Flink原理、实战与性能优化(编辑中)
参考《Flink原理、实战与性能优化》
目录
- 基本架构
-
- client
- JobManager
- TaskManager
- flink编程模型
- Flink数据类型
- DataStream API
-
- DataStream 转换操作
- 时间概念与Watermark
- Flink状态管理和容错
- 环境部署
- 代码
-
- wordcount code
- Datastream Demo Code
- Kafka connector Demo Code
基本架构
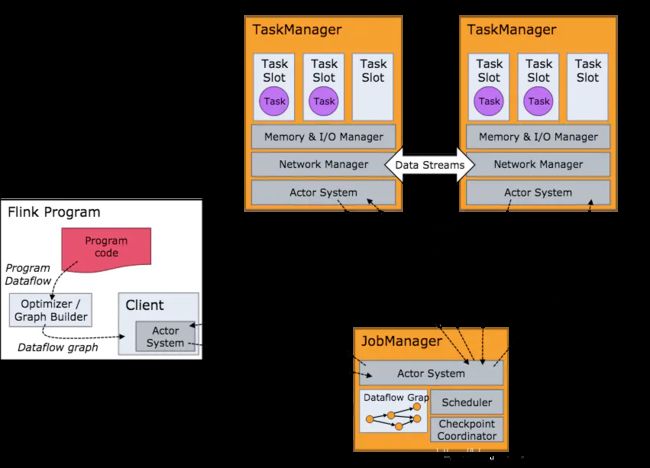
client
将作业提交到jobmanager
用户没提交一个flink程序就会创建一个client,client会将flink程序翻译成一个JobGraph
JobManager
整个集群的master节点,负责整个flink集群的任务调度和资源管理,整个集群有且仅有一个活跃的JobManager。
从客户端获取提交的应用,根据TaskManager上TaskSlot使用情况,为提交的作业分配TaskSlot资源,并命令TaskManager启动应用。
所有checkpoints协调过程都在JobManager完成,每个taskmanager收到触发命令后,完成checkpoints操作。
TaskManager
负责具体任务执行(计算)和对应任务在每个节点资源的申请和管理
flink编程模型
source - transformation -sink
Flink数据类型
1.任意Java原生基本数据类型(装箱)
2.任意Java原生基本数据类型(装箱)数组
3.java Tuples
4.Scala Case Class
5.POJO
等
DataStream API
DataStream 转换操作
- Mpa [DataStream - > DataStream]
应用于对数据格式的变化 - FlatMpa [DataStream - > DataStream]
应用于一个元素产生一个或多个元素 - Filter[DataStream - > DataStream]
过滤 - KeyBy [DataStream - > KeyedStream]
按key分区
keyby(0)//按第一个字段为分区key - Reduce [ KeyedStream- > DataStream]
将KeyedStream按照自定义的reducefunction聚合 - Aggregations [ KeyedStream- > DataStream]
对reduce的封装,有sum、min、minby、max、maxby等 - Union [DataStream - > DataStream]
两个或多个stream合并成一个 - Split [DataStream - > SplitStream]
将一个datastream按条件拆分 - Select [SplitStream- > DataStream ]
对Select的结果数据集筛选 - Iterate [DataStream - > IterativeStream - > DataStream]
将datastream中满足条件的进行下一次迭代,不满足则发到下游datastream中 - 物理分区操作 [SplitStream- > DataStream ]
用于防止数据倾斜
随机分区(Random Partitioning)、R Partioning、Rescaling Partioning 、广播操作(Broadcasting)、自定义分区(Custom Partitioning)
时间概念与Watermark
flink中时间分为三个概念
事件生成时间(Event Time):在设备上发生事件的时间
事件接入时间(Ingestion Time):接入flink系统的时间
事件处理时间(Processing Time):执行算子的时间
EventTime 和 Watermark
原因:防止由于网络或系统等因素,造成事件数据不能及时到flink系统。
简述:设置Watermark(最大延迟间隔),如果数据没有全部到达,则一直等待。
EventTime和Watermark
Flink的时间与watermarks详解


Flink状态管理和容错
有状态的计算
flink程序运行中存储中间计算结果给后面的算子、function使用。存储可以是flink堆内对外内存或第三方存储介质。同理无状态计算不保存中间结果

适用场景
用户想获取某一特定事件规则的时间、按照时间窗口求最大值、机器学习、使用历史数据计算等
Flink状态类型
根据数据集中是否按key分区分为KeyedState、OperatorState(NonkeyedState),这两种状态均具有两种形式,托管状态(ManagedState)形式 和 原生状态(RawState)形式
| ManagedState | 托管状态 | 由Flink Runtime控制管理,将状态转换为内存Hash tables或RocksDB | 通过内部接口持久化到checkpoints |
| RawState | 原生状态 | 算子自己管理数据结构 | 将数据转化成bytes存储在checkpoints中 |
Checkpoints和Savepoints
异步轻量级分布式快照技术Checkpoints容错机制:
- 分布式快照可以将同一时间点Task/Operator状态数据全局统一快照处理。
- flink在输入的数据集上间隔性生成checkpointbarrier,出现异常时,就能从上一个快照恢复算子之前的状态,保持数据一致性。
- checkpoints一些配置:exactlyance(保证数据质量)和atleastonce(保证吞吐)语义选择、checkpoint超时时间、检查点间最小间隔(避免数据堆积)、并行检查点、外部检查点(持久化到外部系统)、checkpoint失败任务是否关闭
以手工命令的方式触发Checkpoint,并将结果持久化到指定的存储路径中的Savepoint机制:
- 目的是帮助用户在升级和维护集群过程中保存系统中的状态数据,避免因为停机运维或者升级应用等正常终止应用的操作而导致系统无法恢复到原有的计算状态的情况
Flink中提供了StateBackend来存储和管理Checkpoints过程中的状态数据:包括基于内存的MemoryStateBackend、基于文件系统的FsStateBackend,以及基于RockDB作为存储介质的RocksDBStateBackend
checkpoint优化
- 减小时间间隔
- 状态容量预估
- 异步snapshot
- 状态数据压缩
- CheckpointDelayTime
环境部署
官网下jar包:https://flink.apache.org/zh/downloads.html
注意,根据Hadoop、scala版本选择flink,避免包冲突
本地启动flink:
./flink-1.7.1/bin/start-cluster.sh
本地停止flink:
./flink-1.7.1/bin/stop-cluster.sh
检验启动成功(默认端口8081):
http://localhost:8081/

代码
wordcount code
maven 依赖
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-coreartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table_2.11artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
dependencies>
java code
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class wordcount {
public static void main(String[] args) throws Exception{
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource<String> text = env.fromElements(
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune",
"Or to take arms against a sea of troubles,"
);
DataSet<Tuple2<String,Integer>> counts =
text.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
counts.print();
}
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] tokens = value.toLowerCase().split("\\W+");//^\w中\w表示字符类(包括大小写字母,数字),后面的+号的作用在前一个字符上,即\w+,表示一个或多个\w,最少一个
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
}
如何用flink启动
~/soft/flink-1.7.1/bin/flink run -c 包名.类名 jar包名.jar
Datastream Demo Code
/*
运行命令:
cd ~/工作/idea_project/lazy_project/java_project/demo && mvn clean install
cd ~/工作/idea_project/lazy_project/java_project/demo/target && ~/soft/flink-1.7.1/bin/flink run -c base.dataStream.StreamingDemoWithMyRichPralalleSource demo-1.0-SNAPSHOT.jar
*/
package base.dataStream;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
public class StreamingDemoWithMyRichPralalleSource {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
// DataStreamSource streamSource = executionEnvironment.addSource(new MyParallesource()).setParallelism(1);
DataStreamSource<Long> streamSource = executionEnvironment.addSource(new MyNoParalleSource()).setParallelism(1);
SingleOutputStreamOperator<Long> operator = streamSource.map(new MyMapFunction());
operator.timeWindowAll(Time.seconds(2)).sum(0).print().setParallelism(1);
String jobName = StreamingDemoWithMyRichPralalleSource.class.getSimpleName();
executionEnvironment.execute(jobName);
}
}
class MyParallesource implements ParallelSourceFunction<Long>{
private long count = 1L;
private boolean isRunning = true;
@Override
public void run(SourceContext sourceContext) throws Exception {
while (isRunning){
sourceContext.collect(count ++);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isRunning = false;
}
}
//使用并行度为1的source
class MyNoParalleSource implements SourceFunction<Long> {//1
private long count = 1L;
private boolean isRunning = true;
/**
* 主要的方法
* 启动一个source
* 大部分情况下,都需要在这个run方法中实现一个循环,这样就可以循环产生数据了
*
* @param ctx
* @throws Exception
*/
@Override
public void run(SourceContext<Long> ctx) throws Exception {
while(isRunning){
ctx.collect(count);
count++;
//每秒产生一条数据
Thread.sleep(1000);
}
}
//取消一个cancel的时候会调用的方法
@Override
public void cancel() {
isRunning = false;
}
}
class MyMapFunction implements MapFunction<Long,Long>{
@Override
public Long map(Long value) throws Exception {
System.out.println("接收到数据:" + value);
return value;
}
}
Kafka connector Demo Code
