【论文】Imitating Driver Behavior with Generative Adversarial Networks---使用生成对抗网络模仿驾驶员行为

紫色:要解决的问题或发现的问题
红色:重点内容
棕色:关联知识,名称
绿色:了解内容,说明内容
论文地址:待后续补充
摘要
准确预测和模拟人类驾驶行为的能力对于智能交通系统的发展至关重要。传统的建模方法采用简单的参数模型和行为克隆。本文采用一种方法来克服先前方法固有的级联误差问题,从而产生对轨迹扰动具有鲁棒性的真实行为。我们将生成对抗模仿学习扩展到循环策略的训练,并证明我们的模型在现实的高速公路模拟中优于基于规则的控制器和最大似然模型。我们的模型既再现了人类驾驶员的紧急行为,例如变道率,又在长时间范围内保持了现实的控制。
一、导言
精确的人类驾驶员模型对于驾驶场景的真实仿真至关重要,并有可能显着推进汽车安全研究。传统上,人类驱动建模一直是基于规则和数据驱动方法的主题。早期基于规则的尝试包括汽车跟随行为的参数模型,具有关于路况 [1] 或驾驶员行为 [2] 的强大内置假设。智能驱动程序模型 (IDM) [3]
通过捕捉加速和减速之间的不对称性、首选的自由道路和保险杠到保险杠之间的前进速度以及逼真的制动行为来扩展这项工作。这种汽车跟随模型后来通过 MOBIL[4] 等控制器扩展到多车道条件,该控制器保持实用功能和“优雅的参数”,以捕获加速和转弯时的聪明的驾驶员行为。这些控制器的主要特点都是平稳、无碰撞的驾驶,但依赖于对驾驶员行为的假设和一小部分参数,这些参数可能无法很好地推广到不同的驾驶场景。
相比之下,模仿学习(IL)方法依赖于通常通过人类演示提供的数据,以便学习行为类似于专家的策略。这些策略可以用表达模型(如神经网络)表示,其可解释参数比基于规则的方法使用的参数少。 先前用于高速公路驾驶的人类行为模型依赖于行为克隆(BC),它将IL视为监督学习问题,将模型拟合到专家【状态-行动】的固定数据集中[5-8]。ALVINN [9] 是 BC 早期的一种方法,它训练了一个神经网络,将原始图像和测距仪输入映射到离散的转弯动作。计算和深度学习的最新进展使这种方法能够扩展到现实场景,例如停车场、高速公路和无标记路况 [10]。这些BC方法在概念上是合理的[11],但在实践中往往会失败,因为在仿真过程中会出现小的不准确性。不准确会导致策略在训练数据中代表性不足的状态(例如,自我车辆向路边倾斜),这会导致更差的预测,并最终导致无效或看不见的情况(例如,越野驾驶【乱开】)。这种级联误差问题[12]在顺序决策文献中是众所周知的,并激发了替代IL方法的工作,例如逆强化学习(IRL)[14]。
逆强化学习假设专家遵循有关未知奖励函数的最佳策略。如果恢复了奖励函数,则可以简单地使用 RL 来查找与专家行为相同的策略。这种模仿延伸到看不见的状态;在高速公路驾驶中,向车道边界受到干扰的车辆应该知道返回车道中心。因此,IRL可以更有效地概括,并且不会受到BC的许多问题的困扰。由于这些好处,一些最近在人类驾驶员建模方面的努力增强了IRL [15,16]。但是,IRL 方法在回收专家成本函数时通常计算成本高昂。相反,最近的工作试图通过直接策略优化来模仿专家行为,而没有首先学习成本函数[13,17]。特别是生成对抗模仿学习(GAIL)[17]在许多基准任务上表现良好,利用专家行为可以通过训练策略来模仿专家行为的洞察力,以产生二分类器错误为专家的行为。
在这项工作中,我们将GAIL应用于模拟人类高速公路驾驶行为的任务。我们的主要贡献是双重的。首先,我们将GAIL扩展到递归神经网络的优化,表明此类策略比前馈策略更忠实于专家行为。其次,我们将我们的模型应用于现实的高速公路模拟器,其中专家演示由NGSIM数据集中包含的真实世界驾驶员轨迹提供[18,19]。我们证明了GAIL优化的政策网络捕获了早期IL模型的许多理想属性,例如重现紧急驾驶员行为并为专家行动分配高可能性,同时降低了长距离高速公路模拟所需的碰撞和越野率。与过去的工作不同,我们的模型学习将原始激光雷达读数和简单、精心挑选的道路特征映射到连续动作,每个时间节点仅调整转弯率和加速度。
二、问题表述
我们将高速公路驾驶视为一个顺序决策任务,其中驾驶员服从随机策略π(a | s)将观察到的道路状况映射到驾驶行为的分布a。给定一类由θ参数化的策略![]() ,我们寻求找到最能模仿人类驾驶行为的策略。我们采用 IL 方法从由一系列状态操作元组
