小白备战大厂算法笔试(四)——哈希表
文章目录
- 哈希表
-
- 常用操作
- 简单实现
- 冲突与扩容
- 链式地址
- 开放寻址
-
- 线性探测
- 多次哈希
哈希表
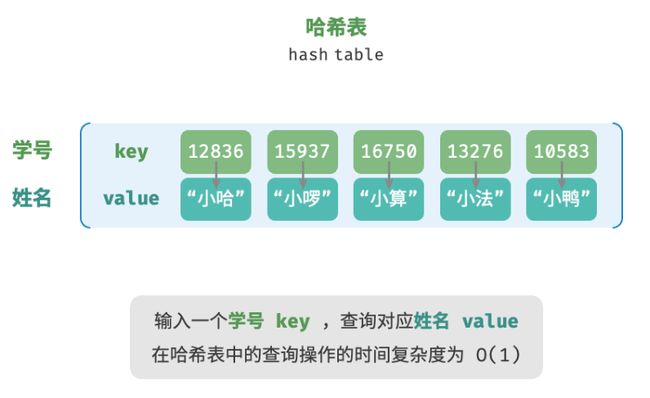
哈希表,又称散列表,其通过建立键 key 与值 value 之间的映射,实现高效的元素查询。具体而言,我们向哈希表输入一个键 key ,则可以在 O(1) 时间内获取对应的值 value 。
除哈希表外,数组和链表也可以实现查询功能,它们的效率对比如下所示。
- 添加元素:仅需将元素添加至数组(链表)的尾部即可,使用 O(1) 时间。
- 查询元素:由于数组(链表)是乱序的,因此需要遍历其中的所有元素,使用 O(n) 时间。
- 删除元素:需要先查询到元素,再从数组(链表)中删除,使用 O(n) 时间。
| 数组 | 链表 | 哈希表 | |
|---|---|---|---|
| 查找元素 | O(n) | O(n) | O(1) |
| 添加元素 | O(1) | O(1) | O(1) |
| 删除元素 | O(n) | O(n) | O(1) |
在哈希表中进行增删查改的时间复杂度都是 O(1) ,非常高效。
常用操作
Python:
# 初始化哈希表
hmap: dict = {}
# 添加操作
# 在哈希表中添加键值对 (key, value)
hmap[12836] = "小哈"
hmap[15937] = "小啰"
hmap[16750] = "小算"
hmap[13276] = "小法"
hmap[10583] = "小鸭"
# 查询操作
# 向哈希表输入键 key ,得到值 value
name: str = hmap[15937]
# 删除操作
# 在哈希表中删除键值对 (key, value)
hmap.pop(10583)
# 遍历哈希表
# 遍历键值对 key->value
for key, value in hmap.items():
print(key, "->", value)
# 单独遍历键 key
for key in hmap.keys():
print(key)
# 单独遍历值 value
for value in hmap.values():
print(value)
Go:
/* 初始化哈希表 */
hmap := make(map[int]string)
/* 添加操作 */
// 在哈希表中添加键值对 (key, value)
hmap[12836] = "小哈"
hmap[15937] = "小啰"
hmap[16750] = "小算"
hmap[13276] = "小法"
hmap[10583] = "小鸭"
/* 查询操作 */
// 向哈希表输入键 key ,得到值 value
name := hmap[15937]
/* 删除操作 */
// 在哈希表中删除键值对 (key, value)
delete(hmap, 10583)
/* 遍历哈希表 */
// 遍历键值对 key->value
for key, value := range hmap {
fmt.Println(key, "->", value)
}
// 单独遍历键 key
for key := range hmap {
fmt.Println(key)
}
// 单独遍历值 value
for _, value := range hmap {
fmt.Println(value)
}
简单实现
先考虑最简单的情况,仅用一个数组来实现哈希表。在哈希表中,我们将数组中的每个空位称为桶,每个桶可存储一个键值对。因此,查询操作就是找到 key 对应的桶,并在桶中获取 value 。
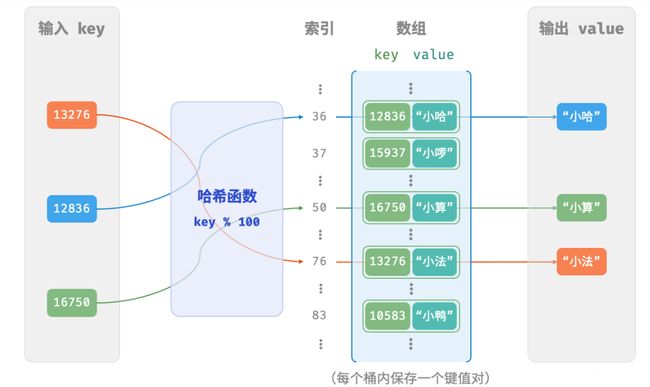
那么,如何基于 key 来定位对应的桶呢?这是通过「哈希函数 hash function」实现的。哈希函数的作用是将一个较大的输入空间映射到一个较小的输出空间。在哈希表中,输入空间是所有 key ,输出空间是所有桶(数组索引)。换句话说,输入一个 key ,我们可以通过哈希函数得到该 key 对应的键值对在数组中的存储位置。
输入一个 key ,哈希函数的计算过程分为以下两步。
- 通过某种哈希算法
hash()计算得到哈希值。 - 将哈希值对桶数量(数组长度)
capacity取模,从而获取该key对应的数组索引index。
index = hash(key) % capacity
随后,我们就可以利用 index 在哈希表中访问对应的桶,从而获取 value 。
设数组长度 capacity = 100、哈希算法 hash(key) = key ,易得哈希函数为 key % 100 。以 key 学号和 value 姓名为例,展示哈希函数的工作原理:
以下代码实现了一个简单哈希表。其中,我们将 key 和 value 封装成一个类 Pair ,以表示键值对。
Python:
class Pair:
"""键值对"""
