【论文阅读】Tetra-NeRF:使用四面体表示神经辐射场
【论文阅读】Tetra-NeRF:使用四面体表示神经辐射场
- 摘要
- 1. 引言
- 2. 相关工作
-
- 2.1 多视图重建
- 2.2 神经辐射场
- 2.3 场表示
- 3. 方法
-
- 3.1.预备知识
- 3.2.四面体场
- 3.3.高效查询四面体场
- 3.4.粗细采样
- 4. 实验
-
- 4.1.实施细节
- 4.2 评估
- 5. 局限
- 6. 结论

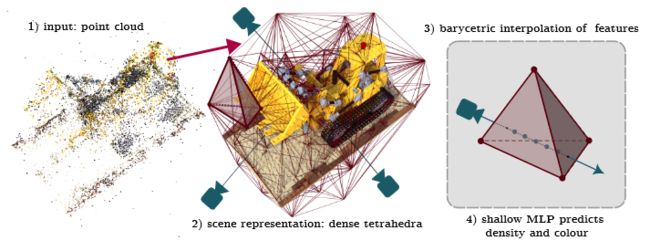
图 1. Tetra-NeRF 的输入是一个点云,它被三角化以获得一组用于表示辐射场的四面体。用以采样光线和查询场。重心插值用于对四面体顶点进行插值,并将生成的特征传递给浅层 MLP,以获得体积渲染的密度和颜色。
paper code
摘要
神经辐射场 (NeRFs) 是一种最近非常流行的方法,用于解决新视图合成和 3D 重建问题。 NeRFs 使用的一种流行的场景表示是将场景的统一的、基于体素的细分与 MLP 相结合。基于场景的(稀疏)点云通常可用的观察,本文提出使用基于四面体和 Delaunay 三角格网表示的自适应表示,而不是均匀细分或基于点的表示。我们表明,这样的表示可以进行有效的训练并产生最先进的结果。我们的方法优雅地结合了 3D 几何处理、基于三角形的渲染和现代神经辐射场的概念。与基于体素的表示相比,我们的表示提供了可能靠近表面的场景部分的更多细节。与基于点的表示相比,我们的方法实现了更好的性能。
1. 引言
从图像重建 3D 场景并渲染照片般逼真的新颖视图是计算机视觉中的关键问题。最近,NeRFs [3, 4, 38] 因其出色的逼真效果而成为该领域的主导者。最初,NeRFs 使用 MLPs 将 3D 场景表示为隐函数。给定一组姿势图像,NeRF 随机采样一批像素,将光线从像素投射到 3D 空间,查询沿光线随机采样距离处的隐式函数,并使用体积渲染聚合采样值 [36, 38] .虽然此类方法的视觉结果质量很高,但问题是在数百万个点上查询大型 MLP 的成本很高。此外,一旦网络经过训练,就很难对所表示的辐射场进行任何更改,因为一切都被烘焙到 MLP 参数中,并且任何更改都具有非局部效果。从那时起,已经提出了许多大型 MLP 场景表示的替代方案 [9、17、31、40、54、67、71]。这些方法将 MLP 与体素特征网格 [40、54] 相结合,或者在某些情况下将辐射场直接表示为张量 [9、10、17]。在查询这些表示时,首先找到包含的体素,然后对体素的八个角点存储的特征进行三线性插值。结果要么通过浅层 MLP [9、10、40、54],要么直接用作密度和颜色 [17、31、54]。
用密集的张量表示整个场景是非常低效的,因为我们只需要表示表面周围的一个小空间。因此,不同的方法提出了不同的处理方法。例如,Instant-NGP [40] 使用哈希网格而不是密集张量,它依靠优化来解决哈希冲突。然而,与 MLP 类似,对存储的哈希图的任何更改都会影响许多地方的场景。解决该问题的更常见方法是直接使用稀疏张量表示 [9, 17]。这些方法从低分辨率网格开始,然后按照预定义的步骤对表示进行子采样,从而提高分辨率。这些方法往往需要仔细设置超参数,例如场景边界框和细分步骤,以便这些方法能够很好地工作。
因为这些方法中有许多使用传统的运动结构 (SfM) [52、53] 方法来为捕获的图像生成初始姿势,所以我们可以在场景表示中复用原始重建。受经典表面重建方法 [22,23,28,29] 的启发,我们将场景表示为输入点云的密集三角网,其中场景是一组不重叠的四面体,其并集是原始点的凸包点云 [14]。当查询这样的表示时,我们查询点属于哪个四面体,并对存储在四面体顶点中的特征进行重心线性插值。这种非常简单的表示可以被认为是图形中使用的经典三角形渲染管道的直接扩展 [39,42,43]。该表示避免了输入点云的稀疏性问题,因为四面体完全覆盖了场景,从而产生连续而不是离散的表示。
本文做出以下贡献:
- 我们提出了一种新颖的辐射场表示,它是从稀疏或密集的点云初始化的。这种表示在表面附近天然更密集,因此在这些区域提供了更高的分辨率。
- 所提出的表示在多个合成和真实世界的数据集上进行了评估,并与最先进的基于点云的表示——Point-NeRF [67] 进行了比较。呈现的结果表明我们的方法明显优于该基线。我们通过将自适应表示与使用相同数量的可训练参数的基于体素的表示进行比较,进一步证明了自适应表示的有效性。