,我们寻求找到最能模仿人类驾驶行为的策略。我们采用 IL 方法从由一系列状态操作元组![]() 组成的数据集推断此策略。IL可以使用BC或强化学习来完成。
组成的数据集推断此策略。IL可以使用BC或强化学习来完成。
2.1、行为克隆
行为克隆解决了一个回归问题,其中通过训练数据中,使采取的动作概率最大化来获得策略参数。BC 在覆盖训练数据的状态分布表现的很充分,但是它强制泛化到对于没有数据覆盖状态(s)的预测动作(a),可能导致不好的行为。不幸的是,即使模拟是在通用状态下初始化的,策略的随机性质也允许行动预测中的小误差随着时间的推移而复合,最终导致人类驾驶员不经常访问的状态,并且没有被训练数据充分覆盖。较差的预测会导致称为级联误差的反馈周期[20]。
在高速公路驾驶环境中,级联错误可能导致越野驾驶【乱开】和碰撞。数据集很少包含有关人类驾驶员在这些环境中的行为信息,这可能导致BC政策在遇到此类状态时行为不规律。
行为克隆已成功用于为简单行为(例如高速公路上的汽车跟随)生成驾驶策略,其中状态和动作空间可以被训练集充分覆盖。当应用于学习具有细微行为和驶出车道潜力的一般驾驶模型时,BC 只能产生长达几秒钟的准确预测 [5, 6]。
2.2、强化学习
相反,强化学习(RL)假设现实世界中的驾驶员遵循专家策略![]() ,其行动最大化预期的全局回报。
,其行动最大化预期的全局回报。

按折扣系数加权γ ∈ [0, 1)。局部奖励函数 r(st,at) 可能是未知的,但可以完全表示专家行为,因此任何优化 R(π, r) 的策略都与![]() 无法区分。
无法区分。
在顺序决策的背景下,R(π,r)的学习比最大似然BC有几个优势[21]。首先,为所有状态操作对定义了r(st,at),允许代理接收学习信号,即使是来自异常状态。相比之下,BC 只接收标记的有限数据集中表示的那些状态的学习信号。
其次,与标签不同,奖励允许学习者在轻度不良行为(例如,急刹车)和极其不良的行为(例如,碰撞)之间建立偏好。最后,RL最大化了轨迹上的全局回报,而不是每个观察的局部指令。一旦了解了偏好,策略现在可能会采取轻微的不良行动,以避免以后出现可怕的情况。因此,强化学习算法提供了针对级联错误的鲁棒性。
三、策略表示
我们学到的策略必须能够捕捉人类的驾驶行为,其中包括:
- 从状态到动作的所需映射的非线性(例如,转向中的大修正以避免当前状态的微小变化引起的碰撞)。
- 状态表示的高维性,除了周围的汽车和道路状况外,还必须描述自我车辆的属性。
- 随机性,因为人类每次遇到给定的交通场景时可能会采取不同的行动。
为了解决第一点和第二点,我们使用神经网络表示所有学习的策略![]() 。为了解决第三点,我们将给定输入
。为了解决第三点,我们将给定输入 的网络输出的真实值解释为高斯分布的对角协方差对数
的网络输出的真实值解释为高斯分布的对角协方差对数 ![]() 的平均
的平均 ![]() 和对数。通过在
和对数。通过在  ∼
∼ ![]() ( | ) 采样来选择动作。前馈模型示例如图 2 所示。我们评估前馈和循环网络架构。
( | ) 采样来选择动作。前馈模型示例如图 2 所示。我们评估前馈和循环网络架构。
前馈神经网络直接将输入映射到输出。最常见的架构是多层感知器(MLP),由可调权重和元件非线性的交替层组成。神经网络因其能够从复杂的输入中学习强大的分层特征而广受欢迎[22,23],并已用于汽车行为建模,用于汽车跟随环境中的活动预测[6,24-27],横向位置预测[28]和机动分类[29]。
前馈 MLP 在充分处理部分可观察环境的能力方面受到限制。在实际驾驶中,传感器误差和遮挡可能会阻止驾驶员看到驾驶状态的所有相关部分。通过在记忆中保持过去观察的足够统计数据,循环策略[30,31]通过对观察的历史而不是个体观察采取行动来消除感知相似状态的歧义。在这项工作中,我们表示使用门控循环单元(GRU)网络的循环策略,因为它们的性能与其他架构相比具有可比的性能和更少的参数[32]。
我们对前馈和循环策略使用类似的架构。循环策略由五个前馈层组成,其大小从 256 个神经元减少到 32 个神经元,还有一个由 32 个神经元组成的额外 GRU 层。指数线性单位(ELU)在整个网络中使用,已被证明可以解决梯度消失问题,同时支持激活向量的零中心分布[33]。
