【升职加薪秘籍】我在服务监控方面的实践(9)-报警设计
服务监控实践完整系列:
【升职加薪秘籍】我在服务监控方面的实践(1)-监控蓝图
【升职加薪秘籍】我在服务监控方面的实践(2)-监控组件配置
【升职加薪秘籍】我在服务监控方面的实践(3)-机器监控
【升职加薪秘籍】我在服务监控方面的实践(4)-日志监控
【升职加薪秘籍】我在服务监控方面的实践(5)-应用监控
【升职加薪秘籍】我在服务监控方面的实践(6)-业务维度的mysql监控
【升职加薪秘籍】我在服务监控方面的实践(7)-业务维度的redis监控
【升职加薪秘籍】我在服务监控方面的实践(8)-elasticsearch 性能监控与分析手段
【升职加薪秘籍】我在服务监控方面的实践(9)-报警设计
大家好,我是蓝胖子,关于性能分析的视频和文章我也大大小小出了有一二十篇了,算是已经有了一个系列,之前的代码已经上传到github.com/HobbyBear/performance-analyze, 接下来这段时间我将在之前内容的基础上,结合自己在公司生产上构建监控系统的经验,详细的展示如何对线上服务进行监控,内容涉及到的指标设计,软件配置,监控方案等等你都可以拿来直接复刻到你的项目里,这是一套非常适合中小企业的监控体系。
在前面的几节里,我挨个从机器监控,应用监控,中间件监控(mysql,redis) 应该如何来做,但光有监控还是不行的,我们不可能时时刻刻都盯着监控大盘,所以还需要有报警机制,这一节我们就来仔细研究下这部分。
监控系列的完整代码已经上传到github
github.com/HobbyBear/easymonitor
报警架构介绍
我们再来回顾下之前介绍的架构图,我们拥有一个自定义的告警服务。
整个报警来源主要分两部分,日志告警和指标告警,日志告警会对整个系统里错误等级的日志进行告警,指标告警则是在grafana上建立告警规则,最后通知到自定义的告警服务,由告警服务发送告警到各自的告警群。

logstash 日志告警
先来看看日志告警的配置,在logstash里,可以配置多输出源,这也是我们为啥要将filebeat的日志先发送到logstash的原因,filebeat只能单输出源,而我们的需求是需要将日志同时输出到es以及自定义的报警服务里。
output {
stdout { codec => rubydebug }
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "easymonitor-%{[fields][log_type]}-%{+yyyy.MM.dd}"
}
if [level] == "error" {
http {
http_method => "post"
url => "http://ubuntu:16060/alert_log"
}
}
}
logstash 里配置如果日志等级是error那么则将调用我们自定义的告警服务接口。
grafana指标告警
接着看下,指标告警的内容。在grafana上配置contact points 这个是触发告警时的通知策略。我们需要把它配置一个webhook端点,也就是告警服务的接口。

接着,将它设置为默认的通知策略。
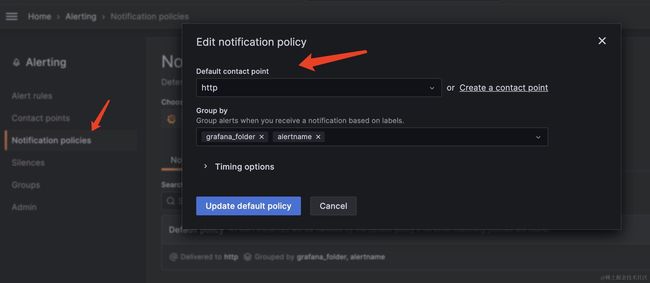
最后,去Alert rules面板定义一些自定义的监控规则就行,到时候指标异常后就会通过设置好的http接口发送过来。

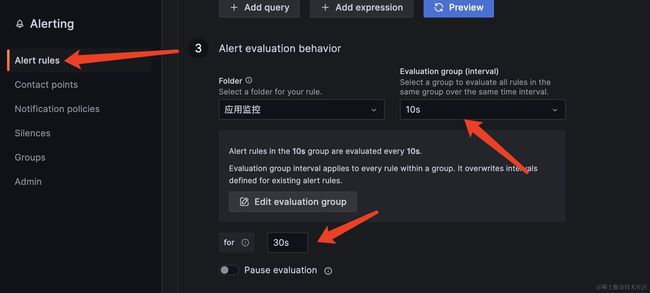
关于grafana的Alert rules 的配置,有几个关于时间的选项,我再说一下,如下,在配置报警规则的时候,需要配置两个时间,一个是多久运行一次指标的评估表达式,一个是配置在报警的持续时间,比如我在配置中写了10s运行一次报警,持续30s,也就是如果连续3次都触发了异常,那么就会对这次异常进行报警。
在报警通知的时候,也会有时间设置。
如下,group wait表示收到来自不同group时的报警时,在通知webhook端点时,不同group之间的报警会间隔30s才会发送,group interval表示同一个group报警规则在发送时,一批报警发送后,新的一批报警需要再5m后再发送给webhook端点。repeat interval 表示,相同的告警在4h内不会重复发送。

针对项目组和应用做不同报警策略
无论是日志告警还是指标异常报警,我们都需要注意一点,那就是报警的分组,因为如果把多个项目组的报警都发往一个告警群,会造成告警过多且杂。
好的设计应该是按项目组对报警进行分组发送到不同的告警群。不同的告警群由各自的业务负责人负责,所以我们在日志打印或者暴露指标时都携带了一个维度,应用服务的名称,通过应用服务的名称区分不同的项目组,并且关联到特定的钉钉告警群。
并且由于是自研的告警服务,我们还可以针对不同的项目组做一些定制化的告警策略。
应用服务和告警群的映射关系被配置到数据库表里,由告警服务读取后常驻与内存中,新的服务接入时也只需要往数据库插入一条配置便可以让他拥有告警能力,十分便捷。
总结
简单总结下,这一节也是构建服务监控系统的最后一节,后续有时间我可能会出一版容器环境下的监控,不过换汤不换药,主要是学习监控系统的思想,应该如何监控,应该如何通过这些监控指标或者日志定位问题,如何更好的定位问题,高效解决问题,一直都是我们的目的,大家对监控系统有什么好的想法或者实践,欢迎留言,我们一起探讨。
在万千人海中,相遇就是缘分,为了这份缘分,给作者点个赞不过分吧。