8月热门论文丨AI Agent会是大模型的未来发展方向吗?
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
以下内容来源于AMiner科技

过去的8月,如果让我用一个词来总结,那就是“Agent”!
大模型的下半场已经拉开序幕,大厂们都纷纷表态入局“Agent”。OpenAI创始成员Andrej Karpathy表示相比大模型,OpenAI内部目前已经关注Agent领域,亚马逊也宣布了Amazon Bedrock Agents新功能,而更早之前的斯坦福“AI小镇”等也是“Agent”的体现。
8月,清华大学ChatGLM团队发布AI Agent能力评测工具AgentBench;中国人民大学高瓴人工智能学院团队发布了AI智能体综述文章《A Survey on LLM-based Autonomous Agents》;商汤团队提出了一个专门为基于LLM的人工智能代理量身定制的结构化框架。
当然,除了上述工作之外,还有Meta开源史上最强代码工具Code Llama,38所机构、200余篇文献、Yoshua Bengio领衔团队综述AI时代的科学发现等。
让我们一起来看看。
1. Code Llama: Open Foundation Models for Code
✦
✦
✦
✦
Meta发布了名为 Code Llama 的一组大型语言模型,该模型基于 Llama 2,为代码提供了最先进的性能、填充能力、对大型输入上下文的支持以及零样本指令跟随能力。我们提供了多种变体以覆盖广泛的应用范围:基础模型(Code Llama)、Python 专长(Code Llama - Python)以及指令跟随模型(Code Llama - Instruct),各自的参数分别为 70 亿、130 亿和 340 亿。所有模型都在 16k 令牌的序列上训练,并在具有多达 100k 令牌的输入上显示出改进。7B 和 13B Code Llama 以及 Code Llama - Instruct 变体支持基于周围内容的填充。Code Llama 在多个代码基准测试中达到了最先进的性能,分别在 HumanEval 和 MBPP 上达到了 53% 和 55% 的得分。值得注意的是,Code Llama - Python 7B 在 HumanEval 和 MBPP 上的表现优于 Llama 2 70B,而Meta的所有模型在 MultiPL-E 上的表现都优于其他任何公开可用的模型。我们将 Code Llama 发布在允许研究和商业使用的宽松许可证下。

论文链接:https://www.aminer.cn/pub/64e82e45d1d14e646633f5aa 阅读原文
2. Scientific discovery in the age of artificial intelligence
✦
✦
✦
✦