MLP 策略具有相同的体系结构,只是 GRU 层被替换为额外的前馈层。对于每个网络架构,一个策略通过 BC 训练,一个策略通过 GAIL 训练。总的来说,我们训练了四种神经网络策略:GAIL GRU、GAIL MLP、BC GRU 和 BC MLP。
四、策略优化
与用传统管理技术训练的不列颠哥伦比亚相反,强化学习政策没有针对个人行为的培训标签。控制器性能改为通过预期回报进行评估。这种方法在对人类驾驶员进行建模时存在问题,因为奖励函数r(,)是未知的。我们首先讨论一种使用已知奖励函数训练策略的方法,然后提供一种学习奖励函数的方法。
4.1. 信任区域策略优化
策略梯度算法是一类特别有效的强化学习技术,用于优化可微策略,包括神经网络。与标准反向传播一样,网络参数使用基于梯度的更新进行优化,但梯度只能通过与环境交互的策略的模拟推出来近似。
这种经验梯度估计通常表现出很大的方差。在实践中,这种差异可能导致参数更新不会改善甚至降低性能。在这项工作中,我们使用信任区域政策优化(TRPO)来学习我们的人类驾驶政策[34]。TRPO 通过约束优化过程更新策略参数,该过程强制策略不能在单次更新中更改太多,从而限制噪声梯度估计可能造成的损害。
尽管控制任何特定人类驾驶员行为的真正奖励函数是未知的,但领域知识可用于制作代理奖励函数,以便最大化此数量的策略将实现与πE类似的随机状态-操作映射。驾驶员避免碰撞和越野,同时也有利于平稳驾驶并最大限度地减少车道偏移。如果这些特征可以组合成一个奖励函数,与人类驾驶r(st,at)的真实奖励函数非常接近,那么建模驾驶员行为就简化为RL。然而,手工制作准确的奖励函数通常很困难,这激发了使用生成对抗模仿学习。
4.2、生成对抗模仿学习
虽然 r(,) 是未知的,但代理奖励 r ̃(,) 可以直接从数据中学习,而无需利用领域知识。GAIL [17] 通过奖励那些能“欺骗”经过训练来区分策略和专家状态行动对的分类器的策略,从而训练策略逐渐具备执行类似专家的行为。考虑一组从![]() 采样的模拟状态-操作对
采样的模拟状态-操作对 ![]() = {(s1, a1), (s2, a2), ..., (sT , aT )} 和一组从
= {(s1, a1), (s2, a2), ..., (sT , aT )} 和一组从 ![]() 采样的专家对
采样的专家对 ![]() 。
。
对于一个神经网络 ![]() 由 ψ 参数化,GAIL 目标由下式给出:
由 ψ 参数化,GAIL 目标由下式给出:

当拟合ψ时,方程(2)可以简单地解释为一个sigmoid交叉熵目标,通过小批量梯度上升最大化。正示例从![]() 中采样,负示例从
中采样,负示例从![]() 与仿真环境交互生成的卷展中采样。然而,V(θ,ψ)相对于θ是不可微的,需要通过RL进行优化。
与仿真环境交互生成的卷展中采样。然而,V(θ,ψ)相对于θ是不可微的,需要通过RL进行优化。
为了拟合![]() ,可以从方程(2)中将代理奖励函数表述为:
,可以从方程(2)中将代理奖励函数表述为:
 当从
当从 ![]() 描述的元组 (, ) 与基于
描述的元组 (, ) 与基于 ![]() 预测的
预测的 ![]() 元素无法区分时,它接近无穷大。使用一组给定的策略参数 θ 执行推出后,将计算代理奖励 r ̃(st, at; ψ),并使用 TRPO 执行策略更新。尽管r ̃(st,at;ψ)可能与专家优化的真实奖励函数有很大不同,但它可用于将
元素无法区分时,它接近无穷大。使用一组给定的策略参数 θ 执行推出后,将计算代理奖励 r ̃(st, at; ψ),并使用 TRPO 执行策略更新。尽管r ̃(st,at;ψ)可能与专家优化的真实奖励函数有很大不同,但它可用于将 驱动到类似于
驱动到类似于![]() 的状态作用空间区域。
的状态作用空间区域。
五、数据集
我们使用美国 101 号高速公路 [19] 和 80 号州际公路 [18] 的公共下一代仿真 (NGSIM) 数据集。NGSIM为每条道路提供45分钟的10Hz驾驶。美国 101 号公路数据集覆盖洛杉矶的一个区域,长约 640 米,有 5 条主线车道和 6 条用于高速公路出入口的辅助车道。80 号州际公路数据集覆盖旧金山湾区长约 500 m 的区域,有六条主线车道,包括一条高占用率车辆车道和一个入口匝道。