def __init__(self, key: int, val: str):
self.key = key
self.val = val
class ArrayHashMap:
"""基于数组简易实现的哈希表"""
def __init__(self):
"""构造方法"""
# 初始化数组,包含 100 个桶
self.buckets: list[Pair | None] = [None] * 100
def hash_func(self, key: int) -> int:
"""哈希函数"""
index = key % 100
return index
def get(self, key: int) -> str:
"""查询操作"""
index: int = self.hash_func(key)
pair: Pair = self.buckets[index]
if pair is None:
return None
return pair.val
def put(self, key: int, val: str):
"""添加操作"""
pair = Pair(key, val)
index: int = self.hash_func(key)
self.buckets[index] = pair
def remove(self, key: int):
"""删除操作"""
index: int = self.hash_func(key)
# 置为 None ,代表删除
self.buckets[index] = None
def entry_set(self) -> list[Pair]:
"""获取所有键值对"""
result: list[Pair] = []
for pair in self.buckets:
if pair is not None:
result.append(pair)
return result
def key_set(self) -> list[int]:
"""获取所有键"""
result = []
for pair in self.buckets:
if pair is not None:
result.append(pair.key)
return result
def value_set(self) -> list[str]:
"""获取所有值"""
result = []
for pair in self.buckets:
if pair is not None:
result.append(pair.val)
return result
def print(self):
"""打印哈希表"""
for pair in self.buckets:
if pair is not None:
print(pair.key, "->", pair.val)
Go:
/* 键值对 */
type pair struct {
key int
val string
}
/* 基于数组简易实现的哈希表 */
type arrayHashMap struct {
buckets []*pair
}
/* 初始化哈希表 */
func newArrayHashMap() *arrayHashMap {
// 初始化数组,包含 100 个桶
buckets := make([]*pair, 100)
return &arrayHashMap{buckets: buckets}
}
/* 哈希函数 */
func (a *arrayHashMap) hashFunc(key int) int {
index := key % 100
return index
}
/* 查询操作 */
func (a *arrayHashMap) get(key int) string {
index := a.hashFunc(key)
pair := a.buckets[index]
if pair == nil {
return "Not Found"
}
return pair.val
}
/* 添加操作 */
func (a *arrayHashMap) put(key int, val string) {
pair := &pair{key: key, val: val}
index := a.hashFunc(key)
a.buckets[index] = pair
}
/* 删除操作 */
func (a *arrayHashMap) remove(key int) {
index := a.hashFunc(key)
// 置为 nil ,代表删除
a.buckets[index] = nil
}
/* 获取所有键对 */
func (a *arrayHashMap) pairSet() []*pair {
var pairs []*pair
for _, pair := range a.buckets {
if pair != nil {
pairs = append(pairs, pair)
}
}
return pairs
}
/* 获取所有键 */
