预测分析·员工满意度预测(传统回归机器学习方法梭哈!)
(本文将以预测员工满意度为背景,使用MSE为衡量标准,尝试各种非集成或者集成的模型,包括:线性回归,KNN,SVM,回归树,随机森林,AdaBoost,GBRT,Xgboost)
最近玩了一下这个新手赛,顺便总结一下学过的传统机器学习方法(回归)
赛题具体如下
链接: link.
赛题&数据
赛题
员工满意度又称雇员满意度,是团队精神的一种参考,也就是个体对他所从事的工作的一般态度。是组织成员对其工作特征的认知评价,是员工通过比较实际获得的价值与期望获得的价值之间的差距后,对工作各方面满足与否的态度和情绪反映。通过持续的员工满意度调查,企业可以对自身管理中所存在的问题进行“诊断”,进而系统地解决问题,改善企业的管理,提高生产效率、降低人员流失率。因此,科学的员工满意度分析对于提高企业管理的有效性意义重大。
本次练习赛基于员工的满意度调查与员工的基本信息和工作经历,预测员工对于公司的满意度情况。
数据说明
本次练习赛所使用数据集基于人力资源分析数据集,并且针对部分字段做出了一定的调整,所有的字段信息请以本练习赛提供的字段信息为准,字段信息内容参考如下:
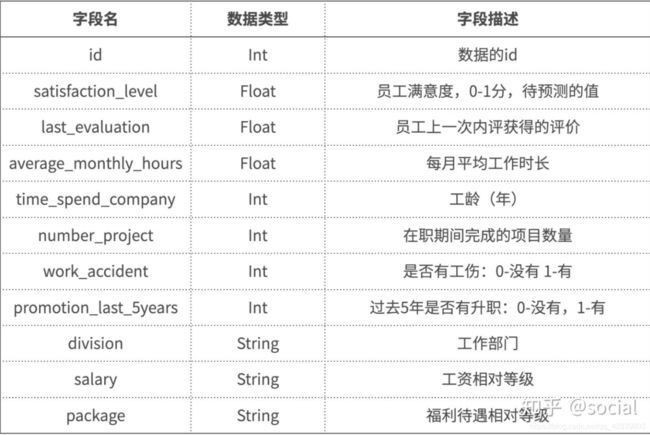
数据放在百度云啦!
链接: https://pan.baidu.com/s/1StTWTHAz4GHpezIiwh5Rmw 密码: uqlc
下面开始整!
import pandas as pd
import numpy as np
from sklearn import ensemble
train = pd.read_csv('训练集.csv')
test11 = pd.read_csv('测试集.csv')
train
#得到如下所示的数据
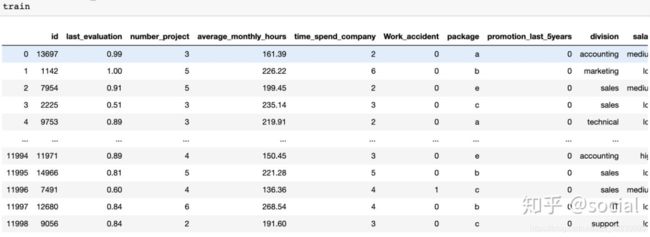
为了对中文读者更加友好,将特征转化为中文:
col = ['id','上次评分','项目数量','平均月工时','工龄','工伤','福利等级','五年内有升职','部门','工资水平','满意度']
name = {i:j for i , j in zip(train.columns, col)}
data= train.rename(columns = name)
test11 = test11.rename(columns = name)
#划分训练集和测试集
#划分训练集和测试集
from sklearn.model_selection import train_test_split
x_train , x_test , y_train ,y_test = train_test_split(data.iloc[:,:-1],data.iloc[:,-1:] , test_size = 0.3 ,random_state = 88 )
#random_state取值还是要吉利一点的呀!哈哈哈!
数据预处理(序数序列编码,one-hot编码):
#数据预处理函数
from sklearn.preprocessing import OrdinalEncoder, OneHotEncoder
#对x_train进行处理得到x_train_final
def process_data(data1):
#序数序列
data1[['福利等级','工资水平']] = OrdinalEncoder().fit_transform(data1[["福利等级" , "工资水平"]])
#one-hot编码
oh = OneHotEncoder()
result = oh.fit_transform(data1[["部门"]])
re = pd.DataFrame(result.toarray(),columns = oh.categories_[0] ,
index = data1.index
)
data1_final = pd.concat([data1, re],axis = 1)
data1_final.drop('部门',inplace = True,axis = 1)
data1_final.drop('id',inplace = True,axis = 1)
return data1_final
x_train_final = process_data(x_train)
x_test_final = process_data(x_test)
#得到数据如下所示
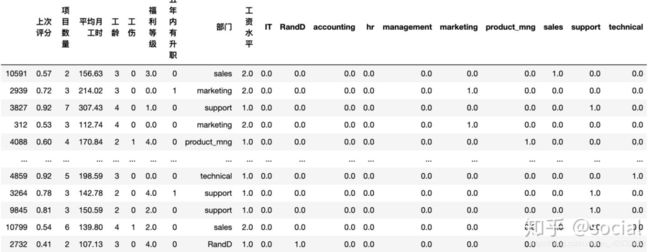
#一切从简,跳过数据初探,特征工程,数据标准化,十折交叉验证,算法集成
下面开始训练模型和预测(梭哈开始啦!):
先从最经典的线性回归开始!
from sklearn.linear_model import LinearRegression , LassoCV,RidgeCV=
lr = LinearRegression()
lr.fit(x_train_final , y_train)
# print(lr.score(xtest_new1,ytest))
print('MSE:',mean_squared_error(y_test ,lr.predict(x_test_final)))
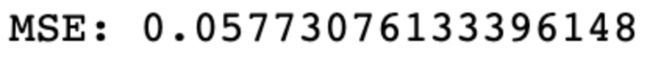
#ridge是l2正则化的线性回归,lasso则是带l1正则化的线性回归。
la = LassoCV()
la.fit(x_train_final , y_train)
# lr.score(xtrain_new1,ytrain)
# print(lr.score(xtest_new1,ytest))
print('MSE:',mean_squared_error(y_test ,la.predict(x_test_final)))
![]()
Rg = RidgeCV()
Rg.fit(x_train_final , y_train)
# lr.score(xtrain_new1,ytrain)
# print(lr.score(xtest_new1,ytest))
print('MSE:',mean_squared_error(y_test ,Rg.predict(x_test_final)))
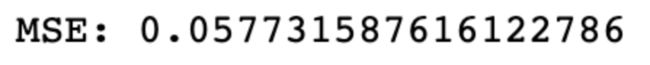
三个线性回归的均方误差都不高呀!
第二位就有请我们的KNN啦:
from sklearn import neighbors
knn = neighbors.KNeighborsRegressor()
knn.fit(x_train_final , y_train)
print("测试集上的MSE:",mean_squared_error(y_test,knn.predict(x_test_final)))
![]()
KNN有所提升!
#第三位来看看大名鼎鼎的SVM啦(这哥们当年可是风头盖过神经网络的存在呀!)
#SVM模型
from sklearn.svm import SVR
svr = SVR()
svr.fit(x_train_final,y_train)
print("测试集上的MSE:",mean_squared_error(y_test,svr.predict(x_test_final)))
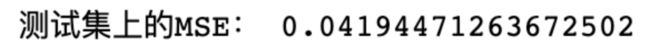
又有一点提升,不过和KNN相差无几(可见KNN虽然原理朴素,但确实好用呀!)
第四个就来回归树吧!
回归树预测
from sklearn import tree
tree_reg = tree.DecisionTreeRegressor()
tree_reg.fit(x_train_final , y_train)
print("测试集上的MSE:",mean_squared_error(y_test,rfr.predict(x_test_final)))
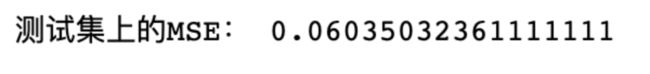
回归树丢脸丢到家了!竟然连线性回归干不过?
下面使用集成算法:
#首先登场的是我们可爱的随机森林呀
#随机森林
rfr = RandomForestRegressor(n_estimators=1000,n_jobs=-1)
rfr.fit(x_train_final , y_train)
from sklearn.metrics import mean_squared_error
print("测试集上的MSE:",mean_squared_error(y_test,rfr.predict(x_test_final)))