两个数据集中的交通密度都从不拥堵过渡到完全拥堵,并且当车辆在高速公路上和高速公路上并流并且必须在拥挤的流量中行驶时,表现出高度的车辆交互。驾驶条件的多样性和交通参与者的强制互动使这些来源对行为研究特别有用。在自行车模型上使用扩展卡尔曼滤波器[35]对轨迹进行平滑处理,并使用从NGSIM CAD文件中提取的中心线投影到车道上。数据集中包括汽车、卡车、公共汽车和摩托车,但只有汽车轨迹用于模型训练。
六、实验
在这项工作中,我们使用GAIL和BC来学习二维高速公路驾驶的策略。随后相对于基线模型评估这些策略的性能。
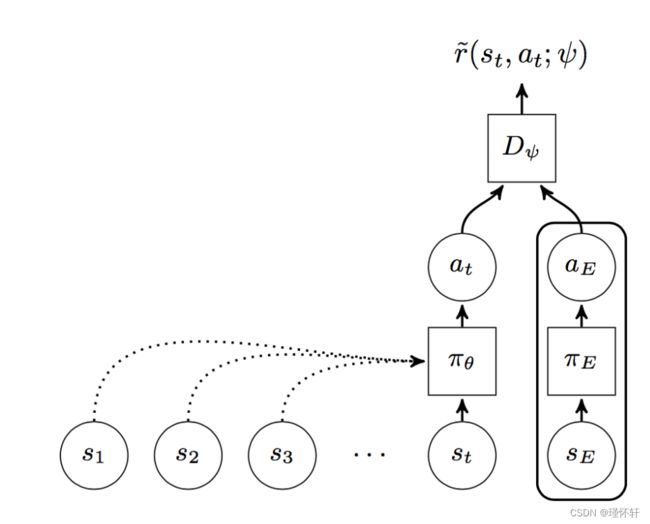
图1:GAIL。圆圈表示值,矩形表示操作,虚线箭头表示重复关系。虽然策略 状态 和操作 在 和 ![]() 的训练期间由鉴别器
的训练期间由鉴别器![]() 评估,但专家的(s,a)仅在训练
评估,但专家的(s,a)仅在训练 ![]() 时采样。
时采样。
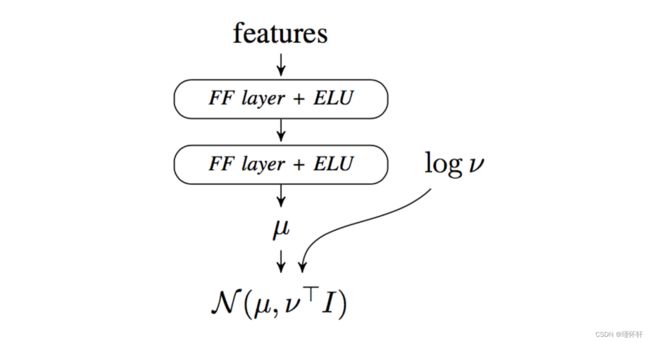
图2:前馈多层感知器驱动策略的架构。网络输出μ和协方差参数 ν 用于构建驱动程序操作的高斯分布。
6.1、实验过程
所有实验均使用rllab强化学习框架进行[36]。仿真环境是NGSIM 80和101道路网络上的驾驶模拟。初始化模拟以匹配NGSIM数据中的帧,并从帧中的交通参与者中随机选择自我车辆【主车】。模拟以 10 Hz 运行 100 步,如果自我车辆发生碰撞、越野驾驶或倒车驾驶,则提前结束。
自我车辆根据自行车模型驱动,加速度和转弯率从策略网络采样。所有其他交通参与者直接从NGSIM数据中重放,但在与ego车辆即将发生追尾碰撞时,会通过紧急制动进行增强。具体来说,如果智能驾驶员模型 (IDM) [3] 预测的加速度小于 −2m/![]() 的激活阈值,则车辆将根据 IDM 加速,同时跟踪最近的车道中心线。IDM 的参数设置为与车辆过渡时速度相等的所需速度、1m 的最小间距、0.5 s 的期望时间前进、3 m/
的激活阈值,则车辆将根据 IDM 加速,同时跟踪最近的车道中心线。IDM 的参数设置为与车辆过渡时速度相等的所需速度、1m 的最小间距、0.5 s 的期望时间前进、3 m/![]() 的标称加速度和 2.5 m/
的标称加速度和 2.5 m/![]() 的舒适制动减速。
的舒适制动减速。
6.2、特征
所有实验都使用相同的特征集。这些特征可以分解为三组。第一组是核心特征,是八个标量值,提供有关车辆里程计、尺寸和车道相对自我状态的基本信息。这些列于表I中。

仅凭核心特征不足以描述当时情况。还必须纳入有关相邻车辆和当地道路结构的信息。有几种方法可以将这些信息编码为与驾驶任务相关的手动选择特征[37]。 我们没有将模型限制为车辆关系的子集,而是引入了更通用和灵活的特征表示。
除了核心特征外,车辆还使用一组类似激光雷达的光束来收集有关其周围环境的信息。这些光束测量被它们击中的第一辆车的距离和射程率,直至最大范围。我们的工作使用的最大范围为100 m,具有20个范围和范围速率光束,每个光束均匀分布在自我周围的360°完整覆盖中车辆中心,如图3所示。
最后,使用一组三个指标特征来识别当自我车辆遇到不良状态时。每当自我车辆发生碰撞、驶离道路或倒车行驶时,这些特征的值为 1,否则为零。所有特征都连接成一个 51 个元素向量并馈送到每个模型中。
主车先前采取的行动不包括在提供给策略的功能集中。我们发现,策略可能会过度依赖以前的行动,而牺牲了对输入中包含的其他功能的依赖。为了解决这个问题,我们研究了在训练过程早期用随机噪声替换先前动作的效果。然而,人们发现,即使有这些缓解措施,纳入以前的行动也会对策略绩效产生不利影响。

图3:用于测量范围和距离速率的类似激光雷达的光束。
6.3、基本模型
我们用来与深度策略进行比较的第一个基线是静态高斯 (SG) 模型,它是使用最大似然拟合的不变高斯分布π(a | s) = N (a | μ, Σ)。
第二个基线模型是使用混合回归(MR)的BC方法[6]。该模型已用于模型预测控制,并已被证明在仿真和实际路测中效果良好。我们的MR模型是动作和特征的联合空间上的高斯混合,使用期望最大化进行训练[38]。随机策略由以特征为条件的高斯分量的加权组合形成。在训练期间使用贪婪特征选择来选择预测因子的子集,直至达到最大特征计数阈值,同时最小化贝叶斯信息标准[39]。