func (a *arrayHashMap) keySet() []int {
var keys []int
for _, pair := range a.buckets {
if pair != nil {
keys = append(keys, pair.key)
}
}
return keys
}
/* 获取所有值 */
func (a *arrayHashMap) valueSet() []string {
var values []string
for _, pair := range a.buckets {
if pair != nil {
values = append(values, pair.val)
}
}
return values
}
/* 打印哈希表 */
func (a *arrayHashMap) print() {
for _, pair := range a.buckets {
if pair != nil {
fmt.Println(pair.key, "->", pair.val)
}
}
}
冲突与扩容
本质上看,哈希函数的作用是将所有 key 构成的输入空间映射到数组所有索引构成的输出空间,而输入空间往往远大于输出空间。因此,理论上一定存在“多个输入对应相同输出”的情况。
对于上述示例中的哈希函数,当输入的 key 后两位相同时,哈希函数的输出结果也相同。例如,查询学号为 12836 和 20336 的两个学生时,我们得到:
12836 % 100 = 36
20336 % 100 = 36
两个学号指向了同一个姓名,这显然是不对的。我们将这种多个输入对应同一输出的情况称为哈希冲突 。
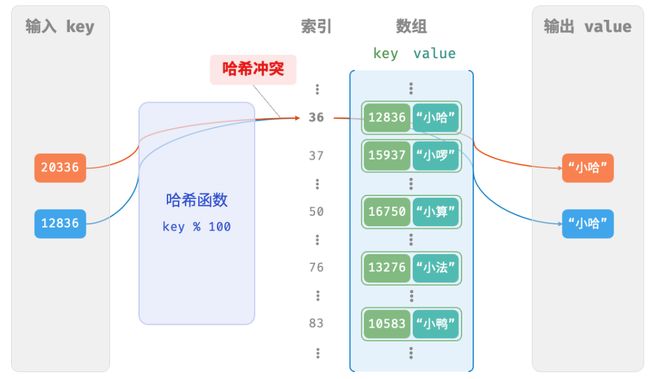
容易想到,哈希表容量n越大,多个 key 被分配到同一个桶中的概率就越低,冲突就越少。因此,我们可以通过扩容哈希表来减少哈希冲突。
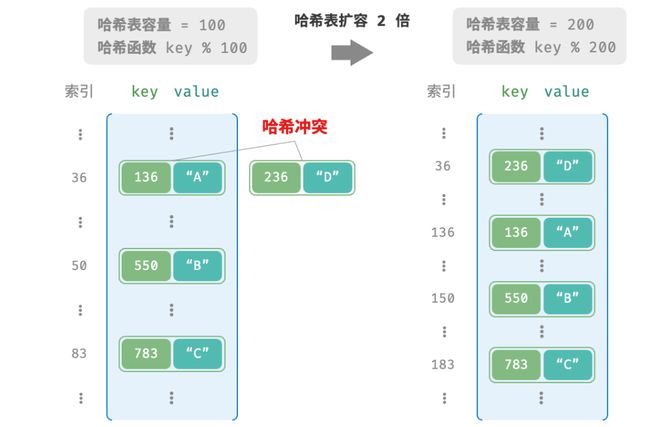
类似于数组扩容,哈希表扩容需将所有键值对从原哈希表迁移至新哈希表,非常耗时。并且由于哈希表容量 capacity 改变,我们需要通过哈希函数来重新计算所有键值对的存储位置,这进一步提高了扩容过程的计算开销。为了提升效率,我们可以采用以下策略。
- 改良哈希表数据结构,使得哈希表可以在存在哈希冲突时正常工作。
- 仅在必要时,即当哈希冲突比较严重时,才执行扩容操作。
哈希表的结构改良方法主要包括“链式地址”和“开放寻址”。
负载因子是哈希表的一个重要概念,其定义为哈希表的元素数量除以桶数量,用于衡量哈希冲突的严重程度,也常被作为哈希表扩容的触发条件。例如在 Java 中,当负载因子超过 0.75 时,系统会将哈希表容量扩展为原先的 2 倍。
链式地址
在原始哈希表中,每个桶仅能存储一个键值对。链式地址将单个元素转换为链表,将键值对作为链表节点,将所有发生冲突的键值对都存储在同一链表中。
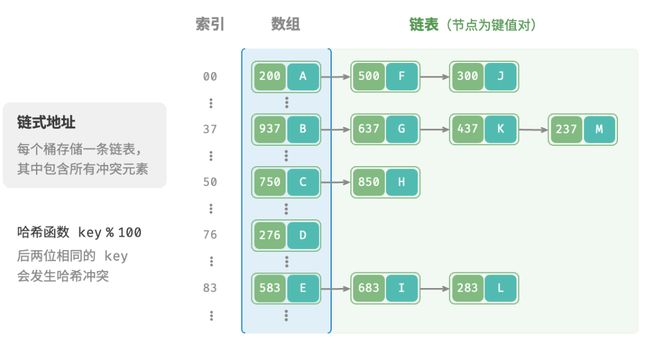
哈希表在链式地址下的操作方法发生了一些变化。
- 查询元素:输入
key,经过哈希函数得到数组索引,即可访问链表头节点,然后遍历链表并对比key以查找目标键值对。 - 添加元素:先通过哈希函数访问链表头节点,然后将节点(即键值对)添加到链表中。
- 删除元素:根据哈希函数的结果访问链表头部,接着遍历链表以查找目标节点,并将其删除。
链式地址存在以下局限性。
- 占用空间增大,链表包含节点指针,它相比数组更加耗费内存空间。
- 查询效率降低,因为需要线性遍历链表来查找对应元素。
以下代码给出了链式地址哈希表的简单实现,需要注意两点。
- 使用列表(动态数组)代替链表,从而简化代码。在这种设定下,哈希表(数组)包含多个桶,每个桶都是一个列表。
- 以下实现包含哈希表扩容方法。当负载因子超过 0.75 时,我们将哈希表扩容至 2 倍。
Python:
class HashMapChaining:
"""链式地址哈希表"""
def __init__(self):
"""构造方法"""
self.size = 0 # 键值对数量
self.capacity = 4 # 哈希表容量
self.load_thres = 2 / 3 # 触发扩容的负载因子阈值
self.extend_ratio = 2 # 扩容倍数
self.buckets = [[] for _ in range(self.capacity)] # 桶数组
def hash_func(self, key: int) -> int:
"""哈希函数"""
return key % self.capacity
def load_factor(self) -> float:
"""负载因子"""
return self.size / self.capacity
def get(self, key: int) -> str:
"""查询操作"""
index = self.hash_func(key)
bucket = self.buckets[index]