本文讨论了过去十年中人工智能在科学发现领域的突破,包括自监督学习和几何深度学习等方法。这些方法可以帮助科学家在生成假设、设计实验、收集和解释大量数据以及获取传统科学方法可能无法获得的洞察力等方面加快和增强研究。此外,生成式人工智能方法可以通过分析图像和序列等不同数据模式来创造设计,例如小分子药物和蛋白质。本文讨论了这些方法如何帮助科学家在整个科学过程中,以及尽管有这些进步,仍然存在的核心问题。开发和使用人工智能工具的开发者和用户都需要更好地了解何时需要改进这些方法,以及数据质量和管理等方面的挑战。这些问题跨越了科学学科,需要开发基础算法方法,可以为科学理解做出贡献或自主获取,使它们成为人工智能创新的关键重点。本文回顾了过去十年人工智能的进步,讨论了人工智能系统如何辅助科学过程以及尽管有进步仍然存在的核心问题。
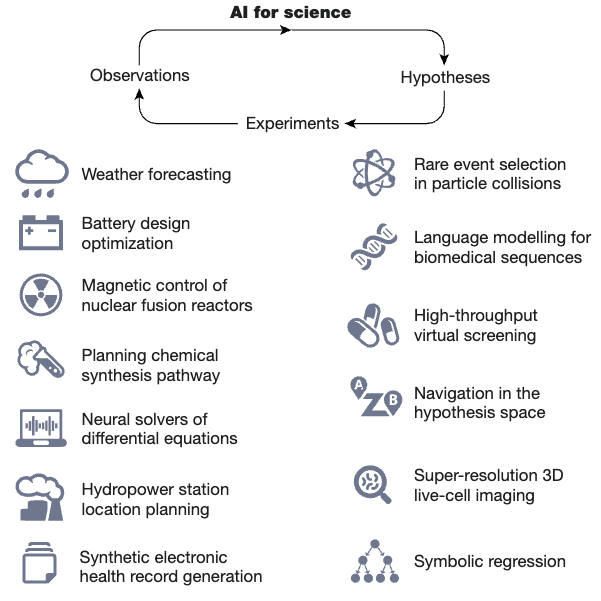
论文链接:https://www.aminer.cn/pub/64cb4fb63fda6d7f06fecb8b 阅读原文
3. AgentBench: Evaluating LLMs as Agents
✦
✦
✦
✦
论文介绍了一个名为 AgentBench 的多维度演化基准,用于评估大型语言模型 (LLM) 作为智能体的能力。随着 LLM 变得越来越智能和自主,在传统自然语言处理任务之外的现实世界实用任务中发挥作用,因此评估 LLM 在交互环境中的挑战性任务上作为智能体的能力变得紧迫。论文测试了 25 个 LLM(包括 API 和开源模型),发现顶级商业 LLM 在复杂环境中作为智能体的表现很强,但与开源竞争者之间存在显著的性能差距。该基准是正在进行的一个更广泛覆盖和更深入考虑系统评估 LLM 的项目的一部分。
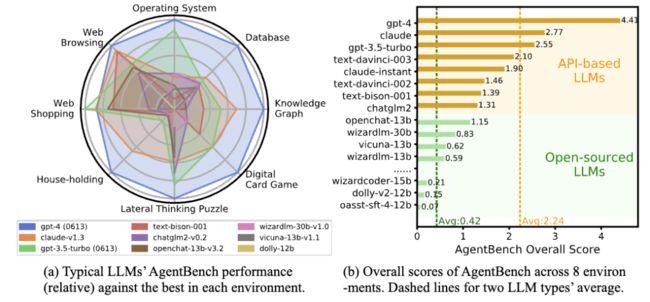
论文链接:https://www.aminer.cn/pub/64d1bdf93fda6d7f06ec4af3 阅读原文
4. All in One: Multi-task Prompting for Graph Neural Networks
✦
✦
✦
✦
论文研究了图神经网络 (Graph Neural Networks,GNNs) 的 prompting 问题,以解决预处理和微调方法在处理各种图任务时存在的不兼容性问题。虽然预处理和微调方法可以缓解缺乏图形注释的问题,但是节点级别、边级别和图级别任务的多样化使得预处理方法往往无法适用于多个任务。这可能导致对某些特定应用而言的“负迁移”,从而导致性能不佳。
论文借鉴了自然语言处理 (NLP) 中的 prompting 概念,并在图领域提出了一种新的多任务 prompting 方法。具体来说,我们首先将图提示和语言提示用提示符、token 结构和插入模式统一起来,使得 NLP 中的 prompting 概念可以无缝应用于图领域。然后,为了进一步缩小各种图任务和最先进的预处理策略之间的差距,我们深入研究了各种图应用的任务空间,并将下游问题重构为图级别任务。最后,我们采用元学习高效地学习多任务提示的初始化,使我们的 prompting 框架对于不同的任务更加可靠和通用。我们进行了广泛的实验,结果表明,我们的方法在多个测试任务中表现更好。
