数据分析指北 - 基础( KNIME 基础模块之一 )

欢迎关注公众号 数据分析指北
数据分析指北 - 基础( KNIME 基础模块之一 )
历史回看:
基础(数据来源及轮廓)
有必要搞清楚数据的原始出处以及大致轮廓(分布)。
基础(基础数据操作之二,读取数据源)
附录三 软件的成本,数据分析的成本

Photo by Kaleidico on Unsplash
微信公众号:数据分析指北
KNIME 模块基础
KNIME 模块基础
之前我们介绍了数据分析中最重要的内容,从最原始的如何问问题,到了解问题的解空间,再到如何使用科学方法在解空间中找到问题真正的解,最后还通过SQL中的一些基础知识捋了一下数据分析中的基础操作。《神雕侠侣》中独孤求败在剑冢中留下这么几句话:
紫薇软剑,三十岁前所用,误伤义士不祥,悔恨无已,乃弃之深谷。
重剑无锋,大巧不工,四十岁前持之横行天下。
四十岁后,不滞于物,草木竹石均可为剑。自此精修,渐进于无剑胜有剑之境。
在我看来,数据分析也与之类似。我们的终极目标是草木竹石均可为剑。之前我们所述大部分基本可以归类为“道”的层面,修炼内功,下面我们将主要讲讲“术”或者“技”层面的内容,谈谈我们的重剑。KNIME 的基础操作请参见附录中的内容(附录二 KNIME 使用基本介绍),我们这里只去重点介绍 KNIME 的模块。
KNIME 在某种程度上可以认为是一种图形化编程语言(不能完全这样认为),对于图形化编程语言来说,有一些概念和文本型编程语言有所不同,比如,节点、多个节点组成的程序或子模块、节点组成程序、循环、以及判断语句等等都有所区别。
KNIME 中的节点(NODE)/ 模块是一个类似于文本型编程语言中函数的东西,如下图所见为节点(NODE)。

节点NODE
大部分节点的功能是作用在数据上的函数,y = f(x), x 代表了输入的数据,即为图中1所示箭头,当输入数据为多个时,在1的位置将会有多个入口;f( ) 代表了作用在数据上的操作,对应于图中3的节点名称;而2代表了节点的输出 y , 和 x 一样,y也可以有多个,在图中会表示为多个箭头,在节点运行成功后,右键单击节点,即可看到输出y;4代表了这个节点的状态,节点状态分别有未配置、空闲、成功执行、错误四种状态,现在图中就是未配置的状态;而5是这个节点的备注名,可以用来简要标注这个节点的实际功能。
节点的图标是特别设计过的,代表了节点的功能要点,而节点、输入数据以及输出数据(对,就是那个小箭头)的颜色也是特别设计过的,比如下图所示的各个节点中,橙色代表的都是输入模块,黄色代表的都是操作、变换模块(Transformation 或 Manipulation),蓝色代表的是画图模块,绿色代表的是一些比较高级的分析模块以及数据挖掘,机器学习模块等。

众多不同的节点
另外也要注意到上图中的输入输出节点的颜色和形状不都是一样的,同样的颜色和形状可以相连,不同的颜色和形状则不能相连。这一系列的细节都是为了用户在使用的时候尽可能直观、方便,以减少低级错误和debug的时间。
节点经过组合后,最终形成我们的数据处理程序,在这里我们将其称之为 workflow 工作流。如下图所示就是一个工作流。