- 我们公开了源代码和模型训练结果。
2. 相关工作
2.1 多视图重建
多视图重建问题已得到广泛研究,并通过各种运动结构 (SfM) [52、58、60] 和多视图立体 (MVS) [12、18、53、68] 方法得到解决。这些方法通常输出表示为点云的场景 [52、53]。在大多数渲染方法中,点云被转换为网格 [24、34],并且使用 启发式定义 [8、13、66] 或学习所得的[20, 48, 49,70] 混合权重通过将观察到的图像重新投影到每个新颖的视点并将它们混合在一起来呈现新颖的视图。
然而,获取网格的过程通常会产生相当多的噪声,并且生成的网格在具有精细细节或复杂材料的区域中往往具有不准确的几何形状。基于点的神经渲染方法 [1、26、37、51] 不使用嘈杂的网格,而是执行神经特征的 splatting 并使用 2D 卷积来渲染它们。与这些方法相比,我们的方法直接在 3D 中操作和聚合特征,并且不会受到点云或重建网格中的噪声的影响。
2.2 神经辐射场
最近,NeRFs [3, 4, 33, 38, 74] 因其高质量的渲染性能而受到广泛关注。原始的 NeRF 方法 [38] 被扩展以更好地处理 [3] 中的混叠伪影,更好地表示 [4, 46, 74] 中的无界场景,或处理真实世界捕获的图像 [35, 55]。这些方法中使用的大型 MLP 的训练可能非常慢,并且在加速训练 [9, 17, 40] 或渲染 [21, 45, 46, 71] 方面已经付出了很多努力,有时仍需要较大的存储成本。其他方法解决了 NeRF 的不同方面,例如依赖于视图的人工制品 [59]、重新照明 [5,7] 或生成模型 [44,61]。此外,一个流行的研究方向是使模型在不同场景中泛化 [11,27,47,63,72]。大量研究致力于表面重建,而不是使用辐射场,而是通过对符号距离函数 (SDF) 建模来隐式表示场景 [50、62、64、69、73]。与那些方法不同,我们只关注辐射场表示,并认为这些方法与我们的方法 正交 。
尽管有一些方法可以在位姿微调 [30、57] 或没有已知相机 [6、65] 的情况下训练辐射场,但大多数方法都需要相机位姿来进行重建。 SfM,例如 COLMAP [52、53],通常用于估计位姿,这也会产生 (稀疏)点云。我们的方法利用位姿估计过程的这种副产品,而不是仅使用姿势本身。
2.3 场表示
当单个 MLP 用于表示整个场景时,所有内容都被烘焙到一组无法修改的参数中,因为对参数的任何更改都具有非局部效果,即它会在多个不相关的地方更改场景。为了克服这个问题,其他人尝试了不同的辐射场表示法 [9,10,17,31,40,54,67]。一种常见的做法是将场景表示为浅层 MLP 和有效编码的体素网格 [9、10、31、40],尽管编码的体素网格可以直接用于表示辐射场 [17、54]。体素网格可以编码为稀疏张量 [17、31、54]、4D 张量的因式分解 [9、10] 或哈希图 [40]。当查询这些结构时,使用三线性插值来组合存储在包含体素角中的特征向量。不幸的是,hashmaps [40] 和 hierarchical representations [10] 具有相同的非局部效应问题,其余方法依赖于后续的字段上采样并且可能过于复杂。此外,特征向量不能任意放置在 3D 空间中,因为它们必须位于具有固定分辨率的网格上。相比之下,我们的方法更加灵活,因为它将特征向量自由地存储在 3D 空间中。
最后,Point-NeRF [67] 将场景表示为使用 k 最近邻搜索查询的特征点云。然而,当点云包含稀疏区域时,光线不会与任何点的任何邻域相交,并且像素保持为空而无法优化。因此,Point-NeRF [67] 依赖于在训练过程中逐渐添加更多的点并增加场景的复杂性。由于我们使用点云的三角网而不是点云本身,因此我们的表示是密集的并且不会受到空白区域的影响。因此,我们不必在训练期间添加任何点。
3. 方法
文献中的一种常见策略是通过体素体积显式表示场景。与这种均匀细分相比,我们使用场景的自适应细分。在许多场景中,场景几何的近似值要么是给定的,例如,当使用 SfM 计算输入相机姿态时,要么是可以计算的,例如,通过 MVS 或单视图深度预测 [76]。这使我们能够通过此类点云的 Delaunay 三角格网 [14] 来计算场景的自适应细分。这将产生一组不重叠的四面体,其中较小的四面体靠近场景表面创建(参见图 2)。在下文中,我们将解释如何使用场景的这种自适应细分代替体素进行体绘制和神经绘制。