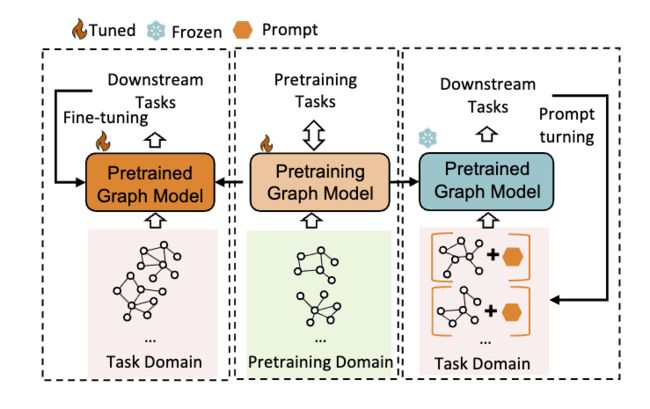
论文链接:https://www.aminer.cn/pub/64a63bbad68f896efaec478f 阅读原文
5. Trustworthy LLMs: a Survey and Guideline for Evaluating Large Language Models' Alignment
✦
✦
✦
✦
这篇论文的摘要是关于评估大型语言模型(LLMs)的信任度,以确保模型的行为符合人类意图。该论文提出了一个全面的调查报告,涵盖了评估 LLM 可信度的关键维度,包括可靠性、安全性、公平性、抵御滥用、可解释性和推理能力、遵守社会规范和鲁棒性,总共分为 7 个主要类别和 29 个子类别。论文进一步选取了 8 个子类别进行深入研究,对几个广泛使用的 LLM 进行了测量研究。测量结果表明,一般来说,更一致的模型在整体可信度方面表现更好。然而,对齐效果在不同的可信度类别上差异很大,这强调了对 LLM 进行更细粒度分析、测试和持续改进的重要性。通过探讨这些关键维度,该论文旨在为该领域的实践者提供有价值的见解和指导。理解和解决这些问题对于在各种应用中实现可靠和道德的 LLM 部署至关重要。

论文链接:https://www.aminer.cn/pub/64d5b2153fda6d7f060d00a4 阅读原文
6. AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining
✦
✦
✦
✦
这篇论文介绍了一种名为 AudioLDM 2 的音频生成框架,该框架使用相同的学习方法来处理语音、音乐和声音效果生成。框架引入了一种通用音频表示,称为音频语言(LOA),任何音频都可以根据 AudioMAE(一种自监督预训练表示学习模型)转换为 LOA。在生成过程中,使用 GPT-2 模型将任何模态转换为 LOA,并在条件为 LOA 的潜在扩散模型上进行自监督音频生成学习。该框架自然带来了诸如上下文学习能力和可重用的自监督预训练 AudioMAE 和潜在扩散模型等优点。在文本到音频、文本到音乐和文本到语音的主要基准测试中,实验证明了这种方法具有比以前方法更先进的性能。
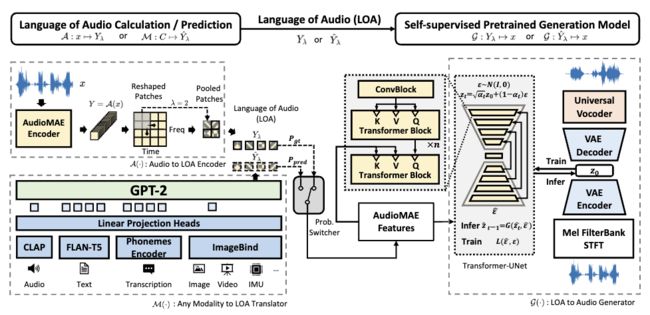
论文链接:https://www.aminer.cn/pub/64d5b21d3fda6d7f060d0db5 阅读原文
7. Self-Alignment with Instruction Backtranslation
✦
✦
✦
✦
