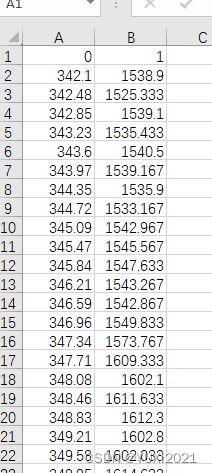
【数据预处理】对于csv文件批量处理
一、csv文件批量读取,原始csv,文件格式并合并第二列,为矩阵
1、matlab实现
% filter = {'*.csv';'*.mat';'*.*'};
% [filename,pathname] = uiputfile(filter);
clc
clear all
filepath=uigetdir('*.*','选择文件夹的路径');
filename=dir(strcat(filepath,'\*.csv')); %读取文件夹下的。csv
N=length(filename);
fprintf('\n 打印进度条示例: \n');
backNum=0;%退格用来
tic
for i=1:N%指定文件夹中csv数量
csvname=[filename(i,1).folder '\' filename(i,1).name];%各个csv文件绝对地址
csvdata{i} = readmatrix(csvname);%将各个csv文件保存至元胞组中
b=csvdata{i};
c(:,i)=b(:,2);
percent = round((i/N)*100); %计算百分比值
fprintf(repmat('\b',1,backNum)); %输出退格
backNum = fprintf('%d %%',percent); %输出进度条
%pause(0.001); %暂停0.1秒(程序运行会短暂延时,评价算法时间是尽量删除)
end
toc
plot(c)
fprintf('\n\n 程序运行完成.\n');
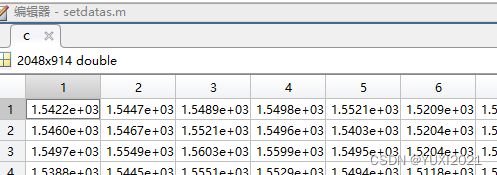
结果
2、 python实现
import numpy as np
import pandas as pd
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
Folder_Path = r"D:\WUCHA\fx" # 要拼接的文件夹及其完整路径,注意不要包含中文
SaveFile_Path = r"D:\WUCHA" # 拼接后要保存的文件路径
SaveFile_Name = r'9.csv' # 合并后要保存的文件名
# 修改当前工作目录
os.chdir(Folder_Path)
# 将该文件夹下的所有文件名存入一个列表
file_list = os.listdir()
# 读取第一个CSV文件并包含表头
df = pd.read_csv(Folder_Path + '\\' + file_list[0]) # 编码默认UTF-8,若乱码自行更改
data = df.values
print(data.shape)
# data=data[1,:]
print(data)
data=pd.DataFrame(data)
print("读入csv大小 /n",data.shape)
# 将读取的第一个CSV文件写入合并后的文件保存
data.to_csv(SaveFile_Path + '\\' + SaveFile_Name, encoding="utf_8_sig", index=False)
x=len(file_list);
# 循环遍历列表中各个CSV文件名,并追加到合并后的文件
for i in range(1, x):
df = pd.read_csv(Folder_Path + '\\' + file_list[i])
data = df.values
data = pd.DataFrame(data)
print(data.shape)
data.to_csv(SaveFile_Path + '\\' + SaveFile_Name, encoding="utf_8_sig", index=False, header=False, mode='a+')
print("读入最后csv数据大小",data.shape)
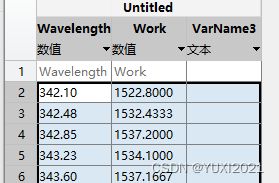
结果:行拼接成为csv