《python趣味工具》——酷炫二维码(2):批量定制合适的二维码
今天,我们将学习如何从Excel中提取相应的内容然后批量生成相应的二维码。

文章目录
- 一、Excel的基本操作:
-
- 1. Excel的基本结构:
- 2. 安装xlrd模块:
- 3. 读取指定工作表:
- 4. 读取指定内容:
-
- Tip:切片读取:
- 5. 在Excel表中查找指定内容:
-
- (1 通过电话号码查找对应的用户:
- (2 将员工的信息逐行输出:
- (3 通过姓名查找其他个人信息:
- 二、 利用Excel表格信息生成对应二维码:
-
- 1. 获取文件夹中的文件名:
-
- (1 获取路径下所有文件【用户】名:
- (2 分割文件名获取文件名称:
- 2. 将姓名与文件名进行比对,生成对应二维码:
- 3. 生成用户对应二维码:
- 4. 把二维码保存到新的文件夹中:
- 三、完整源码:
通过需求分析,我们就得到了解决需求的步骤:
- 获取 Excel 中的姓名和电话;
- 获取文件夹中的文件名;
- 将姓名与文件名进行比对,生成对应二维码;
- 把二维码保存到新的文件夹中。
一、Excel的基本操作:
1. Excel的基本结构:
在开始获取表格数据前, 我们需要先学习一下 Excel 表格的基本结构。
汇总一下Excel表格的基本结构:
-
工作簿(Workbook):一个Excel表格文件。 -
工作表(Worksheet):在工作簿的左下方,可以切换和增删。 -
列(Column):默认从字母A开始,依次递增。超过字母Z后,以AA,AB的方式继续计数。 -
行(Row):从数字 1 开始,并依次递增。 -
单元格(Cell):通过列号和行号对单元格进行定位。

2. 安装xlrd模块:
接下来,我们要使用 Python 获取 Excel 表格文件。
在这里我们使用 xlrd 模块。
xlrd 不是一个内置模块,所以在使用前要先通过代码
pip install xlrd==1.2.0 进行安装。
如果在自己电脑上安装不上或安装缓慢,可在命令后添加
pip install xlrd==1.2.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
进行加速。
安装之后,使用 import 在代码中导入 xlrd 模块。
# 导入xlrd模块
import xlrd
xlrd 模块主要用来读取 Excel 表格数据,支持 .xls 和 .xlsx 类型的文件。

3. 读取指定工作表:
读取指定工作表可以通过下面这段代码来实现:
# 导入xlrd模块
import xlrd
# 将Excel文件路径/Users/minmin/资料.xlsx,赋值给变量path
path = "/Users/minmin/资料.xlsx"
# 读取path的工作簿并赋值给变量data
data = xlrd.open_workbook(path)
# print()输出data
print(data) #输出:, ]
# 使用sheet_names()获取工作表名称,赋值给变量names
names = data.sheet_names()
# print()输出names
print(names) #输出:['信息', '统计']
上面的代码,使用了 xlrd.open_workbook() 函数和 sheets() 函数,就可以读取 Excel 文件,返回一个指定工作表对象
-
调用函数:调用 xlrd.open_workbook() 函数,读取指定路径的工作簿,相当于打开了一份 Excel 文件。
-
指定路径:工作簿文件的路径需要作为函数参数传入。但如果文件就在代码运行的工作目录,就可以直接传入文件名。(就是绝对路径和相对路径的意思啦)
-
返回对象:xlrd.open_workbook() 函数读取成功后,会返回一个工作簿对象,本例中我们将这个对象赋值给了变量 data。
-
-
Sheet对象:通过调用工作簿的 sheets() 函数,获取所有工作表对象,并以列表方式显示。
如果事先不知道工作簿内有哪些工作表,我们可以通过调用工作簿的
sheet_names()函数,来获取一个包含所有工作表名称的列表。
接着,通过索引的方式来获得对应的工作表对象,并赋值给变量。
在本例中,获取工作簿中第一个工作表。
# 使用sheets()获取工作表对象,索引第一个工作表赋值给变量table
# 方法一:
tableList = data.sheets()
table = tableList[0]
# print()输出table
print(table) #输出:4. 读取指定内容:
读取到指定的工作表后,接下来就可以获取指定的内容。
在这里,我们要学习三种读取方式:
- 指定行;
- 指定列;
- 指定单元格。
# 读取path的工作簿并赋值给变量data
data = xlrd.open_workbook(path)
# 使用sheets()获取工作表对象,索引第一个元素赋值给变量table
table = data.sheets()[0]
# 通过调用工作表的 row_values() 函数,读取工作表中第2行数据,并以列表形式返回。
row_value = table.row_values(1)
print(row_value) # 输出:[35.0, '白涵', '女', 15085645407.0, '运营']
# 通过调用工作表的 col_values() 函数,读取工作表中第2列数据,并以列表形式返回。
col_value = table.col_values(1)
print(col_value) # 输出:['名字', '白涵', '白浩涆', '白赫然', '白英发', '白筠']