这篇论文介绍了一种名为"指令反向翻译"的可扩展方法,用于构建高质量的指令跟随语言模型。该方法通过自动为人类编写的文本分配相应的指令,从而实现自我对齐。首先,在一个小量的种子数据和给定的网络文集中对语言模型进行微调。然后,使用种子模型生成指令提示,用于网络文档的自我扩充,并从这些候选者中选择高质量的例子进行自我策展。最后,利用这些数据对模型进行再次微调,从而得到一个更强大的模型。经过两次迭代,该方法在 Alpaca 排行榜上超越了所有不依赖于蒸馏数据的 LLaMa 基础模型,证明了自我对齐的效果非常高效。
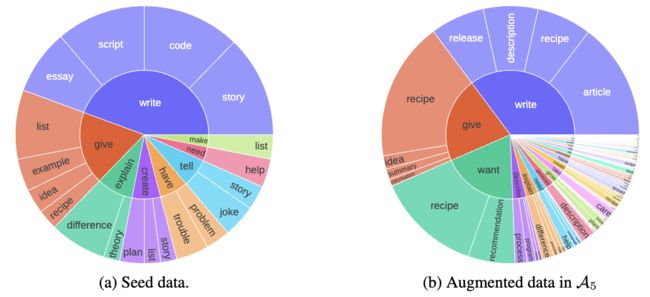
论文链接:https://www.aminer.cn/pub/64d9a6873fda6d7f061d37b9 阅读原文
8. Learning to Identify Critical States for Reinforcement Learning from Videos
✦
✦
✦
✦
这篇论文主要研究了如何从视频中学习识别关键状态,以应用于强化学习。近期的深度强化学习(DRL)研究指出,可以从缺乏关于执行动作的显式信息的离线数据中提取有关优质策略的算法信息。例如,人类或机器人的视频可能包含很多关于有益动作序列的隐含信息,但想要从观看这些视频中获利的 DRL 机器首先必须学会自己识别和理解相关的状态/动作/奖励。在不依赖真实标注的情况下,我们提出的新方法“深度状态标识符”学会了从作为视频编码的剧集中预测回报。然后,它使用一种基于掩码的敏感性分析来提取/识别重要的临界状态。大量的实验展示了我们的方法在理解和改进智能体行为方面的潜力。
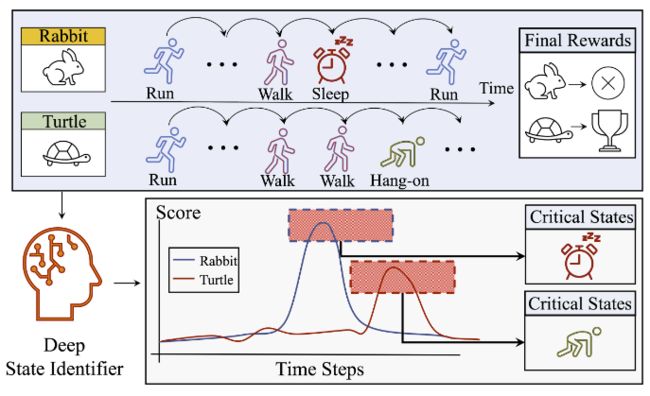
论文链接:https://www.aminer.cn/pub/64dc49903fda6d7f06389d06 阅读原文
9. Consciousness in Artificial Intelligence: Insights from the Science of Consciousness
✦
✦
✦
✦
这篇论文的主题是“人工智能中的意识:来自意识科学的洞察”。论文探讨了当前或近期的人工智能系统是否可能具有意识,这是一个科学问题,也是公众日益关注的问题。论文主张并举例说明了一种严谨且实证为基础的方法来研究 AI 意识,即在详尽地评估现有 AI 系统的基础上,参照我们最支持的神经科学意识理论。论文调查了几种主要的科学意识理论,包括循环处理理论、全局工作空间理论、高级理论、预测处理和注意力模式理论。从这些理论中,我们推导出意识的“指标属性”,并用计算术语阐明,以便我们根据这些属性评估 AI 系统。我们使用这些指标属性评估了几个最近的 AI 系统,并讨论了未来系统可能如何实现这些属性。我们的分析表明,当前的 AI 系统没有意识,但也显示了构建有意识的 AI 系统没有明显的障碍。
论文链接:https://www.aminer.cn/pub/64e2e14f3fda6d7f0646637a 阅读原文
10. Diversifying AI: Towards Creative Chess with AlphaZero
✦
✦
✦