图 2. 输入点云和三角四面体的切片。请注意,较小的四面体是在靠近场景表面的地方创建的,即,靠近表面的区域以更精细的分辨率表示。
3.1.预备知识
神经辐射场 (NeRFs) [38] 通过隐式函数 F (x, d) 表示场景,通常通过神经网络建模,返回观察到的场景中给定 3D 点 x 的颜色值和体积密度预测从观察方向 d.体积渲染 [36] 用于合成新视图:对于虚拟视图中的每个像素,我们将一条光线从相机平面投射到场景中,并对辐射场进行采样以获得距离 ti 处的颜色和密度值 ci 和 σi射线,其中 i = 1 。 . . ñ。然后组合各个样本以预测像素的颜色 C:

δi = ti −ti−1 是相邻样本之间的距离。这个过程是完全可微的。因此,在计算与每条光线相关的预测颜色和地面真实颜色之间的均方误差 (MSE) 之后,我们可以将梯度反向传播到辐射场。
基于体素的特征场如NSVF [31] 等将场景表示为体素网格和 MLP。体素网格的每个网格点都分配有一个可训练向量。有八个特征向量与单个体素相关联,但这些向量在相邻体素之间共享。对于沿射线采样的每个查询点,首先找到其对应的体素。然后通过基于查询点位置的体素网格点特征的三线性插值来计算该点的特征(参见图 3,左)。生成的特征向量通过 MLP 传递以预测密度和外观向量。外观向量与光线方向相结合并通过第二个 MLP 以计算视点相关颜色。

