DeU-Net: 用于三维心脏mri视频分割的可变形(Deformable)U-Net
论文链接:https://arxiv.org/abs/2007.06341
代码链接:文章都看完了实在找不到代码!好崩溃!好崩溃!已经发邮件联系作者!
摘要
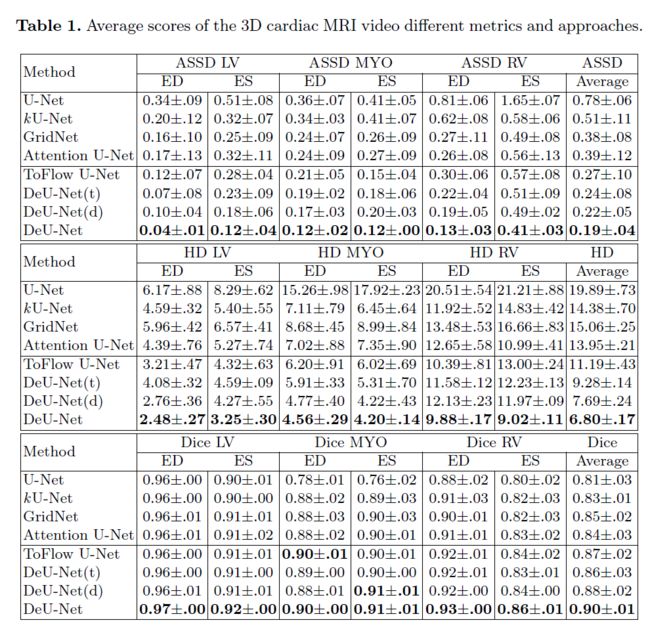
心脏磁共振成像(MRI)的自动分割促进了临床应用中高效、准确的体积测量。然而,由于分辨率各向异性和边界模糊(如右心室心内膜),现有方法在心脏MRI三维视频分割中存在准确性和鲁棒性下降的问题。在本文中,我们提出了一种新的可变形U-Net (DeUNet)来充分利用3D心脏MRI视频的时空信息,包括一个时间可变形聚合模块(TDAM)和一个可变形全局位置注意(DGPA)网络。首先,TDAM以心脏MRI视频片段作为输入,并通过偏移预测网络提取时间信息。然后通过时间聚合可变形卷积对提取的时间信息进行融合,生成融合特征图。此外,为了聚合有意义的特征,我们采用可变形注意力U-Net设计了DGPA网络,该网络可以将更大范围的多维上下文信息编码为全局和局部特征。实验结果表明,我们的DeU-Net在常用的评估指标上达到了最先进的性能,特别是在心脏边缘信息(ASSD和HD)方面。
背景
在本文中,我们提出了一种新的变形U-Net (DeU-Net)来解决上述问题,通过充分利用三维心脏MRI视频的时空信息并聚合时间信息来提高分割性能。DeU-Net由两个部分组成:时间变形聚合模块(TDAM)和可变形全局位置注意网络(DGPA)。为了解决[13,14]中RV的部分体积效应,TDAM利用MRI视频片段的时空信息,通过时间聚合可变形卷积产生融合的特征图。为了解决[6]中的细微结构问题,基于U-Net的DGPA网络将更广泛的多维上下文信息联合编码为全局和局部特征,保证了每个分割图的边界清晰连续。定量和定性的实验结果表明,我们的建议在常用的指标上达到了最先进的性能,特别是对于心脏边缘信息(ASSD和HD)。
方法
DeU-Net的架构如图1所示,包括一个时态可变形聚合模块(TDAM)和一个可变形全球位置注意(DGPA)网络。提出的TDAM包括两个阶段:一个是时间可变形卷积,另一个是基于U-Net的偏移量预测网络,用于预测可变形偏移量。将TDAM产生的融合特征输入到DGPA中,得到最终的分割结果。同样以U-Net为骨干的DGPA网络为编码器引入了可变形卷积,并利用可变形注意块来增加空间采样位置。

Temporal Deformable Aggregation Module(TDAM)
许多现有的方法设计了非常复杂的神经网络来实现性能增益。然而,大多数方法忽略了3D MRI视频的时空信息,并将每一帧视为一个单独的对象,从而导致性能下降。此外,在数据采样过程中,由于心脏边界的快速变化和规则的卷积,可能会丢失视频片段的各种语义细节,不可避免地会扭曲视频局部细节和帧之间逐像素的连接。因此,我们提出了一个时间变形聚合模块(TDAM)来自适应地提取图像解释的时间信息(运动场)。
提出的TDAM以目标帧及其相邻参考帧作为输入,共同预测偏移场。然后,通过时间聚合可变形卷积将增强的上下文信息融合到目标帧中。
我这里先略写一下因为我主要要看的部分是DGPA...后面再补吧


Deformable Global Position Attention(DGPA)
正则卷积受核大小和固定几何结构的限制,在几何变换建模中性能有限。在实践中,由于心脏实例之间的边界不明确,很难减少假阳性预测。
为了解决这些问题,我们提出了一个可变形的全球位置注意(DGPA)网络来捕获足够大的接受野和语义全球上下文信息。DGPA通过额外的偏移量来增加模块中的空间采样位置,这是为了模拟复杂的几何变换。因此,可以收集远程上下文信息,这有助于获得更具辨别性的心脏边界,用于像素级预测。

如图1所示,将融合的局部特征I 2 R NXHXW作为DGPA块的输入,其中N表示输入通道数,H和W分别表示输入特征的高度和宽度。(到时候再对比一下Deformable Conv原论文中插入的位置好了)
我们首先为输入特征I提供一个3X3可变形的卷积层来捕获心脏的几何信息。公式如下:
其中 是特征图,
是特征图,
K是可变形卷积核,l是卷积核大小,δ’是deformable offset
将输入特征映射重构为三个新的特征映射B,C,D ∈ R NXM
式中M为像素数(M = HXW)。

为了利用心脏边界的高级特征,在B和c的转置之间进行点积,然后将结果应用到softmax层中计算注意力图P∈ R NXN↓ 其中pji表示第i个像素对第j个像素的影响。两个像素的特征表示越相似,表明它们之间的相关性越强。
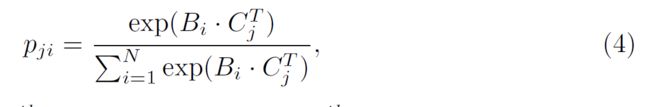
然后我们在P和D的转置之间进行矩阵乘法,将结果重塑为R NXHXW。
最后,对变形块中的特征映射O进行逐元素求和运算,得到输出特征Z ∈ R NXHXW如下:
式中α为属于位置亲和矩阵(position affinity matrix)的尺度参数。Z中的每个元素是全局特征的加权和,并选择性地聚合输入特征i。计算特征映射的远程依赖关系,以提高类内紧凑性和语义一致性。

实验
设备是NVIDIA GTX 1080Ti GPU。对于训练集,进一步使用标准数据增强(即镜像、轴向翻转或旋转)来更好地利用训练样本。我们使用Adam优化器来更新网络参数。初始学习率设置为2 104,权值衰减为1 104。我们使用的批量大小至少为12。设公式1中的参考帧数r为1。如果骰子分数没有增加20次,训练将停止。在我们的实验中,我们进行了5次交叉验证。
结果