误差)
∑ i = 1 n ( y i − y ^ i ) 2 \sum\limits_{i=1}^n(y_i-\hat{y}_i)^2 i=1∑n(yi−y^i)2
总平方和可以分解为回归平方和、残差平方和 S S T = S S R + S S E SST=SSR+SSE SST=SSR+SSE
∑ i = 1 n ( y i − y ‾ ) 2 = ∑ i = 1 n ( y ^ − y ‾ ) 2 + ∑ i = 1 n ( y − y ^ ) 2 \sum\limits_{i=1}^n(y_i-\overline y)^2=\sum\limits_{i=1}^n(\hat{y}-\overline{y})^2+\sum\limits_{i=1}^n(y-\hat{y})^2 i=1∑n(yi−y)2=i=1∑n(y^−y)2+i=1∑n(y−y^)2
判定系数
R 2 = S S R S S T = 回归平方 总平方和 = ∑ i = 1 n ( y ^ i − y ‾ ) 2 ∑ i = 1 n ( y i − y ‾ ) 2 = 1 − ∑ i = 1 n ( y i − y ^ ) 2 ∑ i = 1 n ( y i − y ‾ ) 2 R^2=\frac{SSR}{SST}=\frac{回归平方}{总平方和}=\frac{\sum\limits_{i=1}^n(\hat{y}_i-\overline{y})^2}{\sum\limits_{i=1}^n(y_i-\overline{y})^2}=1-\frac{\sum\limits_{i=1}^n(y_i-\hat{y})^2}{\sum\limits_{i=1}^n(y_i-\overline{y})^2} R2=SSTSSR=总平方和回归平方=i=1∑n(yi−y)2i=1∑n(y^i−y)2=1−i=1∑n(yi−y)2i=1∑n(yi−y^)2
理想情况 R 2 = 1 R^2=1 R2=1 ,残差平方和为 0 0 0(即整体误差完全由线性误差引起)回归方程完全可解释 x x x 与 y y y 的关系
- R 2 R^2 R2 越大,回归方程可解释能力越强
- R 2 R^2 R2 越小,回归方程可解释能力越弱
3.2.7 显著性检验
由于回归方程是根据样本数据得到的,是否真实反映了变量 X X X 和 Y Y Y 之间的关系,需要通过检验后才可以确定
显著性检验包括两方面:
- 线性关系检验
- 回归系数检验
线性关系检验
检验 X X X 和 Y Y Y 的线性关系是否显著,是否可用线性模型表示
将均方回归( MSR )和均方残差( MSE )进行比较,应用 F F F 检验来分析二者之间的差别是否显著
- 均方回归:回归平方和
SSR除以相应的自由度(参数个数 m) - 均方残差:残差平方和
SSE除以自由度( n − m − 1 n-m-1 n−m−1)
线性误差 非线性误差 \frac{线性误差}{非线性误差} 非线性误差线性误差
若 ω = 0 \omega=0 ω=0 ,即所有回归系数与0无显著差异,则 y y y 与全体 x x x 的线性关系不显著
计算检验统计量
F = S S R / m S S E / n − m − 1 = ∑ i = 1 n ( y ^ i − y ‾ ) 2 / m ∑ i = 1 n ( y − y ^ ) 2 / n − m − 1 = M S R M S E ∼ F ( m , n − m − 1 ) \\F=\frac{SSR/m}{SSE/n-m-1}=\frac{\sum\limits_{i=1}^n(\hat{y}_i-\overline{y})^2/m}{\sum\limits_{i=1}^n(y-\hat{y})^2/n-m-1}=\frac{MSR}{MSE}\sim F(m,n-m-1) F=SSE/n−m−1SSR/m=i=1∑n(y−y^)2/n−m−1i=1∑n(y^i−y)2/m=MSEMSR∼F(m,n−m−1)
回归系数检验
检验每个回归系数 ω \omega ω 与 0 0 0 是否有显著性差异,来判断 Y Y Y 与 X X X 之间是否有显著的线性关系
-
若 ω ≈ 0 \omega \approx0 ω≈0 则总体回归方程中不含 X X X 项,因此,变量 Y Y Y 与 X X X 之间不存在线性关系
-
若 ω ≠ 0 \omega \neq 0 ω=0 ,则变量 Y Y Y 与 X X X 有显著的线性关系
如:
ω ^ 1 \hat{\omega}_1 ω^1 是根据最小二乘法求出的样本统计量,服从正态分布,有 E ( ω ^ 1 ) = ω 1 E(\hat{\omega}_1)=\omega_1 E(ω^1)=ω1 ,标准差 σ ω 1 = σ ∑ x i 2 − 1 n ( ∑ x i ) 2 \sigma_{\omega_1}=\frac{\sigma}{\sqrt{\sum x_i^2-\frac{1}{n}(\sum x_i)^2}} σω1=∑xi2−n1(∑xi)2σ