最终的基线模型使用基于规则的控制器来控制自我车辆的横向和纵向运动。纵向运动由智能驾驶员模型控制,其参数与仿真环境中使用的紧急制动控制器相同。对于横向运动,美孚 [4] 用于选择所需的车道,比例控制器用于跟踪车道中心线。在横向和纵向加速度中都会增加少量噪声,使控制器不确定。
6.4、验证
为了评估每个模型的相对性能,执行了系统的验证程序。对于每个模型,在与用于训练 GAIL 策略的环境相同的环境中模拟 1,000 个 10 秒场景,每个场景模拟 20 次。在执行这些部署时,提取了几个指标来量化每个模型模拟人类驾驶员行为的能力。
1)加权平方根误差:加权平方根误差(RWSE)捕获模型概率质量与真实世界轨迹的偏差[40]。对于m轨迹上的预设变量v,我们通过对每个记录的轨迹进行采样n = 20条模拟迹线来估计RWSE:

其中 ![]() 是时间第 i 条轨迹中的真实值j 表示时间视界 H 处的第 i 条轨迹。我们在预测全局位置、中心线偏移和速度(最长 5 秒)中提取 RWSE。
是时间第 i 条轨迹中的真实值j 表示时间视界 H 处的第 i 条轨迹。我们在预测全局位置、中心线偏移和速度(最长 5 秒)中提取 RWSE。
2)Kullback-Leibler散度:驱动模型应该在涌现量上产生与真实世界数据中观察到的分布相匹配的分布。对于每个模型,计算了模拟轨迹上速度、加速度、转弯率、加加速度【变加速度】和逆碰撞时间 (iTTC) 的经验分布。模拟分布和真实世界分布之间的接近性使用Kullback-Leibler(KL)散度进行量化。使用具有 100 个均匀分布箱的分段均匀分布。
3)紧急行为:我们还提取了一组指标,这些指标表明与NGSIM数据集相关的模型模仿性能。这些附加指标是车道变换率、失控持续时间、碰撞率和急刹车率。
变道率是车辆在 10 秒轨迹内变道的平均次数。失控持续时间是车辆在最近的外路标记外花费超过 1m 的每条轨迹的平均时间步数。碰撞率是主车与另一个交通参与者相交的轨迹分数。刹车率捕获模型选择比 −3 m/ 更大刹车加速度的频率。
更大刹车加速度的频率。
进行验证的环境并不完全现实,因为非主车具有预先记录的轨迹,并且并不总是正确响应主车偏离其原始轨迹,从而导致人为的大量碰撞。因此,我们还提取了硬刹车率,以帮助量化危险驾驶情况发生的频率。
七、结果
加权平方根误差的验证结果如图 4 所示。加权平方根误差结果表明,前馈BC模型具有最佳的短视距性能,但在较长的时间范围内开始累积误差。GAIL产生更稳定的轨迹,短期预测表现良好。人们可以清楚地看到控制器贴在车道中心线上,因此其车道偏移误差接近恒定的 0.5,这表明人类驾驶员并不总是密切跟踪最近的车道中心线。
KL 分化分数如图 5 所示。KL发散结果显示,除了加加速度【jerk】之外,SG在所有方面都有非常好的跟踪。SG 不能过度拟合,并且始终采取平均操作。它在其他指标中的表现很差。GAIL GRU在iTTC,速度和加速度指标上表现良好。它在转弯率和混蛋方面表现不佳。
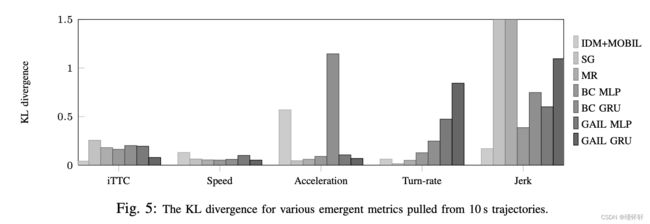


图 4:每个候选模型的加权平方根误差与预测范围的关系。深度策略优于其他方法。
这种糟糕的表现可能是由于平均而言,GAIL GRU 策略采取与人类类似的行动,但在行动之间比人类更不稳定。例如,它不会在直路段上输出零转弯率,而是在输出小的正转弯率和负转弯率之间交替。与GAIL策略相比,iTTC的BC策略更差。GRU版本在加速度方面具有最大的KL分歧,主要是由于其加速度通常很小,但在转弯率和加加速度方面表现相当不错。
涌现变量的验证结果如图 6 所示。涌现的结果观表明,GAIL 策略优于 BC 策略。GAIL GRU 策略最接近与除强制刹车以外的所有位置的数据匹配(它很少采取极端行动)。混合回归在很大程度上比 SG 性能更好,并且与 BC 策略相当,但仍容易受到级联错误的影响。失控持续时间可能是最引人注目的统计数据;只有GAIL(当然还有IDM + MOBIL)能够长时间在路上行驶。SG 从不急刹车,因为它只直行,因此碰撞率很高。有趣的是,IDM + MOBIL的碰撞率与GAIL GRU的碰撞率大致相同,尽管IDM + MOBIL不应该发生碰撞。模拟环境中的其他车辆无法对主车做出充分反应,这也许可以解释这种现象。