✦
这篇文章探讨了人工智能在面临困难任务时是否能从具有创造性决策机制中受益。研究人员通过在象棋游戏中构建一个多样化的人工智能系统团队,并使用行为多样性技术来增加其生成的想法的范围,然后通过选择最有前途的想法来解决困难问题。研究发现,多样化的人工智能系统团队可以以更多样化的方式下棋,并且解决的难题数量比单一人工智能系统团队多两倍。此外,团队中的每个成员在不同的开局中表现出不同的专长,通过使用子可加规划来选择每个开局的成员可以使整个团队的表现显著提升。研究结果表明,多样性对于解决计算上困难问题是一种宝贵的资产,人工智能系统团队中的多样性奖励与人类团队中的多样性奖励一样重要。
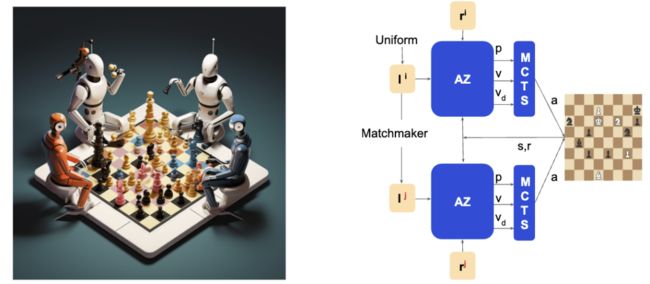
论文链接:https://www.aminer.cn/pub/64e2e14f3fda6d7f06466555 阅读原文
11. ProAgent: Building Proactive Cooperative AI with Large Language Models
✦
✦
✦
✦
这篇论文介绍了一种名为 ProAgent 的新框架,它利用大型语言模型来帮助智能体在与人类或其他智能体的合作中更具前瞻性和主动性。传统的合作智能体方法主要依赖于学习方法,策略泛化严重依赖于与特定队友的过去交互,这限制了智能体在面对新队友时的策略重新调整能力。ProAgent 则可以预见队友的未来决策,并为自己制定增强的计划,表现出卓越的合作推理能力,能够动态适应以提高与队友的合作效果。此外,ProAgent 框架具有高度的模块化和可解释性,可以无缝集成到各种协调场景中。实验结果显示,ProAgent 在 Overcook-AI 框架中的表现优于五种基于自我游戏和基于人口训练的方法,在与人类代理模型的合作中,其性能平均提高了超过 10%,超过了目前的最先进方法 COLE。这一进步在涉及与具有不同特性的 AI 代理和人类对手的互动的多样化场景中是一致的。这些发现激发了未来人类与机器人合作的研究。
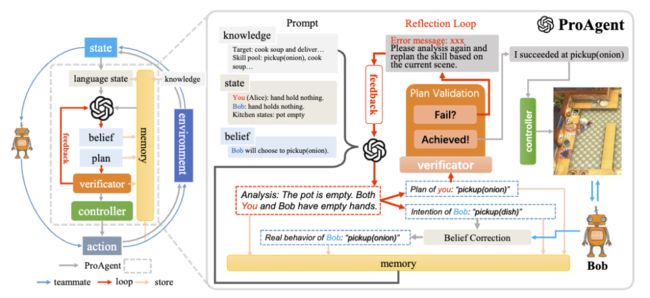
论文链接:https://www.aminer.cn/pub/64e5849c3fda6d7f063af3cd 阅读原文
12. A Survey on Large Language Model based Autonomous Agents
✦
✦
✦
✦
这篇论文是关于基于大型语言模型的自主智能体的研究概述。之前的研究往往集中在有限知识下在孤立环境中训练智能体,这与人类的学习过程相去甚远,因此使得智能体难以实现类人的决策。近年来,通过获取大量的网络知识,大型语言模型 (LLMs) 在实现人类水平智能方面表现出了巨大的潜力。这引发了基于 LLM 的自主智能体研究的激增。为了充分利用 LLM 的潜力,研究人员为不同应用设计了各种智能体架构。在这篇论文中,我们从整体上对这些研究进行了系统回顾,具体来说,我们的重点在于构建基于 LLM 的智能体,为此我们提出了一个统一的框架,涵盖了大部分以前的工作。此外,我们还提供了 LLM 为基础的人工智能智能体在社会科学、自然科学和工程领域各种应用的概述。最后,我们讨论了用于评估 LLM 为基础的人工智能智能体的常用策略。根据以前的研究,我们还提出了这个领域的几个挑战和未来方向。