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.7.0version>
dependency>
/*
启动本地zk,并查看状态,仅执行一次即可:
sh ~/soft/zookeeper-3.4.9/bin/zkServer.sh start && sh ~/soft/zookeeper-3.4.9/bin/zkServer.sh status
停止运行本地zk:
sh ~/soft/zookeeper-3.4.9/bin/zkServer.sh stop
*/
/*
启动本地kafka(先启动zookeeper):
nohup sh ~/soft/kafka_2.11-1.0.1/bin/kafka-server-start.sh ~/soft/kafka_2.11-1.0.1/config/server.properties &
查看是否成功(监听端口):
lsof -i:9092
关闭本地kafka:
sh ~/soft/kafka_2.11-1.0.1/bin/kafka-server-stop.sh
*/
/*
创建kafka topic(topic_name需要给为用户定义的topic名字):
sh ~/soft/kafka_2.11-1.0.1/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic 【topic_name】 ; sh ~/soft/kafka_2.11-1.0.1/bin/kafka-topics.sh --list --zookeeper localhost:2181
删除topic
sh ~/soft/kafka_2.11-1.0.1/bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic 【topic_name】 && sh ~/soft/kafka_2.11-1.0.1/bin/kafka-topics.sh --list --zookeeper localhost:2181
查看topic list:
sh ~/soft/kafka_2.11-1.0.1/bin/kafka-topics.sh --list --zookeeper localhost:2181
*/
/*
测试kafka生产消费:
创建控制台生产者:
sh ~/soft/kafka_2.11-1.0.1/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic 【topic_name】
创建消费者:
sh ~/soft/kafka_2.11-1.0.1/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic 【topic_name】 --from-beginning
*/
package base.dataStream;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.ArrayList;
import java.util.Properties;
import java.util.Random;
public class kafkaDataStream1 {
public static final String TOPIC_NAME = "topic_test";
public static Properties getProperties(){
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
return properties;
}
public static FlinkKafkaProducer<String> getProducer(){
Properties properties = getProperties();
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<String>(kafkaDataStream1.TOPIC_NAME, new SimpleStringSchema(), properties);
return producer;
}
public static FlinkKafkaConsumer<String> getConsumer(){
return new FlinkKafkaConsumer(TOPIC_NAME,new SimpleStringSchema(),getProperties());
}
}
class KafkaProducerDemo1{
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = executionEnvironment.addSource(new MyNoParalleSourceDemo1());
FlinkKafkaProducer<String> producer = kafkaDataStream1.getProducer();
source.addSink(producer);
executionEnvironment.execute();
}
}
class KafkaConsumerDemo1{
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
FlinkKafkaConsumer<String> consumer = kafkaDataStream1.getConsumer();
consumer.setStartFromLatest();
env.addSource(consumer).print();
env.execute();
}
}
class MyNoParalleSourceDemo1 implements SourceFunction<String> {
boolean isRuning = true;
@Override
public void run(SourceContext<String> sourceContext) throws Exception {
while (isRuning == true){
ArrayList<String> list = new ArrayList<>();
list.add("第1条");
list.add("第2条");
list.add("第3条");
list.add("第4条");
list.add("第5条");
int i = new Random().nextInt(5);
System.out.println("============"+list.get(i));
sourceContext.collect(list.get(i));
Thread.sleep(2000);
}
}
@Override
public void cancel() {
isRuning = false;
}
}