图 3. 三线和重心插值。三线性插值是八个体素角的加权组合。重心插值根据重心坐标对四面体顶点的四个顶点进行加权[16]。
3.2.四面体场
给定 3D 空间中的一组点,我们通过对这些点进行三角网剖分来构建四面体结构。我们应用 Delaunay 三角剖分 [14] 来获得一组非重叠四面体,其并集是原始点的凸包。图 2 显示了通过对密集和稀疏 COLMAP 重建点云进行三角测量获得的示例四面体 [52、53]。请注意,生成的表示是自适应的,因为它使用更靠近表面的高分辨率(更小的四面体)和更大的四面体来模拟远离表面的区域。
我们将四面体的所有顶点与可训练向量相关联。在体素网格的情况下,顶点和向量在相邻的四面体之间共享。可以用查询体素网格表示的相同方式查询生成的四面体场:
对于每个查询点,我们首先找到包含该点的四面体。我们使用重心插值 [16] 从存储在四面体顶点的四个特征向量计算查询点的特征向量,而不是用于体素体积的三线性插值(参见图 3)。为此,我们计算查询点 x 的重心坐标 λ,它将点的 3D 坐标表示为四面体顶点的 3D 坐标的唯一加权组合。特别地,顶点的权重是由查询点和与顶点相对的面构造的四面体的体积除以整个四面体的体积:

其中 V1234 是整个四面体的体积,Vx234, V1x34, . . . , 是具有第 1、第 2、. . . , 顶点替换为 x。可以将相同的权重λ应用于顶点的特征向量以获得查询特征。
插值特征用作小型 MLP 的输入,以预测查询点的密度和颜色。我们首先通过三层 MLP 传递重心插值特征来计算密度和外观特征。然后,我们将外观特征与使用傅立叶特征 [38, 56] 编码的光线方向矢量连接起来,并将结果通过单个线性层传递以获得原始 RGB 颜色值。
最后,为了将网络返回的原始密度值 ̄ σi 映射到体积渲染所需的体积密度 σi,我们应用 softplus 激活函数 [3]。对于 RGB 颜色值,我们使用 sigmoid 函数 [17]。
3.3.高效查询四面体场
可以通过哈希[41]高效地确定给定查询点的相应体素。相比之下,为查询点找到对应的四面体更为复杂。这反过来会显着影响渲染,从而影响训练效率 [17、40、54]。
为了有效地查找相应的四面体,我们利用了我们不是在考虑孤立点,而是从光线中采样的点的想法。我们计算与光线相交的四面体,允许我们穿过四面体而不是逐点单独计算它们。可以使用加速结构有效地找到相关的四面体,以进行快速光线-三角形相交计算,例如,通过 NVidia 的 OptiX 库 [42]:我们首先计算来自合成视图的光线与四面体的所有面之间的交点。对于每条射线,我们取前 512 个相交的三角形(为了效率,我们只考虑固定数量的三角形。正如稍后所讨论的,这会降低较大场景/具有细粒度四面体化的场景的结果,其中需要更多的交叉点。当然,可以以更长的运行时间为代价考虑更多的三角形) ,并确定相应的四面体。可以根据沿光线的交点对四面体进行排序,使我们能够轻松地遍历四面体以确定给定查询点使用哪个四面体。
计算光线-三角形交点的一个附带好处是我们可以简化重心坐标的计算:对于每个交点,我们计算 三角形的2D 重心坐标 w.r.t.。然后我们获得 3D 重心坐标 w.r.t.通过简单地为与三角形相对的顶点添加零来关联四面体。对于四面体内部的查询点,我们可以通过在射线和四面体的两个交点的重心坐标之间进行线性插值来计算其四面体重心坐标。
3.4.粗细采样
我们遵循采用两阶段抽样程序的常见做法 [9、38]。在粗采样阶段,我们沿射线均匀采样。在精细阶段,我们使用粗采样阶段的密度权重将采样偏向更接近潜在表面的采样。在[38]之后,我们在粗阶段使用分层均匀采样。分层均匀采样将光线分成等长的间隔,并在每个间隔内均匀采样。与 NeRF [38] 不同,我们将采样限制在四面体占据的空间内。在精细采样阶段,我们使用与粗采样阶段相同的网络。
对于精细采样阶段,我们从粗采样中获取累积权重 wi:

这些权重是等式 1 中用作颜色乘数的系数 [38]。我们通过归一化 ̄ wi 获得 wi 。在 [38] 之后,我们使用权重 wi 对一组精细样本进行采样。为了渲染最终的颜色,我们合并了密集样本和精细样本,并在渲染方程 [9] 中全部使用。
4. 实验
我们将 Tetra-NeRF 与常用的 Blender 数据集 [38]、真实世界的 Tanks and Temples 数据集 [25] 以及具有挑战性的以对象为中心的 mip-NeRF 360 数据集 [4] 上的相关方法进行了比较。为了证明其有效性,我们将 Tetra-NeRF 与密集网格表示进行比较,并在输入点云质量降低的情况下对其进行评估。我们首先描述所使用的特定超参数。
4.1.实施细节
点云生成和三角构网
给定一组姿势图像,我们使用 COLMAP 重建管道 [52、53] 来获取在我们的四面体场表示中使用的点云。然后我们减小生成的点云的大小,如果点数大于 106,我们随机抽取 106 个点。对于点数较少的 Blender 数据集实验,我们添加了更多随机生成的点。在那种情况下,随机点的数量是原始点数量的一半。添加点的原因是点数较少时,边缘上的某些像素可能不会与任何四面体相交,从而可能在边缘上产生伪像。每个添加的点采样如下:我们从原始点云中采样一个随机点x0,采样一个随机法向量n,和一个数α∼N(̄d,̄d2),其-d是点云的平均间距原始点云,即每个点与其六个最近邻点之间的平均距离。然后我们添加点 x = x0 + αn。
初始化
给定处理后的点云,我们应用 Delaunay 三角构网 [14] 来获得一组四面体。为此,我们使用 CGAL 库 [2],它在我们的实验中以毫秒为单位运行。在 [40] 之后,我们在四面体的顶点处初始化大小为 64 的特征,并在 -10-4到 10-4 的范围内均匀采样小值。然而,为了让模型复用点云中包含的信息,我们将特征字段的前四个维度设置为存储在点云中关联点的 RGBA 颜色值(重新缩放到区间 [0, 1]) .所有原始点的 alpha 值为 1,而所有随机采样点的 alpha 值为零。对于 MLP,我们遵循使用 Kaiming 统一初始化 [19] 的常见做法。所有 MLP 中的隐藏大小都是 128。
训练
在训练过程中,我们从随机训练图像中抽取了 4096 条随机射线。我们使用体积渲染来预测每条光线的颜色。通过在预测颜色和地面真实颜色值之间反向传播 MSE 损失来计算梯度。我们使用 RAdam 优化器 [32] 并在 300k 步中以指数方式将学习率从 10−3衰减到 10−4。训练代码建立在 Nerfstudio 框架 [57] 之上,四面体场在 CUDA 中实现并使用 OptiX 库 [42]。我们在单个 NVIDIA A100 GPU 上训练,训练速度范围从每秒 15k 条射线到每秒 30k 条射线。速度取决于三角换分的结构有多好、有多少个顶点以及对象周围是否有空白空间。 300k 次迭代的完整训练需要 11 到 24 小时,具体取决于场景的复杂性。然而,好的结果通常会在更早的时候获得,例如, 100k 次迭代。
4.2 评估
- Blender dataset [38] results.
我们与标准 Blender 数据集上的相关基线进行比较。我们使用与原始 NeRF 论文 [38] 相同的拆分和评估程序,以及与 PointNeRF [67] 相同的 SSIM 实现。为了确保在使用 COLMAP 点时与 PointNeRF [67] 进行公平比较,我们使用与 Point-NeRF 完全相同的 COLMAP 重建。我们报告 PSNR、SSIM 和 LPIPS (Vgg) [75] 指标。标签。表 1 显示平均结果,图 4 显示定性结果,补充矩阵 显示单个场景的结果。