# 通过调用工作表的 cell_value() 函数,读取工作表中指定单元格数据,并返回单元格的值。这里返回第2行第4列的单元格数据.
cell_value = table.cell_value(1, 3)
print(cell_value)# 输出:15085645407.0
- 指定行
row_values()函数传入的参数是行数的索引,即下标从0开始
row_values(0),读取Excel的第 1 行数据;
row_values(1),读取Excel的第 2 行数据。
- 指定列
col_values()函数传入的参数是列数的索引,下标也从0开始
col_values(0),读取 Excel 的第 1 列数据;
col_values(1),读取 Excel 的第 2 列数据。
- 指定单元格
cell_value()函数的第一个参数为行索引,第二个参数为列索引,且下标都从0开始
cell_value(2, 3) 为第 3 行第 4 列的单元格的值;
cell_value(3, 7) 为第 4 行第 8 列的单元格的值。
Tip:切片读取:
学习了如何读取 Excel 文件指定内容后,现在我们需要读取表格中的名字(第二列)和电话(第四列)。
我们可以使用工作表的 col_values() 函数(返回值为一个列表),读取指定的列,由于表头是我们不需要的内容,所以这里要利用切片 [1:],从第二个元素开始读取!
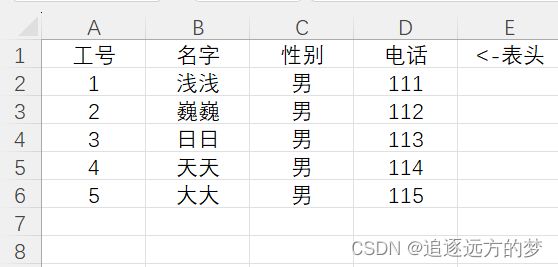
切片在前面的列表中有讲,想复习的同学可以去看看:https://eternity.blog.csdn.net/article/details/132748179?spm=1001.2014.3001.5502
(CSDN的博客阅读系统好像是用类似于栈的结构来实现的,所以你不必担心点击链接之后回不来的情况!)
# 读取工作表第2列非表头数据,赋值给变量allNames
allNames = table.col_values(1)[1:]
# 读取工作表第4列数据非表头数据,赋值给变量allNumbers
allNumbers=table.col_values(3)[1:]
# print()输出allNames和allNumbers
print(allNames)
print(allNumbers)
# 输出都应该是列表
5. 在Excel表中查找指定内容:
现在我们通过下面3个例子来看看如何在Excel表中查找我们需要的内容:

(1 通过电话号码查找对应的用户:
怎样通过电话号码查找到对应的用户是谁呢?
