Day58|leetcode 739. 每日温度、496.下一个更大元素 I
今天开始单调栈!
leetcode 739. 每日温度
题目链接:739. 每日温度 - 力扣(LeetCode)
视频链接:单调栈,你该了解的,这里都讲了!LeetCode:739.每日温度_哔哩哔哩_bilibili
题目概述
给定一个整数数组
temperatures,表示每天的温度,返回一个数组answer,其中answer[i]是指对于第i天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用0来代替。示例 1:
输入:temperatures= [73,74,75,71,69,72,76,73]输出: [1,1,4,2,1,1,0,0]示例 2:
输入: temperatures = [30,40,50,60] 输出: [1,1,1,0]示例 3:
输入: temperatures = [30,60,90] 输出: [1,1,0]
思路
一开始看题,第一个想法就是两层for循环,暴力解决,其实这道题有更巧妙的方法--单调栈!
使用单调栈的时机:通常是一维数组,要寻找任一个元素的右边或者左边 第一个 比自己大或者小的元素的位置,此时我们就要想到可以用单调栈了。时间复杂度为O(n)。
单调栈的本质:空间换时间。
优点:整个数组只需要遍历一次。
说白了就是用一个栈来记录我们所遍历过的元素,而且栈里面只需要放元素下标就行,单调栈是单调递增还是单调递减,跟我们题中的要求有关,如果说题中要求右边第一个元素比自己大的,那就单调递增;如果要求右边第一个元素比自己小的,那就单调递减。
使用单调栈主要有三个判断条件:
当前遍历的元素T[i] 大于/等于/小于 栈顶元素T[st.top()]
以 [73, 74, 75, 71, 71, 72, 76, 73]为例
输出: [1, 1, 4, 2, 1, 1, 0, 0]
首先,根据题意要求,我们的单调栈肯定是个单调递增的(从栈头到栈底的顺序是单增!栈里放的是下标!!)
刚开始栈里放0(73的下标),然后再放个1(74的下标),因为74>73,所以把73弹出(栈头到栈底的顺序是单增!) 如图所示:
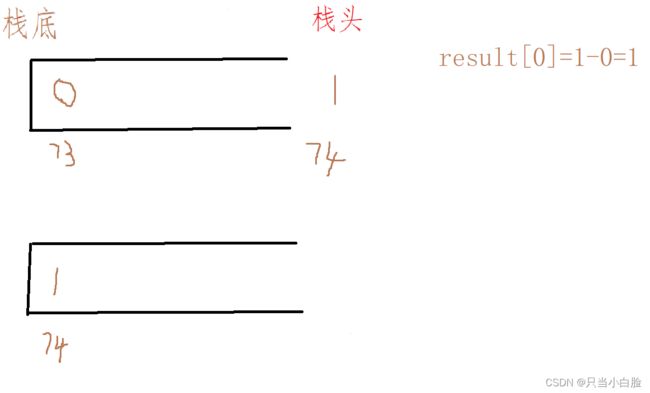
然后加入2(75的下标) ,因为75>74,所以把74弹出,跟上面同理,此时栈里就剩2(75的下标)
然后加入3(71的下标),因为71<75,所以把3(71的下标)往栈里放
然后加入4(71的下标),因为71=71,所以继续把4(71的下标)往栈里放(因为本题要求的是右边元素比左边大,所以只有大于的情况,才能把栈里的元素弹出,等于不可以)
然后加入5(72的下标),因为72>71(下标为4的71),所以将4弹出,然后继续和后面的元素比,因为72>71(下标为3的71),所以继续将3弹出,然后继续和后边元素比(比较过程是一个持续过程!),因为72<75,所以无法将其弹出,所以它俩一起留在栈里。这个过程如图所示:
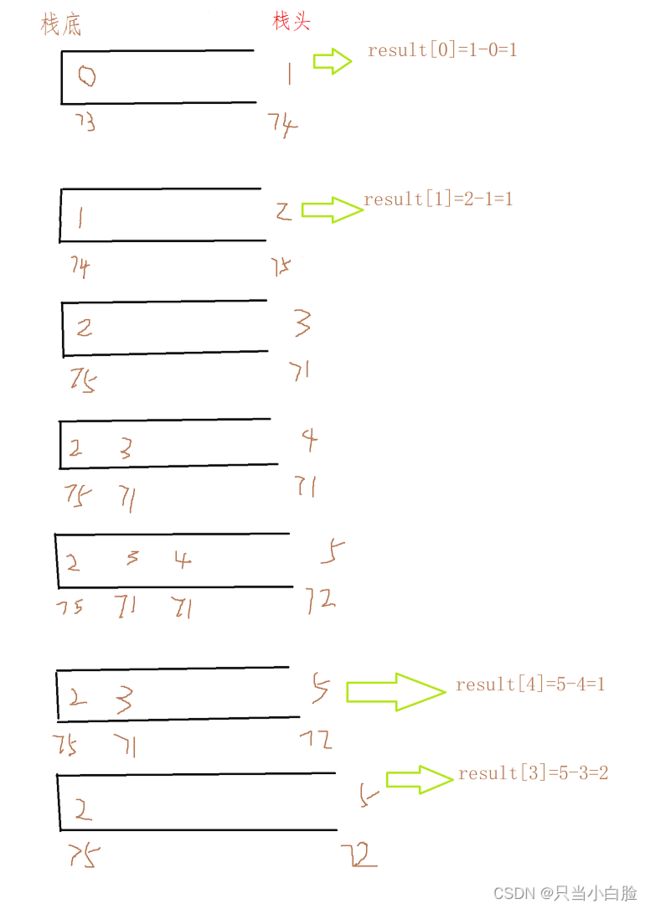
然后加入6(76的下标),因为76>72,所以将5(72的下标)弹出,继续和后面比,然后把2弹出(75的下标)
然后加入7(73的下标),因为73<76,所以它俩一起留在了栈里
这段过程如图所示:
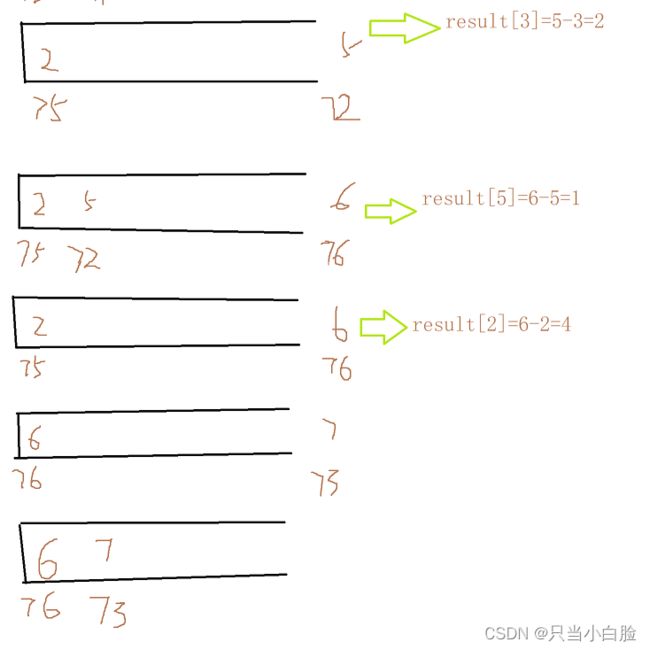
最后result[6] 、 result[7]没有更新,一直留在栈里,说明右边元素没有更大的了,也就是0。
其实自己手动模拟一遍这个过程,思路还挺清晰的。
代码实现
class Solution {
public:
vector dailyTemperatures(vector& temperatures) {
stack st;
vector result(temperatures.size(),0);
st.push(0);
for(int i = 1;i < temperatures.size();i++) {
if(temperatures[i] < temperatures[st.top()]) {
st.push(i);
}
else if(temperatures[i] == temperatures[st.top()]) {