workflow工作流
就如同在标准的程序化设计中,我们要有良好的编码习惯一样,只将功能简单串联的 workflow 工作流是不合格,甚至是难以维护的(时刻考虑维护成本,关于成本的思考请参见附录三 软件的成本,数据分析的成本)。如果利用前面讲节点时讲到的备注名功能对节点进行备注,那么工作流/数据流的整体处理流程就会比较清晰,如下图所示:
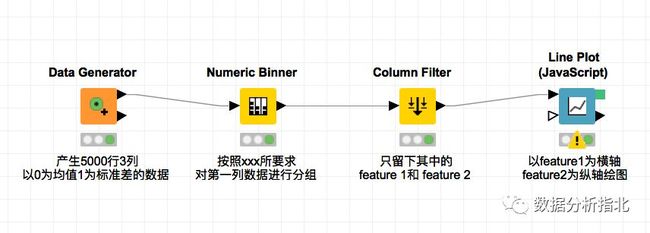
改进的workflow工作流1
另外在整个画布中右击鼠标,选择new workflow annotation, 然后拖拉,配置颜色、字体、边框、对齐等,workflow工作流就可以达到如下程度:
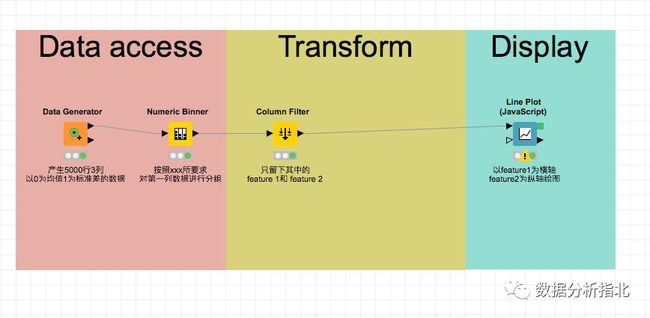
改进的workflow工作流2
图中的Data access,Transform只是示范,在实际使用中,请尽可能本着奥卡姆剃刀原则「如无必要,勿增实体」,考虑使用清晰、简短、有意义的词句。
示例中的节点数较少,可以想见,实际会出现多个节点才能完成一个逻辑上的功能的情况,在这种情况下,就需要将这几个节点组合起来 – 对应的是其他程序设计语言中的“封装”、“模块化”的概念。在KNIME中,选择多个需要封装的节点,右键之后,会弹出菜单让你选择封装类型。如下图所示,有两种类型的节点封装,一种叫做metanode,另外一种叫做wrapped metanode。前者纯粹是将多个节点装在一个新节点中,只是节省了版面的空间,后面一种wrapped metanode是一种可以自定义参数,可以独立存储,并可以在其他 workflow 工作流中调用的高级节点。

两种类型的节点封装
我们在上面所有关于节点的介绍中,介绍的都是数据流,即数据是怎么流过节点,怎么流出节点的。在特定的情况下,如果我们在进行节点配置的时候需要另外节点中的数据,就需要一种叫flow variables的东西了。举个例子,我们有一个节点叫做CSV reader,是用来读取CSV文件,但没有配置去读取哪个文件:

CSV reader配置界面
我们还有另外一个节点,叫做Table Creator,里面存储了所有需要读取的CSV文件名:
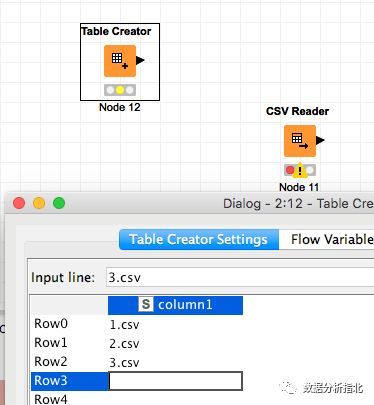
Table Creator中存储的CSV文件名
那么如何将这个table中的csv文件名变成csv reader中的配置参数呢?那就需要flow variable了,它在workflow中是以红线,以及红色的圈来表示的。具体怎么操作,试试咯。
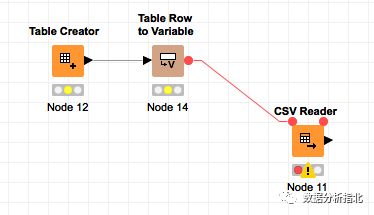
flow variable示例
回头聊
反馈,转发或赞赏?