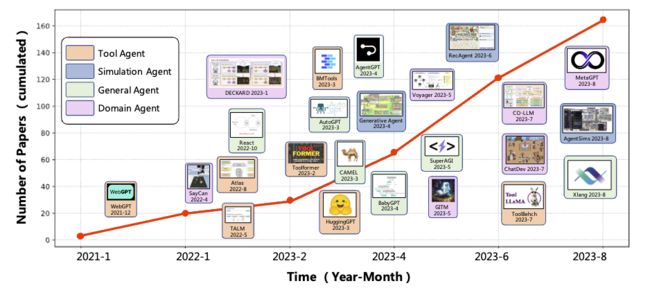
论文链接:https://www.aminer.cn/pub/64e5849c3fda6d7f063af42e 阅读原文
13. SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
✦
✦
✦
✦
这篇论文介绍了一种名为 SeamlessM4T 的大规模多语言和多模态机器翻译模型,它可以帮助个人在多达 100 种语言之间进行语音翻译。尽管近期基于文本的模型突破了 200 种语言的翻译覆盖范围,但统一的语音到语音翻译模型尚未取得类似的进展。为了解决这个问题,作者提出了一个支持语音到语音翻译、语音到文本翻译、文本到语音翻译、文本到文本翻译和自动语音识别的单一模型。他们使用 100 万小时的开放语音音频数据来学习自我监督的语音表示,并创建了一个多模态的自动对齐语音翻译语料库。通过过滤和人类标注以及伪标签数据,他们开发了第一个能翻译成和从英语到语音和文本的多语言系统。在 FLEURS 评估中,SeamlessM4T 在直接语音到文本翻译中取得了比之前最佳水平提高 20% 的 BLEU 评分。与强大的级联模型相比,SeamlessM4T 在语音到文本翻译中提高了 1.3 个 BLEU 点,在语音到语音翻译中提高了 2.6 个 ASR-BLEU 点。经过鲁棒性测试,该系统在语音到文本任务中对背景噪音和说话人变化表现得更好。作者还评估了 SeamlessM4T 在性别偏见和添加毒性方面的翻译安全性。最后,他们在 GitHub 上开源了所有贡献,以供更多人学习和使用。
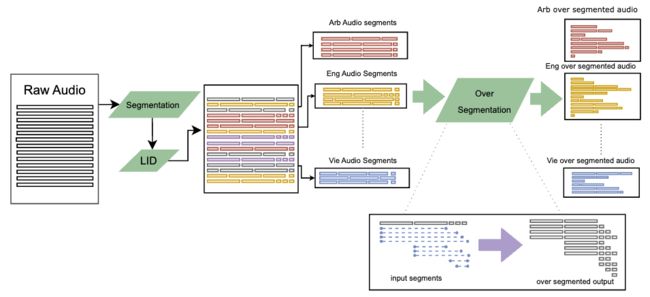
论文链接:https://www.aminer.cn/pub/64e5849c3fda6d7f063af4d6 阅读原文
14. InstructionGPT-4: A 200-Instruction Paradigm for Fine-Tuning MiniGPT-4
✦
✦
✦
✦
这篇文章说明了大型多模态语言模型在进行指令跟随时遇到的问题。这些模型通过两阶段的训练过程获得指令跟随的能力,首先是在图像-文本对上进行预训练,然后在监督式视觉-语言指令数据上进行微调。最近的研究表明,即使使用有限数量的高质量指令跟随数据,大型语言模型也可以获得令人满意的结果。文章介绍了InstructionGPT-4,该模型仅在一个包含200个示例的小型数据集上进行微调,这相当于MiniGPT-4对齐数据集中所使用的指令跟随数据的约6%。作者首先提出了几个衡量多模态指令数据质量的指标。基于这些指标,他们提出了一种简单而有效的数据选择器,可以自动识别和过滤低质量的视觉-语言数据。通过采用这种方法,InstructionGPT-4在各种评估中(如视觉问答、GPT-4偏好)的表现优于原始的MiniGPT-4。总体而言,研究结果表明,数量较少但是高质量的指令微调数据能够有效地使多模态大型语言模型生成更好的输出。