# 遍历桶,若找到 key 则返回对应 val
for pair in bucket:
if pair.key == key:
return pair.val
# 若未找到 key 则返回 None
return None
def put(self, key: int, val: str):
"""添加操作"""
# 当负载因子超过阈值时,执行扩容
if self.load_factor() > self.load_thres:
self.extend()
index = self.hash_func(key)
bucket = self.buckets[index]
# 遍历桶,若遇到指定 key ,则更新对应 val 并返回
for pair in bucket:
if pair.key == key:
pair.val = val
return
# 若无该 key ,则将键值对添加至尾部
pair = Pair(key, val)
bucket.append(pair)
self.size += 1
def remove(self, key: int):
"""删除操作"""
index = self.hash_func(key)
bucket = self.buckets[index]
# 遍历桶,从中删除键值对
for pair in bucket:
if pair.key == key:
bucket.remove(pair)
self.size -= 1
break
def extend(self):
"""扩容哈希表"""
# 暂存原哈希表
buckets = self.buckets
# 初始化扩容后的新哈希表
self.capacity *= self.extend_ratio
self.buckets = [[] for _ in range(self.capacity)]
self.size = 0
# 将键值对从原哈希表搬运至新哈希表
for bucket in buckets:
for pair in bucket:
self.put(pair.key, pair.val)
def print(self):
"""打印哈希表"""
for bucket in self.buckets:
res = []
for pair in bucket:
res.append(str(pair.key) + " -> " + pair.val)
print(res)
Go:
/* 链式地址哈希表 */
type hashMapChaining struct {
size int // 键值对数量
capacity int // 哈希表容量
loadThres float64 // 触发扩容的负载因子阈值
extendRatio int // 扩容倍数
buckets [][]pair // 桶数组
}
/* 构造方法 */
func newHashMapChaining() *hashMapChaining {
buckets := make([][]pair, 4)
for i := 0; i < 4; i++ {
buckets[i] = make([]pair, 0)
}
return &hashMapChaining{
size: 0,
capacity: 4,
loadThres: 2 / 3.0,
extendRatio: 2,
buckets: buckets,
}
}
/* 哈希函数 */
func (m *hashMapChaining) hashFunc(key int) int {
return key % m.capacity
}
/* 负载因子 */
func (m *hashMapChaining) loadFactor() float64 {
return float64(m.size / m.capacity)
}
/* 查询操作 */
func (m *hashMapChaining) get(key int) string {
idx := m.hashFunc(key)
bucket := m.buckets[idx]
// 遍历桶,若找到 key 则返回对应 val
for _, p := range bucket {
if p.key == key {
return p.val
}
}
// 若未找到 key 则返回空字符串
return ""
}
/* 添加操作 */
func (m *hashMapChaining) put(key int, val string) {
// 当负载因子超过阈值时,执行扩容
if m.loadFactor() > m.loadThres {
m.extend()
}
idx := m.hashFunc(key)
// 遍历桶,若遇到指定 key ,则更新对应 val 并返回
for _, p := range m.buckets[idx] {
if p.key == key {
p.val = val
return
}
}
// 若无该 key ,则将键值对添加至尾部
p := pair{
key: key,
val: val,