终于给回归树出了一口恶气,可见集成就是牛皮呀!
下面的是AdaBoost:
ada = ensemble.AdaBoostRegressor(n_estimators=50)
ada.fit(x_train_final , y_train)
print("测试集上的MSE:",mean_squared_error(y_test,ada.predict(x_test_final)))
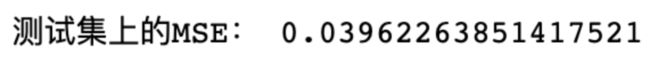
下面是GBRT:
gbrt = ensemble.GradientBoostingRegressor(n_estimators=100)
gbrt.fit(x_train_final , y_train)
print("测试集上的MSE:",mean_squared_error(y_test,gbrt.predict(x_test_final)))

#下面是著名的竞赛女神Xgboost啦
# !pip install xgboost
#上述下载方式实在过于麻烦
#用这个,一步到位
#conda install py-xgboost
from xgboost import XGBRegressor
xgb = XGBRegressor()
xgb.fit(x_train_final,y_train)
print('MSE:',mean_squared_error(y_test ,xgb.predict(x_test_final)))
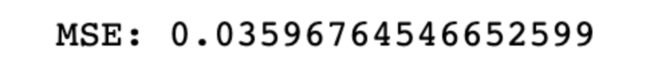
这里我们尝试一下网格搜索
#这里用网格搜索来进一步确定参数值
from sklearn.model_selection import GridSearchCV
xgb1 = XGBRegressor()
pxgb1 = {'learning_rate':[0.01,0.04,0.07,0.10],
'min_child_weight':[1,0.9,0.8,0.7,0.5]}
gscv1 = GridSearchCV(xgb1,pxgb1,n_jobs = -1 , scoring ="neg_mean_squared_error")
gscv1.fit(x_train_final ,y_train)
gscv1.best_score_

gscv1.best_params_
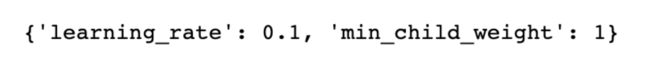
综上还是随机森林牛皮,0.335(当然随着测试集划分的不同也会有不同的变化,大家看着乐就行啦!)