论文链接:https://www.aminer.cn/pub/64e6d5bd3fda6d7f0652c7f8 阅读原文
15. Reinforcement Learning for Generative AI: A Survey
✦
✦
✦
✦
这篇论文摘要是关于强化学习在生成式人工智能中的应用。生成式人工智能在机器学习领域具有长期重要的地位,可以影响到许多应用领域,如文本生成和计算机视觉。训练生成模型的主要方法是最大似然估计,它通过减小模型分布和目标分布之间的差异来推动学习者捕捉和逼近目标数据分布。然而,这种方法不能满足用户对生成模型的所有期望。强化学习作为一种有竞争力的选项,可以通过创建新目标来利用新信号,从而注入新的训练信号,展示出其强大和灵活的适应性,并从多个角度(如对抗性学习、手工设计规则和学习奖励模型)来纳入人类的归纳偏见。因此,强化学习已经成为一个热门的研究领域,并在生成式人工智能的模型设计和应用方面拓展了极限。尽管近年来在不同应用领域进行了一些调查,但这篇综述旨在对近年来的进展进行全面回顾,并涵盖了各个应用领域。我们为这个领域提供了一个严格的分类,并对各种模型和应用进行了充分的覆盖。值得注意的是,我们还调查了快速发展的大型语言模型领域。最后,我们通过展示可能解决当前模型局限性的潜在方向,以及扩展生成式人工智能的前沿,结束了这篇综述。
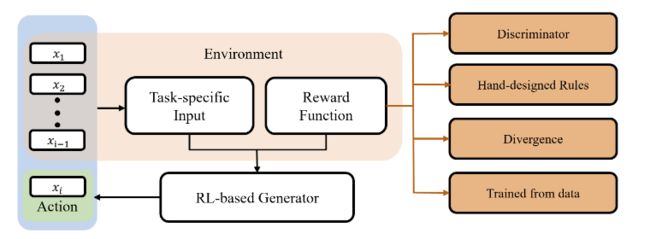
论文链接:https://www.aminer.cn/pub/64ed716d3fda6d7f0658aa83 阅读原文
16. Large Language Models for Information Retrieval: A Survey
✦
✦
✦
✦
这篇论文的摘要是关于使用大型语言模型进行信息检索的。信息检索系统已经成为我们日常生活中的主要信息获取方式,并且还作为对话、问答和推荐系统的组成部分。信息检索的发展轨迹从基于术语的方法开始,已经发展到与先进的神经模型相结合。尽管神经模型在捕捉复杂的上下文信号和语义细微差别方面表现出色,但它们仍然面临着数据稀缺性、可解释性和生成可能不准确的上下文合理响应等挑战。这种发展需要将传统方法(如基于术语的稀疏检索方法)与现代神经架构(如具有强大语言理解能力的语言模型)相结合。大型语言模型(如 ChatGPT 和 GPT-4)的出现,由于它们出色的语言理解、生成、泛化和推理能力,彻底改变了自然语言处理领域。因此,最近的研究试图利用大型语言模型来改进信息检索系统。鉴于这个研究轨迹的快速发展,有必要总结现有的方法,并通过全面的概述提供深入的见解。在这篇调查中,我们深入探讨了大型语言模型和信息检索系统的融合,包括诸如查询重写器、检索器、排序器和阅读器等关键方面。此外,我们还探讨了这个不断扩展领域的有前景的方向。