由于 σ \sigma σ 未知,需要用其估计量 标准差 S e S_e Se 来代替得到 ω ^ 1 \hat{\omega}_1 ω^1 的估计标准差
S ω ^ 1 = S e ∑ x i 2 − 1 n ( ∑ x i ) 2 S e = ∑ ( y i − y ^ i ) 2 n − K − 1 = M S E S_{\hat{\omega}_1}=\frac{S_e}{\sqrt{\sum x_i^2-\frac{1}{n}(\sum x_i)^2}}\\ S_e=\sqrt\frac{\sum(y_i-\hat{y}_i)^2}{n-K-1}=\sqrt{MSE} Sω^1=∑xi2−n1(∑xi)2SeSe=n−K−1∑(yi−y^i)2=MSE
计算检验的统计量: t = ω ^ 1 − ω S ω ^ 1 ∼ t ( n − 2 ) t=\frac{\hat{\omega}_1-\omega}{S_{\hat{\omega}_1}}\sim t(n-2) t=Sω^1ω^1−ω∼t(n−2)
线性关系检验与回归系数检验区别:
线性关系检验的是自变量与因变量是否可以用线性关系表示;回归系数的检验是判断通过样本计算得出的回归系数是否为0
-
在一元线性回归中,自变量只有一个,线性关系检验与回归系数检验是等价的
线性关系检验 F = S S R / 1 S S E / n − 1 − 1 = M S R M S E ∼ F ( 1 , n − 2 ) = t ( n − 2 ) F=\frac{SSR/1}{SSE/n-1-1}=\frac{MSR}{MSE}\sim F(1,n-2)=t(n-2) F=SSE/n−1−1SSR/1=MSEMSR∼F(1,n−2)=t(n−2)
回归系数检验 t = ω ^ 1 − ω 1 S ω ^ 1 ∼ t ( n − 2 ) t=\frac{\hat{\omega}_1-\omega_1}{S_{\hat{\omega}_1}}\sim t(n-2) t=Sω^1ω^1−ω1∼t(n−2)
-
多元回归分析中,线性关系检验只能用来检验总体回归关系的显著性。回归系数检验可以对各个回归系数分别进行检验
3.2.8 利用回归直线进行估计和预测
点估计:利用估计的回归方程,对 x x x 的一个特定值,求解 y ^ i \hat{y}_i y^i 的一个估计值
区间估计:利用估计的回归方程,对于 x x x 的一个特定量,求出 y y y 的一个估计量的区间
预测结果的置信度
标准差
度量观测值围绕着回归直线的变化程度(点估计)
S e = ∑ i = 1 n ( y i − y ^ i ) 2 n − 2 S_e=\sqrt\frac{\sum\limits_{i=1}^n(y_i-\hat{y}_i)^2}{n-2} Se=n−2i=1∑n(yi−y^i)2
- 自由度为 n − 2 n-2 n−2
- 标准差越大,则分散程度越大,回归方程的可靠性越小
置信区间估计
预测结果具有可靠性的范围
y ^ 0 ± t α 2 s e 1 n + ( x i + 1 − x ‾ ) 2 ∑ i = 1 n ( x i − x ‾ ) 2 \hat{y}_0\pm t_{\frac{\alpha}{2}}s_e\sqrt{\frac{1}{n}+\frac{(x_{i+1}-\overline{x})^2}{\sum\limits_{i=1}^n(x_i-\overline{x})^2}} y^0±t2αsen1+i=1∑n(xi−x)2(xi+1−x)2
在 1 − α 1-\alpha 1−α 置信水平下预测区间为
y ^ 0 ± t α 2 s e 1 + 1 n + ( x i + 1 − x ‾ ) 2 ∑ i = 1 n ( x i − x ‾ ) 2 \hat{y}_0\pm t_{\frac{\alpha}{2}}s_e\sqrt{1+\frac{1}{n}+\frac{(x_{i+1}-\overline{x})^2}{\sum\limits_{i=1}^n{(x_i-\overline{x})^2}}} y^0±t2αse1+n1+i=1∑n(xi−x)2(xi+1−x)2
eg
广告费与销售额的关系如图,若2003年广告费120万元,用一元线性回归求 2003年产品销售额的置信区间与预测区间( α = 0.05 \alpha=0.05 α=0.05)