结果表明,基于 GAIL 的模型捕获了基于规则和机器学习方法的许多理想属性,同时避免了常见的陷阱。除了手动编码的控制器外,GAIL 策略实现了最低的碰撞和失控驾驶率,优于基线和类似结构的 BC 模型。然而,GAIL 也实现了比任何其他方法更接近真实人类驾驶的车道变换率。
此外,将GAIL扩展到经常性策略可以提高绩效。这一结果与BC政策形成了有趣的对比,在BC策略中,增加复发在很大程度上不会带来更好的结果。因此,我们发现重复本身不足以解决级联错误可能对BC策略产生的不利影响。
八、结论
本文证明了深度学习作为训练驾驶员模型的一种手段的有效性,这些模型在长时间范围内逼真地执行,同时捕捉微观的、类似人类的行为。我们的贡献是(1)将生成对抗模仿学习扩展到经常性策略的优化,以及(2)将这种技术应用于创建一种新的,智能的高速公路驾驶模型,该模型在几个指标上优于最先进的技术。尽管行为克隆在短时间(∼2秒)内的表现仍然优于生成对抗模仿学习,但其贪婪的行为使其无法在较长时间内实现逼真的驾驶。通过生成对抗模仿学习使用策略优化,使我们能够克服级联误差的问题,从而产生长期、稳定的轨迹。此外,深度递归神经网络使用策略表示使我们能够直接从通用传感器输入(即 LIDAR 距离和距离速率)中学习,这些输入可以捕获任意交通状态并模拟部分可观测性。
我们认为,包含代理奖励函数的强化学习方案克服了高速公路驾驶员建模中监督学习引起的问题。因此,未来的工作可能希望探索将其他奖励信号与我们自己的信号相结合的方法。虽然生成对抗模仿学习捕获数据集中存在的类似人类的行为,但模拟器也可能希望通过将学习的代理奖励与由精心挑选的特征制作的奖励函数相结合来强制执行某些行为(例如,显式建模驾驶员风格)。工程奖励函数也可用于惩罚GAIL GRU产生的加速度和转弯率振荡。最后,我们提供了人类驾驶行为模型,作为模拟真实高速公路条件的重要元素。未来的工作将把我们的模型应用于决策和安全验证。与本文相关的代码可以在 https://github.com/sisl/gail-driver 中找到。
九、参考文献
[1] P. A. Seddon, “A program for simulating the disper- sion of platoons of road traffic”, Simulation, vol. 18, no. 3, pp. 81–90, 1972.
[2] P. G. Gipps, “A behavioural car-following model for computer simulation”, Transportation Research Part B: Methodological, vol. 15, no. 2, pp. 105–111, 1981.
[3] M. Treiber, A. Hennecke, and D. Helbing, “Congested traffic states in empirical observations and micro- scopic simulations”, Physical Review E, vol. 62, no. 2, p. 1805, 2000.
[4] A. Kesting, M. Treiber, and D. Helbing, “General lane-changing model mobil for car-following models”, Journal of the Transportation Research Board, 2007.
[5] T. A. Wheeler, P. Robbel, and M. Kochenderfer, “Analysis of microscopic behavior models for prob- abilistic modeling of driver behavior”, in IEEE In- ternational Conference on Intelligent Transportation Systems (ITSC), 2016.
[6] S. Lefe`vre, C. Sun, R. Bajcsy, and C. Laugier, “Com- parison of parametric and non-parametric approaches for vehicle speed prediction”, American Control Con- ference (ACC), pp. 3494–3499, 2014.