论文链接:https://www.aminer.cn/pub/64dafb293fda6d7f064e2d9e 阅读原文
17. TPTU: Task Planning and Tool Usage of Large Language Model-based AI Agents
✦
✦
✦
✦
这篇论文主要讨论了大型语言模型(LLM)在各种实际应用中的强大功能,但同时也指出,LLM 的内在生成能力可能不足以处理需要任务规划和外部工具结合的复杂任务。因此,作者提出了一个针对 LLM 为基础的人工智能代理的结构化框架,并设计了两种不同类型的代理(一步代理和序列代理)来执行推理过程。接着,作者使用各种 LLM 来实例化该框架,并评估它们在典型任务中的任务规划和工具使用(TPTU)能力。文章通过突出关键发现和挑战,旨在为研究人员和实践者提供利用 LLM 在人工智能应用中的力量的有益资源。研究强调了这些模型的巨大潜力,同时也指出需要更多研究和改进的领域。
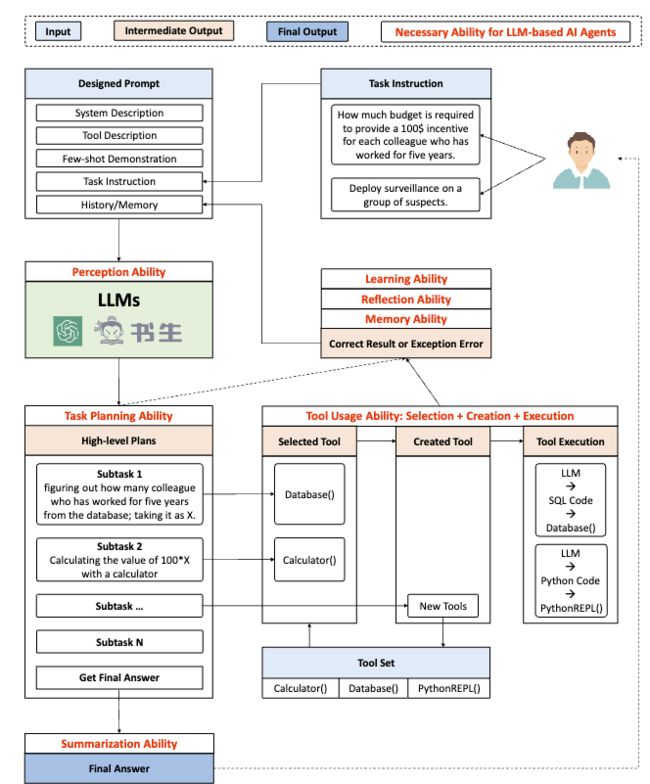
论文链接:https://www.aminer.cn/pub/64d1bde83fda6d7f06ec3db6 阅读原文
18. Cumulative Reasoning With Large Language Models
✦
✦
✦
✦
目这篇论文提出了一种新的方法,称为累积推理 (Cumulative Reasoning,CR),它使用大型语言模型以累积和迭代的方式来模拟人类思维过程。通过将任务分解成更小的组件,CR 方法简化了问题解决过程,使其更加可行和高效。在逻辑推理任务中,CR 方法比现有方法表现更好,改进幅度达到 9.3%,并且在经过筛选的 FOLIO 维基数据集上实现了惊人的 98.04% 的准确度。在 24 点游戏背景下,CR 方法实现了 94% 的准确度,比先前的最先进方法提高了 20%。
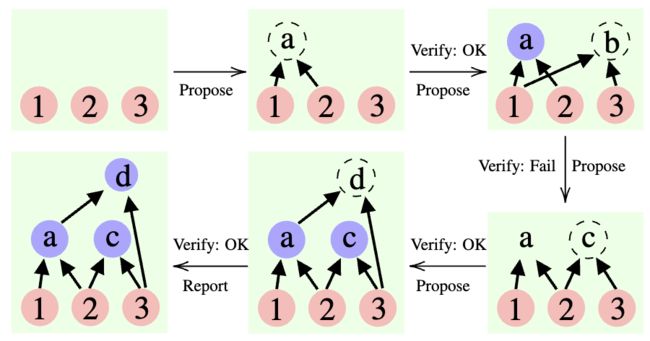
论文链接:https://www.aminer.cn/pub/64d30f353fda6d7f06f6cb27 阅读原文
如何使用ChatPaper?
使用ChatPaper的方法很简单,打开AMiner首页,从页面顶部导航栏或者右下角便可进入ChatPaper页面。
在ChatPaper页面中,可以选择基于单篇文献进行对话和基于全库(个人文献库)对话,可选择上传本地PDF或者直接在AMiner上检索文献。
阅读原文,直达ChatPaper!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1300多位海内外讲者,举办了逾600场活动,超600万人次观看。

我知道你
在看
哦
~
![]()
点击 阅读原文 直达ChatPaper!