ω 1 = ∑ i = 1 n y i ( x i − 1 n ∑ i = 1 n x i ) ∑ i = 1 n x i 2 − 1 n ( ∑ i = 1 n x i ) 2 = 9 ∑ i = 1 9 x i y i − ∑ i = 1 9 x i ∑ i = 1 9 y i 9 ∑ i = 1 9 x i 2 − ( ∑ i = 1 9 x i ) 2 = 0.57 ω ^ 0 = y ‾ − ω ^ 1 x ‾ = − 3.65 故有一元线性回归方程 y ^ = ω ^ 0 + ω ^ 1 x = − 3.65 + 0.57 x y ^ 10 = − 3.65 + 0.57 × 120 = 64.75 t α 2 ( n − 2 ) = t 0.025 ( 7 ) = 2.365 , S e = ∑ i = 1 9 ( y i − y i ^ ) 2 n − 2 = 2.43 y 0 ^ ± t α 2 s e 1 n + ( x 10 − x ‾ ) 2 ∑ i = 1 9 ( x i − x ‾ ) 2 = 64.75 ± 2.365 × 2.43 × 0.743 = 64.75 ± 4.2699 y 0 ^ ± t 1 + α 2 s e 1 n + ( x 10 − x ‾ ) 2 ∑ i = 1 9 ( x i − x ‾ ) 2 = 64.75 ± 2.365 × 2.43 × 1.2459 = 64.75 ± 4.3516 \begin{aligned} &\omega_1=\frac{\sum\limits_{i=1}^ny_i(x_i-\frac{1}{n}\sum\limits_{i=1}^nx_i)}{\sum\limits_{i=1}^nx_i^2-\frac{1}{n}\left(\sum\limits_{i=1}^nx_i\right)^2}=\frac{9\sum_{i=1}\limits^9x_iy_i-\sum_{i=1}\limits^9x_i\sum_{i=1}\limits^9y_i}{9\sum_{i=1}\limits^9x_i^2-(\sum_{i=1}\limits^9x_i)^2}=0.57\\ &\hat{\omega}_0=\overline{y}-\hat{\omega}_1\overline{x}=-3.65\\ &故有一元线性回归方程 \hat{y}=\hat{\omega}_0+\hat{\omega}_1x=-3.65+0.57x\\ &\hat{y}_{10}=-3.65+0.57\times 120=64.75\\ &t_\frac{\alpha}{2}(n-2)=t_{0.025}(7)=2.365,S_e=\sqrt\frac{\sum_{i=1}\limits^9(y_i-\hat{y_i})^2}{n-2}=2.43\\ &\hat{y_0}\pm t_{\frac{\alpha}{2}}s_e\sqrt{\frac{1}{n}+\frac{(x_{10}-\overline{x})^2}{\sum_{i=1}\limits^{9}(x_i-\overline{x})^2}}=64.75\pm2.365\times 2.43\times 0.743=64.75\pm4.2699\\ &\hat{y_0}\pm t_{1+\frac{\alpha}{2}}s_e\sqrt{\frac{1}{n}+\frac{(x_{10}-\overline{x})^2}{\sum_{i=1}\limits^{9}(x_i-\overline{x})^2}}=64.75\pm2.365\times 2.43\times 1.2459=64.75\pm4.3516 \end{aligned} ω1=i=1∑nxi2−n1(i=1∑nxi)2i=1∑nyi(xi−n1i=1∑nxi)=9i=1∑9xi2−(i=1∑9xi)29i=1∑9xiyi−i=1∑9xii=1∑9yi=0.57ω^0=y−ω^1x=−3.65故有一元线性回归方程y^=ω^0+ω^1x=−3.65+0.57xy^10=−3.65+0.57×120=64.75t2α(n−2)=t0.025(7)=2.365,Se=n−2i=1∑9(yi−yi^)2=2.43y0^±t2αsen1+i=1∑9(xi−x)2(x10−x)2=64.75±2.365×2.43×0.743=64.75±4.2699y0^±t1+2αsen1+i=1∑9(xi−x)2(x10−x)2=64.75±2.365×2.43×1.2459=64.75±4.3516
置信区间宽度影响因素
- 区间宽度随置信水平 1 − α 1-\alpha 1−α 的增大而增大
- 区间宽度随离散程度 S e S_e Se 的增大而增大
- 区间宽度随样本容量的增大而减小
- 预测值与均值的差异越大,区间宽度越大

3.2.9 多元线性回归问题
调整的多重判定系数:
R 2 = 1 − ( 1 − R 2 ) × n − 1 n − m − 1 R^2=1-(1-R^2)\times\frac{n-1}{n-m-1} R2=1−(1−R2)×n−m−1n−1
m m m 为系数个数, n n n 为样本容量
- 表示消除自变量数量增加的影响
曲线回归分析过程
- 根据散点图确定曲线类型
- 先将 x x x 或 y y y 进行变量转换
- 对新变量进行直线回归分析,建立直线回归方程并进行显著性检验和置信区间估计