这里我们需要了解两个知识点:
1️⃣index() 函数:
用于从列表中找出某个值的索引位置,如:
nameList = ["Coco", "Yoyo", "Lily", "Anna"]
name = nameList.index("Anna")
print(name) # 3
2️⃣字典的运用:
当我们要定义一个dict操作时,可以使用下面的格式:
# 定义应一个字典:
productItems{"apple":10,"banana":20,"orange":30,"mango":40}
#输出字典
print(productItems)
# 输出字典中某个键的值
print(productItems["apple"])
# 修改字典中的“apple”为“苹果”
productItems["apple"]="苹果"
# 向字典中添加一个键值对
productItems["grapes"]=50
# 再次输出字典
print(productItems)
OK,下面我们来看看如何查找:
# 导入xlrd
import xlrd
# 将Excel文件夹路径/Users/minmin/资料.xlsx,赋值给变量path
path = "/Users/minmin/资料.xlsx"
# 读取path的工作簿并赋值给变量data
data = xlrd.open_workbook(path)
# 使用sheets()获取工作表对象,索引第一个元素复制给变量table
table = data.sheets()[0]
# 需要查询的电话
phoneList = [111,112,113,114,115]
# 新建一个字典name_dic
name_dic={}
# 调用col_values()和切片读取工作表第2列非表头数据,赋值给变量allNames
# 读取工作表第4列数据非表头数据,赋值给变量allNumbers
allNames=table.col_values(1)[1:]
allNumbers=table.col_values(3)[1:]
# for循环遍历phoneList赋值给num
for num in phoneList:
# 如果num在列表allNumbers中
if num in allNumbers:
# 通过index()函数查找num
# 赋值给变量index
index=allNumbers.index(num)
# 在字典中添加键值对
# 键为num,对应的值为列表allNames索引index的元素
name_dic[num]=allNames[index]
# 否则
else:
# 将"查无此人"赋值给字典中num对应的值
name_dic[num]= "查无此人"
# print()输出name_dic
print(name_dic)
(2 将员工的信息逐行输出:
想要逐行输出 Excel 表格数据,应该怎么做呢?
在这里,我们需要可以获取工作表中的总行数,然后一行一行的传入 row_values() 函数中,这样就可以按行输出数据了。
.nrows 属性可以获取工作表的行数,如下:
rows = table.nrows
print(rows)
示例代码如下:
# 导入xlrd模块
import xlrd
# 将Excel文件夹路径/Users/minmin/资料.xlsx,赋值给变量path
path = "/Users/minmin/资料.xlsx"
# 读取path的工作簿并赋值给变量data
data = xlrd.open_workbook(path)
# 使用sheets()获取工作表对象,索引第一个元素赋值给变量table
table = data.sheets()[0]
# 获取工作表的行数
rows=table.nrows
i=0
while i<rows:
row_value=table.row_values(i)
print(row_value)
i+=1
# for row in range(1,rows):
# data_row=table.row_values(row)
# print(data_row)
(3 通过姓名查找其他个人信息:
怎样做可以实现只要输入姓名,就可以找到该同事的全部信息。
步骤如下:
-
使用
input()函数输入查找员工姓名; -
遍历工作表,按行提取数据;
-
如果行数据中的第二个元素为员工姓名,就是输出这一行的数据。
工作表部分截图
示例代码如下:
# 导入xlrd模块
import xlrd
# 将Excel文件夹路径/Users/minmin/资料.xlsx,赋值给变量path
path = "/Users/minmin/资料.xlsx"
# 读取path的工作簿并赋值给变量data
data = xlrd.open_workbook(path)
# 使用sheets()获取工作表对象,索引第一个元素赋值给变量table
table = data.sheets()[0]
# 获取table的行数,并赋值给变量rows
rows = table.nrows
# 使用input()函数"请输入员工姓名:",将输入内容赋值给name
name=input("请输入员工姓名:")
# for循环遍历工作表非表头的行数,赋值给变量row
for row in range(1,rows):
# 使用row_values()得到工作表的对应行数据,并赋值给变量data_row
data_row=table.row_values(row)
# 如果data_row的第二个元素为name
if(data_row[1]==name):
# print()输出data_row
print(data_row)
# 退出循环
break
二、 利用Excel表格信息生成对应二维码:
步骤:
- 获取 Excel 中的姓名和电话;✅
- 获取文件夹中的文件名;
- 将姓名与文件名进行比对,生成对应二维码;
- 把二维码保存到新的文件夹中。
1. 获取文件夹中的文件名:
现将存有头像图片的文件夹放在路径 /Users/minmin/Selfie,我们需要获取的是该文件夹中所有的文件名称。
在这里,我们要分两步获取文件名称:
- 第一步,获取文件夹内全部的文件名;
- 第二步,分割文件名获取文件名称。
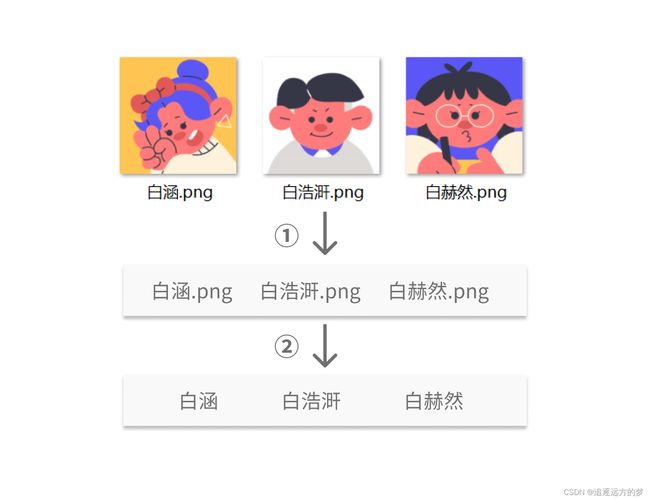
(1 获取路径下所有文件【用户】名:
# 要对文件进行处理,首先导入 os 模块
# os 模块是 Python 的内置模块,不需要安装可以直接导入。
import os
# 定义一个变量 pathFile 并将文件夹路径以字符串的格式赋值给它
pathFile = "/Users/yequ/picture"
# 调用 listdir() 函数获取文件夹中所有文件名,传入参数文件夹路径
allItems = os.listdir(pathFile)
# listdir()函数返回一个列表,列表中的每个元素是文件夹中的文件名。
print(allItems)
great!从文件夹中获取了全部的文件名,如果你在本地运行代码,输出文件夹中所有的文件名,就会有出现一个".DS_Store"
.DS_Store 是 Mac OS 保存文件夹的自定义属性的隐藏文件,如文件的图标位置或背景色,相当于 Windows 的 desktop.ini。
这个文件对我们的项目没有用处,在接下来的操作中,我们可以把它排除掉。
(2 分割文件名获取文件名称:
Python 中的内置函数 split() ,通过指定分隔符对字符串进行切片。
# 定义一个字符串
item = "qq.png"
# 将分隔符作为参数传入到 split() 函数中
# 即可把字符串按照指定分隔符切分成多个字符串组成的列表。
# 分隔符不会保留在分割后的字符串中。
fileName = item.split(".") # 输出列表
print(fileName)
# 由于 split() 函数返回的是分割后字符串组成的列表
# 而列表中的元素可以索引提取:
fileName1 = item.split(".")[0] # 输出前一个元素
print(fileName1)
好了,现在我们就能得到所有的文件名啦!