}
m.buckets[idx] = append(m.buckets[idx], p)
m.size += 1
}
/* 删除操作 */
func (m *hashMapChaining) remove(key int) {
idx := m.hashFunc(key)
// 遍历桶,从中删除键值对
for i, p := range m.buckets[idx] {
if p.key == key {
// 切片删除
m.buckets[idx] = append(m.buckets[idx][:i], m.buckets[idx][i+1:]...)
m.size -= 1
break
}
}
}
/* 扩容哈希表 */
func (m *hashMapChaining) extend() {
// 暂存原哈希表
tmpBuckets := make([][]pair, len(m.buckets))
for i := 0; i < len(m.buckets); i++ {
tmpBuckets[i] = make([]pair, len(m.buckets[i]))
copy(tmpBuckets[i], m.buckets[i])
}
// 初始化扩容后的新哈希表
m.capacity *= m.extendRatio
m.buckets = make([][]pair, m.capacity)
for i := 0; i < m.capacity; i++ {
m.buckets[i] = make([]pair, 0)
}
m.size = 0
// 将键值对从原哈希表搬运至新哈希表
for _, bucket := range tmpBuckets {
for _, p := range bucket {
m.put(p.key, p.val)
}
}
}
/* 打印哈希表 */
func (m *hashMapChaining) print() {
var builder strings.Builder
for _, bucket := range m.buckets {
builder.WriteString("[")
for _, p := range bucket {
builder.WriteString(strconv.Itoa(p.key) + " -> " + p.val + " ")
}
builder.WriteString("]")
fmt.Println(builder.String())
builder.Reset()
}
}
开放寻址
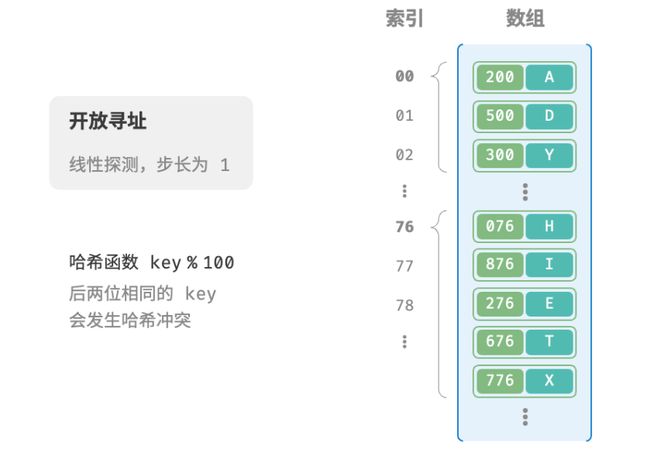
「开放寻址 open addressing」不引入额外的数据结构,而是通过“多次探测”来处理哈希冲突,探测方式主要包括线性探测、平方探测、多次哈希等。
线性探测
线性探测采用固定步长的线性搜索来进行探测,其操作方法与普通哈希表有所不同。
- 插入元素:通过哈希函数计算数组索引,若发现桶内已有元素,则从冲突位置向后线性遍历(步长通常为 1 ),直至找到空位,将元素插入其中。
- 查找元素:若发现哈希冲突,则使用相同步长向后线性遍历,直到找到对应元素,返回
value即可;如果遇到空位,说明目标键值对不在哈希表中,返回 None 。
下图展示了一个在开放寻址(线性探测)下工作的哈希表。
然而,线性探测存在以下缺陷。
- 不能直接删除元素。删除元素会在数组内产生一个空位,当查找该空位之后的元素时,该空位可能导致程序误判元素不存在。为此,通常需要借助一个标志位来标记已删除元素。
- 容易产生聚集。数组内连续被占用位置越长,这些连续位置发生哈希冲突的可能性越大,进一步促使这一位置的聚堆生长,形成恶性循环,最终导致增删查改操作效率劣化。
以下代码实现了一个简单的开放寻址(线性探测)哈希表。
- 我们使用一个固定的键值对实例
removed来标记已删除元素。也就是说,当一个桶内的元素为 None 或removed时,说明这个桶是空的,可用于放置键值对。 - 在线性探测时,我们从当前索引
index向后遍历;而当越过数组尾部时,需要回到头部继续遍历。
Python:
class HashMapOpenAddressing:
"""开放寻址哈希表"""
def __init__(self):
"""构造方法"""
self.size = 0 # 键值对数量
self.capacity = 4 # 哈希表容量
self.load_thres = 2 / 3 # 触发扩容的负载因子阈值
self.extend_ratio = 2 # 扩容倍数
self.buckets: list[Pair | None] = [None] * self.capacity # 桶数组
self.removed = Pair(-1, "-1") # 删除标记
def hash_func(self, key: int) -> int:
"""哈希函数"""
return key % self.capacity
def load_factor(self) -> float:
"""负载因子"""
return self.size / self.capacity
def get(self, key: int) -> str:
"""查询操作"""
index = self.hash_func(key)
# 线性探测,从 index 开始向后遍历
for i in range(self.capacity):
# 计算桶索引,越过尾部返回头部
j = (index + i) % self.capacity
# 若遇到空桶,说明无此 key ,则返回 None
if self.buckets[j] is None:
return None
# 若遇到指定 key ,则返回对应 val
if self.buckets[j].key == key and self.buckets[j] != self.removed:
return self.buckets[j].val
def put(self, key: int, val: str):
"""添加操作"""
# 当负载因子超过阈值时,执行扩容
if self.load_factor() > self.load_thres:
self.extend()
index = self.hash_func(key)
# 线性探测,从 index 开始向后遍历
for i in range(self.capacity):
# 计算桶索引,越过尾部返回头部
j = (index + i) % self.capacity
# 若遇到空桶、或带有删除标记的桶,则将键值对放入该桶
if self.buckets[j] in [None, self.removed]:
self.buckets[j] = Pair(key, val)
self.size += 1
return
# 若遇到指定 key ,则更新对应 val
if self.buckets[j].key == key:
self.buckets[j].val = val
return
def remove(self, key: int):
"""删除操作"""
index = self.hash_func(key)
# 线性探测,从 index 开始向后遍历
for i in range(self.capacity):
# 计算桶索引,越过尾部返回头部
j = (index + i) % self.capacity
# 若遇到空桶,说明无此 key ,则直接返回
if self.buckets[j] is None:
return
# 若遇到指定 key ,则标记删除并返回
if self.buckets[j].key == key:
self.buckets[j] = self.removed
self.size -= 1
return
def extend(self):
"""扩容哈希表"""
# 暂存原哈希表
buckets_tmp = self.buckets
# 初始化扩容后的新哈希表
self.capacity *= self.extend_ratio
self.buckets = [None] * self.capacity
self.size = 0
# 将键值对从原哈希表搬运至新哈希表
for pair in buckets_tmp:
if pair not in [None, self.removed]:
self.put(pair.key, pair.val)
def print(self):
"""打印哈希表"""
for pair in self.buckets:
if pair is not None:
print(pair.key, "->", pair.val)
else:
print("None")
Go:
/* 链式地址哈希表 */
type hashMapOpenAddressing struct {
size int // 键值对数量
capacity int // 哈希表容量
loadThres float64 // 触发扩容的负载因子阈值
extendRatio int // 扩容倍数
buckets []pair // 桶数组
removed pair // 删除标记
}
/* 构造方法 */
func newHashMapOpenAddressing() *hashMapOpenAddressing {
buckets := make([]pair, 4)
return &hashMapOpenAddressing{
size: 0,
capacity: 4,
loadThres: 2 / 3.0,
extendRatio: 2,
buckets: buckets,
removed: pair{
key: -1,
val: "-1",
},
}
}
/* 哈希函数 */
func (m *hashMapOpenAddressing) hashFunc(key int) int {
return key % m.capacity
}
/* 负载因子 */
func (m *hashMapOpenAddressing) loadFactor() float64 {