st.push(i);
}
else {
while(!st.empty() && temperatures[i] > temperatures[st.top()]) {
result[st.top()] = i - st.top();
st.pop();
}
st.push(i);
}
}
return result;
}
}; leetcode 496.下一个更大元素 I
题目链接:496. 下一个更大元素 I - 力扣(LeetCode)
视频链接:单调栈,套上一个壳子就有点绕了| LeetCode:496.下一个更大元素_哔哩哔哩_bilibili
题目概述
nums1中数字x的 下一个更大元素 是指x在nums2中对应位置 右侧 的 第一个 比x大的元素。给你两个 没有重复元素 的数组
nums1和nums2,下标从 0 开始计数,其中nums1是nums2的子集。对于每个
0 <= i < nums1.length,找出满足nums1[i] == nums2[j]的下标j,并且在nums2确定nums2[j]的 下一个更大元素 。如果不存在下一个更大元素,那么本次查询的答案是-1。返回一个长度为
nums1.length的数组ans作为答案,满足ans[i]是如上所述的 下一个更大元素 。示例 1:
输入:nums1 = [4,1,2], nums2 = [1,3,4,2]. 输出:[-1,3,-1] 解释:nums1 中每个值的下一个更大元素如下所述: - 4 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。 - 1 ,用加粗斜体标识,nums2 = [1,3,4,2]。下一个更大元素是 3 。 - 2 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。示例 2:
输入:nums1 = [2,4], nums2 = [1,2,3,4]. 输出:[3,-1] 解释:nums1 中每个值的下一个更大元素如下所述: - 2 ,用加粗斜体标识,nums2 = [1,2,3,4]。下一个更大元素是 3 。 - 4 ,用加粗斜体标识,nums2 = [1,2,3,4]。不存在下一个更大元素,所以答案是 -1 。
思路
本题和上题整体框架几乎一样,就是有点绕。
我们定义存放结果的result和nums1一样大小就行(因为题中最后要求的是nums1中每个元素在nums2中下一个元素比当前元素大的元素),把result初始化为-1。
在遍历nums2时,用map做映射,来判断nums2中的元素是否在nums1中出现过。
代码实现
class Solution {
public:
vector nextGreaterElement(vector& nums1, vector& nums2) {
stack st;
vector result(nums1.size(), -1);
if (nums1.size() == 0) return result;
unordered_map umap; // key:下标元素,value:下标
for (int i = 0; i < nums1.size(); i++) {
umap[nums1[i]] = i;
}
st.push(0);
for (int i = 1; i < nums2.size(); i++) {
if (nums2[i] < nums2[st.top()]) { // 情况一
st.push(i);
} else if (nums2[i] == nums2[st.top()]) { // 情况二
st.push(i);
} else { // 情况三
while (!st.empty() && nums2[i] > nums2[st.top()]) {
if (umap.count(nums2[st.top()]) > 0) { // 看map里是否存在这个元素
int index = umap[nums2[st.top()]]; // 根据map找到nums2[st.top()] 在 nums1中的下标
result[index] = nums2[i];
}
st.pop();
}
st.push(i);
}
}
return result;
}
};