[7] T. Gindele, S. Brechtel, and R. Dillmann, “Learning context sensitive behavior models from observations for predicting traffic situations”, in IEEE Interna- tional Conference on Intelligent Transportation Sys- tems (ITSC), 2013.
[8] G. Agamennoni, J. Nieto, and E. Nebot, “Estimation of multivehicle dynamics by considering contextual information”, IEEE Transactions on Robotics, vol. 28, no. 4, pp. 855–870, 2012.
[9] D. A. Pomerleau, “ALVINN: an autonomous land vehicle in a neural network”, DTIC Document, Tech. Rep. AIP-77, 1989.
[10] M. Bojarski, D. Del Testa, D. Dworakowski, B. Firner, B. Flepp, P. Goyal, L. Jackel, M. Monfort, U. Muller, J. Zhang, X. Zhang, and J. Zhao, “End to end learning for self-driving cars”, IEEE Computer Society Con- ference on Computer Vision and Pattern Recognition (CVPR), 2016.
[11] U. Syed and R. E. Schapire, “A game-theoretic ap- proach to apprenticeship learning”, in Advances in Neural Information Processing Systems (NIPS), 2007.
[12] S. Ross and J. Bagnell, “Efficient reductions for imitation learning”, in International Conference on Artificial Intelligence and Statistics, 2010.
[13] J. Ho, J. K. Gupta, and S. Ermon, “Model-free imita- tion learning with policy optimization”, arXiv preprint arXiv:1605.08478, 2016.
[14] P. Abbeel and A. Y. Ng, “Apprenticeship learning via inverse reinforcement learning”, in International Conference on Machine Learning (ICML), 2004.
[15] D. S. Gonza ́lez, J. Dibangoye, and C. Laugier, “High- speed highway scene prediction based on driver mod- els learned from demonstrations”, in IEEE Interna- tional Conference on Intelligent Transportation Sys- tems (ITSC), 2016.
[16] D. Sadigh, S. Sastry, S. A. Seshia, and A. D. Dragan, “Planning for autonomous cars that leverages effects on human actions”, in Robotics: Science and Systems, 2016.