表 1. Blender 数据集 [38] 对数据集中所有场景的平均结果。即使我们使用与 Point-NeRFcol相同的输入点云,我们的表现也大大优于它。我们的表现与 Point-NeRFmvs 相当,尽管它使用更多的点并在训练期间使点云更加密集。我们突出显示 best (红)、 second (橙) 和 third (黄) 值。

图 4.Blender 数据集的定性结果。我们与 Point-NeRFcol 进行比较,因为我们使用相同的输入点云。在上面的图片中,我们可以看到 Tetra-NeRF 能够很好地表现麦克风场景中的细节。在鼓场景(中)中,两种方法都难以处理闪亮的材料,但我们的方法表现稍好。在底部,Tetra-NeRF 可以渲染细绳。
当我们使用与 PointNeRF(行 Point-NeRFcol)完全相同的 COLMAP 点时,我们在所有三个指标上都优于它。我们的得分与 Point-NeRFmvs 相当,尽管它使用质量更高的初始点云,它是从联合训练的模型中生成的。另请注意,这两种 Point-NeRF 配置在训练期间都会增加点云,因此,场景表示的复杂性也会增加。对我们来说,点是固定的,参数的数量保持不变。我们还优于使用稀疏网格的 Plenoxels [17]。请注意,与 Point-NeRF 一样,Plenoxels 也通过在预定义的训练时期细分网格分辨率来逐渐增加表示的复杂性。尽管 mipNeRF 和 instant-NGP 在 PSNR 方面都优于我们的方法,但我们的方法在 SSIM 方面略胜一筹,在 LPIPS 方面与 mip-NeRF 相当。
为了分析四面体场表示,我们将其与 Point-NeRF 中使用的点云场表示进行比较。在表 2 中,当我们禁用点云增长和修剪时,我们将我们的方法与 PointNeRF 进行了比较。我们展示了在 Point-NeRF 论文中选择的 Blender 数据集 [38] 的两个场景的结果。通过这种设置,我们在所有指标上都大大优于 Point-NeRF。原因是 Point-NeRF 要求点云密集,这样所有光线都有机会与点的邻域相交。由于我们使用连续表示(四面体场)而不是离散表示,因此即使对于较稀疏的点云,我们也可以获得良好的结果。

表 2. 与禁用点云增长和修剪的 Point-NeRF 的比较表明,Point-NeRF 在所有测量指标中的表现明显更差,因为它无法处理稀疏点云。

图 5. 与密集网格场表示的比较。左侧为 Tetra-NeRF,右侧为密集网格。我们对这两种方法使用了相同数量的参数,但是,由于四面体场的自适应特性,Tetra-NeRF 产生了明显更好的渲染,因为它能够专注于场景的相关部分。
与密集网格表示的比较
- 与密集网格表示的比较
为了显示自适应四面体场表示的效用,我们将其与密集网格表示进行比较。与 NSVF [31] 类似,我们将 3D 场景边界框拆分为大小相等的体素。在查询字段时,我们找到查询点所属的体素,并对体素的八个角进行三线性插值。为了确保公平比较,我们选择网格分辨率,使得网格点数是大于原始点云点数的最小立方体数。所有其他超参数与 TetraNeRF 保持相同。我们在 Blender 数据集 [38] 的两个场景上评估这两种方法。密集网格表示在乐高和轮船场景中的 PSNR 分别仅为 18.81 和 18.91,而 Tetra-NeRF 的 PSNR 分别为 33.79 和 30.69。结果如图 5 所示。请注意,在本实验中,我们仅训练了 100、000 次迭代以节省计算时间。从数字和图中,我们可以清楚地看到密集的网格分辨率不足以足够详细地重建场景。因为 Tetra-NeRF 使用自适应细分,在表面周围更加详细,我们能够更好地关注相关场景部分。使用相同数量的可训练参数,我们因此获得了更好的结果。
- Tanks and Temples [25] 数据集