示例代码如下:
# 导入xlrd模块
import xlrd
# 导入os模块
import os
# 将Excel文件路径/Users/minmin/资料.xlsx,赋值给变量path
path = "/Users/minmin/资料.xlsx"
# 读取path的工作簿并赋值给变量data
data = xlrd.open_workbook(path)
# 使用sheets()获取工作表对象,索引第一个元素赋值给变量table
table = data.sheets()[0]
# 调用col_values()和切片读取工作表第2列非表头数据,赋值给变量allNames
# 读取工作表第4列数据非表头数据,赋值给变量allNumbers
allNames = table.col_values(1)[1:]
allNumbers = table.col_values(3)[1:]
# 将文件夹路径"/Users/minmin/Selfie",赋值给pathFile
pathFile = "/Users/minmin/Selfie"
# 使用os.listdir()函数获取该路径下所有文件名,并赋值给变量allItems
allItems = os.listdir(pathFile)
# for循环遍历allItems,赋值给变量item
for item in allItems:
# 如果item不等于".DS_Store"
if item != ".DS_Store":
# 通过"."分割文件名
# 索引第一个元素赋值给变量fileName
fileName = item.split(".")[0]
# print()输出fileName
print(fileName)
2. 将姓名与文件名进行比对,生成对应二维码:
接下来,我们要把文件名称与 Excel 文档中的姓名进行比对,找到对应的电话号码。
之前,我们已经把所有姓名存储在列表 allNames 中,所有电话存储在列表 allNumbers 中,这两个列表中的元素,是一 一对应的关系。也就是说,如果文件名称在列表 allNames 中,就找到该文件名称在列表 allNames 中的索引;通过索引也就能找到列表 allNumbers 中对应的电话号码。
如何查找列表中的元素的索引,上面已经说过了,使用 index() 函数,传入查找对象,返回对应的索引位置。
示例代码如下:
# 导入xlrd模块
import xlrd
# 导入os模块
import os
# 将Excel文件路径/Users/minmin/资料.xlsx,赋值给变量path
path = "/Users/minmin/资料.xlsx"
# 读取path的工作簿并赋值给变量data
data = xlrd.open_workbook(path)
# 使用sheets()获取工作表对象,索引第一个元素赋值给变量table
table = data.sheets()[0]
# 调用col_values()和切片读取工作表第2列非表头数据,赋值给变量allNames
# 读取工作表第4列数据非表头数据,赋值给变量allNumbers
allNames = table.col_values(1)[1:]
allNumbers = table.col_values(3)[1:]
# 将文件夹路径"/Users/minmin/Selfie",赋值给pathFile
pathFile = "/Users/minmin/Selfie"
# 使用os.listdir()函数获取该路径下所有文件名,并赋值给变量allItems
allItems = os.listdir(pathFile)
# for循环遍历allItems,赋值给变量item
for item in allItems:
# 如果item不等于".DS_Store"
if item != ".DS_Store":
# 通过"."分割文件名
# 索引第一个元素赋值给变量fileName
fileName = item.split(".")[0]
# 如果fileName在列表allNames中
if fileName in allNames:
# 查找fileName在列表allNames中的索引位置
# 赋值给变量index
index = allNames.index(fileName)
# 通过列表allNumbers索引index,赋值给变量phoneNumber
phoneNumber = allNumbers[index]
# print()输出phoneNumber
print(phoneNumber)
太好啦~我们根据文件名称,找到了对应的电话号码。

3. 生成用户对应二维码:
接下来,就要将电话号码与对应的头像作为参数值,传入生成二维码的代码里。
下面是生成二维码的一些常用函数:

我们这里通过4步来生成二维码:
-
首先,从
MyQR模块中导入myqr; -
调用
myqr.run()函数,传入参数 words,由于其类型为字符串,我们要使用str()函数,将变量 phoneNumber 从整型转换成字符串; -
传入参数 picture,设置参数值为头像路径,需要使用格式化将文件夹路径与文件名拼接,也就是 f"/Users/minmin/Selfie/{item}"。
-
添加参数
save_name,将二维码图片的文件名设置为对应的头像名 item。
示例代码如下:
# 导入xlrd模块
import xlrd
# 导入os模块
import os
# 使用from...import从MyQR模块中导入myqr
from MyQR import myqr
# 将Excel文件路径/Users/minmin/资料.xlsx,赋值给变量path
path = "/Users/minmin/资料.xlsx"
# 读取path的工作簿并赋值给变量data
data = xlrd.open_workbook(path)
# 使用sheets()获取工作表对象,索引第一个元素赋值给变量table
table = data.sheets()[0]