[17] J. Ho and S. Ermon, “Generative adversarial imitation learning”, arXiv preprint arXiv:1606.03476, 2016.
[18] J. Colyar and J. Halkias, “US highway 80 dataset”, Federal Highway Administration (FHWA), Tech. Rep. FHWA-HRT-06-137, 2006.
[19] J. Colyar and J. Halkias, “US highway 101 dataset”, [29] Federal Highway Administration (FHWA), Tech. Rep. FHWA-HRT-07-030, 2007.
[20] J. A. Bagnell, “An invitation to imitation”, DTIC Document, Tech. Rep. CMU-RI-TR-15-08, 2015.
[21] R. S. Sutton and A. G. Barto, Reinforcement Learning: [30] An Introduction, 1. MIT Press, 1998.
[22] H. Lee, R. Grosse, R. Ranganath, and A. Y. Ng, “Convolutional deep belief networks for scalable un- [31] supervised learning of hierarchical representations”,
in International Conference on Machine Learning (ICML), 2009.
[23] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks”, in Advances in Neural Information Pro- cessing Systems (NIPS), 2012.
[24] J. Hongfei, J. Zhicai, and N. Anning, “Develop acar-following model using data collected by ”five-wheel system””, in IEEE International Conferenceon Intelligent Transportation Systems (ITSC), vol. 1,2003.
[25] S. Panwai and H. Dia, “Neural agent car-following models”, IEEE Transactions on Intelligent Trans- portation Systems, vol. 8, no. 1, pp. 60–70, 2007.
[26] A. Khodayari, A. Ghaffari, R. Kazemi, and R. Braun-stingl, “A modified car-following model based on a neural network model of the human driver effects”, IEEE Transactions on Systems, Man, and Cybernetics,vol. 42, no. 6, pp. 1440–1449, 2012.
[27] J. Morton, T. A. Wheeler, and M. J. Kochenderfer, “Analysis of recurrent neural networks for probabilistic modeling of driver behavior”, IEEE Transactions on Intelligent Transportation Systems, 2016.
[28] Q. Liu, B. Lathrop, and V. Butakov, “Vehicle lateral position prediction: a small step towards a compre- [38] hensive risk assessment system”, in IEEE Interna-tional Conference on Intelligent Transportation Sys- [39] tems (ITSC), 2014.
[29]P. Boyraz, M. Acar, and D. Kerr, “Signal modelling and hidden Markov models for driving manoeuvre recognition and driver fault diagnosis in an urban road scenario”, in IEEE Intelligent Vehicles Symposium, 2007.
[30] D. Wierstra, A. Fo ̈rster, J. Peters, and J. Schmidhuber, “Recurrent policy gradients”, Logic Journal of IGPL, vol. 18, no. 5, pp. 620–634, 2010.
[31] N. Heess, J. J. Hunt, T. P. Lillicrap, and D. Silver, “Memory-based control with recurrent neural net- works”, arXiv preprint arXiv:1512.04455, 2015.
[32] J. Chung, C. Gulcehre, K. Cho, and Y. Ben- gio, “Empirical evaluation of gated recurrent neu- ral networks on sequence modeling”, arXiv preprint arXiv:1412.3555, 2014.
[33]D.-A. Clevert, T. Unterthiner, and S. Hochreiter, “Fast and accurate deep network learning by exponential lin- ear units (ELUs)”, arXiv preprint arXiv:1511.07289, 2015.
[34] J. Schulman, S. Levine, P. Abbeel, M. I. Jordan, and P. Moritz, “Trust region policy optimization”, in In ternational Conference on Machine Learning (ICML), 2015.
[35] R. E. Kalman, “A new approach to linear filtering and prediction problems”, Journal of Basic Engineering, vol. 82, no. 1, pp. 35–45, 1960.
[36]Y. Duan, X. Chen, R. Houthooft, J. Schulman, and P. Abbeel, “Benchmarking deep reinforcement learning for continuous control”, arXiv preprint arXiv:1604.06778, 2016.
[37] C. Chen, A. Seff, A. Kornhauser, and J. Xiao, “Deep- Driving: Learning affordance for direct perception in autonomous driving”, in IEEE International Confer- ence on Computer Vision (ICCV), 2015.
[38] J. Friedman, T. Hastie, and R. Tibshirani, The Ele- ments of Statistical Learning. Springer, 2001.
[39] G. Schwarz, “Estimating the dimension of a model”, The Annals of Statistics, vol. 6, no. 2, pp. 461–464, 1978.
[40] J. Cox and M. J. Kochenderfer, “Probabilistic airport acceptance rate prediction”, in AIAA Modeling and Simulation Conference, 2016.