- 将新变量还原为原变量,由新变量的直线回归方程和置信区间得出原变量的曲线回归方程和置信区间
eg

散点图:

故可设 y ^ = a + b 1 x \hat{y}=a+b\frac{1}{x} y^=a+bx1 ,令 1 x = x ′ ⇒ y ^ = a + b x ′ \frac{1}{x}=x'\Rightarrow \hat{y}=a+bx' x1=x′⇒y^=a+bx′
标准方程为
{ ∑ i = 1 n y i = n a + b ∑ i = 1 n x ′ ∑ i = 1 n x ′ y = a ∑ i = 1 n x ′ + b ∑ i = 1 n ( x ′ ) 2 \left\{\begin{aligned}&\sum\limits_{i=1}^n y_i = na+b\sum\limits_{i=1}^n x'\\&\sum\limits_{i=1}^n x'y=a\sum\limits_{i=1}^n x'+b\sum\limits_{i=1}^n(x')^2\end{aligned}\right. ⎩ ⎨ ⎧i=1∑nyi=na+bi=1∑nx′i=1∑nx′y=ai=1∑nx′+bi=1∑n(x′)2
将数据代入的 { a = − 0.4377 b = 60.4 \left\{\begin{aligned}&a=-0.4377\\&b=60.4\end{aligned}\right. {a=−0.4377b=60.4
有 y ^ = − 0.4377 + 60.4 x ′ = − 0.4377 + 60.4 1 x \hat{y}=-0.4377+60.4x'=-0.4377+60.4\frac{1}{x} y^=−0.4377+60.4x′=−0.4377+60.4x1
多重共线性
回归模型中两个或多个自变量彼此相关
引起的问题:
- 回归系数估计值不稳定性增强
- 回归系数假设检验的结果不显著
多重共线性检验方法:
- 容忍度
- 方差膨胀因子
容忍度
T o l i = 1 − R i 2 Tol_i=1-R_i^2 Toli=1−Ri2
- R i R_i Ri 解释变量 x i x_i xi 与方程中其他解释变量间的复相关系数
- 容忍度在 0 ∼ 1 0\sim 1 0∼1 之间,越接近0,表示多重共线性越强
方差膨胀因子
V I F i = 1 1 − R i 2 = 1 T o l i VIF_i=\frac{1}{1-R_i^2}=\frac{1}{Tol_i} VIFi=1−Ri21=Toli1
- V I F i VIF_i VIFi 越大,解释变量 x i x_i xi 与方程中其他解释变量之间有严重的共线性
过拟合问题
在大量复杂的实际任务中,每个样本属性的数目甚至会超过训练集中的样本总数,此时求出的 ω ^ \hat{\omega} ω^ 不是唯一的,解的选择依赖于学习算法的归纳偏好
但无论怎样选择标准,存在多个最优解的问题不会改变,极易出现过拟合现象——正则化解决过拟合问题
即添加额外的惩罚项。根据使用的惩罚项不同,分为
- 岭回归
- LASSO回归
其共同思想:通过惩罚项的引入抑制过拟合现象,以训练误差增加为代价换取测试误差下降
岭回归
也称 参数衰减
岭回归实现正则化的方式是在原始均方误差的基础上,加一个待求解参数的二范数项,即最小化求解的对象变为
∥ y k − w T x k ∥ 2 + ∥ Γ w ∥ 2 , Γ 为季霍诺夫矩阵 \Vert y_k-w^Tx_k\Vert^2+\Vert \Gamma w\Vert^2,\Gamma为季霍诺夫矩阵 ∥yk−wTxk∥2+∥Γw∥2,Γ为季霍诺夫矩阵
- 季霍诺夫矩阵主要目的是解决矩阵求逆的稳定性问题
LASSO回归
最小绝对缩减和选择算子
LASSO回归选择了待求解参数的一范数作为惩罚项,即最小化求解的对象变为
∥ y k − w T x k ∥ 2 + λ ∥ w ∥ 1 \Vert y_k-w^Tx_k\Vert^2+\lambda \Vert w\Vert_1 ∥yk−wTxk∥2+λ∥w∥1
岭回归与LASSO回归概率角度
从最优化角度
岭回归:二范数惩罚项的作用在于优先选择范数较小的 w w w 。相当于在最小均方误差之外额外添加了一重约束条件,将最优解限制在高维空间内的一个球内
- 在最小二乘的结果上做了缩放,虽然最优解中参数的贡献被削弱了,但参数的数目没有变少
LASSO回归:引入稀疏性,降低了最优解 w w w 维度,使一部分参数的贡献度 w i = 0 w_i=0 wi=0 ,使得 w w w 中元素数目大大小于原始特征的数目
- 引入稀疏性是简化复杂问题的一种常用方法,在数据压缩,信号处理等领域亦有应用
从概率角度看
岭回归是在 w i w_i wi 满足正态先验分布的条件下,用最大后验概率进行估计得到的结果
LASSO回归是在 w i w_i wi 满足拉普拉斯先验分布的条件下,用最大后验概率进行估计得到的结果