表 3. 由 NSVF [31] 处理的 Tanks and Temples 数据集 [25] 的结果在所有场景中取平均值。我们展示了 PSNR、SSIM 和 LPIPS (Alex) [75] 指标。Point-NeRF [67] 结果与论文不同,因为它们是使用其他方法中使用的分辨率重新计算的。
为了能够与真实世界数据上的 Point-NeRF [67] 进行比较,我们在 Tanks and Temples [25] 数据集上评估了 Tetra-NeRF。我们使用与 NSVF [31] 中相同的设置,其中对象被屏蔽。我们报告常用指标:PSNR、SSIM、LPIPS (Alex)3 我们使用密集 COLMAP 重建来获取四面体场中使用的点云。定量结果如表 3 所示,定性结果如图 6 所示,每个场景的结果在补充中给出。垫。请注意,最初在 Point-NeRF 论文 [67] 中报告的结果是使用与比较方法不同的分辨率进行评估的。因此,为了确保公平比较,我们重新计算了公开可用的 Point-NeRF 预测中的指标,其全分辨率为 NSVF [31] 中使用的 1920 × 1080。

图 6. Tanks and Temples 数据集的结果。在顶行,我们可以看到我们能够比 Point-NeRF 更好地表示车轮的轮缘。同样,我们可以在第三行更好地表示轮胎。最后,在底部,Point-NeRF 在墙壁和屋顶上失败,而 Tetra-NeRF 可以很好地渲染这些部分。
在公共数据集中,其中一个场景的相机参数已损坏,我们不得不为 Ignatius 场景再次重建姿势。使用重建的姿势,与其他场景相比,我们的方法在该场景中的表现稍差。结果表明,我们的方法在所有比较指标中都优于基线。这表明即使 Point-NeRF 依赖于在训练期间增加点云密度的能力,但在使用连续而不是离散表示时不需要这样做。
- 稀疏和密集点云比较

图 7. 稀疏与密集模型比较细节。即使底部区域包含的点很少,我们仍然能够至少重建低频数据。
以前的实验使用了密集的 COLMAP 重建。然而,可能不需要密集的点云来实现良好的重建。在本节中,我们比较了在密集重建和稀疏重建上训练的模型。表 5 比较了来自 Blender 数据集 [38] 的两个合成场景和来自 mip-NeRF 360 数据集 [4] 的两个真实场景的 PSNR、SSIM 指标。我们还显示了四面体的顶点数,即输入点云的大小,包括在开始时添加的随机点。请注意,在这个实验中,我们只训练了 100、000 次迭代以节省计算时间。
从结果中我们可以看出,对于 Blender 数据集 [38] 的情况,密集模型要好得多。这是意料之中的,因为从 Blender 数据集上的稀疏重建获得的点数非常少,而且我们的 MLP 没有足够的能力来表示精细的细节。然而,即使在零点覆盖的区域,我们仍然能够提供至少一些低频数据(参见图 7)。在真实场景中,稀疏点云模型几乎与密集点云模型相当。与合成数据集的情况相比,真实世界数据集上的稀疏重建提供了更多的点,并且覆盖范围足够。从这些结果中,我们得出结论,在真实世界的数据上,稀疏模型足以实现良好的性能。
- Mip-NeRF 360 [4] 数据集