# 调用col_values()和切片读取工作表第2列非表头数据,赋值给变量allNames
# 读取工作表第4列数据非表头数据,赋值给变量allNumbers
allNames = table.col_values(1)[1:]
allNumbers = table.col_values(3)[1:]
# 将文件夹路径"/Users/minmin/Selfie",赋值给pathFile
pathFile = "/Users/minmin/Selfie"
# 使用os.listdir()函数获取该路径下所有文件名,并赋值给变量allItems
allItems = os.listdir(pathFile)
# for循环遍历allItems,赋值给变量item
for item in allItems:
# 如果item不等于".DS_Store"
if item != ".DS_Store":
# 通过"."分割文件名
# 索引第一个元素赋值给变量fileName
fileName = item.split(".")[0]
# 如果fileName在列表allNames中
if fileName in allNames:
# 查找fileName在列表allNames中的索引位置
# 赋值给变量index
index = allNames.index(fileName)
# 通过列表allNumbers索引index,赋值给变量phoneNumber
phoneNumber = allNumbers[index]
# 从myqr中调用run()函数
# 添加参数words,参数值为字符串phoneNumber
# 添加参数picture,参数值为f"/Users/minmin/Selfie/{item}"
# 添加参数save_name,参数值为item
myqr.run(words=str(phoneNumber),
picture=f"/Users/minmin/Selfie/{item}",
save_name=item)
代码运行成功后,会生成黑白二维码,用手机扫码,出现对应了电话号码。
4. 把二维码保存到新的文件夹中:
接下来,我们要调整下二维码的样式,把图片变成彩色,并保存在新建的文件夹里。
-
继续在 myqr.run() 函数设置参数,传入参数
colorized,参数值设置为True; -
传入参数
save_dir,将生成的二维码保存在指定的文件夹中,文件夹路径为:“/Users/minmin/myqr”。
myqr.run(words=str(phoneNumber),
picture=f"/Users/minmin/Selfie/{item}",
save_name=item,
colorized=True,
save_dir="/Users/minmin/myqr")
代码运行成功后,在名为 myqr 的文件夹中生成了彩色的二维码,不错不错
在本地练习时,一定要先创建空白文件夹,再把二维码保存在指定文件夹路径中,不然程序就会报错哦~
三、完整源码:
完结撒花!!!我们已经成功地实现了如何去批量定制合适的二维码,下面附上完整的代码:
# 导入xlrd模块
import xlrd
# 导入os模块
import os
# 使用from...import从MyQR模块中导入myqr
from MyQR import myqr
# 将Excel文件路径/Users/minmin/资料.xlsx,赋值给变量path
path = "/Users/minmin/资料.xlsx"
# 读取path的工作簿并赋值给变量data
data = xlrd.open_workbook(path)
# 使用sheets()获取工作表对象,索引第一个元素赋值给变量table
table = data.sheets()[0]
# 调用col_values()和切片读取工作表第2列非表头数据,赋值给变量allNames
# 读取工作表第4列数据非表头数据,赋值给变量allNumbers
allNames = table.col_values(1)[1:]
allNumbers = table.col_values(3)[1:]
# 将文件夹路径"/Users/minmin/Selfie",赋值给pathFile
pathFile = "/Users/minmin/Selfie"
# 使用os.listdir()函数获取该路径下所有文件名,并赋值给变量allItems
allItems = os.listdir(pathFile)
# for循环遍历allItems,赋值给变量item
for item in allItems:
# 如果item不等于".DS_Store"
if item != ".DS_Store":
# 通过"."分割文件名
# 索引第一个元素赋值给变量fileName
fileName = item.split(".")[0]
# 如果fileName在列表allNames中
if fileName in allNames:
# 查找fileName在列表allNames中的索引位置
# 赋值给变量index
index = allNames.index(fileName)
# 通过列表allNumbers索引index,赋值给变量phoneNumber
phoneNumber = allNumbers[index]
# 从myqr中调用run()函数
# 添加参数words,参数值为字符串phoneNumber
# 添加参数picture,参数值为f"/Users/minmin/Selfie/{item}"
# 添加参数save_name,参数值为item
myqr.run(words=str(phoneNumber),
picture=f"/Users/minmin/Selfie/{item}",
save_name=item
colorized=True,
save_dir="/Users/minmin/myqr")
注意,完整的源码复制过去可能并不能运行,你需要根据实际情况修改路径!但是代码的思路是一样的,可以进行参考!