return float64(m.size) / float64(m.capacity)
}
/* 查询操作 */
func (m *hashMapOpenAddressing) get(key int) string {
idx := m.hashFunc(key)
// 线性探测,从 index 开始向后遍历
for i := 0; i < m.capacity; i++ {
// 计算桶索引,越过尾部返回头部
j := (idx + 1) % m.capacity
// 若遇到空桶,说明无此 key ,则返回 null
if m.buckets[j] == (pair{}) {
return ""
}
// 若遇到指定 key ,则返回对应 val
if m.buckets[j].key == key && m.buckets[j] != m.removed {
return m.buckets[j].val
}
}
// 若未找到 key 则返回空字符串
return ""
}
/* 添加操作 */
func (m *hashMapOpenAddressing) put(key int, val string) {
// 当负载因子超过阈值时,执行扩容
if m.loadFactor() > m.loadThres {
m.extend()
}
idx := m.hashFunc(key)
// 线性探测,从 index 开始向后遍历
for i := 0; i < m.capacity; i++ {
// 计算桶索引,越过尾部返回头部
j := (idx + i) % m.capacity
// 若遇到空桶、或带有删除标记的桶,则将键值对放入该桶
if m.buckets[j] == (pair{}) || m.buckets[j] == m.removed {
m.buckets[j] = pair{
key: key,
val: val,
}
m.size += 1
return
}
// 若遇到指定 key ,则更新对应 val
if m.buckets[j].key == key {
m.buckets[j].val = val
}
}
}
/* 删除操作 */
func (m *hashMapOpenAddressing) remove(key int) {
idx := m.hashFunc(key)
// 遍历桶,从中删除键值对
// 线性探测,从 index 开始向后遍历
for i := 0; i < m.capacity; i++ {
// 计算桶索引,越过尾部返回头部
j := (idx + 1) % m.capacity
// 若遇到空桶,说明无此 key ,则直接返回
if m.buckets[j] == (pair{}) {
return
}
// 若遇到指定 key ,则标记删除并返回
if m.buckets[j].key == key {
m.buckets[j] = m.removed
m.size -= 1
}
}
}
/* 扩容哈希表 */
func (m *hashMapOpenAddressing) extend() {
// 暂存原哈希表
tmpBuckets := make([]pair, len(m.buckets))
copy(tmpBuckets, m.buckets)
// 初始化扩容后的新哈希表
m.capacity *= m.extendRatio
m.buckets = make([]pair, m.capacity)
m.size = 0
// 将键值对从原哈希表搬运至新哈希表
for _, p := range tmpBuckets {
if p != (pair{}) && p != m.removed {
m.put(p.key, p.val)
}
}
}
/* 打印哈希表 */
func (m *hashMapOpenAddressing) print() {
for _, p := range m.buckets {
if p != (pair{}) {
fmt.Println(strconv.Itoa(p.key) + " -> " + p.val)
} else {
fmt.Println("nil")
}
}
}
多次哈希
顾名思义,多次哈希方法是使用多个哈希函数 f1(x)、f2(x)、f3(x)、… 进行探测。
- 插入元素:若哈希函数 f1(x) 出现冲突,则尝试 f2(x) ,以此类推,直到找到空位后插入元素。
- 查找元素:在相同的哈希函数顺序下进行查找,直到找到目标元素时返回;或遇到空位或已尝试所有哈希函数,说明哈希表中不存在该元素,则返回 None 。
与线性探测相比,多次哈希方法不易产生聚集,但多个哈希函数会增加额外的计算量。
Python 采用开放寻址。字典 dict 使用伪随机数进行探测。
Golang 采用链式地址。Go 规定每个桶最多存储 8 个键值对,超出容量则连接一个溢出桶;当溢出桶过多时,会执行一次特殊的等量扩容操作,以确保性能。