图 8.Mip-NeRF 360 结果。第一行:我们在花园场景中展示了结果。中排:我们可以看到 Tetra-NeRF 在渲染草地时存在一些问题。下排:Tetra-NeRF 能够很好地表现桌布的细腻质感。
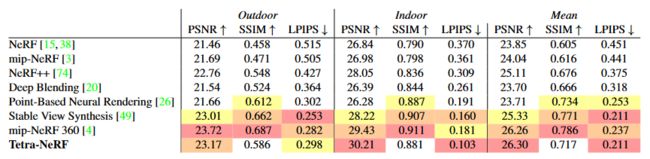
表 4. Mip-NeRF 360 数据集结果。我们在两类 mip-NeRF 360 [4] 场景:室外和室内展示了 PSNR、SSIM 和 LPIPS (Alex) [75]。在户外场景中,我们的表现优于稳定视图合成 [49] 并且与 mip-NeRF 360 [4] 相当,尽管我们的方法没有实现 NeRF++ [74] 和 mip-NeRF 360 [4] 中建议的改进,但与普通的 NeRF [38] 更具可比性。
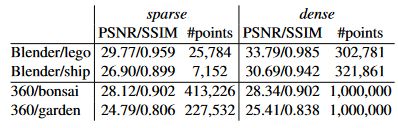
表 5. 密集和稀疏点云比较。我们展示了来自 Blender [38] 和 mip-NeRF 360 [4] 数据集的两个场景的结果。我们还显示了四面体场的顶点数,包括随机采样点。
我们在 mip-NeRF 360 [4] 数据集上进一步评估了我们的方法。为了确保与 mip-NeRF 360 [4] 进行公平比较,我们对室外场景的四倍缩小图像和室内场景的两倍缩小图像进行了训练和评估。定量结果如表 4 所示,定性结果如图 8 所示。
从结果我们可以看出,Tetra-NeRF 能够胜过 vanilla NeRF [38] 和 mip-NeRF [3]。我们在 PSNR 方面也优于 Stable View Synthesis [49],在 LPIPS 方面得分相当。这是可能的,因为室外场景包含许多高分辨率几何图形,例如树叶,而稳定视图合成无法克服近似几何图形中的噪声。 TetraNeRF 不会遇到这些问题,因为我们沿着射线而不是表面聚合 3D 特征。 MipNeRF 360 在 PSNR 和 LPIPS 方面的得分与 Tetra-NeRF 相当,但在 SSIM 方面优于 Tetra-NeRF。然而,mip-NeRF 360 实施了一些旨在提高其性能的技巧。另一方面,我们的方法基于 vanilla NeRF,我们相信性能可以得到类似的提升。
5. 局限

图 9. 失败案例。左图:来自 [25] 的谷仓场景。右图:[4] 中的树山场景。
我们方法的一个缺点是渲染场景不同区域的质量取决于这些区域中点云的密度。如果原始点云是使用 2D 特征匹配构建的,则可能存在 3D 点数非常少的区域。我们在图 9(a)中展示了这样一个例子。地面上几乎没有 3D 点,导致该区域的渲染模糊。另一个问题是当前的实现对每条射线的相交四面体数量有限制。对于光线与许多四面体相交的大型或结构不良的场景,这会限制重建质量。图 9(b)显示了 mip-NeRF 360 场景中的这种情况 [4]。这个问题可以通过增加访问四面体数量的限制来解决,但代价是更高的内存需求和运行时间。或者,从更粗略的四面体化开始并修剪空间的粗到细方案可能会解决这个问题。
6. 结论
本文提出了一种新颖的辐射场表示,与标准的基于体素的表示相比,它很容易适应以(稀疏)点云形式给出的 3D 几何先验。我们的方法优雅地将几何处理(Delaunay 三角剖分)和基于三角形的渲染(光线-三角形相交)的概念与现代神经渲染方法相结合。该表示在表面附近的空间中天然具有更高的分辨率,并且输入点云提供了一种初始化辐射场的直接方法。与使用与我们的方法相同的输入的最先进的基于点云的辐射场表示 PointNeRF 相比,Tetra-NeRF 显示出明显更好的结果。我们的方法的性能与最先进的基于 MLP 的方法相当。结果表明,Tetra-NeRF 是现有辐射场表示的有趣替代方案,值得进一步研究。有趣的研究方向包括四面体化的自适应细化和修剪,以及利用场景表面可能靠近场景中的某些三角形这一事实。
抛砖
- 主要工作都在渲染方面,其粗细采样倒是有点意思,但肯定非常受限于点云质量,例如点云(在水面等弱纹理区域)缺了一块,那其采样约束就不太对了。
- 其四面体场的自适应特性,以及在表面附近的空间中天然具有更高的分辨率的特点很有意思。但其计算量显然比体素方法大得多,但没有看到时间方面的具体比较,效率有待验证。